
Redis操作HyperLogLog
介绍
如果我们遇到这样一个业务,也是HyperLogLog最常用的用法之一,需要统计某个页面的UV,统计每天的数据,如果统计PV的话我们好办,直接一个key一直自增就可以了,但是统计UV我们首先会想到统计每个用户并且每一天,所以会一天一个key,去重再使用set就可以了,当有请求过来时我们直接sadd存入用户的ID,需要统计时用scard取出这个集合的个数,这个数就是这个页面的uv,这样也没什么问题,也是一个非常简单的实现方案。
但是我们如果需要某个爆款页面的UV了,访问量几千万很大的几个页面进行统计,那么这样使用set来存储所占用的空间是非常惊人的,100W和101W这两个数字对于统计结果来说区别并不是很大,
所以,Redsi提供了HyperLogLog数据结构就是解决这种统计问题的,HyperLogLog提供不精准的去重计数方案,虽然不是特别精准,但是也不是那么不精准,标准误差为0.81%,这种准度已经满足统计UV这种需求了。
HyperLogLog数据结构用于计算集合中唯一元素的个数,只需要少量恒定内存,每个结构占用12字节,统计的标准误差容错率为0.81%
命令
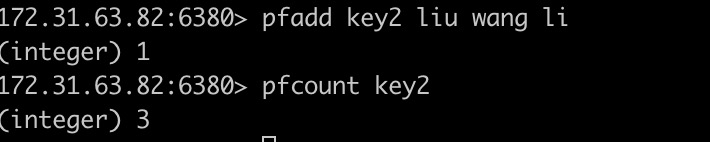
1、 pfadd
> PFADD key [element [element ...]]
将所有元素添加存储在HyperLogLog数据结构的key中,
如果HyperLogLog估计的近似计数在执行后发生变化,返回值为1,否则返回值为0,如果指定的键不存在,Redis会自动创建一个HyperLogLog数据结构

如果在添加的时候没有元素,只有key值,当key值不存在的时候新建HyperLogLog数据结构,返回1,否则返回0
2、 pfcount
> PFCOUNT key [key ...]
当使用单个key时,返回存储在指定变量中HyperLogLog数据结构计算的近似计数,如果变量不存在,返回0;
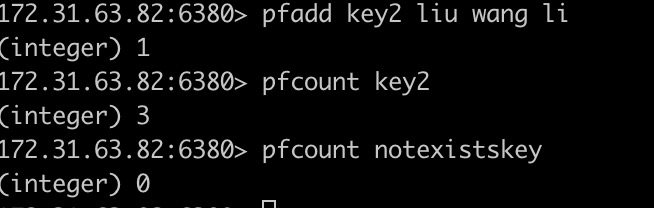
当参数为多个key时,返回内部存储的多个HyperLogLog数据结构合并为一个临时HyperLogLog并返回近似基数。

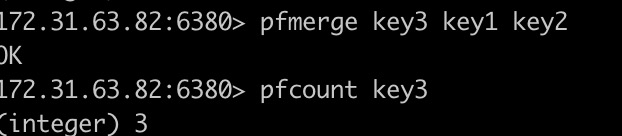
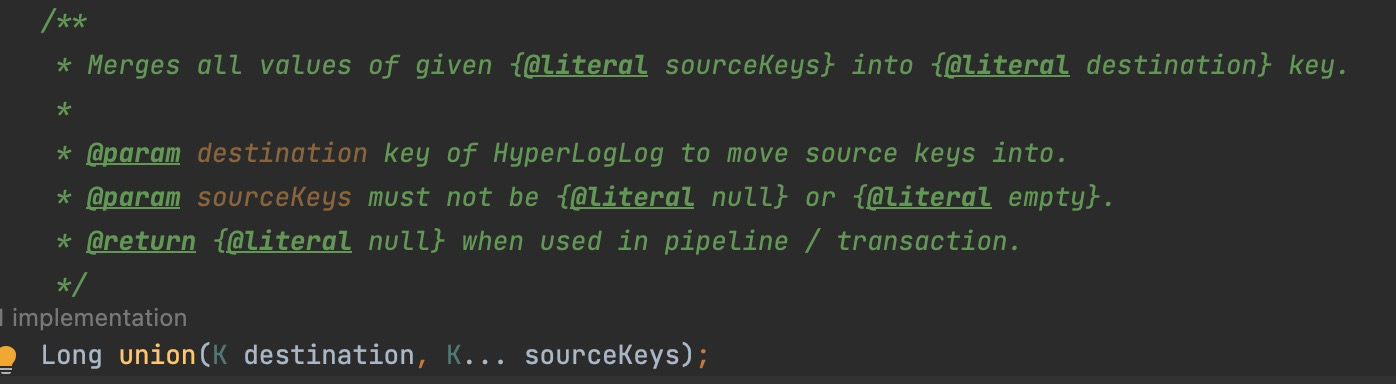
3、 pfmerge
> PFMERGE destkey sourcekey [sourcekey ...]
将多个HyperLogLog数据结构合并为一个唯一的值,该值近似与sourcekey对应的计数的并集,计算出的合并之后的HyperLogLog将被设置为目标变量destkey,如果destkey不存在,则会新创建数据结构,如果destkey存在,那么这个集合会被视为源集合之一,其计数包含在计算的destkey计数中。
它是HyperLogLog数据结构的发明人Philippe Flajolet的首字母缩写,

如统计某本书的浏览次数
ugcRedisTemplate.opsForHyperLogLog().add(booId), userName);
当基数存在时返回0,不存在时返回1
查询数量
ugcRedisTemplate.opsForHyperLogLog().size(key)
> 参考文档
https://redis.io/commands/
《Redis深度历险——核心原理和应用实践》
