5.4 Ceph监控
#
1 部署Dashboard#
(1) 说明
Ceph从L版本开始,Ceph提供了原生的Dashboard功能,通过Dashboard对Ceph集群状态查看和基本管理,使用Dashboard需要在MGR节点安装软件
包。
(2) 查看ceph状态
# ceph -s
cluster:
id: 14912382-3d84-4cf2-9fdb-eebab12107d8
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 4h)
mgr: ceph-node01(active, since 4h), standbys: ceph-node02, ceph-node03
osd: 6 osds: 6 up (since 4h), 6 in (since 12d)
data:
pools: 2 pools, 65 pgs
objects: 4 objects, 19 B
usage: 6.1 GiB used, 114 GiB / 120 GiB avail
pgs: 65 active+clean
# ceph -v
ceph version 15.2.15 (2dfb18841cfecc2f7eb7eb2afd65986ca4d95985) octopus (stable)
(3) 在ceph-node01、ceph-node02、ceph-node03上安装
1) 设置ceph源
之前在部署ceph时已经设置了ceph源,这里就不赘述了。
2) 安装
# yum install ceph-mgr-dashboard –y
......(省略内容)
--> Processing Dependency: python3-routes for package: 2:ceph-mgr-dashboard-15.2.15-0.el7.noarch
--> Processing Dependency: python3-cherrypy for package: 2:ceph-mgr-dashboard-15.2.15-0.el7.noarch
--> Processing Dependency: python3-jwt for package: 2:ceph-mgr-dashboard-15.2.15-0.el7.noarch
---> Package ceph-prometheus-alerts.noarch 2:15.2.15-0.el7 will be installed
---> Package python36-werkzeug.noarch 0:1.0.1-1.el7 will be installed
--> Finished Dependency Resolution
Error: Package: 2:ceph-mgr-dashboard-15.2.15-0.el7.noarch (Ceph-noarch)
Requires: python3-jwt
Error: Package: 2:ceph-mgr-dashboard-15.2.15-0.el7.noarch (Ceph-noarch)
Requires: python3-routes
Error: Package: 2:ceph-mgr-dashboard-15.2.15-0.el7.noarch (Ceph-noarch)
Requires: python3-cherrypy
You could try using --skip-broken to work around the problem
You could try running: rpm -Va --nofiles --nodigest
(4) 安装报错原因分析
这是由于从O版本开始,MGR改为Python3编写,而默认库没有这3个模块包,即使单独找包安装也可能不生效或者安装不上。从社区得知,这是已知问
题,建议使用CentOS8系统或者使用cephadm容器化部署Ceph,或者降低Ceph版本也可以,例如H版本,这个版本还是Python2编写的,不存在缺包
问题。这里选择降低到H版本,重新部署Ceph集群。
2 部署Ceph H版#
在ceph-deploy节点上进行操作
(1) 清理Ceph集群环境
1) 从远程主机卸载ceph包并清理数据
# ceph-deploy purge ceph-deploy ceph-node01 ceph-node02 ceph-node03
执行的命令实际为:
# yum -y -q remove ceph ceph-release ceph-common ceph-radosgw
"/etc/ceph/"目录会被移除。
2) 清理ceph所有node节点上的数据
# ceph-deploy purgedata ceph-node01 ceph-node02 ceph-node03
执行的命令为:
Running command: rm -rf --one-file-system -- /var/lib/ceph
Running command: rm -rf --one-file-system -- /etc/ceph/
3) 从本地目录移出认证秘钥
# cd /root/my-cluster/
# ceph-deploy forgetkeys
# rm -f ./*
4) 彻底清理ceph相关软件包
在ceph-deploy、ceph-node01、ceph-node02、ceph-node03节点上操作
# rpm -qa |grep 15.2.15 |xargs -i yum remove {} -y
5) 取消OSD盘创建的LVM逻辑卷映射关系
在ceph-node01、ceph-node02、ceph-node03节点上操作
# dmsetup info -C |awk '/ceph/{print $1}' |xargs -i dmsetup remove {}
6) 清除OSD盘GPT数据结构
在ceph-node01、ceph-node02、ceph-node03节点上操作
# yum install gdisk -y
# sgdisk --zap-all /dev/sdb # 从硬盘中删除所有分区
# sgdisk --zap-all /dev/sdc
(2) 部署(与之前的部署方式一样)
1) 设置yum源
在ceph-deploy、ceph-node01、ceph-node02、ceph-node03节点上操作
# cat > /etc/yum.repos.d/ceph.repo << EOF
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/\$basearch
gpgcheck=0
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch
gpgcheck=0
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
gpgcheck=0
EOF
2) 创建ceph-deploy部署目录
# mkdir -p /root/my-cluster/ && cd /root/my-cluster/
3) 初始化mon
# ceph-deploy install --no-adjust-repos ceph-deploy ceph-node01 ceph-node02 ceph-node03
# ceph-deploy new ceph-node01 ceph-node02 ceph-node03
# ceph-deploy mon create-initial
# ceph-deploy admin ceph-deploy ceph-node01 ceph-node02 ceph-node03
4) 初始化osd
# ceph-deploy osd create --data /dev/sdb ceph-node01
# ceph-deploy osd create --data /dev/sdc ceph-node01
# ceph-deploy osd create --data /dev/sdb ceph-node02
# ceph-deploy osd create --data /dev/sdc ceph-node02
# ceph-deploy osd create --data /dev/sdb ceph-node03
# ceph-deploy osd create --data /dev/sdc ceph-node03
5) 初始化mgr
# ceph-deploy mgr create ceph-node01 ceph-node02 ceph-node03
6) 查看ceph集群状态(报错)
# ceph -s
cluster:
id: 07862ba6-c411-4cee-a912-ed68850028d5
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
......(省略的内容)
报错解决办法:
# ceph config set mon auth_allow_insecure_global_id_reclaim false
7) 查看ceph集群状态(正常)
# ceph -s
cluster:
id: 07862ba6-c411-4cee-a912-ed68850028d5
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 13m)
mgr: ceph-node01(active, since 6m), standbys: ceph-node02, ceph-node03
osd: 6 osds: 6 up (since 7m), 6 in (since 7m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 114 GiB / 120 GiB avail
pgs:
8) 查看Ceph版本
# ceph -v
ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
(3) 添加RBD块设备和CephFS文件系统测试
1) 添加RBD块设备
# ceph osd pool create rbd-pool 64 64
# ceph osd pool application enable rbd-pool rbd
# rbd create --size 10240 rbd-pool/image01
# rbd feature disable rbd-pool/image01 object-map fast-diff deep-flatten
# rbd map rbd-pool/image01
# mkfs.xfs /dev/rbd0
# mount /dev/rbd0 /mnt
2) 添加CephFS文件系统
# cd /root/my-cluster/
# ceph-deploy mds create ceph-node01 ceph-node02 ceph-node03
# ceph osd pool create cephfs_data 64 64
# ceph osd pool create cephfs_metadata 64 64
# ceph fs new cephfs-pool cephfs_metadata cephfs_data
# ceph fs ls
name: cephfs-pool, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
# ceph osd pool ls
rbd-pool
cephfs_data
cephfs_metadata
# grep "key" /etc/ceph/ceph.client.admin.keyring
key = AQAIKKNhJJWQARAA47VYIHu8MD/j8SQkbqq+Pw==
3) 挂载cephfs文件系统
在172.16.1.34节点上操作
# mount -t ceph 172.16.1.31:6789,172.16.1.32:6789,172.16.1.33:6789:/ /mnt -o \
name=admin,secret=AQAIKKNhJJWQARAA47VYIHu8MD/j8SQkbqq+Pw==
# df -hT
Filesystem Type Size Used Avail Use% Mounted on
......(省略的内容)
172.16.1.31:6789,172.16.1.32:6789,172.16.1.33:6789:/ ceph 36G 0 36G 0% /mnt
(4) 查看ceph状态
# ceph -s
cluster:
id: 0469a267-e475-4934-b0e3-de3cc725707e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 19m)
mgr: ceph-node01(active, since 15m), standbys: ceph-node02, ceph-node03
mds: cephfs-pool:1 {0=ceph-node02=up:active} 2 up:standby
osd: 6 osds: 6 up (since 16m), 6 in (since 16m)
data:
pools: 3 pools, 192 pgs
objects: 46 objects, 14 MiB
usage: 6.1 GiB used, 114 GiB / 120 GiB avail
pgs: 192 active+clean
3 重新部署Dashboard#
在ceph-deploy节点上操作
(1) 在每个MGR节点安装
在ceph-node01、ceph-node02、ceph-node03节点上操作
# yum install ceph-mgr-dashboard -y
(2) 开启MGR功能
# ceph mgr module enable dashboard
# ceph mgr module ls | head -n 20
......(省略的内容)
"enabled_modules": [
"dashboard",
"iostat",
"restful"
],
......(省略的内容)
(3) 修改默认配置
# ceph config set mgr mgr/dashboard/server_addr 0.0.0.0
# ceph config set mgr mgr/dashboard/server_port 7000 # 每个mgr节点上都会起一个7000的TCP端口。
# ceph config set mgr mgr/dashboard/ssl false # 内网环境,web访问ceph的dashboard时,这里不需要ceph的ssl自签证书。
注: 后面如果修改配置,重启生效
# ceph mgr module disable dashboard
# ceph mgr module enable dashboard
(4) 创建一个dashboard登录用户名密码
格式: dashboard ac-user-create <username> {<rolename>} {<name>}
# echo "123456" > password.txt
# ceph dashboard ac-user-create admin administrator -i password.txt
{"username": "admin", "lastUpdate": 1638084810, "name": null, "roles": ["administrator"], "password": "$2b$12$amtj6kibrkqqixSFrriKNOxHXkazdN8MgjirC//Koc.z6x42tGenm", "email": null}
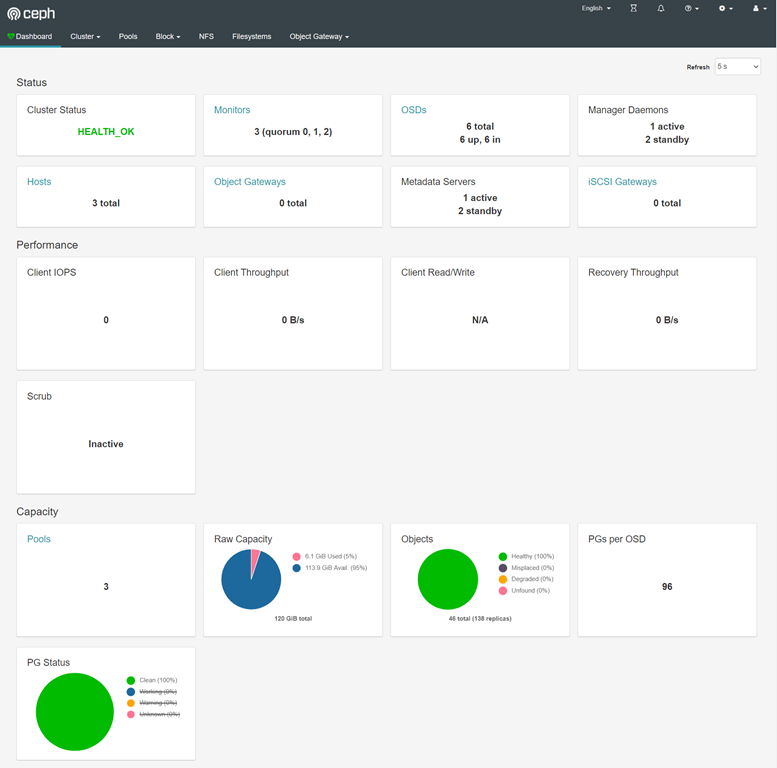
(5) 查看服务访问方式
# ceph mgr services
{
"dashboard": "http://ceph-node01:7000/"
}
UI登录: http://172.16.1.31:7000/


4 Prometheus+Grafana监控Ceph#
在172.16.1.34节点上操作
(1) 说明
Prometheus(普罗米修斯)是容器监控系统,官网地址为https://prometheus.io。
Grafana是一个开源的度量分析和可视化系统,官网地址为https://grafana.com/grafana。
(2) 部署docker
1) 安装依赖包
# yum install -y yum-utils device-mapper-persistent-data lvm2
2) 更新为阿里云的源
# wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
3) 清理源缓存
# yum clean all
4) 安装Docker CE
# yum install -y docker-ce
5) 启动Docker服务并设置开机启动
# systemctl start docker
# systemctl enable docker
6) 查看docker版本
# docker -v
Docker version 19.03.12, build 48a66213fe
7) 添加阿里云的镜像仓库
# mkdir -p /etc/docker
# tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://b1cx9cn7.mirror.aliyuncs.com"]
}
EOF
8) 重启docker
# systemctl daemon-reload
# systemctl restart docker
(3) docker部署Prometheus
官方文档: https://prometheus.io/docs/prometheus/latest/installation/
1) 将二进制安装包中的prometheus.yml配置文件上传到/opt/prometheus/config目录下
# mkdir -p /opt/prometheus/config
# cp -a /usr/local/prometheus/prometheus.yml /opt/prometheus/config/
2) 授权prometheus TSDB存储目录
# mkdir -p /opt/prometheus/data && chown -R 65534.64434 /opt/prometheus/data
3) 启动
# docker run -d \
-p 9090:9090 \
--restart=always \
--name=prometheus \
-v /opt/prometheus/config:/etc/prometheus \
-v /opt/prometheus/data:/prometheus \
prom/prometheus
4) UI访问
http://172.16.1.34:9090/
(4) docker部署Grafana
官方文档: https://grafana.com/docs/grafana/latest/installation/docker/
1) 创建grafana本地存储目录并授权
# mkdir -p /opt/grafana/
# chown -R 472.472 /opt/grafana/
2) 启动
# docker run -d \
--name grafana \
-p 3000:3000 \
-v /opt/grafana:/var/lib/grafana \
--restart=always \
grafana/grafana:7.5.9
3) UI访问
http://172.16.1.34:3000/
注: 初次登录时默认用户名和密码均为admin,录入后会要求修改密码,我这里修改为123456
(5) 启用MGR Prometheus插件
在ceph-deploy节点操作
# ceph mgr module enable prometheus # 每个mgr节点上都会起一个9283的TCP端口。
# ceph mgr services # 查看访问mgr服务的方式
{
"dashboard": "http://ceph-node01:7000/",
"prometheus": "http://ceph-node01:9283/"
}
# curl 172.16.1.31:9283/metrics # 测试promtheus指标接口。
(6) 配置Prometheus采集
# vim /opt/prometheus/config/prometheus.yml
......(省略的内容)
- job_name: 'ceph'
static_configs:
- targets: ['172.16.1.31:9283']
# docker restart prometheus
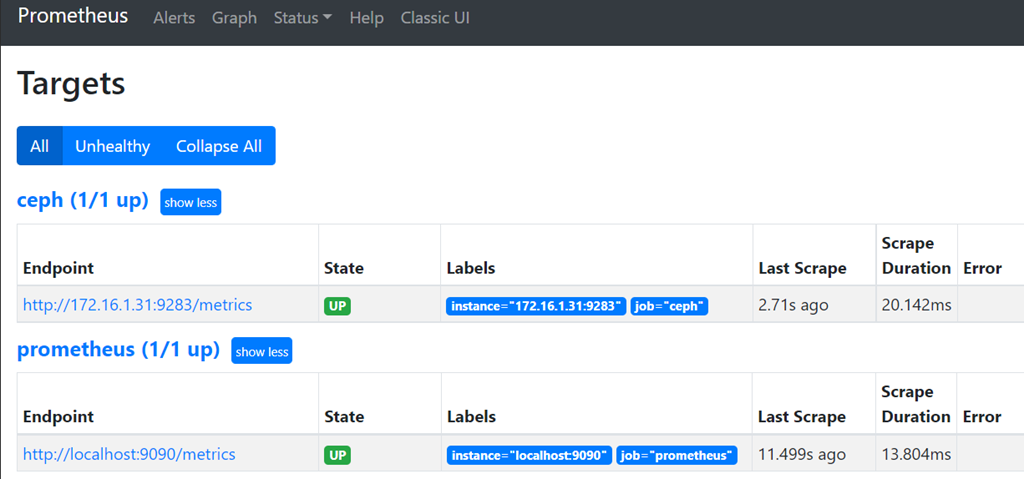
Prometheus-Targets: http://172.16.1.34:9090/targets

(7) 访问Grafana仪表盘
1) 访问Grafana
http://172.16.1.34:3000/
用户名为: admin
密码为: 123456
2) 添加Prometheus为数据源
Configuration -> Data sources -> Add Data sources -> Promethes -> 输入URL http://172.16.1.34:9090 -> Save & Test
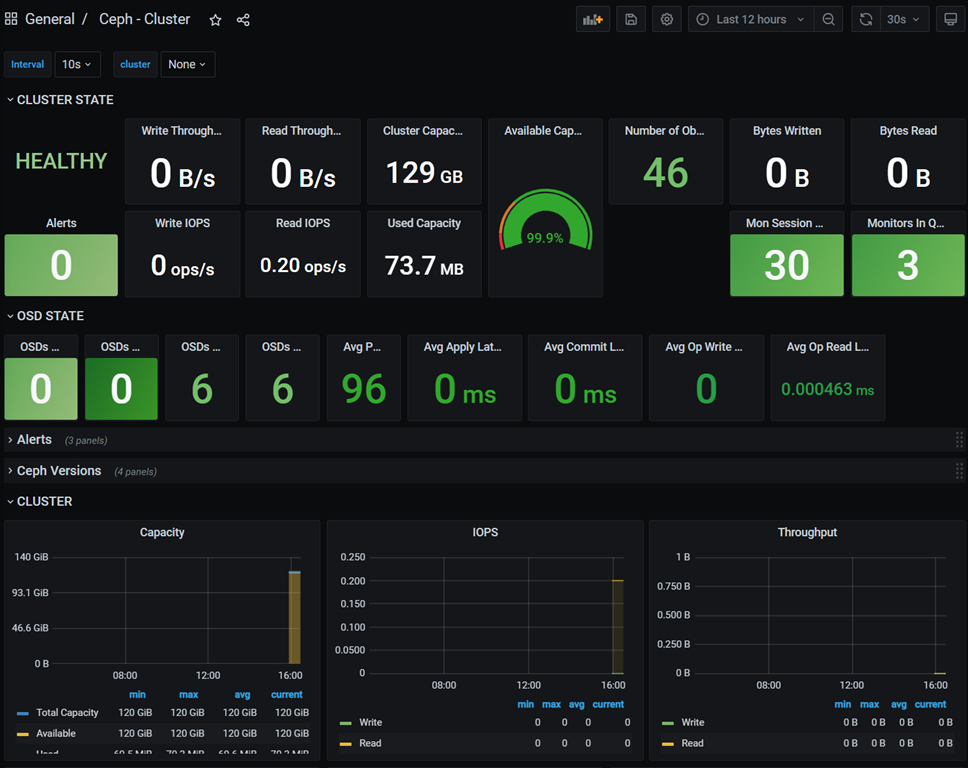
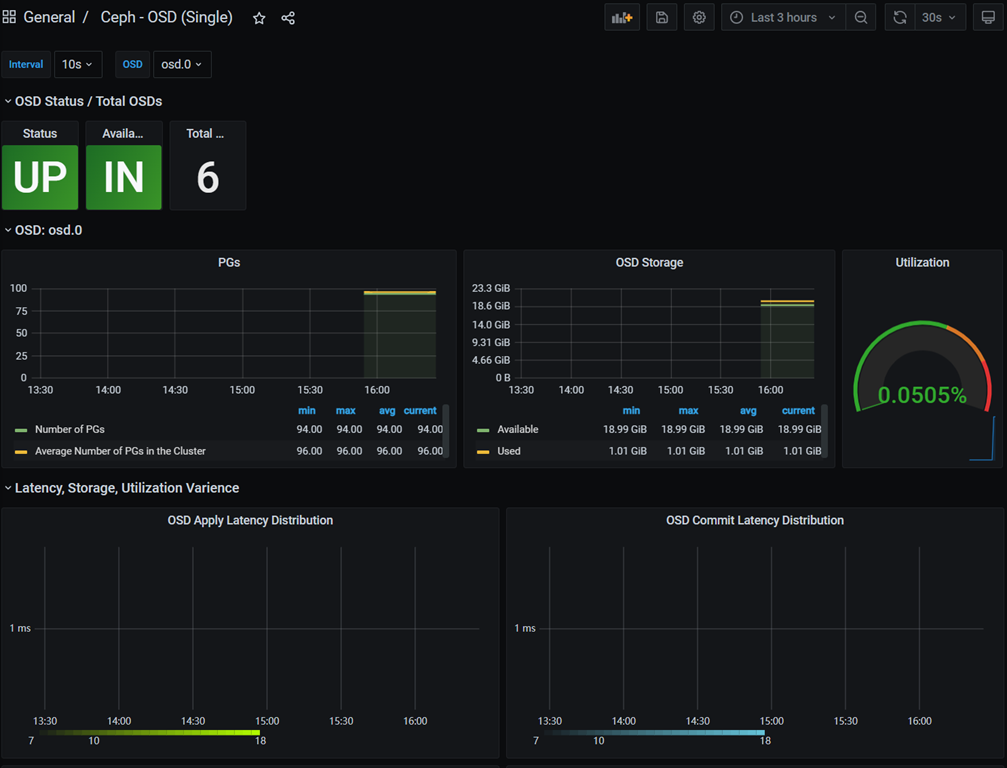
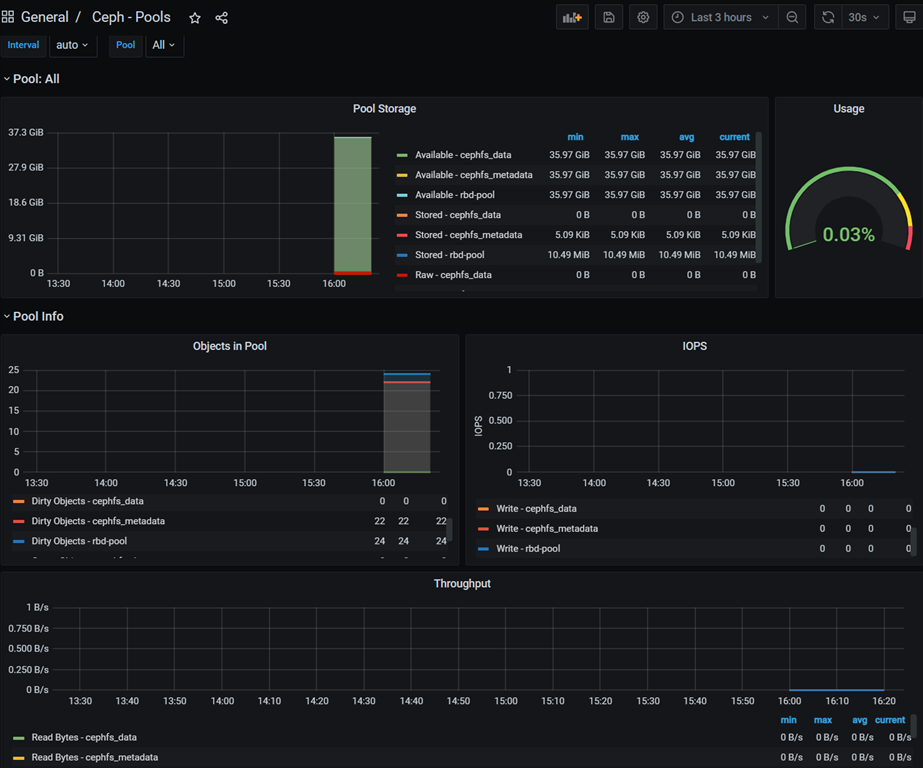
3) 导入Ceph监控仪表盘
Dashboards -> Manage -> Import -> 输入仪表盘ID -> Load
# 仪表盘ID
Ceph-Cluster ID: 2842
Ceph-OSD ID: 5336
Ceph-Pool ID: 5342




.JPG)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏