5.9、ceph集群ceph.conf配置文件
(1) 默认生成的ceph.conf文件如果需要改动的话需要加一些参数,如果配置文件变化也是通过ceph-deploy进行推送。请不要直接修改某个节
点的"/etc/ceph/ceph.conf"文件,而是在部署机下修改ceph.conf,采用推送的方式更加方便安全。
(2) 推送修改的ceph.conf文件到所有节点(覆盖旧的ceph.conf)
# ceph-deploy --overwrite-conf config push ceph-deploy ceph-node01 ceph-node02 ceph-node03
(3) 特定服务配置项下的配置参数只对对应的特定服务生效,修改特定服务的配置参数后需要重启对应的特定服务才能生效,配置参数带下划线或者不带下划线都可以。
(4) 开启、关闭、重启所有 ceph 服务
# systemctl { start | stop | restart} ceph.target
(5) 根据进程类型开启、关闭、重启 ceph 服务
1) mon 进程
# systemctl { start | stop | restart} ceph-mon.target
2) mgr 进程
# systemctl { start | stop | restart} ceph-mgr.target
3) osd 进程
# systemctl { start | stop | restart} ceph-osd.target
4) rgw 进程
# systemctl { start | stop | restart} ceph-radosgw.target
5) mds 进程
# systemctl { start | stop | restart} ceph-mds.target
(6) 根据进程实例开启、关闭、重启 ceph 服务
1) mon 实例
# systemctl { start | stop | restart} ceph-mon@{mon_instance}.service
2) mgr 实例
# systemctl { start | stop | restart} ceph-mgr@{mgr_instance}.service
3) osd 实例
# systemctl { start | stop | restart} ceph-osd@{osd_instance}.service
4) rgw 实例
# systemctl { start | stop | restart} ceph-radosgw@{rgw_instance}.service
5) mds 实例
# systemctl { start | stop | restart} ceph-mds@{mds_instance}.service
9.2 PG 和 PGP 的区别
参考: https://www.bookstack.cn/read/ceph-handbook/Advance_usage-pg_pgp.md
1 说明
PG(Placement Group),pg是一个虚拟的概念,用于存放object,PGP(Placement Group for Placement purpose),相当于是pg存放的
一种osd排列。举个例子,假设集群有3个osd,即osd1,osd2,osd3,副本数为2,如果pgp=1,那么pg存放的osd的排列就有一种,可能是
[osd1,osd2],那么所有的pg主从副本都会存放到osd1和osd2上,如果pgp=2,那么其osd排列可能就两种,可能是[osd1,osd2]和[osd1,osd3]
,pg的主从副本会落在[osd1,osd2]或者[osd1,osd3]中,和我们数学中的排列很像,所以pg是存放对象的归属组是一种虚拟概念,pgp就是pg对应
的osd排列。一般情况下,存储池的pg和pgp的数量设置相等。
2 查看 pg 的分布
osd: osd=9
pool: pg=6,pgp=6,size=2
使用 ceph pg dump pgs 查看 pg 的分布,pg 数为 6,因为存储池为双副本,我们可以看到每个 pg 会分布在两个 osd 上,整个集群有 9 个
osd,按照排列会有很多种,此时 pgp=6,就会选择这些排列中的 6 种排列来供 pg 存放,我们可以看到最右侧的 6 种排列顺序均不重复。第一列
为 pg,第 2 列为每个 pg 的对象数,第 3 列为 pg 所在的 osd。
# ceph pg dump pgs |grep active |awk '{print 17,$18}'
dumped pgs
2.5 178 [1,2]
2.4 162 [6,0]
2.3 368 [5,2]
2.2 308 [5,6]
2.1 176 [7,8]
2.0 166 [0,6]
3 总结
(1) PG 是指定存储池存储对象的归属组有多少个,PGP 是存储池 PG 的 OSD 分布排列个数。
(2) PG 的增加会引起 PG 内的数据进行迁移,迁移到不同的 OSD 上新生成的 PG 中。
(3) PGP 的增加会引起部分 PG 的分布变化,但是不会引起 PG 内对象的变动。
4 排列组合
(1) 概念
1) 排列
一般地,从n个不同元素中取出m(m≤n)个元素,按照一定的顺序排成一列,叫做从n个元素中取出m个元素的一个排列(permutation)。
2) 组合
一般地,从n个不同的元素中,任取m(m≤n)个元素为一组,叫作从n个不同元素中取出m个元素的一个组合。
3) 排列与元素的顺序有关,组合与元素的顺序无关。
4) 元素的顺序对排列至关重要,比如 1、2、3 与 2、3、1 就是两种排列。
5) 与元素顺序无关的是组合,比如把 1、2、3 看作一个组合,那么 2、3、1 仍然是同一个组合。
(2) 在线计算器
https://tool.520101.com/calculator/zuhepailie/
(3) 计算公式


(4) 示例
ceph 集群中有 6 个 osd,存储池副本数为 3,那么存储池 PG 的 OSD 分布排列 PGP 个数计算如下。
P(6,3) = 120
9.4 生产环境 ceph.conf 配置
注: 我的 ceph 集群环境配置中允许管理员删除 pool,为了操作安全,建议不允许管理员删除pool,将如下配置参数取值 true 改为 false 即可。
[mon]
mon_allow_pool_delete = true
[root@ceph-deploy my-cluster]# cat > /root/my-cluster/ceph.conf << EOF
[global] # 全局设置
# 集群标识ID
fsid = 14912382-3d84-4cf2-9fdb-eebab12107d8
# 初始monitor(由创建monitor命令而定)
mon_initial_members = ceph-node01, ceph-node02, ceph-node03
# monitor IP 地址
mon_host = 172.16.1.31,172.16.1.32,172.16.1.33
auth_cluster_required = cephx # 集群认证
auth_service_required = cephx # 服务认证
auth_client_required = cephx # 客户端认证
osd_pool_default_size = 3 # 最小副本数,默认是3
osd_pool_default_min_size = 1 # PG处于degraded(降级)状态不影响其IO能力,min_size是一个PG能接受IO的最小副本数,默认是2
# 最小副本数为1,也就是只能坏2个副本(osd)
public_network = 172.16.1.0/24 # 公共网络(monitorIP段),默认值 ""
# monitor与osd,client与monitor,client与osd通信的网络,最好配置为带宽较高的万兆网络。
cluster_network = 172.16.1.0/24 # 集群网络,默认值 ""
# OSD之间通信的网络,一般配置为带宽较高的万兆网络。
max_open_files = 131072 # 默认0,如果设置了该选项,Ceph会设置系统的max open fds
#mon_pg_warn_max_per_osd = 3000 # 每个osd上pg数量警告值,这个可以根据具体规划来设定
mon_osd_full_ratio = .90 # 存储使用率达到90%将不再提供数据存储
mon_osd_nearfull_ratio = .80 # 存储使用率达到80%集群将会warn状态
osd_deep_scrub_randomize_ratio = 0.01 # 随机深度清洗概率,值越大,随机深度清洗概率越高,太高会影响业务
rbd_default_features = 1 # 解决rbd image挂载,OS kernel不支持块设备镜像一些特性的问题
##############################################################
[mon]
#mon_data = /var/lib/ceph/mon/ceph-$id
mon_clock_drift_allowed = 2 # 默认值0.05s,monitor间的clock drift(时钟偏移)
mon_clock_drift_warn_backoff = 30 # 默认值5,时钟偏移警告的退避指数
mon_osd_min_down_reporters = 13 # 默认值1,向monitor报告OSD down的最小次数
mon_osd_down_out_interval = 600 # 默认值300,标记一个OSD状态为down和out之前ceph等待的秒数
#mon_allow_pool_delete = false # false,不允许Ceph存储池被删除,默认值false
mon_allow_pool_delete = true # true,允许Ceph存储池被删除
##############################################################
[osd]
#osd_data = /var/lib/ceph/osd/ceph-$id
#osd_mkfs_type = xfs # 格式化文件系统类型,默认是xfs
osd_max_write_size = 512 # 默认值90,OSD一次可写入的最大值(MB)
osd_client_message_size_cap = 2147483648 # 默认值100,客户端允许在内存中的最大数据(bytes)
osd_deep_scrub_stride = 131072 # 默认值524288,在Deep Scrub(数据清洗)时候允许读取的字节数(bytes)
osd_op_threads = 16 # 默认值2,并发文件系统操作数
osd_disk_threads = 4 # 默认值1,OSD密集型操作例如恢复和Scrubbing时的线程
osd_map_cache_size = 1024 # 默认值500,保留OSD Map的缓存(MB)
osd_map_cache_bl_size = 128 # 默认值50,OSD进程在内存中的OSD Map缓存(MB)
#osd_mount_options_xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier"
# 默认值rw,noatime,inode64,Ceph OSD xfs Mount选项
osd_recovery_op_priority = 2 # 默认值10,恢复操作优先级,取值1-63,值越高占用资源越高,优先级也越高
osd_recovery_max_active = 10 # 默认值15,同一时间内活跃的恢复请求数,即每个OSD上同时进行的所有PG的恢复操作的最大数量
osd_max_backfills = 4 # 默认值10,一个OSD上允许最多有多少个pg同时做backfills,太大会影响业务
osd_min_pg_log_entries = 30000 # 默认值3000,PGLog保留的最小PGLog数
osd_max_pg_log_entries = 100000 # 默认值10000,PGLog保留的最大PGLog数
osd_mon_heartbeat_interval = 40 # 默认值30s,OSD ping一个monitor的时间间隔
ms_dispatch_throttle_bytes = 1048576000 # 默认值104857600,等待派遣的最大消息数(bytes)
objecter_inflight_ops = 819200
# 默认值1024,客户端流控,允许的最大未发送io请求数,超过阀值会堵塞应用io,为0表示不受限
osd_op_log_threshold = 50 # 默认值5,一次显示多少操作的log
osd_crush_chooseleaf_type = 0 # 默认值为1,CRUSH规则用到chooseleaf时的bucket的类型,0 表示让数据尽量散列
osd_recovery_max_single_start = 1
# OSD在某个时刻会为一个PG启动恢复操作数。
# 和osd_recovery_max_active一起使用,假设我们配置osd_recovery_max_single_start为1,osd_recovery_max_active为10,
# 那么,这意味着OSD在某个时刻会为一个PG启动一个恢复操作,而且最多可以有10个恢复操作同时处于活动状态。
osd_recovery_max_chunk = 1048576 # 默认为8388608, 设置恢复数据块的大小,以防网络阻塞
osd_recovery_threads = 10 # 恢复数据所需的线程数
osd_recovery_sleep = 0
# 默认为0,recovery的时间间隔,会影响recovery时长,如果recovery导致业务不正常,可以调大该值,增加时间间隔
# 通过sleep的控制可以大大的降低迁移磁盘的占用,对于本身磁盘性能不太好的硬件环境下,可以用这个参数进行一下控制,能够缓解磁盘压力过大引起的osd崩溃的情况
# 参考值: sleep=0;sleep=0.1;sleep=0.2;sleep=0.5
osd_crush_update_on_start = true # 默认true。false时,新加的osd会up/in,但并不会更新crushmap,prepare+active期间不会导致数据迁移
osd_op_thread_suicide_timeout = 600 # 防止osd线程操作超时导致自杀,默认150秒,这在集群比较卡的时候很有用
osd_op_thread_timeout = 300 # osd线程操作超时时间,默认15秒
osd_recovery_thread_timeout = 300 # osd恢复线程超时时间,默认30秒
osd_recovery_thread_suicide_timeout = 600 # 防止osd恢复线程超时导致自杀,默认300秒,在集群比较卡的时候也很有用
osd_memory_target = 2147483648 # osd最大使用内存量,单位为字节,配置为2GB(计算节点大内存机器才可以配置为4GB以上以提升性能)
osd_scrub_begin_hour = 0 # 开始scrub的时间(含deep-scrub),为每天0点
osd_scrub_end_hour = 8 # 结束scrub的时间(含deep-scrub),为每天8点,这样将deep-scrub操作尽量移到夜间相对client io低峰的时段,避免影响正常client io
osd_max_markdown_count = 10 # 当osd执行缓慢而和集群失去心跳响应时,可能会被集群标记为down(假down),默认为5次,超过此次数osd会自杀,必要时候可设置osd nodown来避免这种行为
##############################################################
[client]
rbd_cache_enabled = true # 默认值 true,RBD缓存
rbd_cache_size = 335544320 # 默认值33554432,RBD能使用的最大缓存大小(bytes)
rbd_cache_max_dirty = 235544320
# 默认值25165824,缓存为write-back时允许的最大dirty(脏)字节数(bytes),不能超过 rbd_cache_size,如果为0,使用write-through
rbd_cache_target_dirty = 134217728 # 默认值16777216,开始执行回写过程的脏数据大小,不能超过rbd_cache_max_dirty
rbd_cache_max_dirty_age = 30
# 默认值1,在被刷新到存储盘前dirty数据存在缓存的时间(seconds),避免可能的脏数据因为迟迟未达到开始回写的要求而长时间存在
rbd_cache_writethrough_until_flush = false
# 默认值true,该选项是为了兼容linux-2.6.32之前的virtio驱动,避免因为不发送flush请求,数据不回写。
# 设置该参数后,librbd会以writethrough的方式执行io,直到收到第一个flush请求,才切换为writeback方式。
rbd_cache_max_dirty_object = 2
# 默认值0,最大的Object对象数,默认为0,表示通过rbd cache size计算得到,librbd默认以4MB为单位对磁盘Image进行逻辑切分。
# 每个chunk对象抽象为一个Object;librbd中以Object为单位来管理缓存,增大该值可以提升性能。
#rgw_dynamic_resharding = false
# 关闭rgw自动动态index分片,防止丢index的情况,但需要定期手动进行reshard操作,默认值true
rgw_cache_enabled = true # 开启RGW cache,默认为true
rgw_cache_expiry_interval = 900 # 缓存数据的过期时间(seconds),默认900
rgw_thread_pool_size = 2000 # rgw进程的线程数目,默认512
# 查看方法: ps -ef |grep radosgw cat /proc/<radosgw进程id>/status |grep Thread
rgw_cache_lru_size = 20000
# RGW 缓存entries的最大数量,当缓存满后会根据LRU算法做缓存entries替换,entries size默认为10000
#rgw_num_rados_handles = 128
# Ceph Nautilus 14.2.3 版本之后,此配置选项已经从 Ceph 配置中删除
# Ceph 社区不建议调大此值,认为会造成内存泄漏
EOF

.JPG)


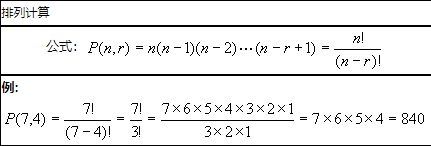{kind=link}
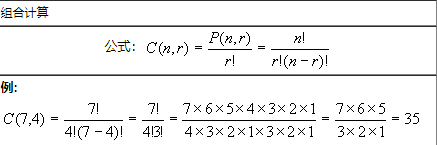{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏