
ElasticSearch聚合之指标聚合(Metric Aggregations)
介绍
桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档需要一些指标的计算。分桶是一种达到的目的的手段,它提供了一种给文档分组的方法来让我们可以计算感兴趣的指标
大多数指标是指简单的数学运算(例如最小值、最大值、平均值、汇总等),这些都是通过文档的值计算,
指标聚合一般用于桶聚合之后进行数值分析,当然也可以直接使用指标聚合,但是指标聚合之后结果分为单指聚合和多值聚合,不可以再继续聚合,否则会报aggregation_initialization_exception异常
cannot accept sub-aggregations,类似Stream流的count()、max()、collect()等终结操作,会结束关闭流。
指标聚合大概有20多种,
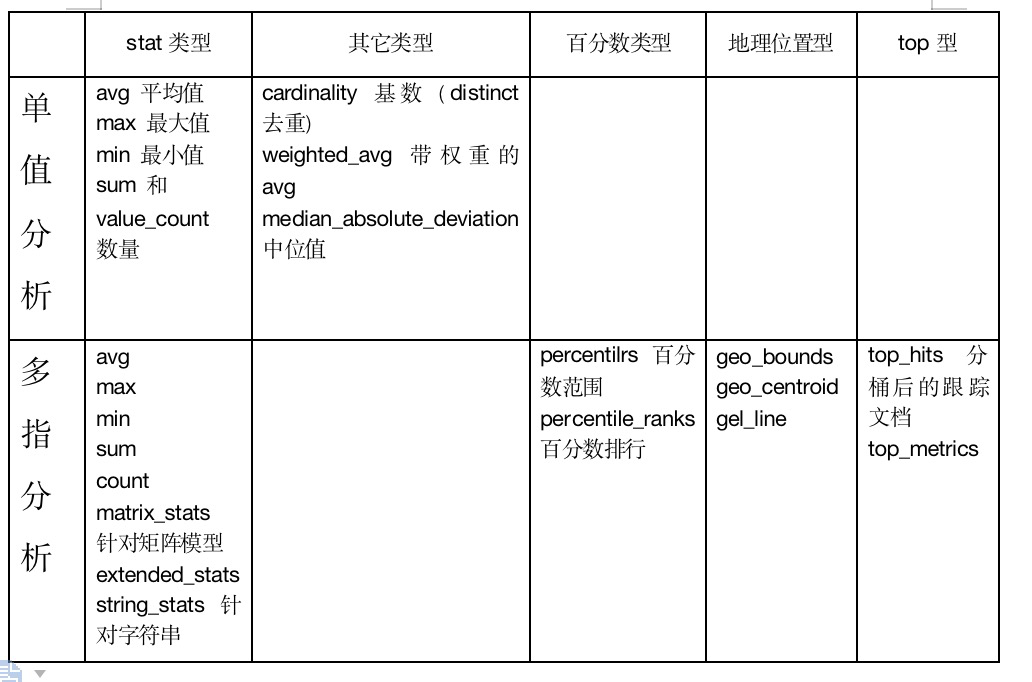
- 从分类上看:Metric分为单指聚合和多值聚合两种
- 从功能上来看:根据具体应用场景,如地理位置,百分数等
下面根据使用程序罗列几种经常使用的指标聚合
Avg聚合
平均值聚合,属于单指聚合,计算从聚合文档中提取的数值的平均值,
例如每个帖子都有一个热度值,我们用这个可以来计算全部帖子的平均热度

java代码实现
public void aggregations() {
final String aggName = "score_avg";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
AvgAggregationBuilder agg = AggregationBuilders.avg(aggName).field("score");
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedAvg aggregation = aggregations.get(aggName);
double avg = aggregation.getValue();
}
参数介绍
missing
却是参数定义了如何处理缺失值的文档,,默认情况下,会将这个文档进行忽略,但也可以将他们视为具体指。
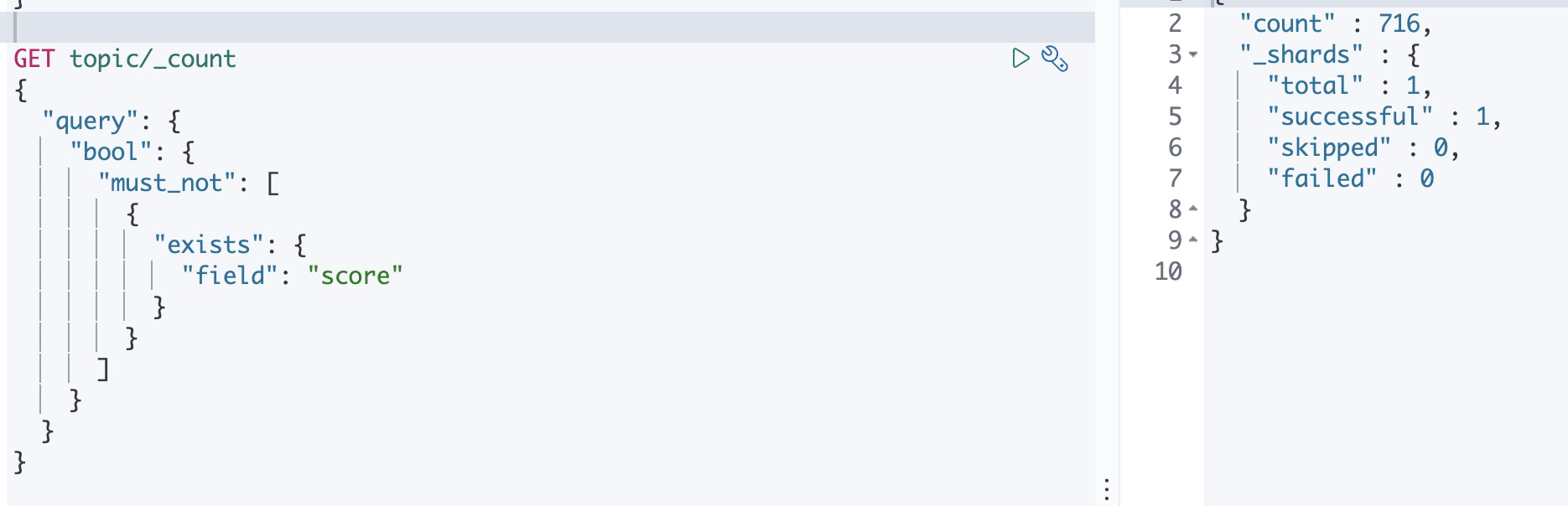
可以看到有700多个文档没有这个字段,因为是计算平均值,如果没有这个字段,我们可以将缺失这个字段的文档设置一个缺省值,为了演示效果,我们设置为1000

可以看到平均值瞬间提升了好多,missing字段生效
AvgAggregationBuilder agg = AggregationBuilders.avg(aggName).field("score").missing(10000);
Max、Min聚合
最大值聚合,属于单指聚合,跟踪并返回从聚合文档中提取的数值的最大值/最小值

计算帖子的最高热度值
public void aggregations() {
final String aggName = "score_max";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
MaxAggregationBuilder agg = AggregationBuilders.max(aggName).field("score").missing(10000);
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedMax aggregation = aggregations.get(aggName);
double avg = aggregation.getValue();
}
参数桶avg
Sum聚合
单值聚合,汇总从聚合文档提取的数值,这些值可以从字段或者script来获取

public void aggregations() {
final String aggName = "score_sum";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
SumAggregationBuilder agg = AggregationBuilders.sum(aggName).field("score").missing(10000);
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedSum aggregation = aggregations.get(aggName);
double avg = aggregation.getValue();
}
参数同avg
value_count聚合
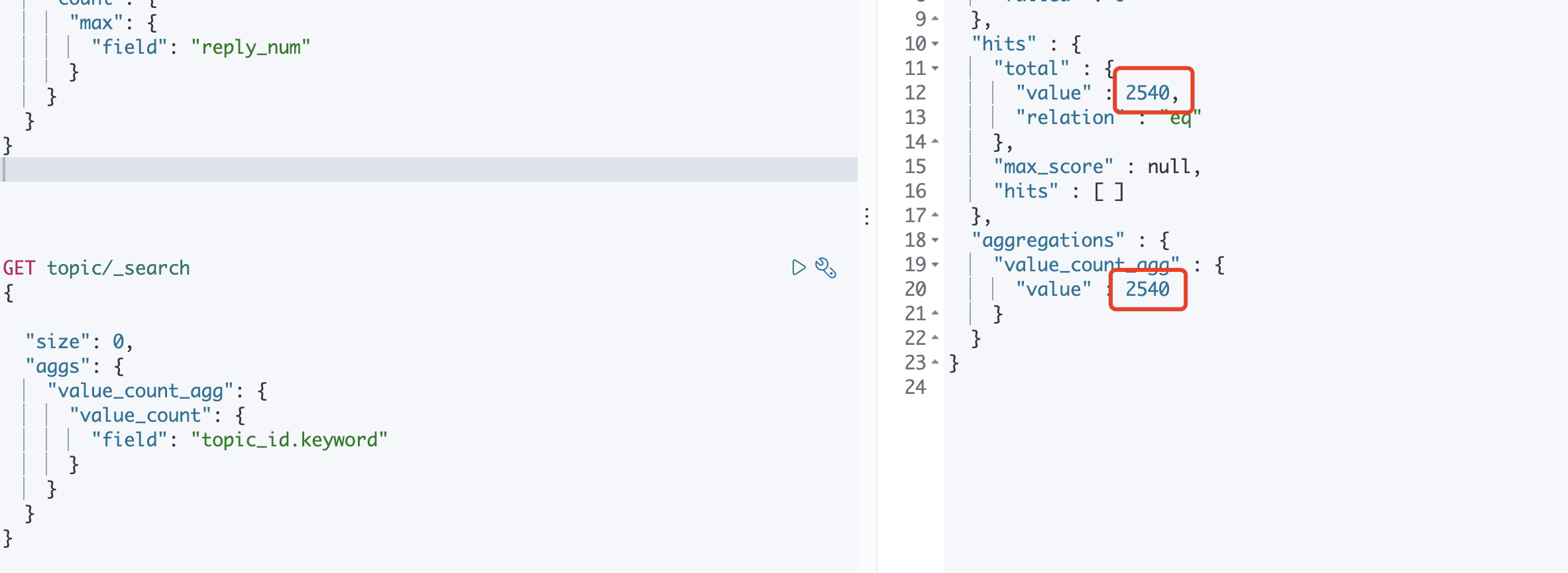
单值聚合,用于统计从聚合文档中提取值的数量,这些值可以从文档中特定字段提取,也可以由脚本提供,通常,此聚合器与其他单指聚合一起使用,
value_count不会去除重复值,因此每个字段有重复值,每个值也将单独计数
如果没有其他聚合,只有value_count聚合,那么结果值与查询结果集hits的总文档数一致
public void aggregations() {
final String aggName = "score_count";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
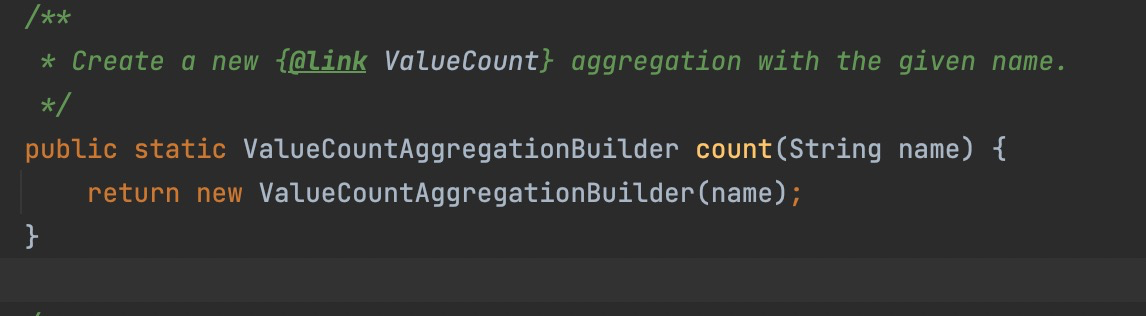
ValueCountAggregationBuilder agg = AggregationBuilders.count(aggName);
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedValueCount aggregation = aggregations.get(aggName);
long avg = aggregation.getValue();
}
注意这里直接使用.count()方法
Cardinality聚合
单值聚合,计算不同值的近似计数的单值度量聚合,可以看成value_count + distinct
例如计算话题底下的发帖人数
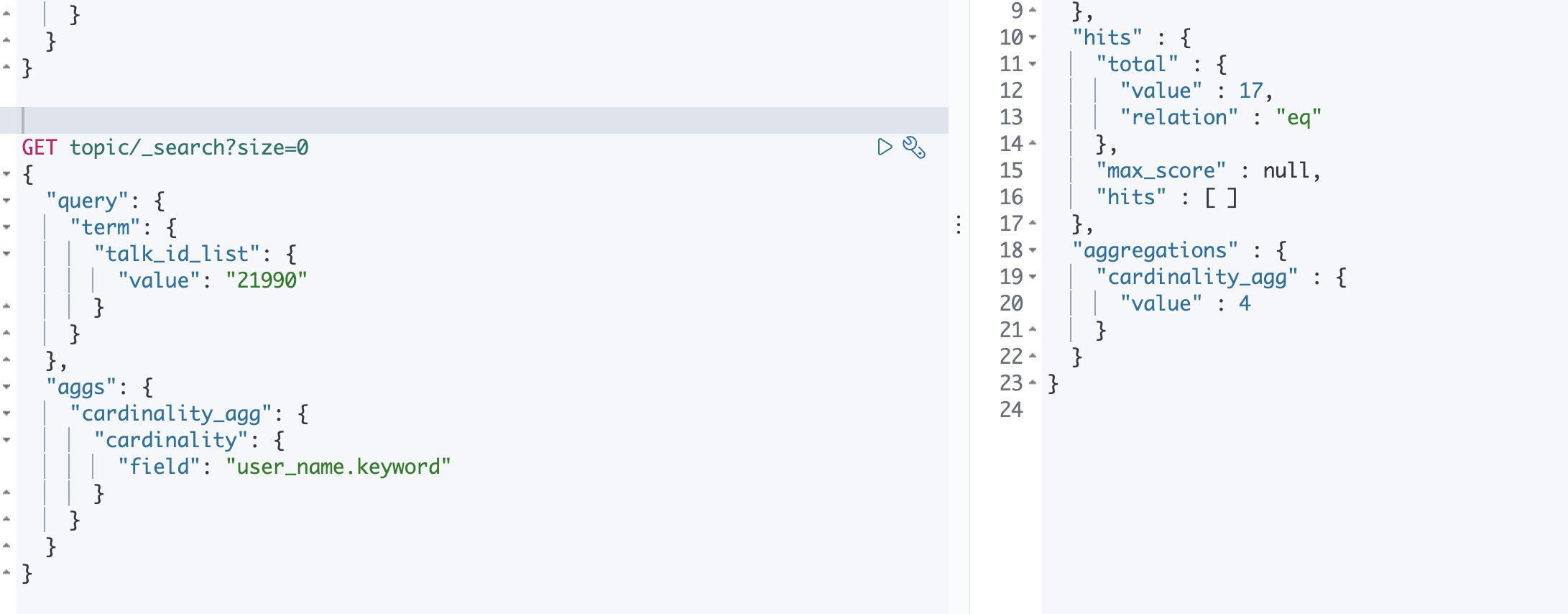
参数介绍
precision_threshold
精确阈值,precision_threshold参数允许以内存换取准确性,并定义了一个唯一的计数,低于该计数时,预计接近准确。高于此值时,计数可能变得更加模糊,支持的最大数为40000,默认值为3000
以这个例子为例,假如聚合的结果为13988,但是实际展示的时候可能展示个粗略,比如该话题超过1w人参与讨论,那么此时可以添加这个参数,设置值为10000,超过10000的值我们可以粗略统计
missing
缺失参数定义了如何处理缺失值的文档,默认情况下,他们将被忽略,但也可以将他们视为具体指
public void aggregations() {
final String aggName = "cardinality_agg";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
CardinalityAggregationBuilder agg = cardinality(aggName).precisionThreshold(10000);
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedCardinality aggregation = aggregations.get(aggName);
long avg = aggregation.getValue();
}
stats聚合
多值聚合,计算从聚合文档中提取的数值的统计信息,前面sum、max、min、avg、count如果都想要返回怎么办,一个一个写肯定很麻烦,stats聚合包含了sum、max、min、avg、count聚合的所有结果

参数介绍
missing 同上
public void aggregations() {
final String aggName = "stats_agg";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
StatsAggregationBuilder agg = AggregationBuilders.stats(aggName).field("score");
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedStats aggregation = aggregations.get(aggName);
aggregation.getAvg();
aggregation.getCount();
aggregation.getMax();
aggregation.getMin();
aggregation.getSum();
}
top_hits聚合
top_hits聚合跟踪正在聚合的最相关的文档,该聚合器旨在用作子聚合器,以便每个bucket聚合最匹配的文档
一般用于最厚层级的聚合,来跟踪最近聚合的文档结果,
例如查询每个类型帖子下面热度最高的一个帖子
GET topic/_search?size=0
{
"aggs": {
"tersm_agg": {
"terms": {
"field": "channel.keyword",
"size": 1,
"order": {
"_count": "desc"
}
},
"aggs": {
"top_hits_agg": {
"top_hits": {
"from": 0,
"size": 1,
"sort": [
{
"score": {
"order": "desc"
}
}
]
}
}
}
}
}
}
返回结果
"aggregations" : {
"tersm_agg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 1292,
"buckets" : [
{
"key" : "paragraph",
"doc_count" : 1248,
"top_hits_agg" : {
"hits" : {
"total" : {
"value" : 1248,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "topic",
"_type" : "_doc",
"_id" : "2877",
"_score" : null,
"_source" : {
帖子信息
},
"sort" : [
40.0
]
}
]
}
}
}
]
}
}
参数介绍
from
第一个结果的偏移量
size
每个桶返回的最大匹配命中数。默认情况下,返回前三个匹配的命中
sort
返回文档进行排序,默认按照主查询的score进行排序
public void aggregations() {
final String aggName = "terms_agg";
final String subAggName = "top_hits_agg";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
TopHitsAggregationBuilder subAggregation =
AggregationBuilders.topHits(subAggName).from(0).size(1).sort(SortBuilders.fieldSort("score").order(SortOrder.DESC));
TermsAggregationBuilder agg =
terms(aggName).field("channel.keyword").size(1).order(BucketOrder.count(false))
.subAggregation(subAggregation);
NativeSearchQuery query = queryBuilder.addAggregation(agg).build();
SearchHits<TopicDTO> search = esRestTemplate.search(query, TopicDTO.class);
Aggregations aggregations = search.getAggregations();
ParsedStringTerms aggregation = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = aggregation.getBuckets();
for (Terms.Bucket bucket : buckets) {
Aggregations aggregations1 = bucket.getAggregations();
ParsedTopHits aggregation1 = aggregations1.get(subAggName);
org.elasticsearch.search.SearchHits hits = aggregation1.getHits();
...
}
}
参考文档
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号