
ElasticSearch聚合之管道聚合(Pipeline Aggregation)
管道聚合
让上一步聚合的结果作为下一个聚合的输入,类似stream()流的操作,当不上终结操作时,每次操作的流都作为下次操作的输入
管道类型有很多种不同类型,每种类型都与其他聚合计算不同的信息,但是可以将这些类型分为两类
- 父级 父级聚合的输出提供了一组管道聚合,它可以计算新的存储桶或新的聚合以添加到现有存储桶中
- 兄弟 同级聚合的输出提供管道,并且能够计算与该同级聚合处于同一级别的新聚合
管道聚合可以通过使用bucket_path参数来指示到所需度量的路径,从而引用执行计算所需的聚合。定义这些路径的语法可以在下面的bucket_path语法部分中找到。
比如前置聚合为Bucket聚合,后置聚合为Metric聚合,它可以成为一类管道,进而出现了xxxbucket如Maxbucket,在我们使用中,管道聚合也不少数
大多数管道聚合需要另一个聚合作为其输入。输入聚合通过bucket_path参数定义,该参数遵循特定格式:
AGG_SEPARATOR = `>` ;
METRIC_SEPARATOR = `.` ;
AGG_NAME = <the name of the aggregation> ;
METRIC = <the name of the metric (in case of multi-value metrics aggregation)> ;
MULTIBUCKET_KEY = `[<KEY_NAME>]`
PATH = <AGG_NAME><MULTIBUCKET_KEY>? (<AGG_SEPARATOR>, <AGG_NAME> )* ( <METRIC_SEPARATOR>, <METRIC> ) ;
下面介绍使用次数最多的管道排序
Bucket sort聚合
语法
{
"bucket_sort": {
"sort": [
{ "sort_field_1": { "order": "asc" } },
{ "sort_field_2": { "order": "desc" } },
"sort_field_3"
],
"from": 1,
"size": 3
}
}
父管道聚合,对其父多桶聚合的桶进行排序。可以指定零个或多个排序字段以及相应的排序顺序。
每个桶可以基于其_key、_count或其子聚合进行排序。此外,可以设置参数from和size,以截断结果桶。
我们发现桶排序terms聚合只能根据_key或者根据_count来进行排序,我们可以将聚合之后的桶作为Bucket sort的输入来实现桶之间的排序,也可以实现分页
例如下面查询每个帖子类型按照发帖人数聚合
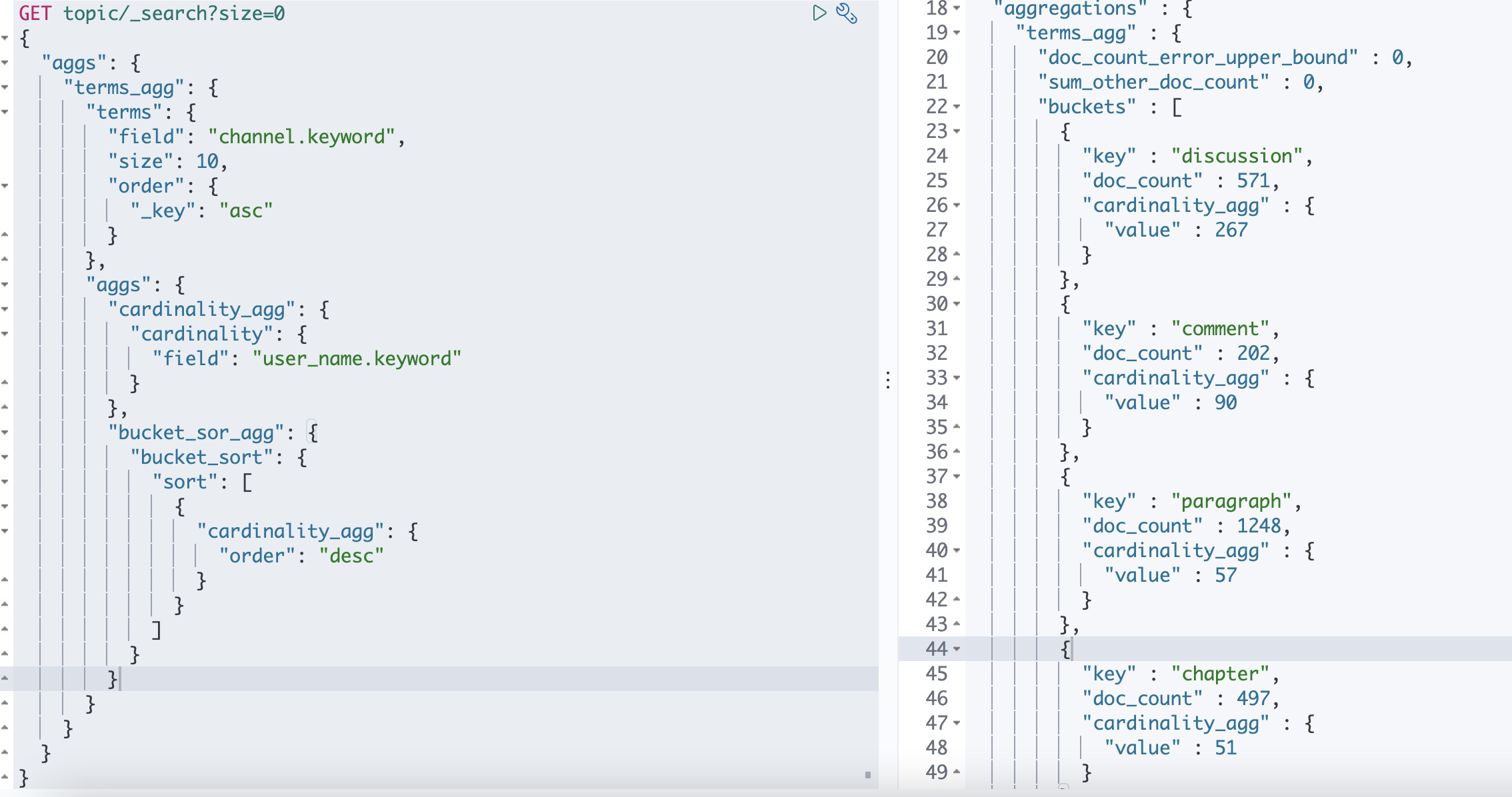
也可以使用这种聚合来截断结果桶,而不进行任何排序。为此,只需使用from和/或size参数,而不指定排序。
参数介绍
sort 自定义排序
from 位于设定值之前位置的桶将被截断。
size 要返回的桶数。默认为父聚合的所有存储桶。
参考文档
elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号