Stream流式计算
什么是Stream流式计算
存储+计算
- 集合框架,mysql 本质是存储东西的
- 计算应该交给流来操作
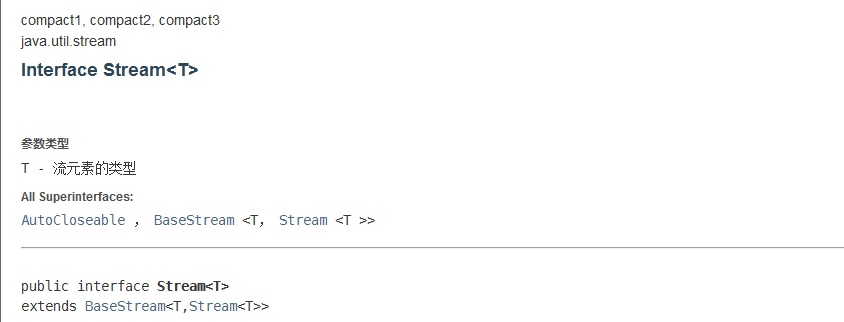
//一行代码实现五个要求
/* 筛选出
* 1.id必须是偶数
* 2.年龄大于15岁
* 3.用户名转为大写字母
* 4.用户名字母倒着排序
* 5.只输出一个用户*/
public class Test {
public static void main(String[] args) {
User u1=new User(1,"a",13);
User u2=new User(2,"b",14);
User u3=new User(3,"c",15);
User u4=new User(4,"d",16);
User u5=new User(5,"e",17);
//集合就是存储
List<User> list = Arrays.asList(u1, u2, u3, u4, u5);
//计算交给Stream流
list.stream() //lambda表达式,链式编程,函数式接口,Stream流计算
.filter(u->{return u.getId()%2!=0;})
.filter(user -> {return user.getAge()>=15;})
.map(user -> {return user.getName().toUpperCase();})
.sorted((uu1,uu2)->{return uu2.compareTo(uu1);})
.limit(1)
.forEach(System.out::println);
}
}
使用Stream流式计算的优点
- 使用Stream流式计算效率更高
- 程序更加简洁
方法
boolean allMatch(Predicate<? super T> predicate)
返回此流的所有元素是否与提供的谓词匹配。
boolean anyMatch(Predicate<? super T> predicate)
返回此流的任何元素是否与提供的谓词匹配。
static <T> Stream.Builder<T> builder()
返回一个 Stream的构建器。
<R,A> R collect(Collector<? super T,A,R> collector)
使用 Collector对此流的元素执行 mutable reduction Collector 。
<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner)
对此流的元素执行 mutable reduction操作。
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
创建一个懒惰连接的流,其元素是第一个流的所有元素,后跟第二个流的所有元素。
long count()
返回此流中的元素数。
Stream<T> distinct()
返回由该流的不同元素(根据 Object.equals(Object) )组成的流。
static <T> Stream<T> empty()
返回一个空的顺序 Stream 。
Stream<T> filter(Predicate<? super T> predicate)
返回由与此给定谓词匹配的此流的元素组成的流。
Optional<T> findAny()
返回描述流的一些元素的Optional如果流为空,则返回一个空的Optional 。
Optional<T> findFirst()
返回描述此流的第一个元素的Optional如果流为空,则返回一个空的Optional 。
<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper)
返回由通过将提供的映射函数应用于每个元素而产生的映射流的内容来替换该流的每个元素的结果的流。
DoubleStream flatMapToDouble(Function<? super T,? extends DoubleStream> mapper)
返回一个 DoubleStream ,其中包含将该流的每个元素替换为通过将提供的映射函数应用于每个元素而产生的映射流的内容的结果。
IntStream flatMapToInt(Function<? super T,? extends IntStream> mapper)
返回一个 IntStream ,其中包含将该流的每个元素替换为通过将提供的映射函数应用于每个元素而产生的映射流的内容的结果。
LongStream flatMapToLong(Function<? super T,? extends LongStream> mapper)
返回一个 LongStream ,其中包含将该流的每个元素替换为通过将提供的映射函数应用于每个元素而产生的映射流的内容的结果。
void forEach(Consumer<? super T> action)
对此流的每个元素执行操作。
void forEachOrdered(Consumer<? super T> action)
如果流具有定义的遇到顺序,则以流的遇到顺序对该流的每个元素执行操作。
static <T> Stream<T> generate(Supplier<T> s)
返回无限顺序无序流,其中每个元素由提供的 Supplier 。
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f)
返回有序无限连续 Stream由函数的迭代应用产生 f至初始元素 seed ,产生 Stream包括 seed , f(seed) , f(f(seed)) ,等
Stream<T> limit(long maxSize)
返回由此流的元素组成的流,截短长度不能超过 maxSize 。
<R> Stream<R> map(Function<? super T,? extends R> mapper)
返回由给定函数应用于此流的元素的结果组成的流。
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)
返回一个 DoubleStream ,其中包含将给定函数应用于此流的元素的结果。
IntStream mapToInt(ToIntFunction<? super T> mapper)
返回一个 IntStream ,其中包含将给定函数应用于此流的元素的结果。
LongStream mapToLong(ToLongFunction<? super T> mapper)
返回一个 LongStream ,其中包含将给定函数应用于此流的元素的结果。
Optional<T> max(Comparator<? super T> comparator)
根据提供的 Comparator返回此流的最大元素。
Optional<T> min(Comparator<? super T> comparator)
根据提供的 Comparator返回此流的最小元素。
boolean noneMatch(Predicate<? super T> predicate)
返回此流的元素是否与提供的谓词匹配。
static <T> Stream<T> of(T... values)
返回其元素是指定值的顺序排序流。
static <T> Stream<T> of(T t)
返回包含单个元素的顺序 Stream 。
Stream<T> peek(Consumer<? super T> action)
返回由该流的元素组成的流,另外在从生成的流中消耗元素时对每个元素执行提供的操作。
Optional<T> reduce(BinaryOperator<T> accumulator)
使用 associative累积函数对此流的元素执行 reduction ,并返回描述减小值的 Optional (如果有)。
T reduce(T identity, BinaryOperator<T> accumulator)
使用提供的身份值和 associative累积功能对此流的元素执行 reduction ,并返回减小的值。
<U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
执行 reduction在此流中的元素,使用所提供的身份,积累和组合功能。
Stream<T> skip(long n)
在丢弃流的第一个 n元素后,返回由该流的 n元素组成的流。
Stream<T> sorted()
返回由此流的元素组成的流,根据自然顺序排序。
Stream<T> sorted(Comparator<? super T> comparator)
返回由该流的元素组成的流,根据提供的 Comparator进行排序。
Object[] toArray()
返回一个包含此流的元素的数组。
<A> A[] toArray(IntFunction<A[]> generator)
使用提供的 generator函数返回一个包含此流的元素的数组,以分配返回的数组,以及分区执行或调整大小可能需要的任何其他数组。
