
Elasticsearch使用terms聚合之后进行分页排序
引言
elasticsearch中实现聚合也非常常见,同时es的数据量一般比较大,因此聚合结果比较多,像terms聚合默认只返回10条聚合结果,所以聚合之后进行分页,也是非常常见的操作。
es的terms聚合只能传入需要聚合的field和需要聚合返回的条数size,可能一开始我们只能通过将size设置为较大一些,获取全部的聚合结果之后再进行代码手动分页,其实大可不必这样,es的管道聚合中就有bucket_sort针对聚合之后的桶进行分页排序
我们看官方的介绍:

父管道聚合,对其父多桶聚合之后的桶进行排序,可以指定零个或者多个排序字段以及相应的排序顺序,每个bucket可以根据_key或者_count对其子聚合进行排序,此外,可以设置from和size以截取存储的桶,也就算我们所需要的分页。
我们可能发现term聚合中包含参数sort,也可以对聚合之后的桶进行聚合,那么这个order与bucket_sort有什么区别了?官方的介绍:
与所有管道聚合一样,bucket_sort聚合在所有其他非管道聚合之后执行。这意味着排序仅适用于已从父聚合返回的任何bucket。例如,如果父聚合是terms,并且其大小设置为10,则bucket_sort将只对这10个返回的term bucket进行排序。
terms的order是对所有桶进行_key排序或者_count排序,bucket_sort只对terms的size范围内的数据进行_key排序或者_count排序。
参数如下:
sort排序字段
from截取桶起始位置,默认0
size 返回桶数(我们所需要的页数),默认值为父聚合的size
使用bucket_sort的DSL语句
{
"from": 0,
"size": 0,
"query": {
"bool": {
"must": [
]
}
},
"aggs": {
"bucketAgg": {
"terms": {
"field": "extern.paragraph_id",
"size": 1000
},
"aggs": {
"toptop": {
"top_hits": {
"size": 1,
"sort": []
}
},
"bucketSort": {
"bucket_sort": {
"from": 0,
"size": 10,
"sort": []
}
}
}
}
}
}
这里使用ElasticsearchRestTemplate作为第三方连接工具:
java代码使用如下,这里假设我们请求第一页page为2,每页10条size为10,所有from为 (2 - 1 )*10 = 10,size为10
// 桶排序聚合
BucketSortPipelineAggregationBuilder bucketSortAggregation = PipelineAggregatorBuilders.bucketSort(
paragraphBucketSortAggName, Lists.emptyList()).from((page - 1) * size).size(size);
terms聚合,添加子聚合bucketSortAggregation,因为我们已经知道需要的页数和条数,所以这个地方的size我们不必设置为较大的默认值,而是当前页数的最后一条记录,为(page - 1) * size + size = page * size
TermsAggregationBuilder termsAggregationBuilder =
terms(chapterTermsAggName).field("extern.paragraph_id").size(page * size).order(bucketOrders)
.subAggregation(bucketSortAggregation)
最后需要分页的时候我们发现总条数即总的桶数没法获取呀,这时候我们可以使用指标聚合cardinality
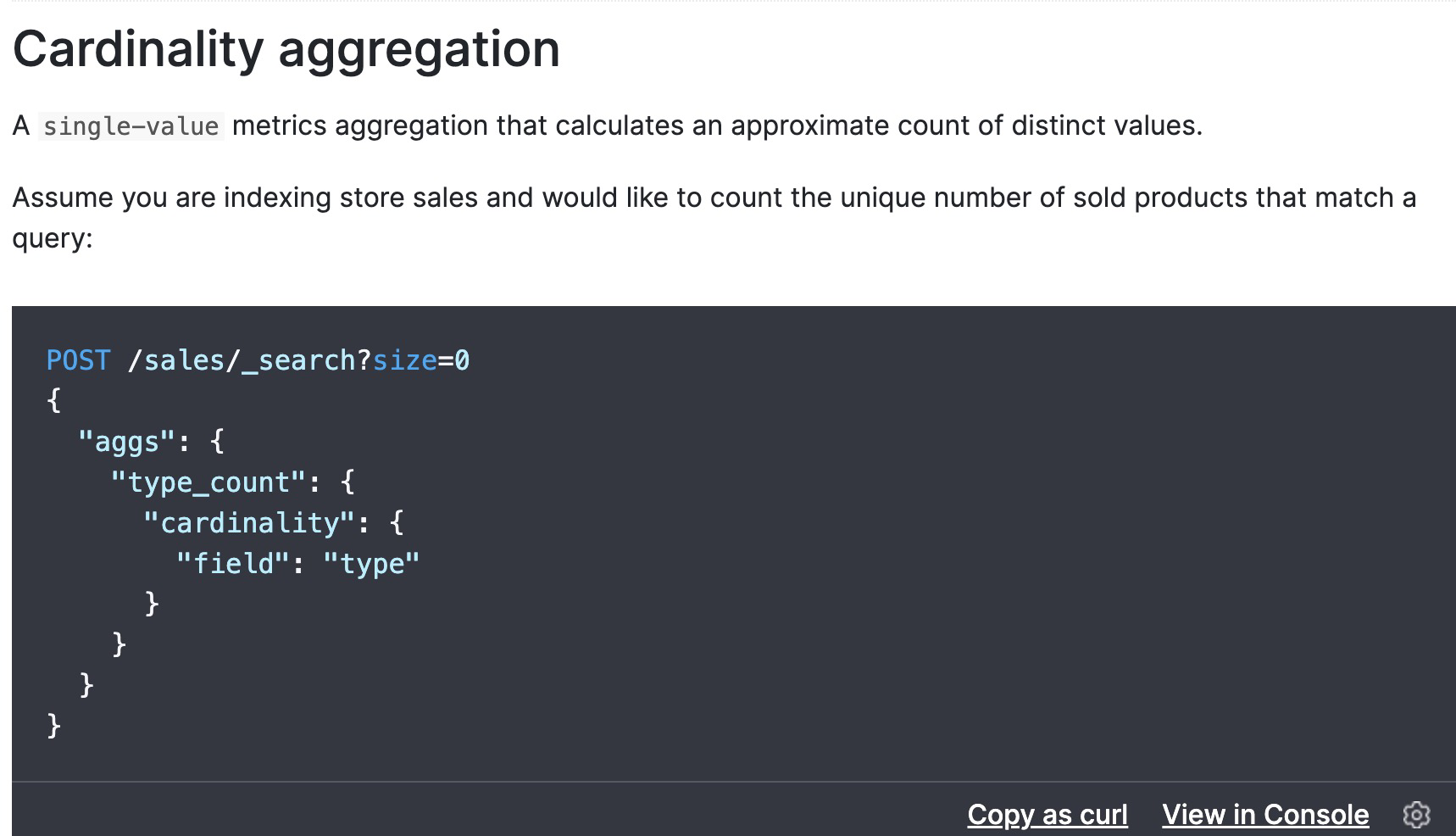
因为cardinality可以统计query不同字段的值,我们只需要将cardinality的field与terms聚合的字段相同就可以得到所有的桶数,
因为一个桶聚合可以同时添加多个指标聚合,java代码实现如下:
CardinalityAggregationBuilder cardinalityAggregation = cardinality(paragraphCardinalityAggName)
.field("extern.paragraph_id");
ArrayList<BucketOrder> bucketOrders = Lists.newArrayList(BucketOrder.count(false), BucketOrder.key(true));
TermsAggregationBuilder termsAggregationBuilder =
terms(chapterTermsAggName).field("extern.paragraph_id").size(page * size).order(bucketOrders)
.subAggregation(bucketSortAggregation).subAggregation(topHitsAggregation);
最后通过分页工具就可以实现分页之后返回的数据
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withPageable(Pageable.unpaged())
.addAggregation(termsAggregationBuilder)
.addAggregation(cardinalityAggregation)
.build();
terms聚合并且分页的DSL语句如下:
{
"from": 0,
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"bucketAgg": {
"terms": {
"field": "extern.paragraph_id",
"size": 8
},
"aggs": {
"bucketSort": {
"bucket_sort": {
"from": 1,
"size": 4,
"sort": []
}
}
}
},
"countAgg": {
"cardinality": {
"field": "extern.paragraph_id"
}
}
}
}
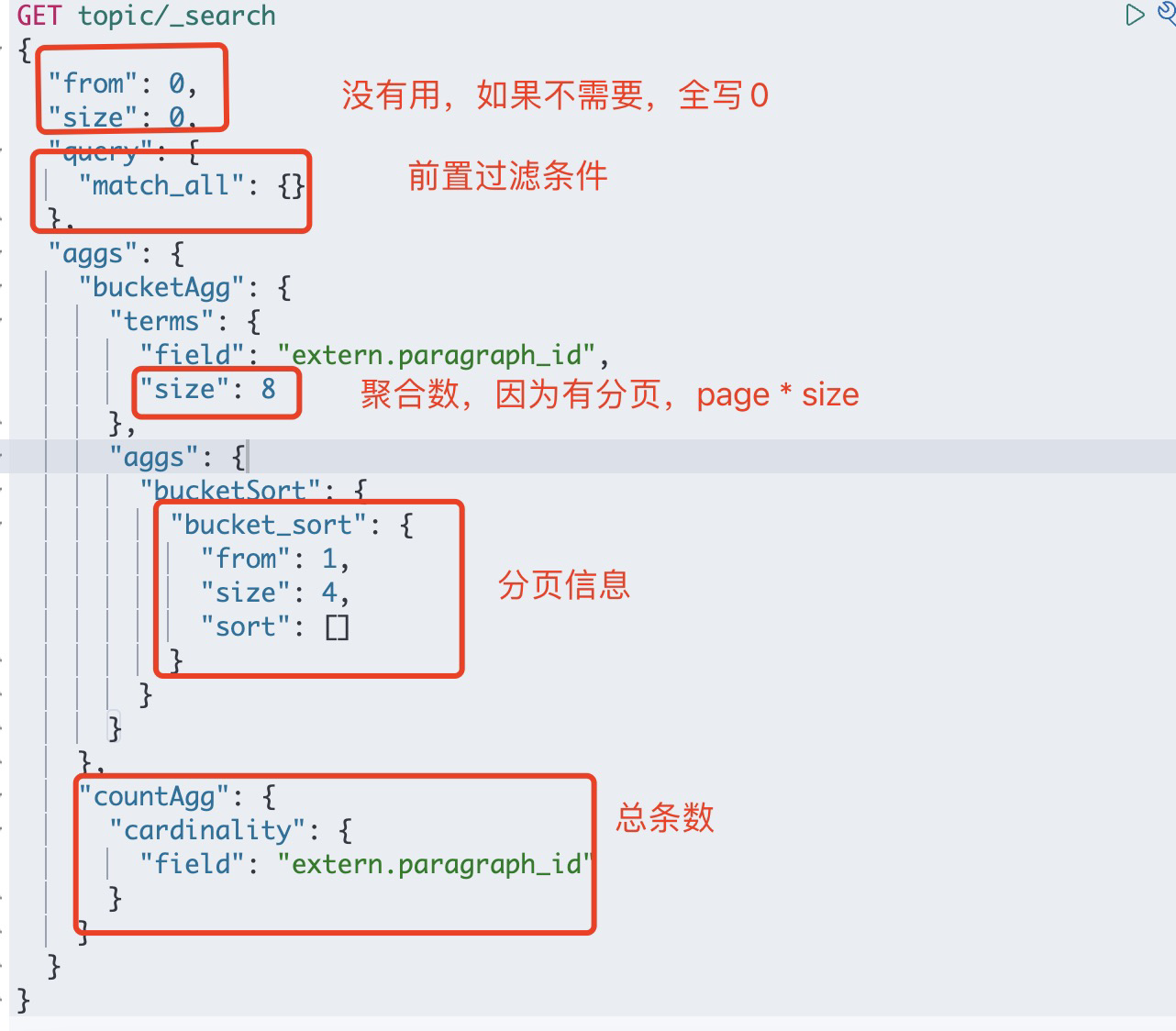
聚合之后的结果如图

至此分页就完成了。
这里如果需要查询出桶内经过排序之后的最新几条记录,可以使用指标聚合top_hits,
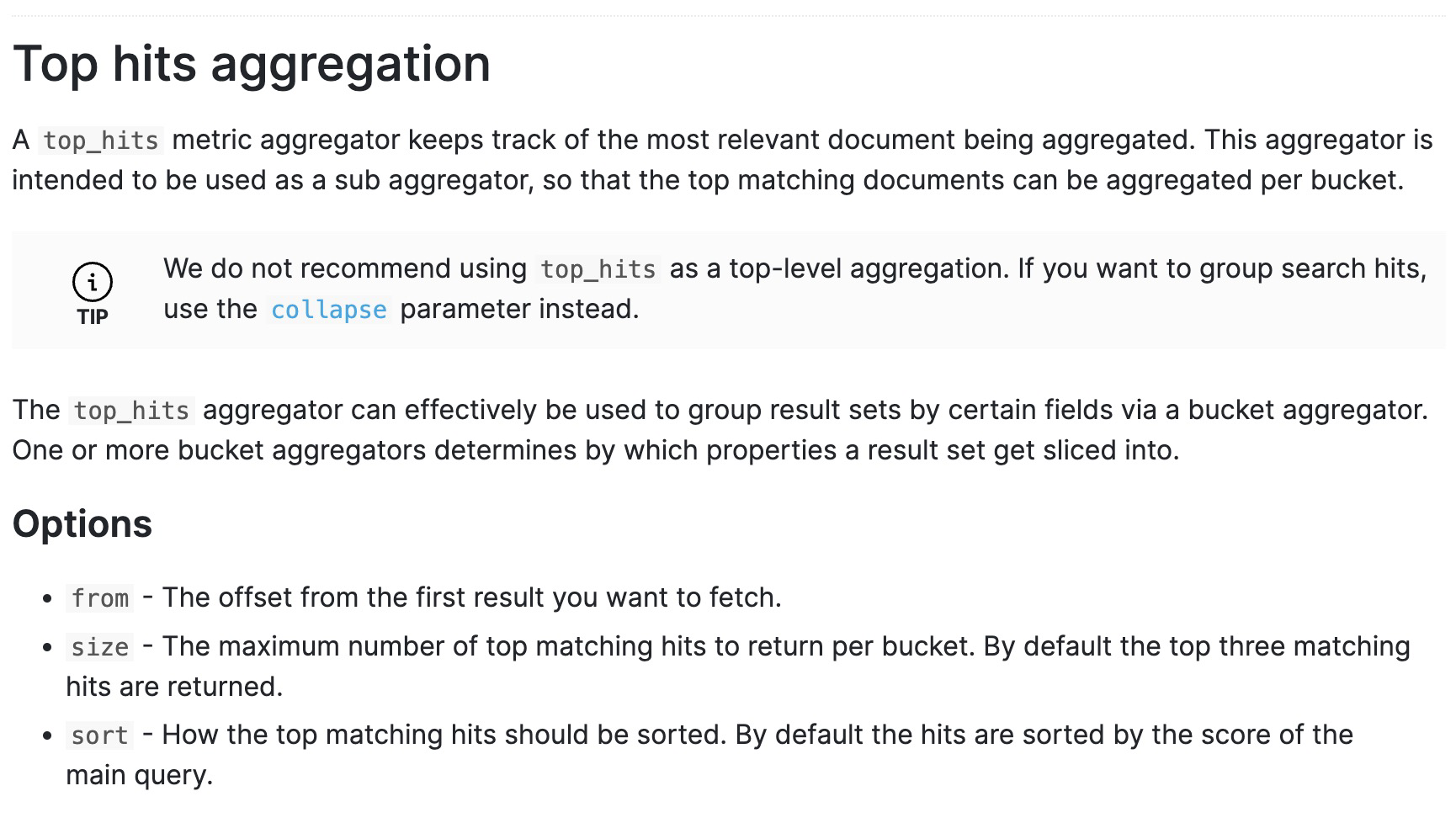
返回桶内经过排序的最近几条记录,比如这里我们需要最新的一条记录,java代码实现
TopHitsAggregationBuilder topHitsAggregation = AggregationBuilders.topHits(topHitsAggName).size(1);
topHitsAggregation.sort(getAuthorSortBuilder(SortOrder.DESC));
topHitsAggregation.sort(getTopicLikeSortBuilder(SortOrder.DESC));
topHitsAggregation.sort(getTopicLikeSortBuilder(SortOrder.DESC));

这里经过tophits之后返回的数据不能直接转为实体,所有我们写一个公用工具类进行转换
package com.bukeneng.ugc.utiils;
import cn.hutool.json.JSONUtil;
import org.elasticsearch.search.SearchHits;
/**
*
* @author liufuqiang
*/
public class SearchHitsUtil {
private SearchHitsUtil() {}
public static long getTotalCount(SearchHits searchHits) {
return searchHits.getTotalHits().value;
}
public static <T> T getSourceAsEntity(String sourceAsString, Class<T> clazz) {
return JSONUtil.toBean(sourceAsString, clazz, true);
}
}
调用:
获取对象
T t = SearchHitsUtil.getSourceAsEntity(topHit.getSourceAsString, T.class);
获取总条数
long totalCount = SearchHitsUtil.getTotalCount(hits);
参考文档
https://www.elastic.co/guide/en/elasticsearch/reference/8.4/search-aggregations-bucket.html

