
macbook苹果m1芯片训练机器学习、深度学习模型,resnet101在mnist手写数字识别上做加速,torch.device("mps")
apple的m1芯片比以往cpu芯片在机器学习加速上听说有15倍的提升,也就是可以使用apple mac训练深度学习pytorch模型!!!惊呆了
安装apple m1芯片版本的pytorch
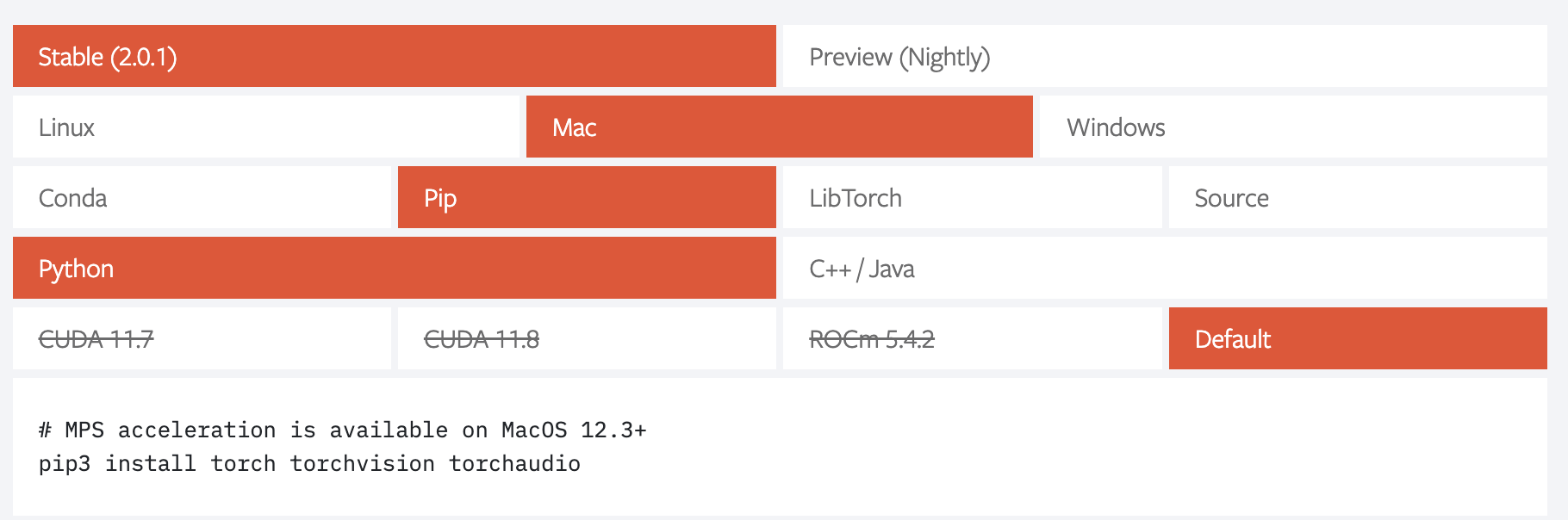
然后使用chatGPT生成一个resnet101的训练代码,这里注意,如果网络特别轻的话是没有加速效果的,还没有cpu的计算来的快
这里要选择好设备不是"cuda"了,cuda是nvidia深度学习加速的配置
1 2 3 | # 设置设备# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = torch.device("mps") #torch.device("cpu") |
resnet101的训练代码,训练mnist手写数字识别,之前我还尝试了两层linear的训练代码,低估了apple 的 torch.device("mps"),这两层linear的简单神经网络完全加速不起来,还不如torch.device("cpu")快,换成了resnet101加速效果就很明显了,目测速度在mps上比cpu快了5倍左右
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 | import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom torchvision.datasets import MNISTfrom torchvision.transforms import ToTensorfrom torchvision.models import resnet101from tqdm import tqdm# 设置设备# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = torch.device("mps") #torch.device("cpu")# 加载 MNIST 数据集train_dataset = MNIST(root="/Users/xinyuuliu/Desktop/test_python/", train=True, transform=ToTensor(), download=True)test_dataset = MNIST(root="/Users/xinyuuliu/Desktop/test_python/", train=False, transform=ToTensor())# 创建数据加载器train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)# 定义 ResNet-101 模型model = resnet101(pretrained=False)model.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)model.fc = nn.Linear(2048, 10) # 替换最后一层全连接层model.to(device)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练和评估函数def train(model, dataloader, optimizer, criterion): model.train() running_loss = 0.0 for inputs, labels in tqdm(dataloader, desc="Training"): inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() * inputs.size(0) epoch_loss = running_loss / len(dataloader.dataset) return epoch_lossdef evaluate(model, dataloader): model.eval() correct = 0 total = 0 with torch.no_grad(): for inputs, labels in tqdm(dataloader, desc="Evaluating"): inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() accuracy = correct / total * 100 return accuracy# 训练和评估num_epochs = 10for epoch in range(num_epochs): print(f"Epoch {epoch+1}/{num_epochs}") train_loss = train(model, train_loader, optimizer, criterion) print(f"Training Loss: {train_loss:.4f}") test_acc = evaluate(model, test_loader) print(f"Test Accuracy: {test_acc:.2f}%") |
结果:
在mps device上,训练时间在10分钟左右

在cpu device上,训练时间在50分钟左右,明显在mps device上速度快了5倍

多思考也是一种努力,做出正确的分析和选择,因为我们的时间和精力都有限,所以把时间花在更有价值的地方。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律