
策略梯度玩 cartpole 游戏,强化学习代替PID算法控制平衡杆
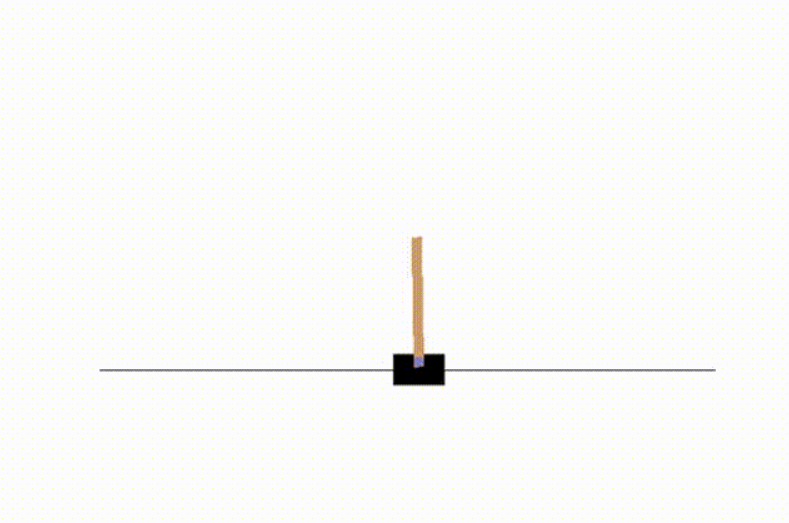
cartpole游戏,车上顶着一个自由摆动的杆子,实现杆子的平衡,杆子每次倒向一端车就开始移动让杆子保持动态直立的状态,策略函数使用一个两层的简单神经网络,输入状态有4个,车位置,车速度,杆角度,杆速度,输出action为左移动或右移动,输入状态发现至少要给3个才能稳定一会儿,给2个完全学不明白,给4个能学到很稳定的policy
策略梯度实现代码,使用torch实现一个简单的神经网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 | import gymimport torchimport torch.nn as nnimport torch.optim as optimimport pygameimport sysfrom collections import dequeimport numpy as np# 策略网络定义class PolicyNetwork(nn.Module): def __init__(self): super(PolicyNetwork, self).__init__() self.fc = nn.Sequential( nn.Linear(4, 10), # 4个状态输入,128个隐藏单元 nn.Tanh(), nn.Linear(10, 2), # 输出2个动作的概率 nn.Softmax(dim=-1) ) def forward(self, x): # print(x) 车位置 车速度 杆角度 杆速度 selected_values = x[:, [0,1,2,3]] #只使用车位置和杆角度 return self.fc(selected_values)# 训练函数def train(policy_net, optimizer, trajectories): policy_net.zero_grad() loss = 0 print(trajectories[0]) for trajectory in trajectories: # if trajectory["returns"] > 90: # returns = torch.tensor(trajectory["returns"]).float() # else: returns = torch.tensor(trajectory["returns"]).float() - torch.tensor(trajectory["step_mean_reward"]).float() # print(f"获得奖励{returns}") log_probs = trajectory["log_prob"] loss += -(log_probs * returns).sum() # 计算策略梯度损失 loss.backward() optimizer.step() return loss.item()# 主函数def main(): env = gym.make('CartPole-v1') policy_net = PolicyNetwork() optimizer = optim.Adam(policy_net.parameters(), lr=0.01) print(env.action_space) print(env.observation_space) pygame.init() screen = pygame.display.set_mode((600, 400)) clock = pygame.time.Clock() rewards_one_episode= [] for episode in range(10000): state = env.reset() done = False trajectories = [] state = state[0] step = 0 torch.save(policy_net, 'policy_net_full.pth') while not done: state_tensor = torch.tensor(state).float().unsqueeze(0) probs = policy_net(state_tensor) action = torch.distributions.Categorical(probs).sample().item() log_prob = torch.log(probs.squeeze(0)[action]) next_state, reward, done, _,_ = env.step(action) # print(episode) trajectories.append({"state": state, "action": action, "reward": reward, "log_prob": log_prob}) state = next_state for event in pygame.event.get(): if event.type == pygame.QUIT: pygame.quit() sys.exit() step +=1 # 绘制环境状态 if rewards_one_episode and rewards_one_episode[-1] >99: screen.fill((255, 255, 255)) cart_x = int(state[0] * 100 + 300) pygame.draw.rect(screen, (0, 0, 255), (cart_x, 300, 50, 30)) # print(state) pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * torch.sin(torch.tensor(state[2]))), 300 - int(50 * torch.cos(torch.tensor(state[2])))), 2) pygame.display.flip() clock.tick(200) print(f"第{episode}回合",f"运行{step}步后挂了") # 为策略梯度计算累积回报 returns = 0 for traj in reversed(trajectories): returns = traj["reward"] + 0.99 * returns traj["returns"] = returns if rewards_one_episode: # print(rewards_one_episode[:10]) traj["step_mean_reward"] = np.mean(rewards_one_episode[-10:]) else: traj["step_mean_reward"] = 0 rewards_one_episode.append(returns) # print(rewards_one_episode[:10]) train(policy_net, optimizer, trajectories)def play(): env = gym.make('CartPole-v1') policy_net = PolicyNetwork() pygame.init() screen = pygame.display.set_mode((600, 400)) clock = pygame.time.Clock() state = env.reset() done = False trajectories = deque() state = state[0] step = 0 policy_net = torch.load('policy_net_full.pth') while not done: state_tensor = torch.tensor(state).float().unsqueeze(0) probs = policy_net(state_tensor) action = torch.distributions.Categorical(probs).sample().item() log_prob = torch.log(probs.squeeze(0)[action]) next_state, reward, done, _,_ = env.step(action) # print(episode) trajectories.append({"state": state, "action": action, "reward": reward, "log_prob": log_prob}) state = next_state for event in pygame.event.get(): if event.type == pygame.QUIT: pygame.quit() sys.exit() # 绘制环境状态 screen.fill((255, 255, 255)) cart_x = int(state[0] * 100 + 300) pygame.draw.rect(screen, (0, 0, 255), (cart_x, 300, 50, 30)) # print(state) pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * torch.sin(torch.tensor(state[2]))), 300 - int(50 * torch.cos(torch.tensor(state[2])))), 2) pygame.display.flip() clock.tick(60) step +=1 print(f"运行{step}步后挂了")if __name__ == '__main__': main() #训练 # play() #推理 |
运行效果,训练过程不是很稳定,有时候学很多轮次也学不明白,有时侯只需要几十次就可以学明白了

多思考也是一种努力,做出正确的分析和选择,因为我们的时间和精力都有限,所以把时间花在更有价值的地方。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App