scrapy学习(一)
1.Scrapy架构图(绿线是数据流向)
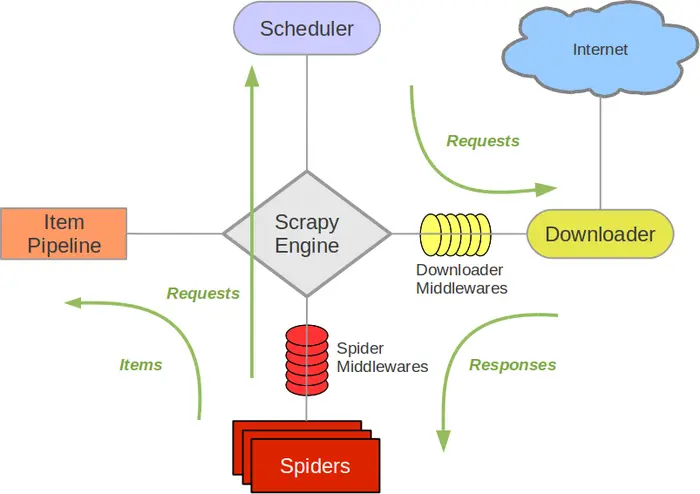
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2.制作Scrapy Spider的步骤
(1)新建项目(scrapy startproject xxx):新建一个新的爬虫项目
(2)明确目标(编写items.py,其中的字段为要爬取的关键信息):明确想要抓取的目标
(3)制作爬虫(编辑spiders/xxx_spider.py):制作爬虫,开始爬取网页
(4)存贮内容(编辑pilelines.py):设计管道,存储爬取的内容。
项目一:百度翻译
spider组件代码:
import scrapy import json class TranslationsSpider(scrapy.Spider): name = 'translations' # allowed_domains = ['translations.com'] start_urls = ['https://fanyi.baidu.com/sug'] # scrapy默认发起一个get请求 # 思考:scrapy如何发起一个post请求 # 需要重写父类的start_requests方法 # start_requests()方法永远是scrapy的初始请求的发送者 # 之所以,start_urls也能够成为初始请求的发送者,是因为 # 父类的start_requests()方法就是从start_urls中取出URL发起get请求的 # 所以,如果需要第一步就发起post请求,必须重写父类的start_requests() # 如果发起的post请求,使用FormRequest方法 def start_requests(self): data = {'kw': 'as'} # callback: 指定该请求返回的Response,由那个函数来处理。 # formdata是post请求发送的数据 # yield 的作用就是把一个函数变成一个生成器(generator),与return区别,不会结束程序 # yield 来发起一个请求,并通过 callback 参数为这个请求添加回调函数,在请求完成之后会将响应作为参数传递给回调函数 yield scrapy.FormRequest(url=self.start_urls[0],formdata=data,callback=self.parse) def parse(self, response): print(json.loads(response.text))
项目二:利用Scrapy自定义文件和图片下载类完成文件和图片的下载
-- FilesPipeline
--ImagesPipeline
(1)下载文件地址:https://matplotlib.org/2.0.2/examples/index.html
其相关配置:
ITEM_PIPELINES = { 'download_files.pipelines.DownloadFilesPipeline': 300, 'download_files.pipelines.DownloadImagesPipeline': 300, # 'scrapy.pipelines.files.FilesPipeline': 300, } # 存放文件的路径 FILES_STORE = 'files' # 存放图片的路径 IMAGES_STORE = 'images'
files的spider组件代码:
import scrapy from ..items import DownloadFilesItem class FilesSpider(scrapy.Spider): name = 'files' # allowed_domains = ['files.com'] start_urls = ['https://matplotlib.org/2.0.2/examples/index.html'] def parse(self, response): li_list = response.xpath('//li[@class="toctree-l2"]') for li in li_list: href = li.xpath('./a/@href').get() # urljoin(相对路径) 自动将不完整链接拼接成完整的链接 full_href = response.urljoin(href) # 发起二次请求 yield scrapy.Request(url=full_href, callback=self.downloads) def downloads(self, response): href = response.xpath('//div[@class="section"]/p[1]/a[1]/@href').get() # 将相对路径变为绝对路径 full_href = response.urljoin(href) # 实例化对象 item = DownloadFilesItem() # 注意:file_urls值必须是一个列表 item['file_urls'] = [full_href] yield item
images的spider组件代码
import scrapy import json from ..items import DownloadImagesItem class ImageSpider(scrapy.Spider): name = 'images' start_urls = ['https://image.so.com/zjl?ch=beauty&sn=60'] def parse(self, response, **kwargs): image_data = json.loads(response.text) image_list = image_data['list'] for image in image_list: item = DownloadImagesItem() title = image['title'] image_urls = image['qhimg_url'] item['image_name']=title item['image_urls']=[image_urls] # 每次传入一个url yield item # 返回值时,每个item都是一个title、一个urls这样的好处是不用考虑title和url对应的问题,方便pipelines保存
items文件代码:
import scrapy class DownloadFilesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 定义文件的url # file_urls变量名不能改动 file_urls = scrapy.Field() class DownloadImagesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 定义图片的url,固定 image_urls = scrapy.Field() # 定义图片的名称 image_name = scrapy.Field()
pipelines文件代码:
from scrapy.pipelines.images import ImagesPipeline from scrapy.pipelines.files import FilesPipeline import scrapy class DownloadFilesPipeline(FilesPipeline): # 重写父类的文件保存的方法 def file_path(self, request, response=None, info=None, *, item=None): # 获取文件名 file_name = request.url.split('/')[-1] return f'full/{file_name}' # def process_item(self, item, spider): # return item class DownloadImagesPipeline(ImagesPipeline): # def get_media_requests(self, item, info): # for image_url in item['image_urls']: # yield scrapy.Request(url=image_url) def file_path(self, request, response=None, info=None, *, item=None): # image_name = item['image_name'][item['image_urls'].index(request.url)] image_name = item['image_name'] return f"360/{image_name}.jpg"
scrapy中使用selenium
from selenium import webdriver from scrapy.http import HtmlResponse class DbydDownloaderMiddleware(object): # 定义初始化函数 def __init__(self): # 调用浏览器 self.driver = webdriver.Chrome(executable_path=r'D:\chrome\chromedriver.exe') pass def process_request(self, request, spider): if 'dcm' in request.url: # 最大化浏览器 self.driver.maximize_window() # 发起请求 self.driver.get(url=request.url) # 获取内容 content = self.driver.page_source return HtmlResponse(body=content,encoding='utf-8',url=request.url) else: return None
扩展: 将数据保存到Excel中(示例)
from openpyxl import Workbook # 1.实力化对象 wb = Workbook() # 2.激活工作表 ws = wb.active # 3.填写表头 ws.append(['阅读数','评论数','标题','作者','时间']) # 插入内容lst为内容列表 ws.append(lst) # 保存 wb.save('股吧.xlsx')
详细操作:
https://vlambda.com/wz_yL8VKk2AcVl.html
https://blog.csdn.net/weixin_41546513/article/details/109555832
