
分布式事务Seata AT模式原理分析
Seata
官网地址:https://seata.apache.org/zh-cn/
AT模式
优点:无侵入式代码,只需要添加注解,底层采用Seata代理的数据源DataSourceProxy
缺点:依赖于数据库,目前只适用于postgresql、oracle、mysql、polardb-x、sqlserver、达梦数据库等数据库,比如业务逻辑中含有redis、es等操作需要控制事务,无法实现,可以使用TCC模式
客户端
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
首先从源码查起,自动配置首先可以看到这两个,是比较核心的,SeataAutoConfiguration负责扫描@GlobalTransactional注解以及@GlobalLock注解,生成代理类,SeataDataSourceAutoConfiguration主要生成DataSourceProxy代理类以及PreparedStatementProxy或StatementProxy都使用的是Seata的代理类
io.seata.spring.boot.autoconfigure.SeataAutoConfiguration,
io.seata.spring.boot.autoconfigure.SeataDataSourceAutoConfiguration,
GlobalTransactionScanner类会首先扫描带@GlobalTransactional注解的类,其次在bean注入完成后 注册TM以及RM,主要逻辑还是生成GlobalTransactional注解的代理方法
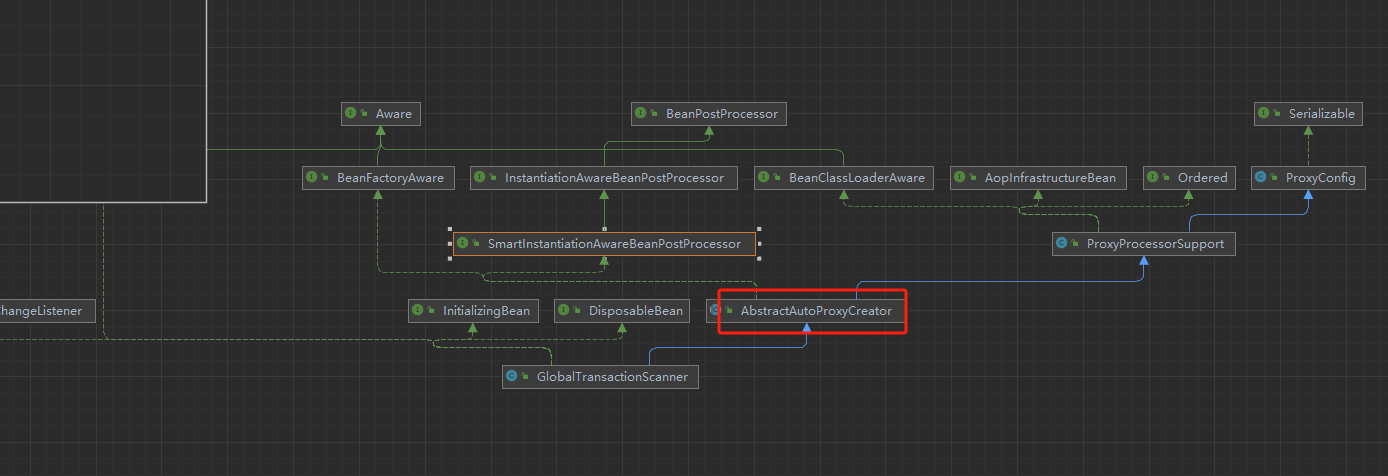
首先会在postProcessAfterInitialization初始化之后wrapIfNecessary也就是包装一层,这个方法所有bean都会执行一遍,为了过滤会进行一次初步筛选

会对包名判断以及去除Configuration类,然后会判断是否存在GlobalTransactional或GlobalLock注解,代理最重要的MethodInterceptor,所有的处理逻辑都将会在这个拦截器执行,只不过这里大概封装了三四层,因为TCC需要走不同的逻辑,
这里以官网例子举例,当调用purchase方法时会执行GlobalTransactionalInterceptorHandler#doInvoke方法
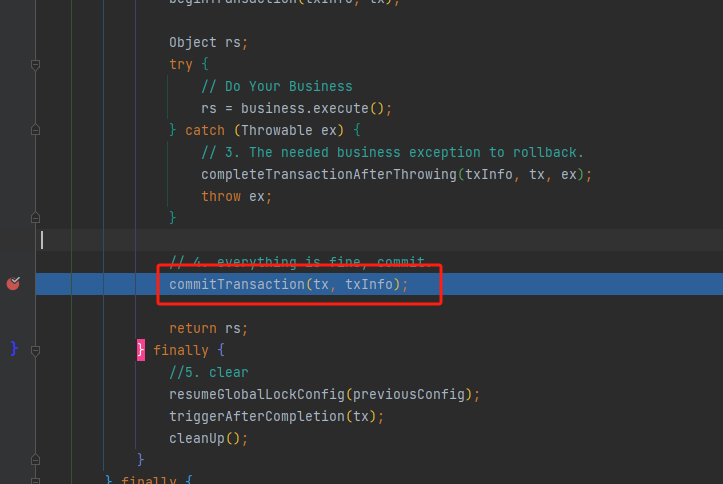
然后执行TransactionalTemplate#execute,首先判断事务的传播机制,默认为REQUIRED,会创建新的事务,以下为代理方法的核心逻辑,创建分布式事务,提交事务以及回滚事务
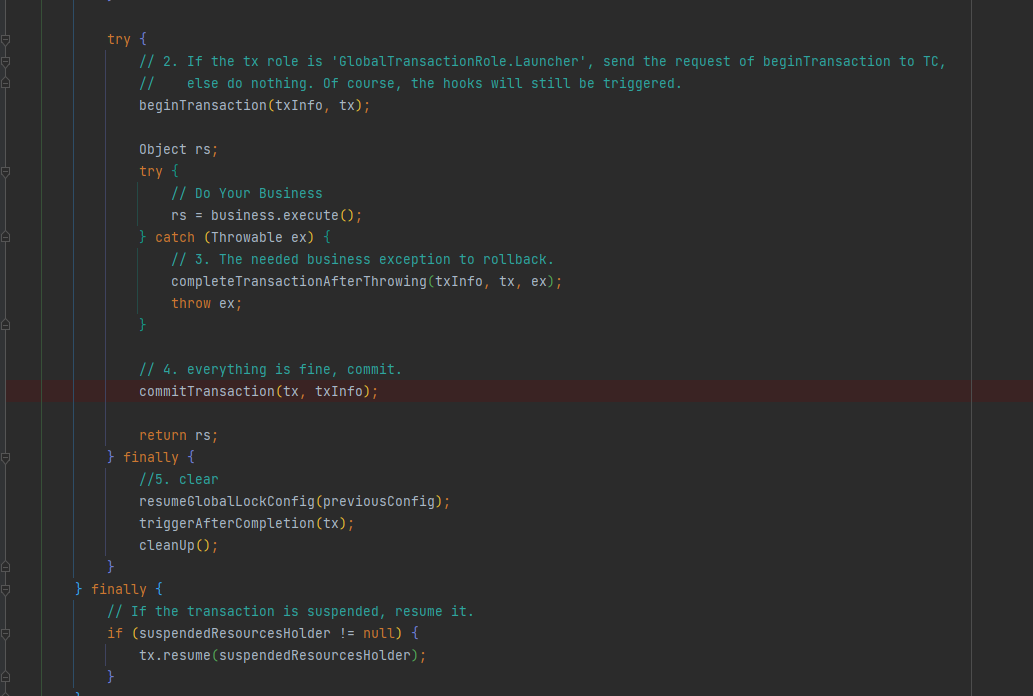
beginTransaction表示开启事务,第一次与服务端交互,拿到全局锁,返回一个xid,
第二步business.execute表示执行真正执行purchase方法,但是执行的过程中务必会有数据库的操作,所以先看DataSource的代理逻辑
DataSource方法代理
同上,继承了AbstractAutoProxyCreator,如果判断bean类型为DataSource,生成代理类之后放入DataSourceProxyHolder,类型为<origin, proxy>的缓存当中,
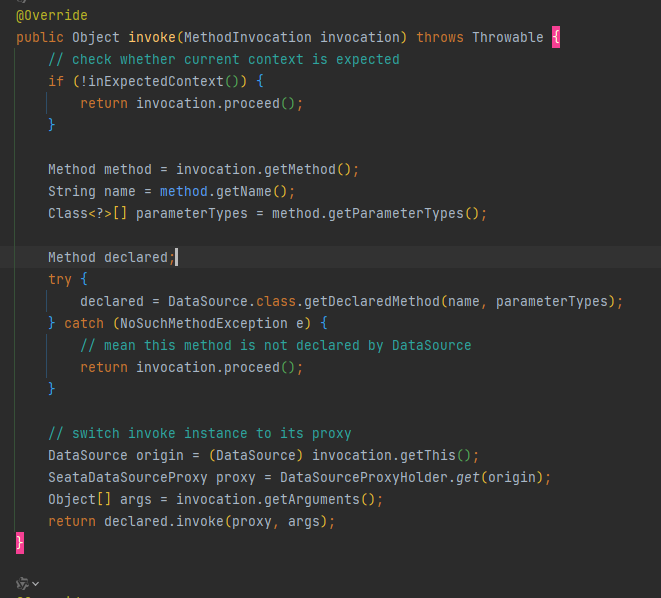
当调用DataSource方法的时候,再从DataSourceProxyHolder取出来,这样实际调用的就是代理类的方法,
其中DataSourceProxy中Connection以及Statement均用的seata的代理类
这里以更新为例,扣减库存数量,库存-2
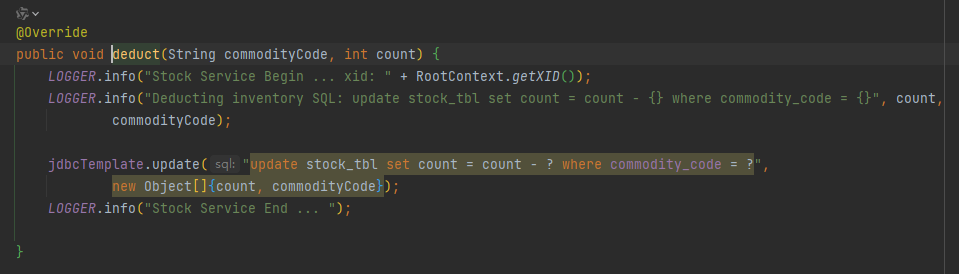
最终执行executeUpdate方法,在获取Connection的时候获取到的是代理之后的ConnectionProxy
一阶段
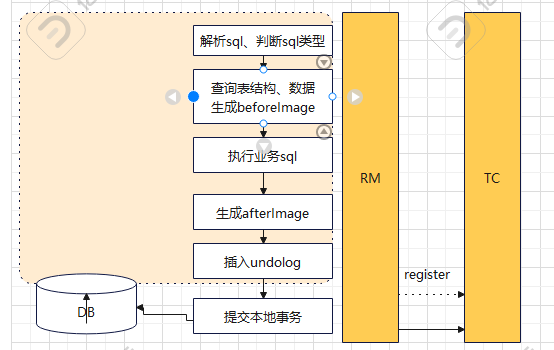
ExecuteTemplate#execute方法会判断执行sql类型,以UpdateExecutor为例,下面再执行sql的时候添加了额外的逻辑,这也是AT模式可以回滚的关键,
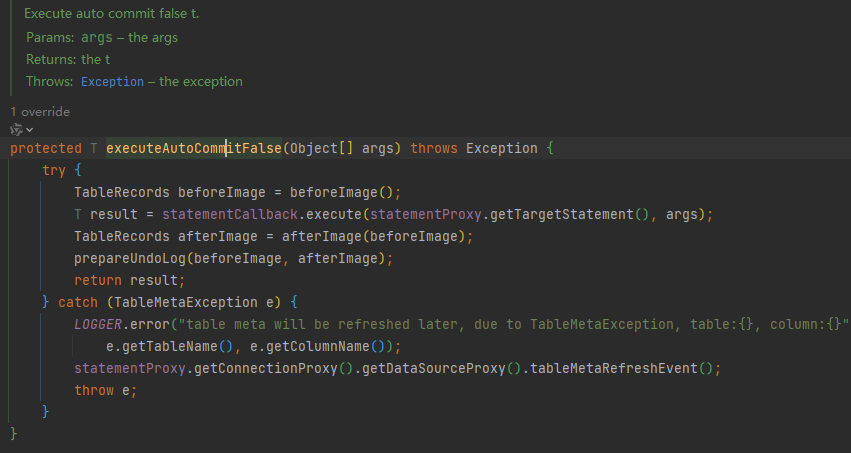
statementCallback.execute会在执行业务sql的前后添加镜像,首先看beforeImage,还是以update为例,beforeImage记录更新之前的数据,在更新之前会先查询表结构,获得当前事务表的所有列及索引,
但是这里查询结构不是通过information_schema.tables,以stock_tbl 为例执行的sql为SELECT * FROM stock_tbl LIMIT 1,再通过ResultSetMetaData以及DatabaseMetaData可以获得当前表的所有列及索引,当然这不是每次执行都必须的,只有第一次会查询limit 1语句,后续会放入本地缓存caffeine中,然后根据where条件以及索引来生成查询语句,执行查询得到记录生成beforeImage
SELECT id, count FROM stock_tbl WHERE commodity_code = ? FOR UPDATE
然后执行业务代码,执行完成之后生成afterImage,通过beforeImage和afterImage生成undolog
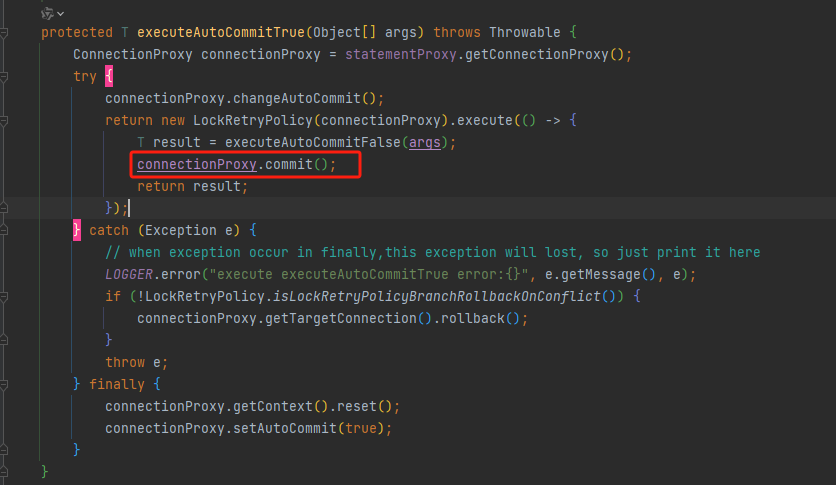
然后执行代理类的事务提交,在提交的时候也大有来头,首先向TM注入分支,
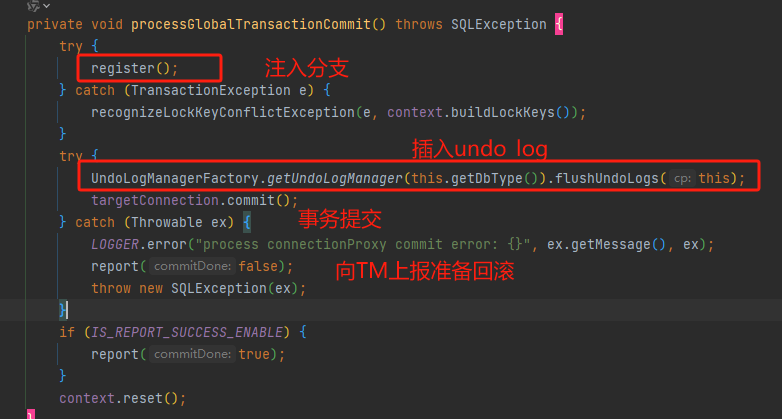
然后会插入undo_log,这个Insert会加入当前事务,可以通过 select * from performance_schema.data_locks 查看当前锁

如果在commit当前本地事务的时候发生异常,会上报给TM,会立马进行回滚本地事务,
二阶段—提交
当所有一阶段执行完成之后,由TM开始提交全局事务,TransactionalTemplate#execute
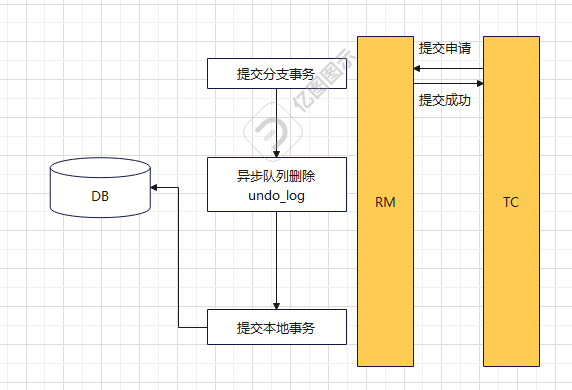
然后TC会向RM发起分支提交请求,在AbstractNettyRemoting#processMessage收到消息之后进行分支的提交,在异步任务提交的时候,AsyncWorker#dealWithGroupedContexts 同时会删除undo_log日志,
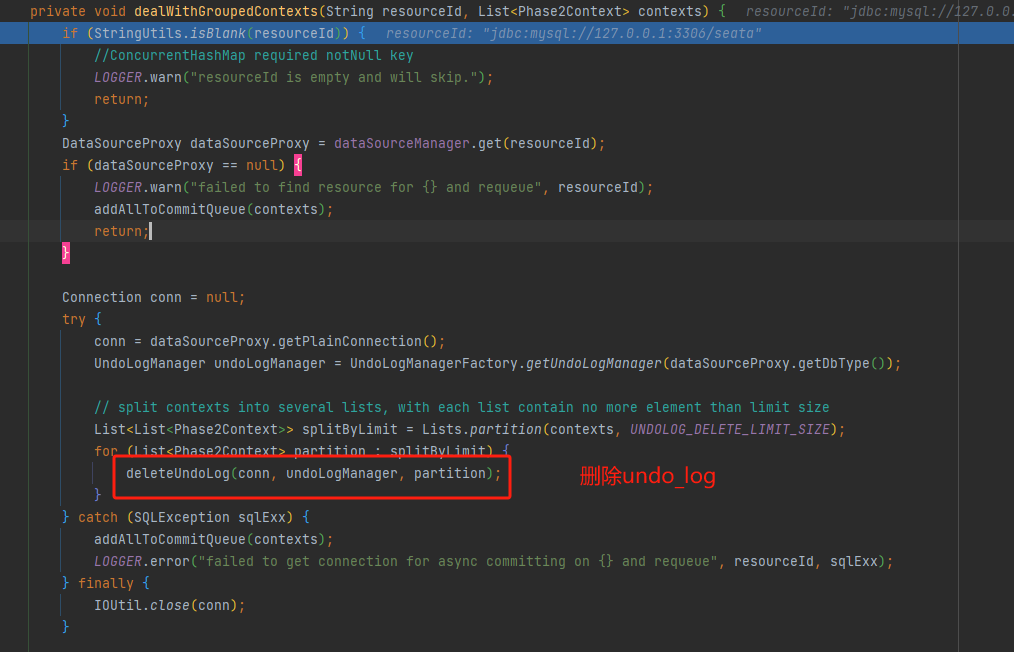
至此,提交完事务,整个流程就结束了
二阶段-回滚
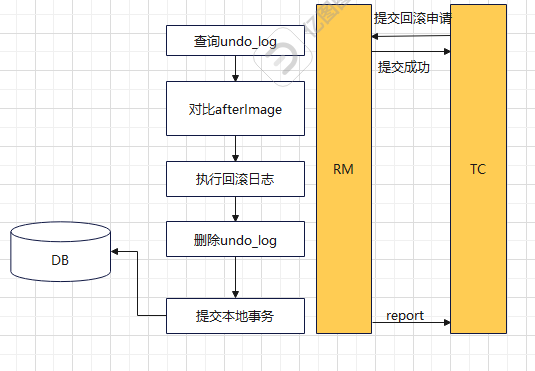
如果执行过程中发生了满足条件的异常,TM会向TC发送异常回滚的请求,收到TC回滚请求的RM通过XID与branchId查找undoLog
DataSourceManager#branchRollback
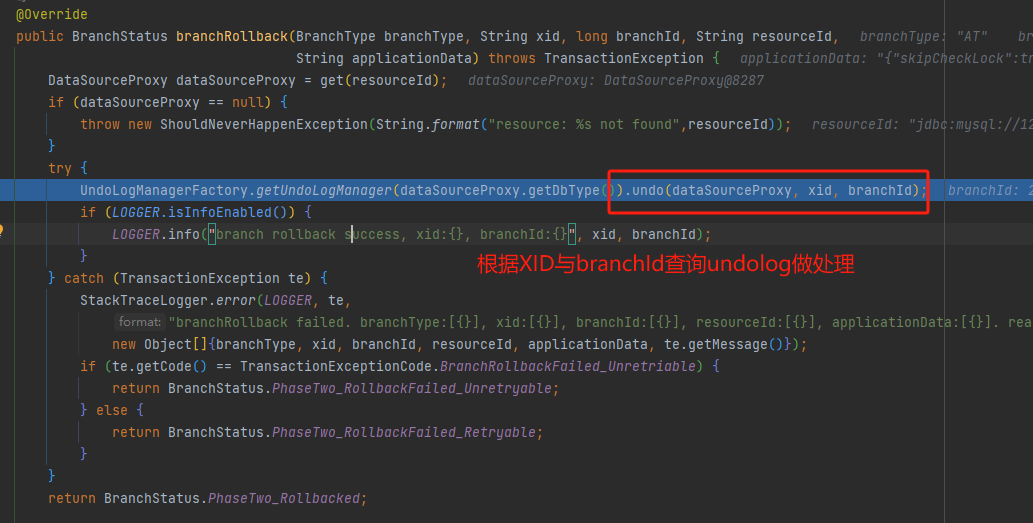
会拿到后镜像与当前数据进行做对比,如果一致,说明被当前事务之外的操作做了处理,如果不一致生成回滚sql,并且删除当前undolog,提交事务并将结果上报给TC
题外话
mysql查看当前事务
select * from information_schema.innodb_trx
mysql查看当前锁信息
select * from performance_schema.data_locks
如果项目使用Mybatis等其他JPA框架,原理同上 因为最终都是通过DataSource获取代理之后的Connection

