4 kubernetes数据库Etcd备份与恢复
4 kubernetes数据库Etcd备份与恢复
Kubernetes使用Etcd数据库实时存储集群中的数据,安全起见,一定要备份。
4.1 kubeadm部署方式#
单master节点k8s集群环境,在master节点操作
1 备份
kubeadm部署的etcd没有etcdctl命令,需要下载etcd二进制包。
下载地址:
https://github.com/etcd-io/etcd/releases/download/v3.5.0/etcd-v3.5.0-linux-amd64.tar.gz
#
tar -xzf etcd-v3.5.0-linux-amd64.tar.gz
#
cp -a etcd-v3.5.0-linux-amd64/etcdctl /usr/bin/
#
mkdir -p /opt/etcd_backup/
# ETCDCTL_API=3
etcdctl \
snapshot
save /opt/etcd_backup/snap-etcd-$(date
+%F-%H-%M-%S).db \
--endpoints=https://127.0.0.1:2379
\
--cacert=/etc/kubernetes/pki/etcd/ca.crt
\
--cert=/etc/kubernetes/pki/etcd/server.crt
\
--key=/etc/kubernetes/pki/etcd/server.key
注: 会生成一个路径为"/opt/etcd_backup/snap-etcd-2021-09-28-19-57-47.db"的etcd备份文件。
2 恢复
(1)
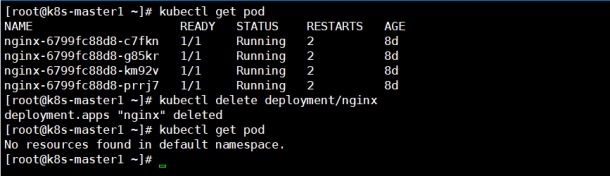
为了方便测试,先删除创建的pod
(2)
恢复etcd备份
1) 停掉kube-apiserver和etcd容器
# mv
/etc/kubernetes/manifests/ /etc/kubernetes/manifests-backup/
2) 对现在的etcd数据进行备份
# mv
/var/lib/etcd/ /var/lib/etcd-$(date
+%F-%H-%M-%S)-backup/
3) 恢复之前备份的etcd数据
# ETCDCTL_API=3
etcdctl \
snapshot
restore /opt/etcd_backup/snap-etcd-2021-09-28-19-57-47.db \
--data-dir=/var/lib/etcd/
注: /var/lib/etcd/目录不存在时,还原时会自动创建
4) 启动kube-apiserver和etcd容器
# mv
/etc/kubernetes/manifests-backup/ /etc/kubernetes/manifests/
注: 容器启动需要一定时间,请耐心等待还原完成
5) 然后重启所有节的kube-proxy容器和kubelet服务,否则pod无法正常进行访问
#
kubectl delete pod/<kube-proxy容器名>
-n kube-system
# system restart
kubelet.service
6) 再次查看,发现之前删除的pod恢复回来了
#
kubectl get pod -o wide
4.2 二进制部署方式#
在k8s高可用(2台apiserver),3个节点组成的etcd集群的环境下
1 说明
ETCD是一个高可用的分布式Key/Value存储系统,它使用Raft算法,通过选举来保持集群内各
节点状态的一致性。虽然ETCD具有高可用的特点,但是也无法避免多个节点宕机,甚至全部
宕机的情况发生。如何快速的恢复集群,就变得格外重要。由于ETCD集群需要选举产生leader,
所以集群节点数目需要为奇数来保证正常进行选举。而集群节点的数量并不是越多越好,过多
的节点会导致集群同步的时间变长,使得leader写入的效率降低。线上的ETCD集群最好由三个
节点组成(即宕机一台,集群可正常工作),并开启认证。
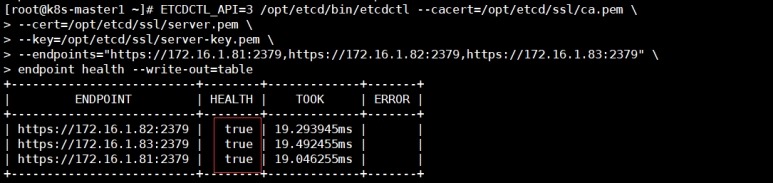
2 检查etcd的健康状态
# ETCDCTL_API=3 /opt/etcd/bin/etcdctl
--cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
\
--endpoints="https://172.16.1.81:2379,https://172.16.1.82:2379,https://172.16.1.83:2379"
\
endpoint health --write-out=table
3 备份
# mkdir -p /opt/etcd_backup/
#
ETCDCTL_API=3 /opt/etcd/bin/etcdctl \
snapshot
save /opt/etcd_backup/snap-etcd-$(date
+%F-%H-%M-%S).db \
--endpoints=https://172.16.1.81:2379 \
--cacert=/opt/etcd/ssl/ca.pem
\
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
注:
--endpoints=https://172.16.1.81:2379
etcd集群每个节点上的数据都是相同的,在任意一个正常的节点上备份都能得到k8s集群完整的数据。
生成一个路径为"/opt/etcd_backup/snap-etcd-2021-09-29-13-06-12.db"的etcd集群备份文件。
4 为了方便测试,删除当前的pod

5 集群超过半数节点宕机的恢复步骤
(1) 停止所有kube-apiserver
#
systemctl stop kube-apiserver.service
(2) 停止etcd集群的各个节点
#
systemctl stop etcd.service
(3) 备份etcd集群各个节点上当前的数据
#
mv /var/lib/etcd/default.etcd/ /var/lib/etcd/default.etcd-$(date
+%F-%H-%M-%S)-backup/
(4) 在etcd集群每个节点上恢复
前提:
将备份好的etcd数据复制到etcd集群各个节点上
# ETCDCTL_API=3 /opt/etcd/bin/etcdctl snapshot
restore /opt/etcd_backup/snap-etcd-2021-09-29-13-06-12.db \
--name
etcd-1 \
--initial-cluster="etcd-1=https://172.16.1.81:2380,etcd-2=https://172.16.1.82:2380,etcd-3=https://172.16.1.83:2380"
\
--initial-cluster-token=etcd-cluster
\
--initial-advertise-peer-urls=https://172.16.1.81:2380 \
--data-dir=/var/lib/etcd/default.etcd
参数说明:
--name #
节点名称
--initial-cluster #
集群中所有节点
--initial-cluster-token #
集群的ID
--initial-advertise-peer-urls #
告知集群其他节点当前的url
--data-dir # 指定节点的数据存储目录,这些数据包括节点ID,集群ID,集群初始化
# 配置,Snapshot文件等。
注:
--name
etcd-1
# 每个节点的唯一标识,在172.16.1.81-83节点上还原时,分别为etcd-1、etcd-2、etcd-3
--initial-advertise-peer-urls=https://172.16.1.81:2380
# ip替换为当前还原节点的ip地址,分别为172.16.1.81-83
(5) etcd集群各个节点还原后启动
#
systemctl start etcd.service
# 检查etcd集群健康状态,如下图可以看到集群还原成功
(6) 启动所有kube-apiserver
#
systemctl start kube-apiserver.service
(7)
查看pod已经还原,并且可以正常访问
# kubectl get pod
6 集群一个节点宕机的恢复步骤
(1) 查看集群健康状态
#
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
\
--endpoints="https://172.16.1.81:2379,https://172.16.1.82:2379,https://172.16.1.83:2379"
\
endpoint health --write-out=table
# 可以看到etcd集群中172.16.1.82
etcd节点出现了异常,但整个集群还是可用的状态。
(2) 将异常etcd节点数据进行备份
#
mv /var/lib/etcd/default.etcd/ /var/lib/etcd/default.etcd-$(date
+%F-%H-%M-%S)-backup/
(3) 找到异常的etcd节点的ID
#
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
\
--endpoints="https://172.16.1.81:2379,https://172.16.1.82:2379,https://172.16.1.83:2379"
\
member list --write-out=table
# 可以看到异常etcd节点的id为"161f8426ecb09eb3"
(4) 根据上一步获取的ID将异常的etcd节点从集群中移除
#
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
\
--endpoints="https://172.16.1.81:2379,https://172.16.1.82:2379,https://172.16.1.83:2379"
\
member
remove
161f8426ecb09eb3
#
移除成功,输出内容如下:
Member 161f8426ecb09eb3 removed from cluster
80ff3a5935a32a1d
(5)
将节点重新加入集群
由于ETCD集群证书依赖于服务器IP,为避免重新制作证书,需要保持节点IP不变。
# ETCDCTL_API=3
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
\
--endpoints="https://172.16.1.81:2379,https://172.16.1.82:2379,https://172.16.1.83:2379"
\
member
add etcd-2 --peer-urls=https://172.16.1.82:2380
(6) 修改异常etcd节点的配置文件
# vim /opt/etcd/cfg/etcd.conf
将ETCD_INITIAL_CLUSTER_STATE="new"
修改为 ETCD_INITIAL_CLUSTER_STATE="existing"
(7) 启动异常的etcd节点
#
systemctl start etcd.service
(8) 查看etcd集群的健康状态
#
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem
\
--key=/opt/etcd/ssl/server-key.pem
\
--endpoints="https://172.16.1.81:2379,https://172.16.1.82:2379,https://172.16.1.83:2379"
\
endpoint health --write-out=table
# 可以看到集群修复成功了

.JPG)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏