k8s中部署 zookeeper kafka集群部署
#
| 主机名 | 系统版本 | IP地址 | cpu/内存/磁盘 | 用途 | 软件版本 |
|---|---|---|---|---|---|
| k8s_nfs | CentOS7.5 | 172.16.1.60 | 2核/2GB/60GB | zookeeper、kafka的nfs存储 | nfs-utils-1.3.0-0.68 |
| k8s-master1 | CentOS7.5 | 172.16.1.81 | 2核/2GB/60GB | kubernetes master1节点 | k8s v1.20.0 |
| k8s-master2 | CentOS7.5 | 172.16.1.82 | 2核/2GB/60GB | kubernetes master2节点 | k8s v1.20.0 |
| k8s-node1 | CentOS7.5 | 172.16.1.83 | 4核/8GB/60GB | kubernetes node1节点 | k8s v1.20.0 |
| k8s-node2 | CentOS7.5 | 172.16.1.84 | 4核/8GB/60GB | kubernetes node2节点 | k8s v1.20.0 |
补充: kubernetes集群的控制节点我打了污点不能被pod调度使用。
zookeeper镜像: guglecontainers/kubernetes-zookeeper:1.0-3.4.10 对应版本: zookeeper-3.4.10
kafka镜像: cloudtrackinc/kubernetes-kafka:0.10.0.1 对应版本: kafka_2.11-0.10.0.1

1 nfs服务部署
节点: k8s_nfs
用途: k8s pod 数据持久化存储
说明: nfs服务的搭建过程不再赘述
验证:
[root@k8s_nfs ~]# ls /ifs/kubernetes/
kafka zk
# 注: kafka目录用于存储kafka的数据,zk目录用于存储zookeeper的数据。
[root@k8s_nfs ~]# showmount -e 172.16.1.60
Export list for 172.16.1.60:
/ifs/kubernetes *
2 nfs-subdir-external-provisioner插件部署
节点: kubernetes集群
用途: 为中间件pod提供pvc自动供给
注意: 在部署前需要在k8s各个节点上部署nfs的客户端(yum install nfs-utils -y),否则无法部署成功。
项目:
(1) github项目地址: https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
(2) 下载 deploy 目录如下文件
class.yaml、deployment.yaml、rbac.yaml
# 可以根据需要修改三个配置文件
配置文件说明:
(1) 创建命名空间
[root@k8s-master1 ~]# kubectl create namespace zk-kafka
(2) 部署文件说明
[root@k8s-master1 zk-kafka-nfs]# ls -l /root/zk-kafka-nfs/
total 20
# kafka集群的storageclass
-rw-r--r-- 1 root root 392 Feb 21 17:09 class_kafka.yaml
# zk集群的storageclass
-rw-r--r-- 1 root root 386 Feb 21 17:08 class_zk.yaml
# kafka集群的nfs-client-provisioner
-rw-r--r-- 1 root root 1355 Feb 21 17:07 deployment_kafka.yaml
# zk集群的nfs-client-provisioner
-rw-r--r-- 1 root root 1325 Feb 21 17:03 deployment_zk.yaml
# nfs的rbac
-rw-r--r-- 1 root root 1905 Feb 21 15:52 rbac.yaml
说明: zk、kafka都在zk-kafka命名空间,共用一套rbac,class、deployment命名不同。
(3) rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zk-kafka
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zk-kafka
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zk-kafka
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zk-kafka
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: zk-kafka
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
(4) deployment_zk.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner-zk
labels:
app: nfs-client-provisioner-zk
# replace with namespace where provisioner is deployed
namespace: zk-kafka
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner-zk
template:
metadata:
labels:
app: nfs-client-provisioner-zk
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner-zk
#image: k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
image: registry.cn-hangzhou.aliyuncs.com/k8s-image01/nfs-subdir-external-provisione:v4.0.1
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner-zk
- name: NFS_SERVER
value: 172.16.1.60 # 修改为nfs服务器地址
- name: NFS_PATH
value: /ifs/kubernetes/zk # 修改为nfs共享目录
volumes:
- name: nfs-client-root
nfs:
server: 172.16.1.60 # 修改为nfs服务器地址
path: /ifs/kubernetes/zk # 修改为nfs共享目录
(5) deployment_kafka.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner-kafka
labels:
app: nfs-client-provisioner-kafka
# replace with namespace where provisioner is deployed
namespace: zk-kafka
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner-kafka
template:
metadata:
labels:
app: nfs-client-provisioner-kafka
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner-kafka
#image: k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
image: registry.cn-hangzhou.aliyuncs.com/k8s-image01/nfs-subdir-external-provisione:v4.0.1
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner-kafka
- name: NFS_SERVER
value: 172.16.1.60 # 修改为nfs服务器地址
- name: NFS_PATH
value: /ifs/kubernetes/kafka # 修改为nfs共享目录
volumes:
- name: nfs-client-root
nfs:
server: 172.16.1.60 # 修改为nfs服务器地址
path: /ifs/kubernetes/kafka # 修改为nfs共享目录
(6) class_zk.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage-zk # pv 动态供给插件名称
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner-zk # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "true" # 修改删除pv后,自动创建的nfs共享目录不被删除。默认false,即删除
(7) class_kafka.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage-kafka # pv 动态供给插件名称
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner-kafka # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "true" # 修改删除pv后,自动创建的nfs共享目录不被删除。默认false,即删除
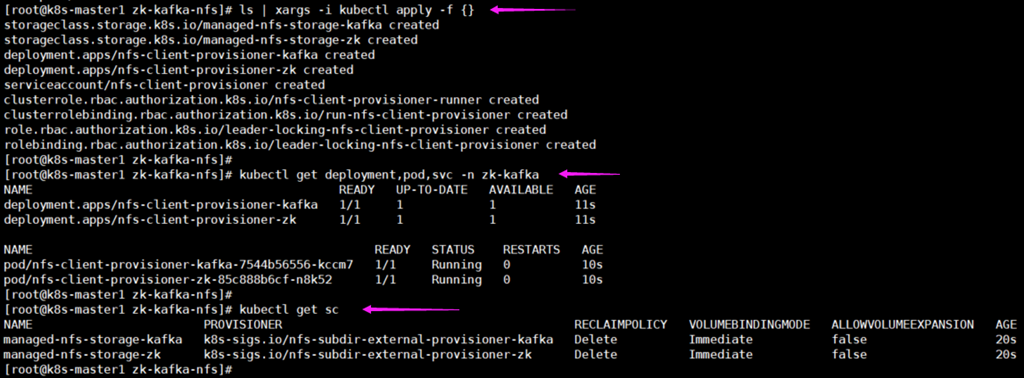
(8) 部署yaml文件并查看信息
[root@k8s-master1 zk-kafka-nfs]# ls | xargs -i kubectl apply -f {}
[root@k8s-master1 zk-kafka-nfs]# kubectl get deployment,pod,svc -n zk-kafka
[root@k8s-master1 zk-kafka-nfs]# kubectl get sc


2 zookeeper、kafka说明#
1 Kafka和zookeeper是两种典型的有状态的应用集群服务。首先kafka和zookeeper都需要存储盘来保存有状态信息;其次kafka和zookeeper每
一个实例都需要有对应的实例Id(Kafka需broker.id, zookeeper需要my.id)来作为集群内部每个成员的标识,集群内节点之间进行内部通信时需
要用到这些标识。
2 对于这类服务的部署,需要解决两个大的问题,一个是状态保存,另一个是集群管理(多服务实例管理)。kubernetes中的StatefulSet方便了有
状态集群服务的部署和管理。通常来说,通过下面三个手段来实现有状态集群服务的部署。
(1) 通过Init Container来做集群的初始化工作。
(2) 通过Headless Service来维持集群成员的稳定关系。
(3) 通过Persistent Volume和Persistent Volume Claim提供网络存储来持久化数据。
因此,在K8S集群里面部署类似kafka、zookeeper这种有状态的服务,不能使用Deployment,必须使用StatefulSet来部署,有状态简单来说就
是需要持久化数据,比如日志、数据库数据、服务状态等。
3 StatefulSet应用场景
(1) 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现。
(2) 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现。
(3) 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(即从0到N-1,在下一个Pod运行之前所有之前的
Pod必须都是Running和Ready状态),基于init containers来实现有序收缩,有序删除(即从N-1到0)。
4 StatefulSet组成
用于定义网络标志(DNS domain)的Headless Service。
用于创建PersistentVolumes的volumeClaimTemplates。
定义具体应用的StatefulSet。
5 StatefulSet中每个Pod的DNS格式
<statefulSetName-{0..N-1}>.<serviceName>.<namespace>.svc.cluster.local
(1) statefulSetName为StatefulSet的名字,0..N-1为Pod所在的序号,从0开始到N-1。
(2) serviceName为Headless Service的名字。
(3) namespace为服务所在的namespace,Headless Servic和StatefulSet必须在相同的namespace。
(4) svc.cluster.local为K8S的Cluster Domain集群根域。
3 zookeeper集群部署#
3.1 yaml配置文件
1 参考文档
https://kubernetes.io/zh/docs/tutorials/stateful-application/zookeeper/
2 zk-cluster.yml
zookeeper有三个端口,2181、3888、2888,三个端口的作用为:
(1) 2181 # 为client端提供服务的端口
(2) 3888 # 选举leader使用的端口
(3) 2888 # 集群内节点间通讯的端口
[root@k8s-master1 ~]# mkdir -p zk-kafka-cluster
[root@k8s-master1 ~]# cd zk-kafka-cluster/
[root@k8s-master1 zk-kafka-cluster]# cat zk-cluster.yml
apiVersion: v1
kind: Service
metadata:
namespace: zk-kafka
name: zk-hs
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
namespace: zk-kafka
name: zk-cs
labels:
app: zk
spec:
#type: NodePort
ports:
- port: 2181
targetPort: 2181
name: client
#nodePort: 32181
selector:
app: zk
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
namespace: zk-kafka
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: zk-kafka
name: zk
spec:
serviceName: zk-hs
replicas: 3
selector:
matchLabels:
app: zk
template:
metadata:
labels:
app: zk
spec:
containers:
- name: kubernetes-zookeeper
imagePullPolicy: Always
image: registry.cn-hangzhou.aliyuncs.com/k8s-image01/kubernetes-zookeeper:1.0-3.4.10
resources:
requests:
memory: "1024Mi"
cpu: "500m"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
volumeClaimTemplates:
- metadata:
name: datadir
#annotations:
# volume.beta.kubernetes.io/storage-class: "zk-nfs-storage"
spec:
storageClassName: "managed-nfs-storage-zk"
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
3.2 部署
1 应用yml文件
[root@k8s-master1 zk-kafka-cluster]# kubectl apply -f zk-cluster.yml
service/zk-hs created
service/zk-cs created
poddisruptionbudget.policy/zk-pdb created
statefulset.apps/zk created
2 查看zk集群的pod
[root@k8s-master1 zk-kafka-cluster]# kubectl get pod -n zk-kafka -l app=zk

3 查看zk集群的svc
[root@k8s-master1 zk-kafka-cluster]# kubectl get svc,ep -n zk-kafka

4 查看zk集群的pvc、pv
PVC是namespace命名空间级别的,查询时需要跟"-n 命名空间",PV是集群级别的,查询时可以不需要跟"-n 命名空间"。
[root@k8s-master1 zk-kafka-cluster]# kubectl get pvc -n zk-kafka
[root@k8s-master1 zk-kafka-cluster]# kubectl get pv

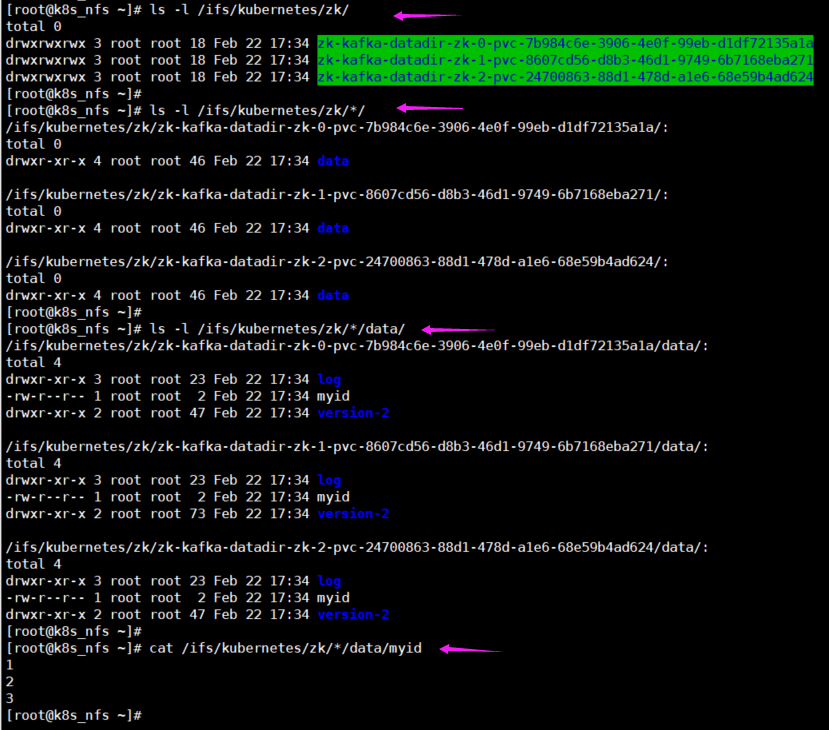
5 查看zk集群的nfs持久化共享目录
可以发现,NFS的持久化目录名称组成为,<namespace名称>-<PVC名称>-<PV名称>,只要PVC和PV不删除,这个持久化目录名称就不会变。
[root@k8s_nfs ~]# ls -l /ifs/kubernetes/zk/
[root@k8s_nfs ~]# ls -l /ifs/kubernetes/zk/*/
[root@k8s_nfs ~]# ls -l /ifs/kubernetes/zk/*/data/
[root@k8s_nfs ~]# cat /ifs/kubernetes/zk/*/data/myid

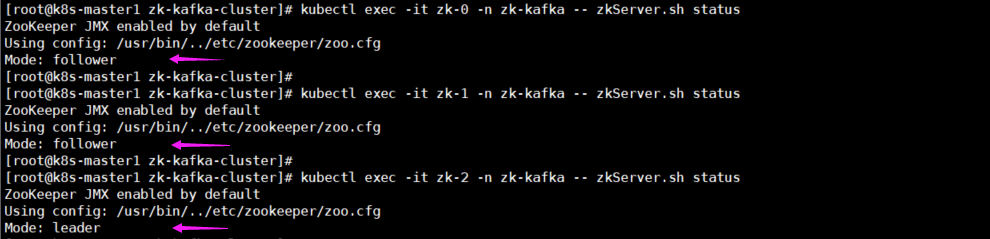
6 查看zk集群的主从关系
[root@k8s-master1 zk-kafka-cluster]# kubectl exec -it zk-0 -n zk-kafka -- zkServer.sh status
[root@k8s-master1 zk-kafka-cluster]# kubectl exec -it zk-1 -n zk-kafka -- zkServer.sh status
[root@k8s-master1 zk-kafka-cluster]# kubectl exec -it zk-2 -n zk-kafka -- zkServer.sh status

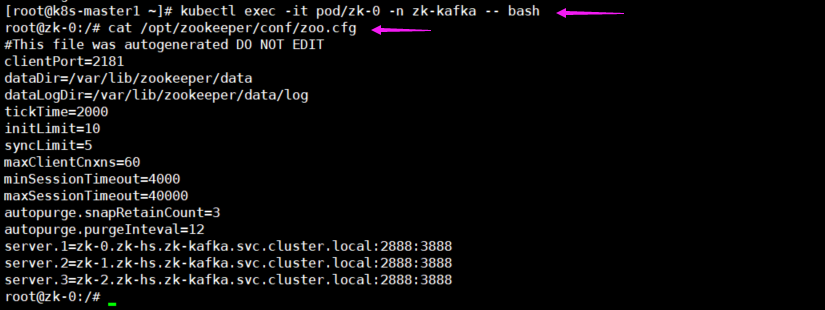
7 查看zk集群的配置文件
[root@k8s-master1 ~]# kubectl exec -it pod/zk-0 -n zk-kafka -- bash
root@zk-0:/# cat /opt/zookeeper/conf/zoo.cfg

3.3 验证zk集群的连接
[root@k8s-master1 zk-kafka-cluster]# kubectl get svc -n zk-kafka
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
zk-cs ClusterIP 172.28.20.31 <none> 2181/TCP 79m
zk-hs ClusterIP None <none> 2888/TCP,3888/TCP 79m
[root@k8s-master1 zk-kafka-cluster]#
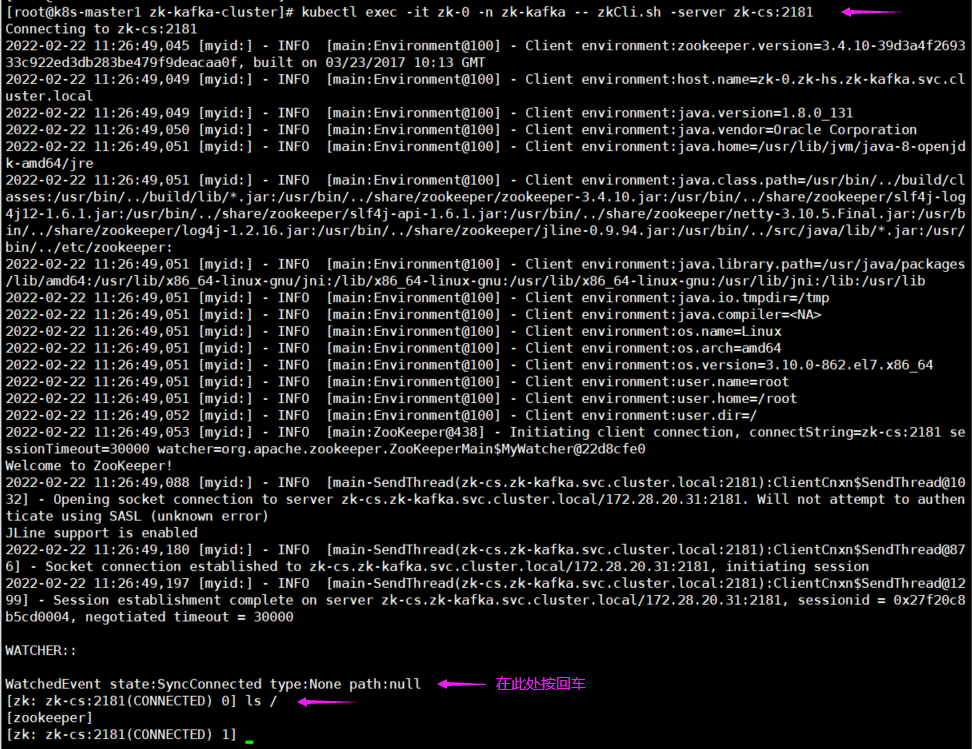
zookeeper集群连接方式:
zk-cs:2181
zk-0.zk-hs.zk-kafka.svc.cluster.local:2181
zk-1.zk-hs.zk-kafka.svc.cluster.local:2181
zk-2.zk-hs.zk-kafka.svc.cluster.local:2181
[root@k8s-master1 zk-kafka-cluster]# kubectl exec -it zk-0 -n zk-kafka -- zkCli.sh -server zk-cs:2181

4 kafka集群部署#
4.1 yaml配置文件
[root@k8s-master1 zk-kafka-cluster]# cat kafka-cluster.yml apiVersion: v1 kind: Service metadata: namespace: zk-kafka name: kafka-cs labels: app: kafka spec: #type: NodePort clusterIP: None ports: - port: 9092 targetPort: 9092 name: client #nodePort: 32092 selector: app: kafka --- apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: kafka-pdb namespace: zk-kafka spec: selector: matchLabels: app: kafka minAvailable: 2 --- apiVersion: apps/v1 kind: StatefulSet metadata: namespace: zk-kafka name: kafka spec: serviceName: kafka-cs replicas: 3 selector: matchLabels: app: kafka template: metadata: labels: app: kafka spec: containers: - name: k8s-kafka imagePullPolicy: IfNotPresent image: cloudtrackinc/kubernetes-kafka:0.10.0.1 ports: - containerPort: 9092 name: client resources: requests: memory: "1024Mi" cpu: "500m" command: - sh - -c - "exec /opt/kafka_2.11-0.10.0.1/bin/kafka-server-start.sh /opt/kafka_2.11-0.10.0.1/config/server.properties --override broker.id=${HOSTNAME##*-} \ --override listeners=PLAINTEXT://:9092 \ --override zookeeper.connect=zk-0.zk-hs.zk-kafka.svc.cluster.local:2181,zk-1.zk-hs.zk-kafka.svc.cluster.local:2181,zk-2.zk-hs.zk-kafka.svc.cluster.local:2181 \ --override log.dirs=/var/lib/kafka \ --override auto.create.topics.enable=true \ --override auto.leader.rebalance.enable=true \ --override background.threads=10 \ --override compression.type=producer \ --override delete.topic.enable=true \ --override leader.imbalance.check.interval.seconds=300 \ --override leader.imbalance.per.broker.percentage=10 \ --override log.flush.interval.messages=9223372036854775807 \ --override log.flush.offset.checkpoint.interval.ms=60000 \ --override log.flush.scheduler.interval.ms=9223372036854775807 \ --override log.retention.bytes=-1 \ --override log.retention.hours=168 \ --override log.roll.hours=168 \ --override log.roll.jitter.hours=0 \ --override log.segment.bytes=1073741824 \ --override log.segment.delete.delay.ms=60000 \ --override message.max.bytes=1000012 \ --override min.insync.replicas=1 \ --override num.io.threads=8 \ --override num.network.threads=3 \ --override num.recovery.threads.per.data.dir=1 \ --override num.replica.fetchers=1 \ --override offset.metadata.max.bytes=4096 \ --override offsets.commit.required.acks=-1 \ --override offsets.commit.timeout.ms=5000 \ --override offsets.load.buffer.size=5242880 \ --override offsets.retention.check.interval.ms=600000 \ --override offsets.retention.minutes=1440 \ --override offsets.topic.compression.codec=0 \ --override offsets.topic.num.partitions=50 \ --override offsets.topic.replication.factor=3 \ --override offsets.topic.segment.bytes=104857600 \ --override queued.max.requests=500 \ --override quota.consumer.default=9223372036854775807 \ --override quota.producer.default=9223372036854775807 \ --override replica.fetch.min.bytes=1 \ --override replica.fetch.wait.max.ms=500 \ --override replica.high.watermark.checkpoint.interval.ms=5000 \ --override replica.lag.time.max.ms=10000 \ --override replica.socket.receive.buffer.bytes=65536 \ --override replica.socket.timeout.ms=30000 \ --override request.timeout.ms=30000 \ --override socket.receive.buffer.bytes=102400 \ --override socket.request.max.bytes=104857600 \ --override socket.send.buffer.bytes=102400 \ --override unclean.leader.election.enable=true \ --override zookeeper.session.timeout.ms=6000 \ --override zookeeper.set.acl=false \ --override broker.id.generation.enable=true \ --override connections.max.idle.ms=600000 \ --override controlled.shutdown.enable=true \ --override controlled.shutdown.max.retries=3 \ --override controlled.shutdown.retry.backoff.ms=5000 \ --override controller.socket.timeout.ms=30000 \ --override default.replication.factor=1 \ --override fetch.purgatory.purge.interval.requests=1000 \ --override group.max.session.timeout.ms=300000 \ --override group.min.session.timeout.ms=6000 \ --override log.cleaner.backoff.ms=15000 \ --override log.cleaner.dedupe.buffer.size=134217728 \ --override log.cleaner.delete.retention.ms=86400000 \ --override log.cleaner.enable=true \ --override log.cleaner.io.buffer.load.factor=0.9 \ --override log.cleaner.io.buffer.size=524288 \ --override log.cleaner.io.max.bytes.per.second=1.7976931348623157E308 \ --override log.cleaner.min.cleanable.ratio=0.5 \ --override log.cleaner.min.compaction.lag.ms=0 \ --override log.cleaner.threads=1 \ --override log.cleanup.policy=delete \ --override log.index.interval.bytes=4096 \ --override log.index.size.max.bytes=10485760 \ --override log.message.timestamp.difference.max.ms=9223372036854775807 \ --override log.message.timestamp.type=CreateTime \ --override log.preallocate=false \ --override log.retention.check.interval.ms=300000 \ --override max.connections.per.ip=2147483647 \ --override num.partitions=1 \ --override producer.purgatory.purge.interval.requests=1000 \ --override replica.fetch.backoff.ms=1000 \ --override replica.fetch.max.bytes=1048576 \ --override replica.fetch.response.max.bytes=10485760 \ --override reserved.broker.max.id=1000 " env: - name: KAFKA_HEAP_OPTS value : "-Xmx512M -Xms512M" - name: KAFKA_OPTS value: "-Dlogging.level=INFO" volumeMounts: - name: datadir mountPath: /var/lib/kafka lifecycle: postStart: exec: command: ["/bin/sh","-c","touch /tmp/health"] livenessProbe: exec: command: ["test","-e","/tmp/health"] initialDelaySeconds: 5 timeoutSeconds: 5 periodSeconds: 10 readinessProbe: tcpSocket: port: client initialDelaySeconds: 15 timeoutSeconds: 5 periodSeconds: 20 volumeClaimTemplates: - metadata: name: datadir #annotations: # volume.beta.kubernetes.io/storage-class: "kafka-nfs-storage" spec: storageClassName: "managed-nfs-storage-kafka" accessModes: - ReadWriteMany resources: requests: storage: 10Gi
4.2 部署
1 应用配置文件
[root@k8s-master1 zk-kafka-cluster]# kubectl apply -f kafka-cluster.yml
service/kafka-cs created
poddisruptionbudget.policy/kafka-pdb created
statefulset.apps/kafka created
2 查看kafka集群的pod
[root@k8s-master1 zk-kafka-cluster]# kubectl get pod -n zk-kafka

3 查看kafka集群的pvc
[root@k8s-master1 zk-kafka-cluster]# kubectl get pvc -n zk-kafka

4 查看kafka集群的pv
[root@k8s-master1 zk-kafka-cluster]# kubectl get pv

5 查看kafka集群的svc
[root@k8s-master1 zk-kafka-cluster]# kubectl get svc,ep -n zk-kafka

6 查看kafka集群的nfs持久化存储目录
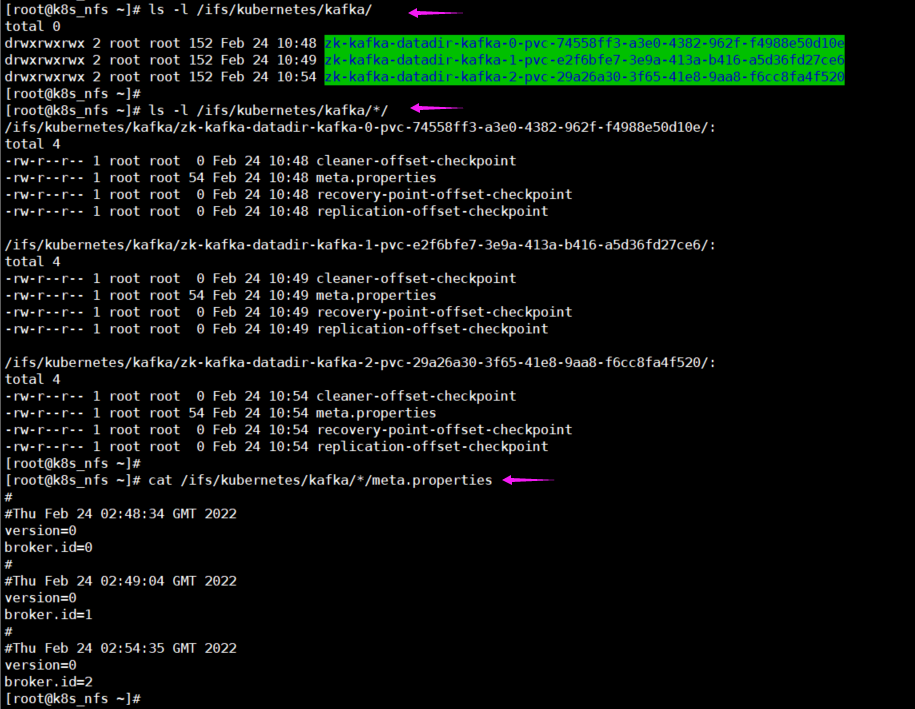
[root@k8s_nfs ~]# ls -l /ifs/kubernetes/kafka/
[root@k8s_nfs ~]# ls -l /ifs/kubernetes/kafka/*/
[root@k8s_nfs ~]# cat /ifs/kubernetes/kafka/*/meta.properties

7 kafka集群内部连接地址
# kubectl run -i --tty --image busybox:1.28.4 dns-test --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kafka-cs.zk-kafka.svc.cluster.local
Server: 172.28.0.2
Address 1: 172.28.0.2 kube-dns.kube-system.svc.cluster.local
Name: kafka-cs.zk-kafka.svc.cluster.local
Address 1: 172.27.36.90 kafka-2.kafka-cs.zk-kafka.svc.cluster.local
Address 2: 172.27.169.156 kafka-0.kafka-cs.zk-kafka.svc.cluster.local
Address 3: 172.27.169.157 kafka-1.kafka-cs.zk-kafka.svc.cluster.local
/ # exit
pod "dns-test" deleted
[root@k8s-master1 zk-kafka-cluster]#
4.3 测试(验证kafka集群数据的生产和消费)
1 说明
(1) zookeeper、kafka的svc信息
[root@k8s-master1 zk-kafka-cluster]# kubectl get svc -n zk-kafka
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka-cs ClusterIP None <none> 9092/TCP 76m
zk-cs ClusterIP 172.28.66.236 <none> 2181/TCP 107m
zk-hs ClusterIP None <none> 2888/TCP,3888/TCP 107m
(2) 客户端访问zookeeper的方式
zk-cs:2181
zk-0.zk-hs.zk-kafka.svc.cluster.local:2181
zk-1.zk-hs.zk-kafka.svc.cluster.local:2181
zk-2.zk-hs.zk-kafka.svc.cluster.local:2181
(3) 客户端访问kafka的方式
kafka-0.kafka-cs.zk-kafka.svc.cluster.local:9092
kafka-1.kafka-cs.zk-kafka.svc.cluster.local:9092
kafka-2.kafka-cs.zk-kafka.svc.cluster.local:9092
2 登录到三个kafka集群中的任意一个kafka的pod容器实例(比如kafka-0节点),进行kafka数据生产
[root@k8s-master1 zk-kafka-cluster]# kubectl exec -it pod/kafka-0 -n zk-kafka -- bash
> cd /opt/kafka_2.11-0.10.0.1/bin/
(1) 创建名称为test的topic
> ./kafka-topics.sh --create \
--topic test \
--zookeeper zk-cs:2181 \
--partitions 3 \
--replication-factor 3
输出信息如下:
Created topic "test".
(2) 查看topic列表
> ./kafka-topics.sh --list --zookeeper zk-cs:2181
输出信息如下:
test
(3) 查看名称为test的topic的描述信息
> ./kafka-topics.sh --describe --zookeeper zk-cs:2181 --topic test
输出信息如下:
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test Partition: 2 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
(4) 在名称为test的topic上生产消息
> ./kafka-console-producer.sh --topic test --broker-list localhost:9092
依次输入如下内容:
1
2
3
3 另起一个窗口,再登录到另外的一个kafka的pod实例,比如kafka-1,验证kafka数据消费
[root@k8s-master1 zk-kafka-cluster]# kubectl exec -it pod/kafka-1 -n zk-kafka -- bash
> cd /opt/kafka_2.11-0.10.0.1/bin/
> ./kafka-console-consumer.sh --topic test --zookeeper zk-cs:2181 --from-beginning
输出内容如下:
1
2
3
4 说明
生产者连接kafka集群,消费者及其它连接zookeeper集群或kafka集群(跟kafka的版本有关,版本高的kafka对zookeeper的依赖就小)。
较低版本kafka: --zookeeper <zookeeper集群>:2181
较高版本kafka: --bootstrap-server <kafka集群>:9092
5 知识拾遗#
5.1 关于亲和性说明
由于我的k8s集群master节点有2台且不允许被pod调度使用,node节点有2台允许被pod调度和使用,不能满足zookeeper、kafka集群pod的
亲和性/反亲和性,所以就删除了这方面的yaml配置,在实际生产中建议加上。
5.2 自定义kafka版本镜像
1 说明 我这里kafka镜像使用的是官方镜像(cloudtrackinc/kubernetes-kafka:0.10.0.1 对应版本为kafka_2.11-0.10.0.1),该版本比较老,如果 想使用较新的kafka版本就需要自定义kafka镜像。 http://kafka.apache.org/downloads.html https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz JDK版本: jdk-8u45-linux-x64.tar.gz 2 Dockerfile文件 # cat Dockerfile FROM centos:7 LABEL maintainer liuchang RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ADD jdk-8u45-linux-x64.tar.gz /usr/local ADD kafka_2.13-2.8.0.tgz /opt RUN ln -s /usr/local/jdk1.8.0_45 /usr/local/jdk && \ ln -s /opt/kafka_2.13-2.8.0 /opt/kafka ENV JAVA_HOME /usr/local/jdk ENV CLASSPATH $JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar ENV PATH $JAVA_HOME/bin:/opt/kafka/bin:$PATH ENV LANG en_US.UTF-8 WORKDIR /opt CMD ["/bin/bash"] 3 构建kafka镜像 [root@k8s-master1 kafka-cluster-image]# ls -l total 238956 -rw-r--r-- 1 root root 464 Feb 24 23:15 Dockerfile -rw-r--r-- 1 root root 173271626 Mar 14 2021 jdk-8u45-linux-x64.tar.gz -rw-r--r-- 1 root root 71403603 Jul 25 2021 kafka_2.13-2.8.0.tgz -rw-r--r-- 1 root root 7048 Feb 24 23:33 kafka-cluster.yml # docker build -t registry.cn-hangzhou.aliyuncs.com/k8s-image01/kafka:2.13-2.8.0 . 说明: 构建完成的镜像我已经上传到了阿里个人镜像库上。 4 部署到k8s集群中进行测试 (1) 修改kafka-cluster.yml文件 1) 修改image如下 image: registry.cn-hangzhou.aliyuncs.com/k8s-image01/kafka:2.13-2.8.0 2) 修改kafka启动命令如下 exec kafka-server-start.sh /opt/kafka/config/server.properties (2) 进行消费者和生产者测试 注意: 由于kafka版本较高,对zookeeper的依赖小,在进行消费者测试时,使用--bootstrap-server参数。 # kafka-console-consumer.sh --topic test --bootstrap-server localhost:9092 --from-beginning
5.3 K8S部署Kafka界面管理工具(kafkamanager)
1 说明 (1) kafka-manager 是雅虎开源的apache-kafka管理工具,是用Scala编写的,可以在web页面进行kafka的相关操作 1) 管理kafka集群 2) 方便集群状态监控(包括topics, consumers, offsets, brokers, replica distribution, partition distribution) 3) 方便选择分区副本 4) 配置分区任务,包括选择使用哪些brokers 5) 可以对分区任务重分配 6) 提供不同的选项来创建及删除topic 7) Topic list会指明哪些topic被删除 8) 批量产生分区任务并且和多个topic和brokers关联 9) 批量运行多个主题对应的多个分区 10) 向已经存在的主题中添加分区 11) 对已经存在的topic修改配置 12) 可以在broker level和topic level的度量中启用JMX polling功能 13) 可以过滤在ZK上没有ids/ owners/offsets/ directories的consumer (2) 开源仓库地址 https://github.com/yahoo/CMAK (3) 下载源码包 https://github.com/yahoo/CMAK/tree/2.0.0.2 https://github.com/yahoo/CMAK/archive/refs/tags/2.0.0.2.tar.gz 要求: Kafka 0.8.. or 0.9.. or 0.10.. or 0.11.. Java 8+ (我这里使用的jdk版本为jdk-8u45-linux-x64.tar.gz) 2 编译 参考文档: https://www.scala-sbt.org/download.html https://www.cnblogs.com/coding-farmer/p/12097519.html 由于编译的依赖包需要FQ,我这里下载别人编译好的包"kafka-manager-2.0.0.2.zip"。 3 修改kafka-manager-2.0.0.2.zip配置文件 # unzip kafka-manager-2.0.0.2.zip # vim kafka-manager-2.0.0.2/conf/application.conf 1) 修改 kafka-manager.zkhosts="kafka-manager-zookeeper:2181" 如下 kafka-manager.zkhosts="zk-0.zk-hs.zk-kafka.svc.cluster.local:2181,zk-1.zk-hs.zk-kafka.svc.cluster.local:2181,zk-2.zk-hs.zk-kafka.svc.cluster.local:2181" 2) 启用用户密码登录,默认false不启用 basicAuthentication.enabled=true 3) 修改用户登录密码 basicAuthentication.password="admin@123" 修改完成后重新打包: # tar -czf kafka-manager-2.0.0.2.tar.gz kafka-manager-2.0.0.2/ 4 制作Dockerfile镜像 (1) Dockerfile文件 # cat Dockerfile FROM centos:7 LABEL maintainer liuchang RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ADD jdk-8u45-linux-x64.tar.gz /usr/local ADD kafka-manager-2.0.0.2.tar.gz /opt RUN ln -s /usr/local/jdk1.8.0_45 /usr/local/jdk && \ ln -s /opt/kafka-manager-2.0.0.2 /opt/kafka-manager ENV JAVA_HOME /usr/local/jdk ENV CLASSPATH $JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar ENV PATH $JAVA_HOME/bin:$PATH ENV LANG en_US.UTF-8 WORKDIR /opt EXPOSE 9000 CMD ["/opt/kafka-manager/bin/kafka-manager"] (2) 构建并上传到阿里云个人镜像仓库 [root@k8s-master1 kafka-manager]# ls -l total 357576 -rw-r--r-- 1 root root 509 Feb 25 14:39 Dockerfile -rw-r--r-- 1 root root 173271626 Mar 14 2021 jdk-8u45-linux-x64.tar.gz -rw-r--r-- 1 root root 96171216 Feb 25 14:30 kafka-manager-2.0.0.2.tar.gz -rw-r--r-- 1 root root 96701356 Feb 25 13:48 kafka-manager-2.0.0.2.zip -rw-r--r-- 1 root root 1839 Feb 25 15:00 kafka-manager.yml # docker build -t registry.cn-hangzhou.aliyuncs.com/k8s-image01/kafka-manager:2.0.0.2 . # docker push registry.cn-hangzhou.aliyuncs.com/k8s-image01/kafka-manager:2.0.0.2 5 kafka-manager.yml文件 # cat kafka-manager.yml apiVersion: v1 kind: Service metadata: name: kafka-manager namespace: zk-kafka labels: app: kafka-manager spec: type: NodePort selector: app: kafka-manager ports: - name: http port: 9000 targetPort: 9000 nodePort: 30096 --- apiVersion: apps/v1 kind: Deployment metadata: name: kafka-manager namespace: zk-kafka spec: replicas: 1 minReadySeconds: 10 strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 0 type: RollingUpdate selector: matchLabels: app: kafka-manager template: metadata: labels: app: kafka-manager spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: "app" operator: In values: - kafka-manager topologyKey: "kubernetes.io/hostname" terminationGracePeriodSeconds: 120 containers: - name: kafka-manager image: registry.cn-hangzhou.aliyuncs.com/k8s-image01/kafka-manager:2.0.0.2 imagePullPolicy: Always ports: - name: cport containerPort: 9000 resources: requests: cpu: 100m memory: 100Mi limits: cpu: 500m memory: 400Mi lifecycle: postStart: exec: command: ["/bin/sh","-c","touch /tmp/health"] livenessProbe: exec: command: ["test","-e","/tmp/health"] initialDelaySeconds: 5 timeoutSeconds: 5 periodSeconds: 10 readinessProbe: tcpSocket: port: cport initialDelaySeconds: 15 timeoutSeconds: 5 periodSeconds: 20 6 应用kafka-manager.yml文件 [root@k8s-master1 kafka-manager]# kubectl apply -f kafka-manager.yml service/kafka-manager created deployment.apps/kafka-manager created [root@k8s-master1 kafka-manager]# kubectl get pod -n zk-kafka NAME READY STATUS RESTARTS AGE kafka-0 1/1 Running 4 15h kafka-1 1/1 Running 4 15h kafka-2 1/1 Running 3 15h kafka-manager-7d86bc79c8-v5gfx 1/1 Running 11 60m nfs-client-provisioner-kafka-7544b56556-sw5cq 1/1 Running 4 29h nfs-client-provisioner-zk-85c888b6cf-zslhx 1/1 Running 4 29h zk-0 1/1 Running 4 29h zk-1 1/1 Running 4 29h zk-2 1/1 Running 4 29h [root@k8s-master1 kafka-manager]# kubectl get svc -n zk-kafka NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kafka-cs ClusterIP None <none> 9092/TCP 15h kafka-manager NodePort 172.28.196.251 <none> 9000:30096/TCP 61m zk-cs ClusterIP 172.28.66.236 <none> 2181/TCP 29h zk-hs ClusterIP None <none> 2888/TCP,3888/TCP 29h 7 访问kafka-manager (1) 使用K8S的nodeport端口访问kafka-manager 访问地址: http://<NodeIP>:30096/ 用户名: admin 密码: admin@123

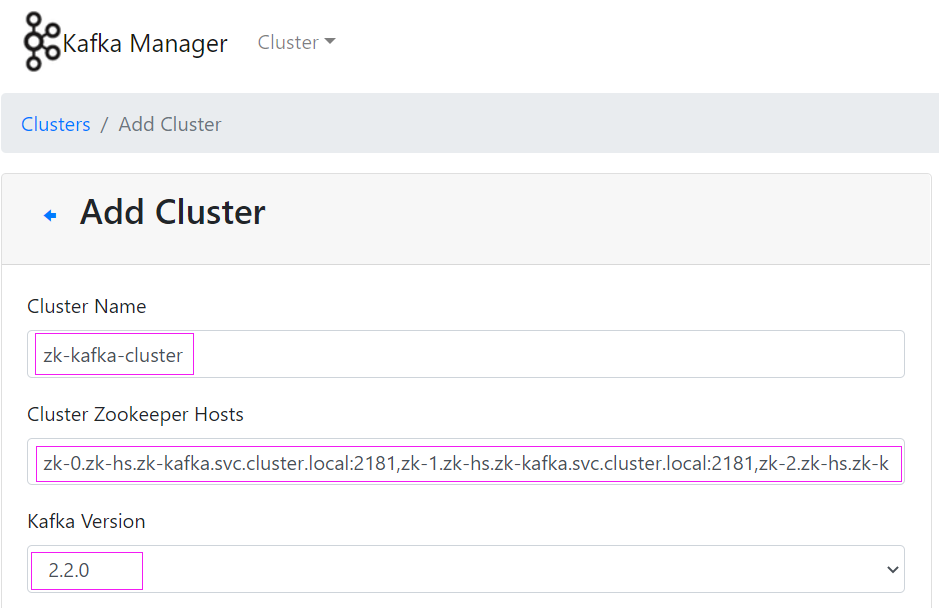
(2) Add Cluster



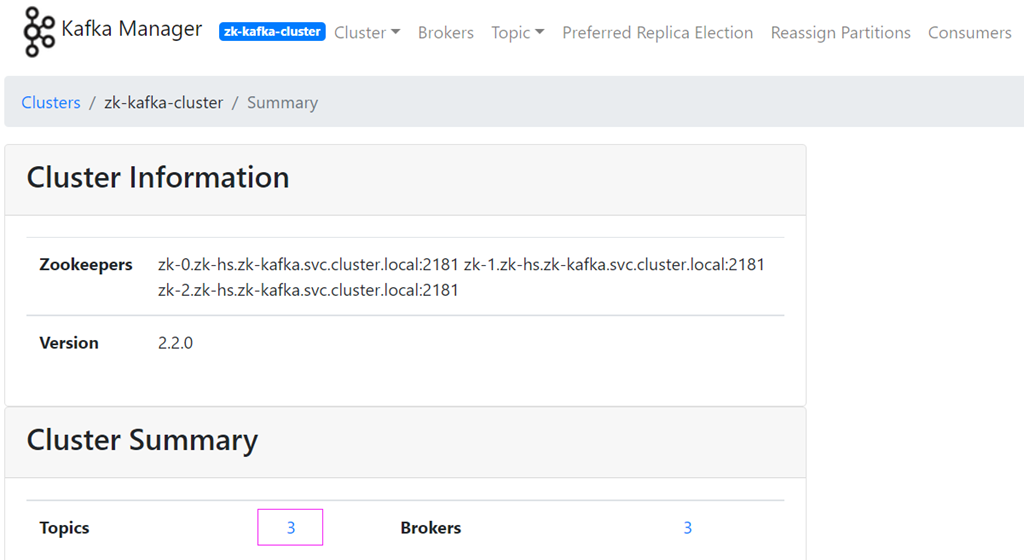
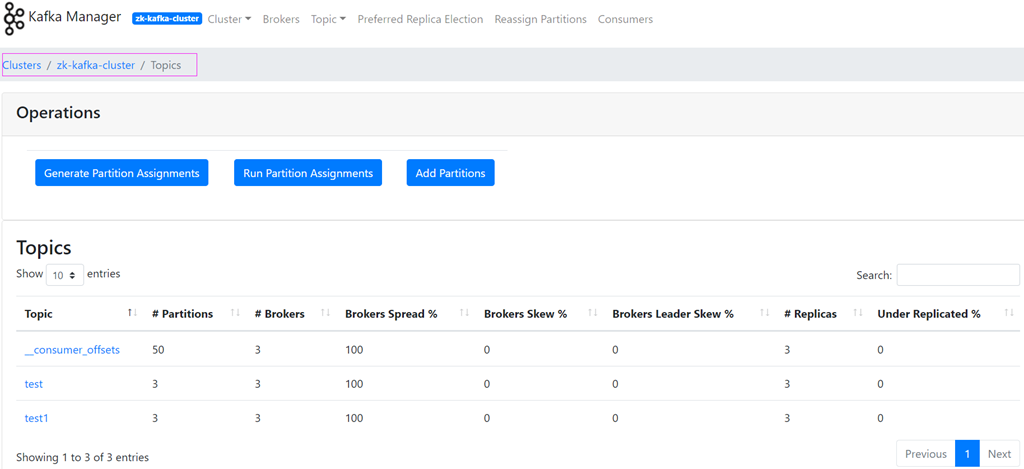
(3) 查看创建集群的具体信息



.JPG)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
2020-02-25 11、nginx+tomcat+redis_session共享
2020-02-25 9、make和make install的区别