


4-pandas 对文件的读取和存储
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
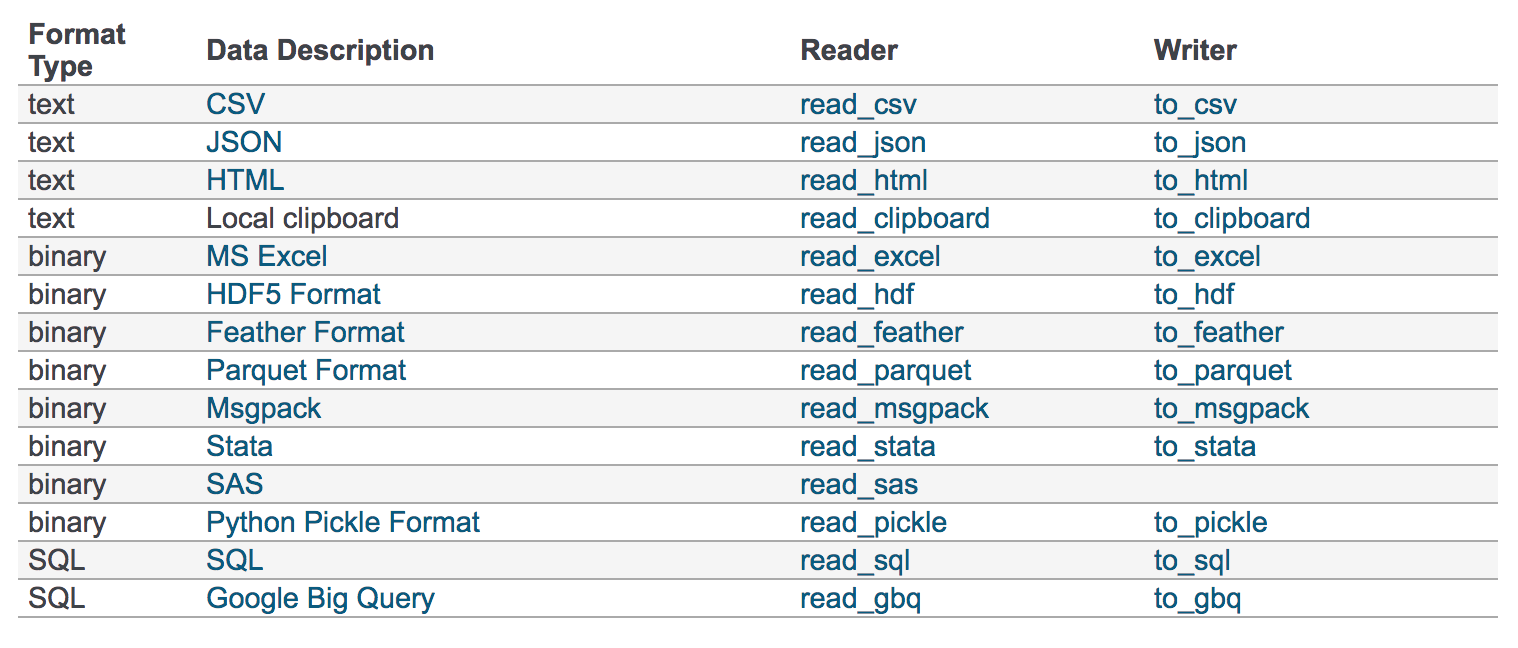
1 CSV
1.1 read_csv
- pandas.read_csv(filepath_or_buffer, sep =',' )
- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式
读取之前的股票的数据 # 读取文件,并且指定只获取'open', 'close'指标 data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close']) open high close 2018-02-27 23.53 25.88 24.16 2018-02-26 22.80 23.78 23.53 2018-02-23 22.88 23.37 22.82 2018-02-22 22.25 22.76 22.28 2018-02-14 21.49 21.99 21.92
1.2 to_csv
- DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None)
- path_or_buf :string or file handle, default None
- sep :character, default ‘,’
- columns :sequence, optional
- mode:'w':重写, 'a' 追加
- index:是否写进行索引
- header :boolean or list of string, default True,是否写进列索引值
1.3 案例
- 保存'open'列的数据
# 选取10行数据保存,便于观察数据 data[:10].to_csv("./data/test.csv", columns=['open'])
- 读取,查看结果
pd.read_csv("./data/test.csv") Unnamed: 0 open 0 2018-02-27 23.53 1 2018-02-26 22.80 2 2018-02-23 22.88 3 2018-02-22 22.25 4 2018-02-14 21.49 5 2018-02-13 21.40 6 2018-02-12 20.70 7 2018-02-09 21.20 8 2018-02-08 21.79 9 2018-02-07 22.69 会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。 # index:存储不会讲索引值变成一列数据 data[:10].to_csv("./data/test.csv", columns=['open'], index=False)
2 HDF5
2.1 read_hdf与to_hdf
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
-
pandas.read_hdf(path_or_buf,key =None,** kwargs)
从h5文件当中读取数据
- path_or_buffer:文件路径
- key:读取的键
- return:Theselected object
-
DataFrame.to_hdf(path_or_buf, key, *\kwargs*)
2.2 案例
- 读取文件
day_eps_ttm = pd.read_hdf("./data/stock_data/day/day_eps_ttm.h5")
需要安装安装tables模块避免不能读取HDF5文件
pip install tables
- 存储文件
day_eps_ttm.to_hdf("./data/test.h5", key="day_eps_ttm")
再次读取的时候, 需要指定键的名字
new_eps = pd.read_hdf("./data/test.h5", key="day_eps_ttm")


