5.5 ceph 集群状态说明
#
1.1 集群整体运行状态
1 查看集群状态
可以快速了解 Ceph 集群的 clusterID,health状况,以及 monitor、OSD、PG 的 map 概况。
[root@ceph-deploy my-cluster]# ceph -s
cluster:
id: 14912382-3d84-4cf2-9fdb-eebab12107d8
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 21m)
mgr: ceph-node01(active, since 21m), standbys: ceph-node03, ceph-node02
osd: 6 osds: 6 up (since 21m), 6 in (since 4w)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 114 GiB / 120 GiB avail
pgs: 1 active+clean
注: 参数说明
id # 集群ID
health # 集群运行状态。
mon # Monitors运行状态。
mgr # Managers运行状态。
osd # OSDs运行状态。
pools # 存储池与PGs的数量。
objects # 存储对象的数量。
usage # 存储的理论用量。
pgs # PGs的运行状态
2 观看实时群集状态更改
[root@ceph-deploy my-cluster]# ceph -w
3 查看集群健康状态
如果集群处于健康状态,会输出 HEALTH_OK,如果输出 HEALTH_WARN 甚至 HEALTH_ERR,表明 Ceph 处于一个不正常状态,可以加上"detail"选
项帮助排查问题。
[root@ceph-deploy my-cluster]# ceph health detail
HEALTH_OK
1.2 PG状态
查看pg状态通常使用下面两个命令即可,dump可以查看更详细信息,如
[root@ceph-deploy my-cluster]# ceph pg stat
1 pgs: 1 active+clean; 0 B data, 35 MiB used, 114 GiB / 120 GiB avail
PG状态概述: 一个 PG 在它的生命周期的不同时刻可能会处于以下几种状态中
(1) Creating(创建中)
在创建 POOL 时,需要指定 PG 的数量,此时 PG 的状态便处于 creating,意思是 Ceph 正在创建 PG。
(2) Peering(互联中)
peering 的作用主要是在 PG 及其副本所在的 OSD 之间建立互联,并使得 OSD 之间就这些 PG 中的 object 及其元数据达成一致。
(3) Active(活跃的)
处于该状态意味着数据已经完好的保存到了主 PG 及副本 PG 中,并且 Ceph 已经完成了 peering 工作。
(4) Clean(整洁的)
当某个 PG 处于 clean 状态时,则说明对应的主 OSD 及副本 OSD 已经成功互联,并且没有偏离的PG。也意味着 Ceph 已经将该 PG 中的对象按
照规定的副本数进行了复制操作。
(5) Degraded(降级的)
当某个 PG 的副本数未达到规定个数时,该 PG 便处于 degraded 状态,例如,在客户端向主 OSD 写入 object 的过程,object 的副本是由主
OSD 负责向副本 OSD 写入的,直到副本 OSD 在创建 object 副本完成,并向主 OSD 发出完成信息前,该 PG 的状态都会一直处于 degraded
状态。又或者是某个 OSD 的状态变成了 down,那么该 OSD 上的所有 PG 都会被标记为 degraded。当 Ceph 因为某些原因无法找到某个 PG 内
的一个或多个 object 时,该 PG 也会被标记为 degraded 状态。此时客户端不能读写找不到的对象,但是仍然能访问位于该 PG 内的其他object。
(6) Recovering(恢复中)
当某个 OSD 因为某些原因 down 了,该 OSD 内 PG 的 object 会落后于它所对应的 PG 副本。而在该 OSD 重新 up 之后,该 OSD 中的内容
必须更新到当前状态,处于此过程中的 PG 状态便是 recovering。
(7) Backfilling(回填)
当有新的 OSD 加入集群时,CRUSH 会把现有集群内的部分 PG 分配给它。这些被重新分配到新 OSD 的 PG 状态便处于 backfilling。
(8) Remapped(重映射)
当负责维护某个 PG 的 acting set 变更时,PG 需要从原来的 acting set 迁移至新的 acting set。这个过程需要一段时间,所以在此期间,相
关 PG 的状态便会标记为 remapped。
(9) Stale(陈旧的)
默认情况下,OSD 守护进程每半秒钟便会向 Monitor 报告其 PG 等相关状态,如果某个 PG 的主 OSD 所在 acting set 没能向 Monitor 发送
报告,或者其他的 Monitor 已经报告该 OSD 为 down 时,该 PG 便会被标记为stale。
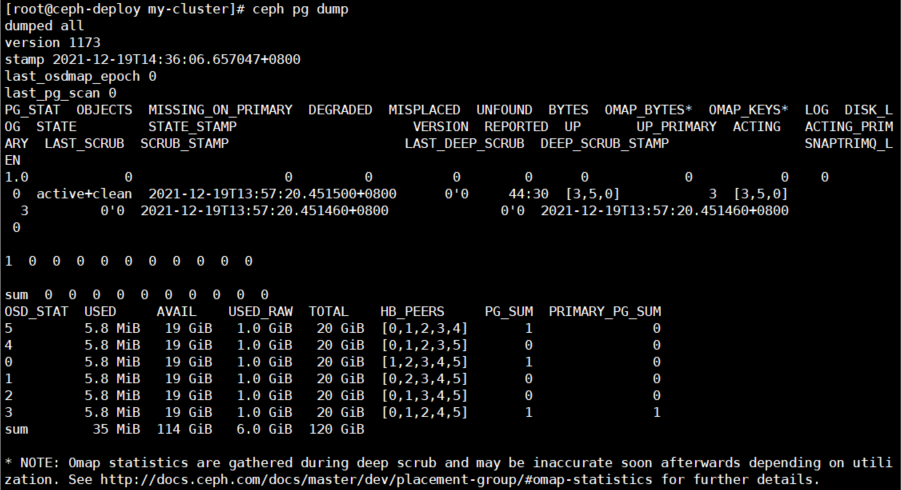
# 获取状态不正常的 PG 的状态,可以使用如下命令
[root@ceph-deploy ~]# ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format <format>]
# 获取集群里 PG 的统计信息
[root@ceph-deploy my-cluster]# ceph pg dump

1.3 Pool状态
[root@ceph-deploy my-cluster]# ceph osd pool stats
pool device_health_metrics id 1
nothing is going on
1.4 OSD状态
[root@ceph-deploy my-cluster]# ceph osd stat
6 osds: 6 up (since 44m), 6 in (since 4w); epoch: e45
# 查看 OSD 在集群布局中的设计分布
[root@ceph-deploy my-cluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.11691 root default
-3 0.03897 host ceph-node01
0 hdd 0.01949 osd.0 up 1.00000 1.00000
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-5 0.03897 host ceph-node02
2 hdd 0.01949 osd.2 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
-7 0.03897 host ceph-node03
4 hdd 0.01949 osd.4 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
# 查看 OSD 容量的使用情况
[root@ceph-deploy my-cluster]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.01949 1.00000 20 GiB 1.0 GiB 5.8 MiB 1 KiB 1024 MiB 19 GiB 5.03 1.00 1 up
1 hdd 0.01949 1.00000 20 GiB 1.0 GiB 5.8 MiB 4 KiB 1024 MiB 19 GiB 5.03 1.00 0 up
2 hdd 0.01949 1.00000 20 GiB 1.0 GiB 5.8 MiB 4 KiB 1024 MiB 19 GiB 5.03 1.00 0 up
3 hdd 0.01949 1.00000 20 GiB 1.0 GiB 5.8 MiB 1 KiB 1024 MiB 19 GiB 5.03 1.00 1 up
4 hdd 0.01949 1.00000 20 GiB 1.0 GiB 5.8 MiB 4 KiB 1024 MiB 19 GiB 5.03 1.00 0 up
5 hdd 0.01949 1.00000 20 GiB 1.0 GiB 5.8 MiB 1 KiB 1024 MiB 19 GiB 5.03 1.00 1 up
TOTAL 120 GiB 6.0 GiB 34 MiB 19 KiB 6.0 GiB 114 GiB 5.03
MIN/MAX VAR: 1.00/1.00 STDDEV: 0
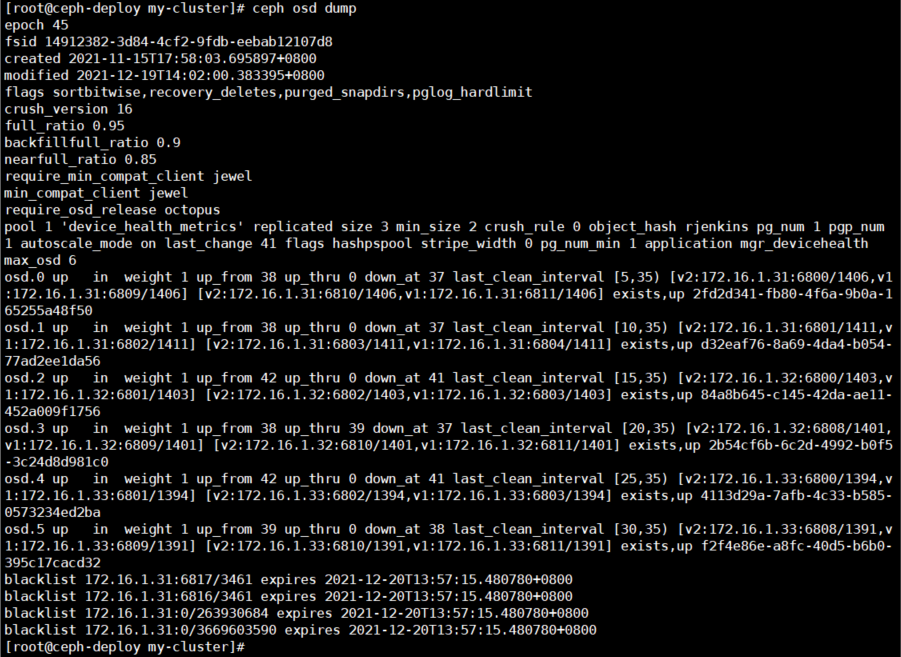
# 查看 OSD 的 dump 概况,OSD dump 输出的条目较多,基本可以分为三个部分:
(1) 输出 OSDmap 信息,包括版本号、集群ID 以及 map 相关的时间。
(2) POOL 的相关信息,包括 POOL ID、POOL名称、副本数、最小副本数、ruleset ID 等信息。
(3) 列出所有 OSD 的状态等信息,包括 OSD ID、状态、状态版本记录以及被监听的 IP 地址及端口等信息。
[root@ceph-deploy my-cluster]# ceph osd dump

OSD 状态说明:
单个 OSD 有两组状态需要关注,其中一组使用 in/out 标记该 OSD 是否在集群内,另一组使用 up/down 标记该 OSD 是否处于运行中状态。两组
状态之间并不互斥,换句话说,当一个 OSD 处于 in 状态时,它仍然可以处于 up 或 down 的状态。REWEIGHT(0 <=> out,1 <=> in)。
(1) OSD 状态为 in 且 up
这是一个 OSD 正常的状态,说明该 OSD 处于集群内,并且运行正常。
(2) OSD 状态为 in 且 down
此时该 OSD 尚处于集群中,但是守护进程状态已经不正常,默认在 300 秒后会被踢出集群,状态进而变为 out 且 down,之后处于该 OSD 上的 PG
会迁移至其它 OSD。当重新启动 osd 进程后,该 osd 会被加入到 ceph 集群中。
(3) OSD 状态为 out 且 up
这种状态一般会出现在新增 OSD 时,意味着该 OSD 守护进程正常,但是尚未加入集群。
(4) OSD 状态为 out 且 down
在该状态下的 OSD 不在集群内,并且守护进程运行不正常,CRUSH 不会再分配 PG 到该 OSD 上。
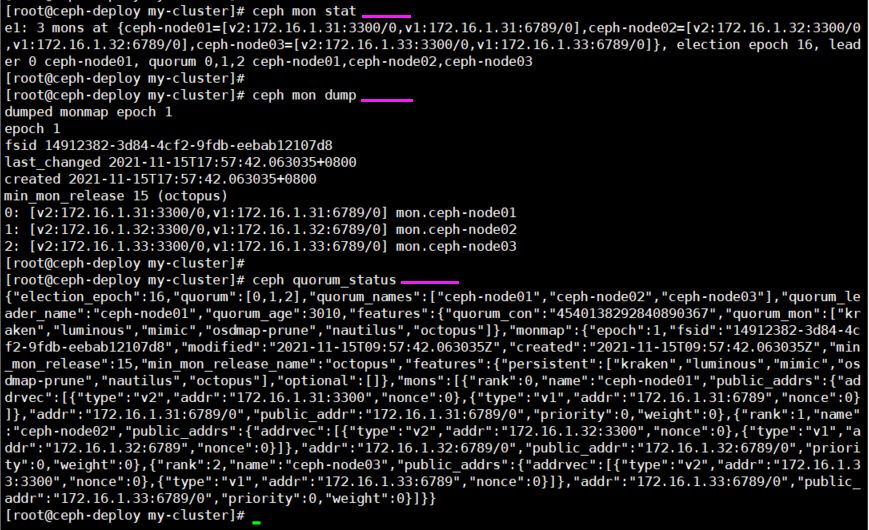
1.5 Monitor状态和查看仲裁状态
[root@ceph-deploy my-cluster]# ceph mon stat
[root@ceph-deploy my-cluster]# ceph mon dump
# ceph集群中mon的仲裁状态
[root@ceph-deploy my-cluster]# ceph quorum_status

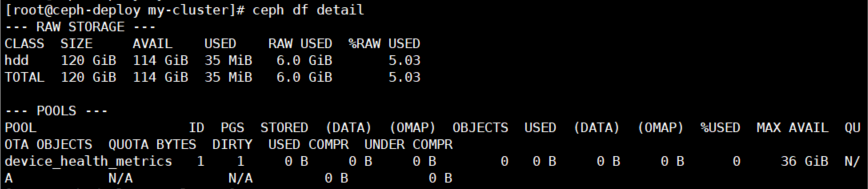
1.6 集群空间用量
[root@ceph-deploy ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 120 GiB 114 GiB 38 MiB 6.0 GiB 5.03
TOTAL 120 GiB 114 GiB 38 MiB 6.0 GiB 5.03
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 36 GiB
[root@ceph-deploy my-cluster]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 160 GiB 148 GiB 3.9 GiB 12 GiB 7.41
TOTAL 160 GiB 148 GiB 3.9 GiB 12 GiB 7.41
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 46 GiB
cephfs_data 2 64 1.2 GiB 302 3.5 GiB 2.48 46 GiB
cephfs_metadata 3 16 182 KiB 23 2.1 MiB 0 46 GiB
参数说明:
输出的 RAW STORAGE 段显示了数据所占用集群存储空间概况。
SIZE # 集群的总容量
AVAIL # 集群的总空闲容量
RAW USED # 已用存储空间总量
%RAW USED # 已用存储空间百分比
输出的POOLS段展示了存储池列表及各存储池的大致使用率。
POOL # 存储池名
ID # 存储池唯一标识符
PGS # 存储池内的 pg 数量
STORED # 不包含副本数的存储使用容量
OBJECTS # 存储池内的 object 个数
USED # 包含副本数的存储使用容量
%USED # 存储池的使用率 = STORED / MAX AVAIL
MAX AVAIL # 不包含副本数的存储池的最大可用空间
[root@ceph-deploy my-cluster]# ceph df detail

2 集群配置管理(临时和全局,服务平滑重启)#
有时候需要更改服务的配置,但不想重启服务,或者是临时修改。这时候就可以使用tell和daemon子命令来完成此需求。
2.1 查看运行配置
命令格式:
# ceph daemon {daemon-type}.{id} config show
命令举例(在角色所在的主机上进行操作):
[root@ceph-node01 ~]# ceph daemon osd.0 config show
2.2 tell子命令格式
使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配就可以对整个集群的角色进行设置,当出现节点异常无法设置的时候,只会在命令 行当中进行报错,不太便于查找。
命令格式:
# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]
注: 参数说明
daemon-type # 要操作的对象类型如osd、mon、mds等。
daemon id # 该对象的名称,osd通常为0、1等,mon为"ceph -s"显示的名称,这里可以输入'*'表示全部。
injectargs # 表示参数注入,后面必须跟一个参数,也可以跟多个。
命令举例:
[root@ceph-deploy my-cluster]# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1
{}
[root@ceph-node01 ~]# ceph daemon osd.0 config show | egrep 'debug_osd|debug_ms'
"debug_ms": "1/1",
"debug_osd": "20/20",
2.3 daemon子命令
使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此方法是需要在设置的角色所在的主机上进行设置。
命令格式:
# ceph daemon {daemon-type}.{id} config set {name}={value}
命令举例:
[root@ceph-node01 ~]# ceph daemon mon.ceph-node01 config set mon_allow_pool_delete false
{
"success": "mon_allow_pool_delete = 'false' "
}
3 集群操作#
命令包含start(启动服务)、stop(停止服务)、restart(重启服务)、status(服务状态)、enable(默认服务开机自启动)
、disable(服务器开机不自启动),需要在角色所在的主机上进行操作。
3.1 启动所有守护进程
[root@ceph-node01 ~]# systemctl start ceph.target
3.2 按类型启动守护进程
[root@ceph-node01 ~]# systemctl start ceph-mgr.target
# 根据osd编号启动osd服务(一个osd进程对应一块硬盘,一个节点上可以有多个osd)
[root@ceph-node01 ~]# systemctl start ceph-osd@id.service
[root@ceph-node01 ~]# systemctl start ceph-mon.target
[root@ceph-node01 ~]# systemctl start ceph-mds.target
[root@ceph-node01 ~]# systemctl start ceph-radosgw.target

.JPG)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏