scrapy-redis实现分布式爬虫
什么是分布式爬虫
分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集。单机爬虫就是只在一台计算机上的爬虫。
其实搜索引擎都是爬虫,负责从世界各地的网站上爬取内容,当你搜索关键词时就把相关的内容展示给你,只不过他们那都是灰常大的爬虫,爬的内容量也超乎想象,也就无法再用单机爬虫去实现,而是使用分布式了,一台服务器不行,我来1000台。我这么多分布在各地的服务器都是为了完成爬虫工作,彼此得通力协作才行啊,于是就有了分布式爬虫
单机爬虫的问题:
- 一台计算机的效率问题
- IO 的吞吐量,传输速率也有限
多爬虫问题
- 多爬虫要实现数据共享
- 比如说一个爬取了某个网站,下载了哪些内容,其他爬虫要知道,以避免重复爬取等很多问题,所以要实现数据共享
- 在空间上不同的多台机器,可以成为分布式
多爬虫条件:
- 需要共享队列
- 去重,让多个爬虫不爬取其他爬虫爬取过的爬虫
理解分布式爬虫:
- 假设上万的 url 需要爬取,有 100 多个爬虫,分布在全国不同的城市
- url 被分给不同的爬虫,但是不同爬虫的效率又是不一样的,所以说共享队列,共享数据,让效率高的爬虫多去做任务,而不是等着效率低的爬虫
Redis
- Redis 是完全开源免费的,遵守BSD协议,是一个高性能的 key-value 数据库
- 内存数据库,数据存放在内存
- 同时可以落地保存到硬盘
- 可以去重
- 可以把 Redis 理解成一共 dict,set,list 的集合体
- Redis 可以对保存的内容进行生命周期
- Redis 教程:Redis 教程 - 菜鸟教程
内容保存数据库
- MongoDB,运行在内存,数据保存在硬盘
- MySQL
一、 分布式爬虫Master的settings:
# 使用scrapy-redis里的去重组件,不使用scrapy默认的去重方式 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis里的调度器组件,不使用默认的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 允许暂停,redis请求记录不丢失 SCHEDULER_PERSIST = True # 默认的scrapy-redis请求队列形式(按优先级) #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # 栈形式,请求先进后出 #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" # 队列形式,请求先进先出 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 打开请求延时为1秒 DOWNLOAD_DELAY = 1 # 配置redis的主机号 REDIS_HOST = '127.0.0.1' # 配置redis的端口号 REDIS_PORT = 6379 #也可以通过下面这种方法设置redis地址 端口和密码,一旦设置了这个,则会覆盖上面所设置的REDIS_HOST和REDIS_HOST #root用户名,redis_pass:你设置的redis验证密码,xxxx:你的主机ip # REDIS_URL = 'redis://root:redis_pass@xxx.xx.xx.xx:6379' REDIS_ENCODING = 'utf-8'
master其他设置:spider文件
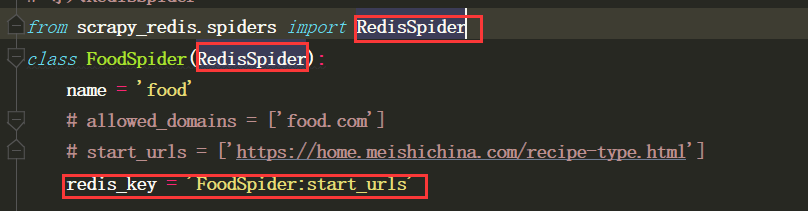
1.需要更改继承的类
from scrapy_redis.spiders import RedisSpider
2.注释掉start_urls
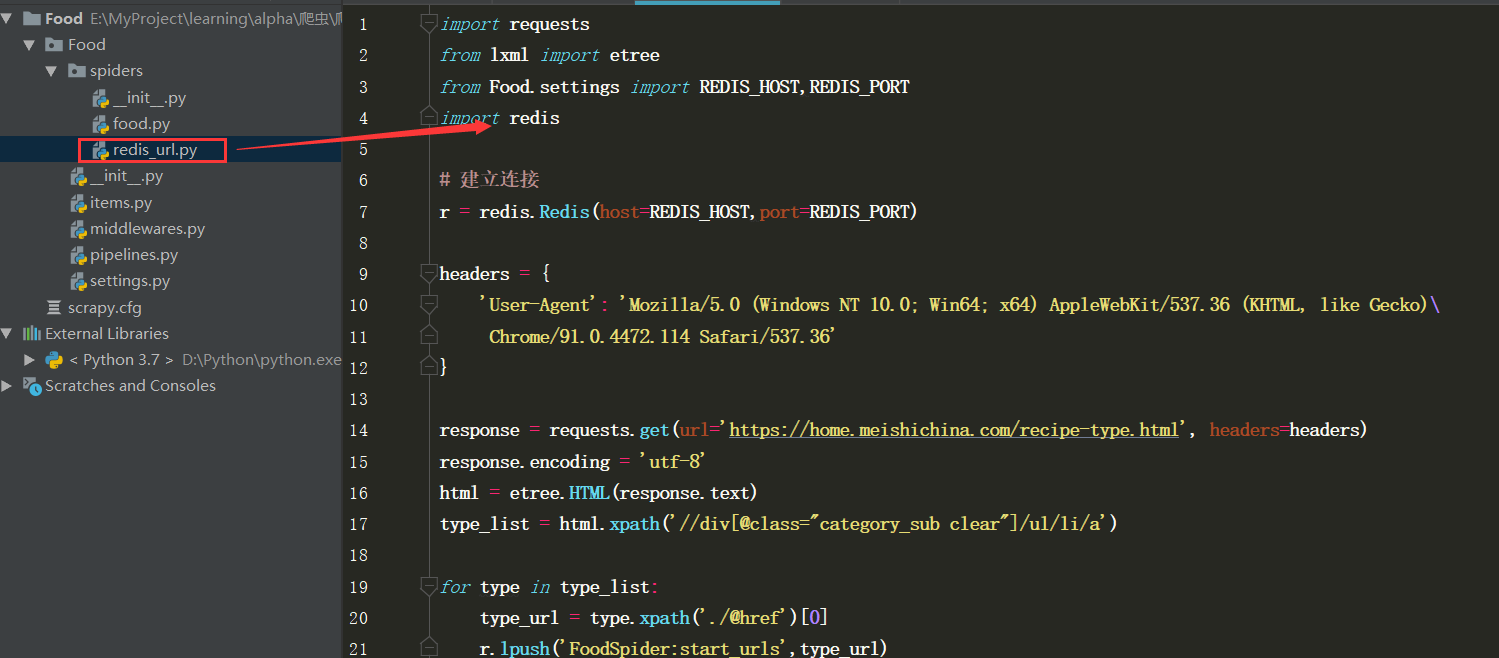
3.在爬虫目录下新创建一个redis_urls.py文件,放所有的URL到redis数据库的列表中
4.回到爬虫文件中,写一个redis_key = '列表的key'
redis_urls.py
二、分布式爬虫Slave的settings:
前面的和master都一样 #配置redis主机名 REDIS_HOST = 'master的IP' #配置redis端口号 REDIS_PORT = 6379 # 若有密码则一样和master保持一致 ...
slave其他配置:
1、需要删除redis_urls文件
2、如果数据是存到master的MongoDB数据库,需要到pipelines文件中将host改成master的ip,数据库改成master的,集合也改成master的。
注意:scrapy-redis存在空跑问题
1.在master和slave项目目录下,新建一个extensions.py文件,写如下代码:
# spider_idle信号只有在爬虫队列为空时才会被触发, 触发间隔为5s。 import logging from scrapy import signals from scrapy.exceptions import NotConfigured logging = logging.getLogger(__name__) class RedisSpiderSmartIdleClosedExensions(object): def __init__(self, idle_number, crawler): self.crawler = crawler self.idle_number = idle_number self.idle_list = [] self.idle_count = 0 @classmethod def from_crawler(cls, crawler): # first check if the extension should be enabled and raise # NotConfigured otherwise if not crawler.settings.getbool('MYEXT_ENABLED'): raise NotConfigured if not 'redis_key' in crawler.spidercls.__dict__.keys(): raise NotConfigured('Only supports RedisSpider') # get the number of items from settings idle_number = crawler.settings.getint('IDLE_NUMBER', 360) # instantiate the extension object ext = cls(idle_number, crawler) # connect the extension object to signals crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened) crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed) crawler.signals.connect(ext.spider_idle, signal=signals.spider_idle) return ext def spider_opened(self, spider): spider.logger.info("opened spider {}, Allow waiting time:{} second".format(spider.name, self.idle_number * 5)) def spider_closed(self, spider): spider.logger.info( "closed spider {}, Waiting time exceeded {} second".format(spider.name, self.idle_number * 5)) def spider_idle(self, spider): # 程序启动的时候会调用这个方法一次,之后每隔5秒再请求一次 # 当持续半个小时都没有spider.redis_key,就关闭爬虫 # 判断是否存在 redis_key if not spider.server.exists(spider.redis_key): self.idle_count += 1 else: self.idle_count = 0 if self.idle_count > self.idle_number: # 执行关闭爬虫操作 self.crawler.engine.close_spider(spider, 'Waiting time exceeded')
2.打开settings.py文件中EXTENSIONS的注释,将Telent的注释掉,换上:
'项目名.extensions.RedisSpiderSmartIdleClosedExensions': 500
3.配置settings.py文件:
# 开启扩展 MYEXT_ENABLED = True # 每5秒就检测一次,检测10次(50秒),如果url还为空,那么就结束爬虫程序 IDLE_NUMBER = 10
最后Slave尝试连接Master
尝试连接 mongo:mongo --host masterIP --port 27017
尝试连接master的redis数据库:redis-cli -h masterIP
ps:master的redis数据库配置文件需要做如下更改:
1.将bind 127.0.0.1 注释掉

2.将protected-mode yes 改为 protected-mode no

