
8-pandas 之分组聚合
1 什么分组与聚合
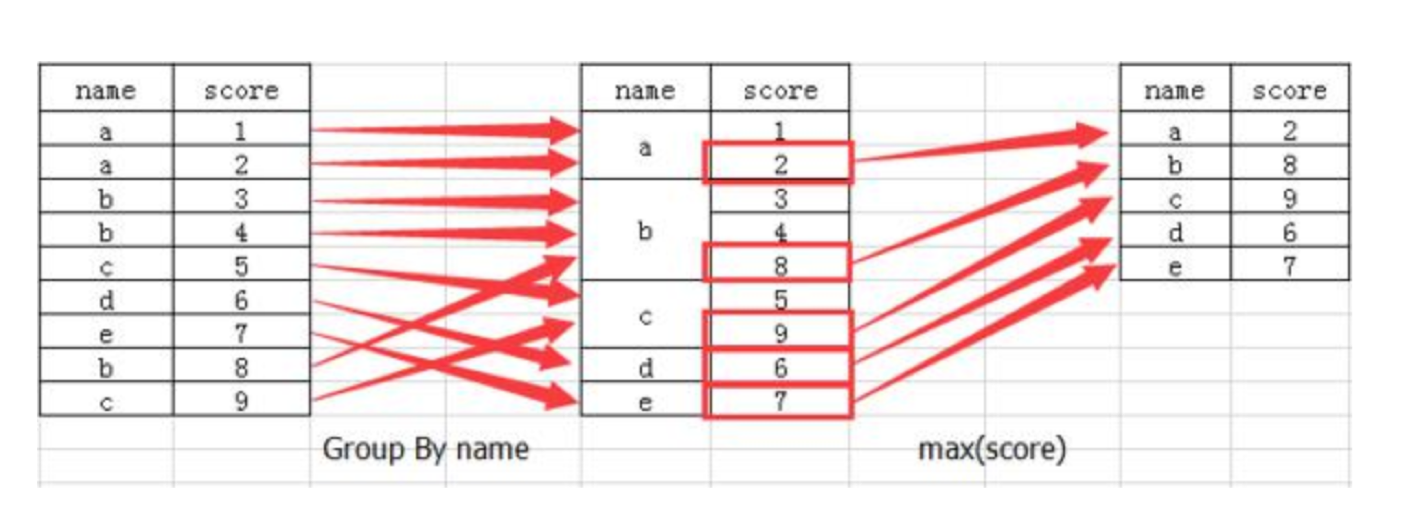
2 分组API
- DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个
- 案例:不同颜色的不同笔的价格数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
- 进行分组,对颜色分组,price进行聚合
# 分组,求平均值 col.groupby(['color'])['price1'].mean() col['price1'].groupby(col['color']).mean() color green 2.025 red 2.380 white 5.560 Name: price1, dtype: float64 # 分组,数据的结构不变 col.groupby(['color'], as_index=False)['price1'].mean() color price1 0 green 2.025 1 red 2.380 2 white 5.560
3 星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
3.1 数据获取
从文件中读取星巴克店铺数据
# 按照国家分组,求出每个国家的星巴克零售店数量
starbucks = pd.read_csv("./data/starbucks/directory.csv") starbucks.head() Brand Store Number Store Name Ownership Type Street Address City State/Province Country Postcode Phone Number Timezone Longitude Latitude 0 Starbucks 47370-257954 Meritxell, 96 Licensed Av. Meritxell, 96 Andorra la Vella 7 AD AD500 376818720 GMT+1:00 Europe/Andorra 1.53 42.51 1 Starbucks 22331-212325 Ajman Drive Thru Licensed 1 Street 69, Al Jarf Ajman AJ AE NaN NaN GMT+04:00 Asia/Dubai 55.47 25.42 2 Starbucks 47089-256771 Dana Mall Licensed Sheikh Khalifa Bin Zayed St. Ajman AJ AE NaN NaN GMT+04:00 Asia/Dubai 55.47 25.39 3 Starbucks 22126-218024 Twofour 54 Licensed Al Salam Street Abu Dhabi AZ AE NaN NaN GMT+04:00 Asia/Dubai 54.38 24.48 4 Starbucks 17127-178586 Al Ain Tower Licensed Khaldiya Area, Abu Dhabi Island Abu Dhabi AZ AE NaN NaN GMT+04:00 Asia/Dubai 54.54 24.51
3.2 进行分组聚合
# 按照国家分组,求出每个国家的星巴克零售店数量 count = starbucks.groupby(['Country']).count() count.head() Brand Store Number Store Name Ownership Type Street Address City State/Province Postcode Phone Number Timezone Longitude Latitude Country AD 1 1 1 1 1 1 1 1 1 1 1 1 AE 144 144 144 144 144 144 144 24 78 144 144 144 AR 108 108 108 108 108 108 108 100 29 108 108 108 AT 18 18 18 18 18 18 18 18 17 18 18 18 AU 22 22 22 22 22 22 22 22 0 22 22 22
假设我们加入省市一起进行分组
# 设置多个索引,set_index() starbucks.groupby(['Country', 'State/Province']).count() Brand Store Number Store Name Ownership Type Street Address City Postcode Phone Number Timezone Longitude Latitude Country State/Province AD 7 1 1 1 1 1 1 1 1 1 1 1 AE AJ 2 2 2 2 2 2 0 0 2 2 2 AZ 48 48 48 48 48 48 7 20 48 48 48 DU 82 82 82 82 82 82 16 50 82 82 82 FU 2 2 2 2 2 2 1 0 2 2 2


