Google Protocol Buffers
摘自:https://blog.csdn.net/wm_1991/article/details/51788868
Google Protocol Buffers浅析(一)
本文主要偏向于介绍怎么使用Google的Protocol Buffer技术来压缩与解析你的数据文件,更加详细的信息请参阅Google开放的开发者网页文档,地址为:http://code.google.com/apis/protocolbuffers/docs/overview.html 。
一、简单的介绍
当然,在继续本文之前,读者还是需要对Google Protocol Buffers有一些基本的认识。Protocol buffers是一个用来序列化结构化数据的技术,支持多种语言诸如C++、Java以及Python语言,可以使用该技术来持久化数据或者序列化成网络传输的数据。相比较一些其他的XML技术而言,该技术的一个明显特点就是更加节省空间(以二进制流存储)、速度更快以及更加灵活。
通常,编写一个protocol buffers应用需要经历如下三步:
1、定义消息格式文件,最好以proto作为后缀名
2、使用Google提供的protocol buffers编译器来生成代码文件,一般为.h和.cc文件,主要是对消息格式以特定的语言方式描述
3、使用protocol buffers库提供的API来编写应用程序
二、定义Proto文件
proto文件即消息协议原型定义文件,在该文件中我们可以通过使用描述性语言,来良好的定义我们程序中需要用到数据格式。首先我们可以通过Google在线文档上提供的一个电话簿的例子来了解下,不过稍微加了点改动。

required string name = 1 ;
required int32 id = 2 ;
optional string email = 3 ;
enum PhoneType {
MOBILE = 0 ;
HOME = 1 ;
WORK = 2 ;
}
message PhoneNumber {
required string number = 1 ;
optional PhoneType type = 2 [ default = HOME];
}
repeated PhoneNumber phone = 4 ;
required bytes unsure = 5; // Add byte array here
}
message AddressBook {
repeated Person person = 1 ;
}
诚如你看到的一样,消息格式定义很简单,对于每个字段而言都有一个修饰符(required/repeated/optional)、字段类型(bool/string/bytes/int32等)和字段标签(Tag)组成。
三个修饰符从词义上可以很清楚的弄明白,
1)对于required的字段而言,初值是必须要提供的,否则字段的便是未初始化的。在Debug模式的buffer库下编译的话,序列化话的时候可能会失败,而且在反序列化的时候对于该字段的解析会总是失败的。所以,对于修饰符为required的字段,请在序列化的时候务必给予初始化。
2)对于optional的字段而言,如果未进行初始化,那么一个默认值将赋予该字段,当然也可以指定默认值,如上述proto定义中的PhoneType字段类型。
3)对于repeated的字段而言,该字段可以重复多个,google提供的这个addressbook例子便有个很好的该修饰符的应用场景,即每个人可能有多个电话号码。在高级语言里面,我们可以通过数组来实现,而在proto定义文件中可以使用repeated来修饰,从而达到相同目的。当然,出现0次也是包含在内的。
其中字段标签标示了字段在二进制流中存放的位置,这个是必须的,而且序列化与反序列化的时候相同的字段的Tag值必须对应,否则反序列化会出现意想不到的问题。
三、编译proto文件,生成特定语言数据的数据定义代码
在定义好了proto文件,就可以将该文件作为protocol buffers编译器的输入文件,编译产生特定语言的数据定义代码文件了。本文主要是针对C++语言,所以使用编译器后生成的是.h与.cc的代码文件。对于C++、Java还有Python都有各自的编译器,下载地址:http://code.google.com/p/protobuf/downloads/list
当你下载完了对应的编译器二进制文件后,就可以使用下列命令来完成编译过程:
protoc.exe -proto_path=SRC --cpp_out=DST SRC/addressbook.proto
其中--proto_path指出proto文件所在的目录,--cpp_out则是生成的代码文件要放的目录,最后的一个参数指出proto文件的路径。如上述命令中可以看出,将SRC目录下的addressbook.proto编译后放在DST目录下,应该会生成addressbook.pb.h和addressbook.pb.cc文件(/Files/royenhome/addressbook.rar)。
通过查看头文件,可以发现针对每个字段都会大致生成如下几种函数,以number为例:
inline bool has_number() const ;
inline void clear_number();
inline const ::std:: string & number() const ;
inline void set_number( const ::std:: string & value);
inline void set_number( const char * value);
inline ::std:: string * mutable_number();
可以看出,对于每个字段会生成一个has函数(has_number)、clear清除函数(clear_number)、set函数(set_number)、get函数(number和mutable_number)。这儿解释下get函数中的两个函数的区别,对于原型为const std::string &number() const的get函数而言,返回的是常量字段,不能对其值进行修改。但是在有一些情况下,对字段进行修改是必要的,所以提供了一个mutable版的get函数,通过获取字段变量的指针,从而达到改变其值的目的。
而对于字段修饰符为repeated的字段生成的函数,则稍微有一些不同,如phone字段,则编译器会为其产生如下的代码:
inline int phone_size() const ;
inline void clear_phone();
inline const ::google::protobuf::RepeatedPtrField < ::Person_PhoneNumber >& phone() const ;
inline ::google::protobuf::RepeatedPtrField < ::Person_PhoneNumber >* mutable_phone();
inline const ::Person_PhoneNumber & phone( int index) const ;
inline ::Person_PhoneNumber * mutable_phone( int index);
inline ::Person_PhoneNumber * add_phone();
可以看出,set函数变成了add函数,这个其实很好理解。上面也说过,repeated修饰的字段在高级语言中的实现可能是个数组或动态数组,所以当然通过添加的方式来加入新的字段值。而起get函数也变化很大,这个也不用多说了。
好了,本文主要是对了解protocol buffer作了些简单的介绍,当然更详细的还是看官方文档。下篇文章开始将介绍怎么利用protocol buffers来完成序列化与反序列化数据。
欢迎转载,转载时请务必保留原文出处:http://www.cnblogs.com/royenhome ,谢谢合作!
Google Protocol Buffers浅析(二)
本文开始将逐渐介绍怎么使用protocol buffers来完成序列化与反序列化数据的应用,开发环境为VS2008,语言为C++,外部库用的是googlebuffer库。
1、Google Protocol Buffer库
在我们的应用程序里面,需要使用到google buffer提供的库,大家可以到官网去下载,笔者也会提供一个精简后的Win32 Release版的Lib库下载(Debug版与X64版的都删去了,不然lib包超过200M)。下载地址:GoogleBufferLib
解压缩后可以看出文件夹结构如下所示:
---GoogleProtocolBuffer
---include文件夹
---lib文件夹
---win32文件夹
---release文件夹
---proto文件夹(自己建的,放proto文件的)
---royen文件夹(自己建的,生成的.h和.cc的目录)
---*.lib 库文件
---protoc.exe编译器
其中,include文件夹下是一堆程序中需要引用的头文件,而在lib文件夹下则是有protoc编译器和链接库。
2、建立并正确设置项目
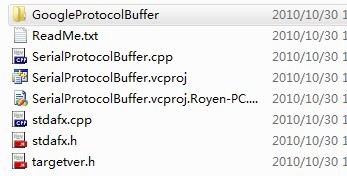
1)使用VS2008新建一个项目后,将上面下载的GoogleProtocolBuffer文件夹拷贝到你的项目工程里,如下图所示:
2)使用编译器将定义的proto文件编译成.h与.cc文件,拷贝到项目工程目录下,如下图所示:
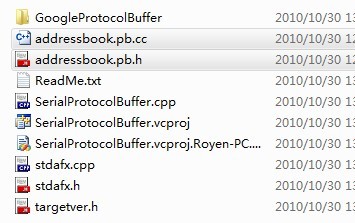
3)在项目中将.h与.cc文件引用进来,并在addressbook.pb.cc头部加上一句include "stdafx.h",否则编译时会报错
4)打开项目属性,右键项目-》Configuration-》C/C++ -》General ,设置Additional Include Directories,如下所示:

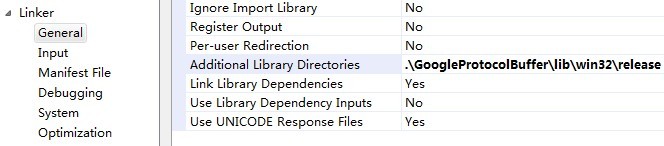
5)定位到Configuration -》Linker -》General,设置Additional Library Directories,如下所示:
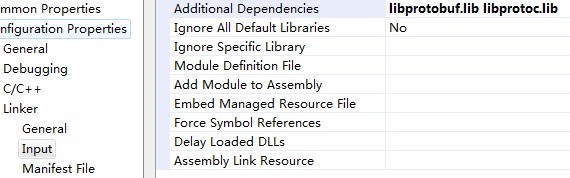
6)定位到Configuration -》Input-》Additional Dependencies,如下图所示:
7)定位到Configuration -》C/C++ -》Code Generation,修改Runtime Library项为Multi-threaded(/MT),如下图所示:
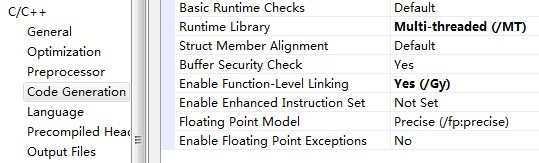
通过上述的一些列项目属性设置,程序可以正确编译通过了,但是什么功能都没有,下篇文章中将介绍怎么序列化与反序列化我们的数据。
Google Protocol Buffers浅析(三)
本文主要会介绍怎么使用Google Protocol的Lib来序列化我们的数据,方法很多种,本文只介绍其中的三种,其他的方法读者可以通过自行研究摸索。但总的来说,序列化数据总的来说分为以下俩步:
1)使用数据源填充数据结构,无论数据源来自文件还是内存还是标准输入
2)利用Lib提供的序列化接口将数据结构序列化,然后存储在内存或者磁盘上
一、填充数据结构
从数据源中获取数据,这儿的数据源可能来自磁盘上的一个文件或者内存中存储的一段数据或者来自标准输入的数据。我们需要做的就是,将AddressBook这个数据结构中的各个字段填充。本例中是通过AddressBook提供的add_person函数来获得一个Person的指针,从而对其进行填充,如下代码所示:
AddressBook addressBook;
// 第一个联系人的数据定义与初始化
Person * personMe = addressBook.add_person();
personMe -> set_id( 1 );
personMe -> set_name( " royen " );
personMe -> set_email( " zwg19891129@163.com " );
personMe -> set_unsure( " 19bf173a0e87ab " );
// 第二个联系人的数据定义与初始化
Person * personHim = addressBook.add_person();
personHim -> set_id( 2 );
personHim -> set_name( " XXX " );
personHim -> set_email( " XXX@XXX.com " );
personHim -> set_unsure( " 19bf173a0e87ab " );
// personMe的手机号码数据定义与初始化
Person_PhoneNumber * phoneNumberMobile = personMe -> add_phone();
phoneNumberMobile -> set_number( " 15996110120 " );
phoneNumberMobile -> set_type(Person_PhoneType_MOBILE);
// personMe的座机号码数据定义与初始化
Person_PhoneNumber * phoneNumberHome = personMe -> add_phone();
phoneNumberHome -> set_number( " 0256110120 " );
phoneNumberHome -> set_type(Person_PhoneType_HOME);
// personHim的一个号码数据定义与初始化
Person_PhoneNumber * phoneNumberHim = personHim -> add_phone();
phoneNumberHim -> set_number( " 15996111111 " );
phoneNumberHim -> set_type(Person_PhoneType_HOME);
很容易看出,上述代码即在地址簿中添加了俩个联系人,然后又分别填充各个联系人的数据信息,通过上述代码一个地址簿的数据便准备好了。
二、序列化数据
其实通过看编译器生成的AddressBook这个类所提供的方法名,既可以大致知道有哪些序列化的方式,如下所示:
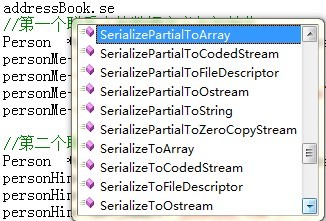
从上图可以看出,可利用序列化的方法很多,本文中主要使用SerializeToString、SerializeToCodedStream以及SerializeToOstream来完成序列化。
下面就分别就这几种方式来介绍下:
1) SerializeToCodedStream方式
首先可以知道该函数的原型是bool SerializeToCodedStream(std::ostream *),所以使用该函数需要结合C++的fstream流,代码如下:
fstream fserial( " addressbook.data " ,ios:: out | ios::trunc | ios::binary);
if ( ! addressBook.SerializePartialToOstream( & fserial))
{
cerr << " Failed to serial address book data!\n " ;
return ;
}
cout << " Serial address book data successfully!\n " ;
fserial.close();
fserial.clear();
可以看出,采用这种方法相当的便捷,而且也很简洁,但有个缺点就是输出到文件的编码格式不好控制,所以可以使用下面介绍的这种方法。
2)SerializeToString方式
函数原型为bool SerializeToString(std::string* output) ,所以可以讲填充在数据结构AddressBook中的数据取出存到一个string对象中,然后再以二进制流的方式将其写入到磁盘文件中,代码如下:
if ( NULL == g_AddressBook )
{
cerr << " Create addressbook.data failed!\n " ;
return ;
}
string serialStream = "" ;
if ( ! addressBook.SerializePartialToString( & serialStream) )
{
cerr << " Failed to serial addressbook data!\n " ;
return ;
}
fwrite( serialStream.c_str(), sizeof ( char ),addressBook.ByteSize(),g_AddressBook);
cout << " serial address successfully!\n " ;
if ( g_AddressBook )
{
fclose(g_AddressBook);
g_AddressBook = NULL;
}
上述代码稍微繁琐了点,但是也是一种序列化的方式,通过结合使用C库中的文件操作函数,可以更方便的定制输出文件。
3)SerializeToCodedStream方式
该方式主要指用到的google buffer的库中提供的一组数据流操作对象,在使用这些对象之前需要引入一些头文件,如下所示:
#include < google / protobuf / io / zero_copy_stream.h >
#include < google / protobuf / io / coded_stream.h >
using namespace ::google::protobuf::io;
该方式也结合C库的open与write函数,序列化部分的代码如下:
if ( - 1 == fd )
{
cerr << " Create addressbook.data failed!\n " ;
return ;
}
char tmpArr[MAX_SIZE];
memset(tmpArr, 0 , sizeof (tmpArr));
ZeroCopyOutputStream * raw_output = new ArrayOutputStream(tmpArr,addressBook.ByteSize() + 1 );
CodedOutputStream * coded_output = new CodedOutputStream(raw_output);
if ( ! addressBook.SerializeToCodedStream( coded_output ))
{
cerr << " Fail to serial addressbook data!\n " ;
return ;
}
_write(fd,tmpArr,addressBook.ByteSize() + 1 );
cout << " serial address successfully!\n " ;
delete coded_output;
delete raw_output;
close(fd);
本文暂时介绍这三种序列化话方式,还有像SerializeToArray以及SerializeToFileDescriptor等方式都应该比较类似,所以感兴趣的朋友可以自己动手试试。
下篇文章再稍微介绍下反序列化的方法,但是应该不会太多内容,毕竟都方法都很相似。
Google Protocol Buffers浅析(四)
本文作为结束篇,会稍微介绍下怎么反序列化GoogleBuffer数据,并在最后提供本系列文章中所用到的代码整理供下载。
上一篇文章介绍了怎样将数据序列化到了addressbook.data中,那么对于接受方而言该怎么解析出原本的数据呢。同样,protoc编译器生成的代码文件中提供了反序列化的接口,基本上和序列化的函数对应的,如下图所示:
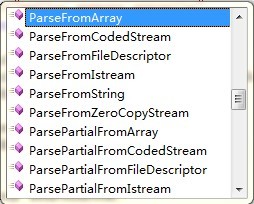
上文中采用了SerializeToOstream、SerializeToString、SerializeToCodedStream来序列化数据的,反序列化反其道行之即可。本文反序列化采用ParseFromArray方式,从某个角度算是对上文的一个补充吧!
反序列化也是分为两个步骤:
1)将数据载入内存或者输入流
2)调用库提供的反序列化接口函数进行反序列化
一、将数据载入
将数据从文件中读出时候,需要注意以二进制的模式打开,且编码格式要指定正确,如下所示:
if ( NULL == g_AddressBook )
{
cerr << " Open addressbook.data failed!\n " << endl;
return ;
}
int lfilesize = 0 ;
fseek( g_AddressBook, 0 ,SEEK_END);
lfilesize = ftell( g_AddressBook );
fseek( g_AddressBook , 0 ,SEEK_SET );
char * buffer = new char [lfilesize + 1 ];
if ( NULL == buffer )
{
cerr << " malloc memory error!\n " ;
return ;
}
memset(buffer, ' \0 ' , sizeof (buffer));
fread( buffer, sizeof ( char ),lfilesize,g_AddressBook);
if ( g_AddressBook )
{
fclose(g_AddressBook);
g_AddressBook = NULL;
}
二、反序列化
上述代码将addressbook.data中的数据载入了buffer中,接着我们就可以将其作为参数传给ParseFromArray来反序列化,并格式化输出到控制台,如下:
addressBook.par
addressBook.Clear();
if ( ! addressBook.ParseFromArray(buffer,lfilesize) )
{
cerr << " Deserial from addressbook.data failed!\n " ;
return ;
}
int personSize = addressBook.person_size();
for ( int i = 0 ;i < personSize; i ++ )
{
Person p = addressBook.person( i );
cout << " Person " << i + 1 << " :\nid\t " << p.id() << " \nname:\t " << p.name() << " \n " ;
int phoneSize = p.phone_size();
for ( int j = 0 ;j < phoneSize;j ++ )
{
Person_PhoneNumber phone = p.phone(j);
cout << " Phone " << j + 1 << " :\nType:\t " ;
switch ( phone.type())
{
case Person_PhoneType_MOBILE:
cout << " Mobile\t\tPhone Number:\t " << phone.number() << endl;
break ;
case Person_PhoneType_HOME:
cout << " Home\t\tPhone Number:\t " << phone.number() << endl;
break ;
case Person_PhoneType_WORK:
cout << " Work\t\tPhone Number:\t " << phone.number() << endl;
break ;
default :
cout << " Unkown\n " ;
break ;
}
}
cout << endl;
}
运行结果如下所示:
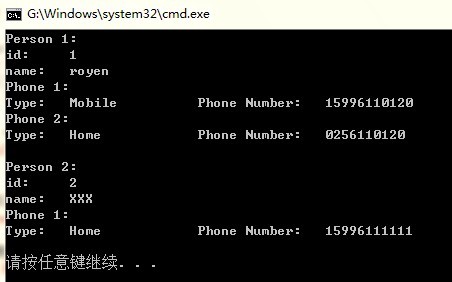
好了,相信通过本系列文章,读者应该对Google Protocol Buffer有一定的认识了吧。当然,想要更深入的了解,还是参考Google的官方在线文档吧!
示例代码下载地址:SerialProtocolBuffer示例代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号