网络爬虫之猫眼电影影人信息的抓取
项目简介:爬取猫眼电影中所有影人的信息,包括其中文名、英文名、职业、生日、身高、代表作、粉丝数、和累计票房数,并保存至MongoDB数据库中。
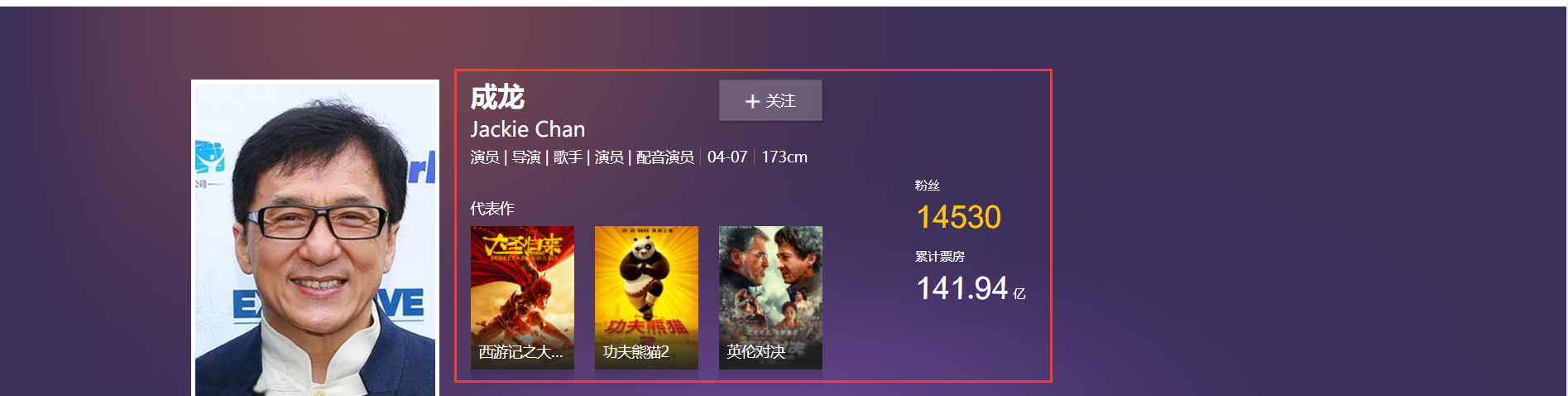
项目难点一:粉丝数和累计票房数的CSS字体加密破解。
项目难点二:爬取过程中出现滑块验证码的破解。
项目思路分析:爬取所有影人信息,在这里采用传统的分页式爬取并不可取,而增量爬虫的思路无疑是最好的解决办法。
增量式爬虫介绍:
概念:通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新出的新数据。
如何进行增量式的爬取工作:
在发送请求之前判断这个URL是不是之前爬取过
在解析内容后判断这部分内容是不是之前爬取过
写入存储介质时判断内容是不是已经在介质中存在
- 经过分析不难发现,其实增量爬取的核心是去重, 至于去重的操作在哪个步骤起作用,只能说各有利弊。在我看来,前两种思路需要根据实际情况取一个(也可能都用)。第一种思路适合不断有新页面出现的网站,比如说小说的新章节,每天的最新新闻等等;第二种思路则适合页面内容会更新的网站。第三个思路是相当于是最后的一道防线。这样做可以最大程度上达到去重的目的。
去重方法
- 将爬取过程中产生的url进行存储,存储在redis的set中。当下次进行数据爬取时,首先对即将要发起的请求对应的url在存储的url的set中做判断,如果存在则不进行请求,否则才进行请求。
- 对爬取到的网页内容进行唯一标识的制定,然后将该唯一表示存储至redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,首先可以先判断该数据的唯一标识在redis的set中是否存在,在决定是否进行持久化存储。
项目代码:
from selenium.webdriver.chrome.options import Options from selenium.webdriver import ActionChains from fontTools.ttLib import TTFont from selenium import webdriver from queue import Queue from lxml import etree import hashlib import pymongo import requests import re import time import redis def get_tracks(distance): """ v = v0+at x = v0t+1/2at**2 """ # 定义存放运动轨迹的列表 tracks = [] # 定义初速度 v = 0 # 定义单位时间 t = 0.5 # 定义匀加速运动和匀减速运动的分界线 mid = distance * 4 / 5 # 定义当前位移 current = 0 # 为了一直移动,定义循环 while current < distance: if mid > current: a = 2 else: a = -3 v0 = v # 计算位移 x = v0 * t + 1 / 2 * a * t ** 2 # 计算滑块当前位移 current += x # 计算末速度 v = v0 + a * t tracks.append(round(x)) return tracks def get_driver(): """ 定义调用selenium的方法 :return: """ # 2. 调用浏览器 driver = webdriver.Chrome(options=options) # 将webdriver属性干掉 driver.execute_cdp_cmd( "Page.addScriptToEvaluateOnNewDocument", { "source": 'Object.defineProperty(navigator,"webdriver",{get:()=>undefined})' } ) # 最大化窗口 driver.maximize_window() return driver def check_code(url): """ 破解滑块验证码、验证函数 :param url: :return: """ driver = get_driver() # 3. 请求 driver.get(url=url) # 休眠,等待验证码加载 time.sleep(2) # 切入iframe标签 driver.switch_to.frame(1) # 获取滑块 huakuai = driver.find_element_by_xpath('//div[@id="tcaptcha_drag_thumb"]') # 点击并按住 ActionChains(driver).click_and_hold(on_element=huakuai).perform() # 开始滑动,测试距离大概212 ActionChains(driver).move_by_offset(xoffset=108, yoffset=0).perform() # 获取运动轨迹 tracks = get_tracks(100) for track in tracks: ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() time.sleep(1) # 释放鼠标 ActionChains(driver).release().perform() time.sleep(5) print('当前请求的URL:', driver.current_url) if 'verify' in driver.current_url: check_code(driver.current_url) # 关闭浏览器 driver.close() else: global check_url check_url = driver.current_url driver.close() def downloader(url): """ 下载网页源码 :param url: :return: 网页源代码的文本 """ response = requests.get(url=url, headers=headers) print(response.url) # 判断是否有滑块验证码 if response.url != url: # 破解滑块验证码 check_code(response.url) # 使用破解滑块验证码的url在去请求,下载网页源代码 response = downloader(check_url) return response def get_woff(content): """ 下载woff文件 :param content: :return: woff文件名 """ woff_pattern = re.compile(r" url\('(.*?\.woff)'\)") woff_href = 'https:' + woff_pattern.findall(content)[0] woff_name = woff_href.split('/')[-1] woff_response = requests.get(url=woff_href, headers=headers) with open(woff_name, 'wb') as fp: fp.write(woff_response.content) return woff_name def get_font_code(woff): """ 获取加密字体的编码 :param woff: :return: 编码的列表 """ base_font = TTFont(woff) code_list = base_font.getGlyphOrder()[2:] return code_list def get_font_dict(code_list): """ 生成破解字体加密替换字典 :param code_list: :return: """ for code, font in zip(code_list, font_list): font_dict[code] = font def extract_first(content): """ 定义获取列表值的函数,若没有返回None :param content: :return: """ if content: return content[0] else: return None def spider(content): """ 爬虫组件,爬取网页中的信息 :param content: :return: item """ html = etree.HTML(content) China_name = extract_first(html.xpath('//div[@class="shortInfo"]/p[1]/text()')) English_name = extract_first(html.xpath('//div[@class="shortInfo"]/p[2]/text()')) profession = extract_first(html.xpath('//div[@class="shortInfo"]/p[3]/span[1]/text()')) birthday = extract_first(html.xpath('//div[@class="shortInfo"]/p[3]/span[2]/text()')) height = extract_first(html.xpath('//div[@class="shortInfo"]/p[3]/span[3]/text()')) works = html.xpath('//li[@class="master-item"]/a/div/p/text()') # 代表作 fans = extract_first(html.xpath('//p[@class="index-num followCount"]/span[@class="stonefont"]/text()')) # 粉丝数 box_office = ''.join(html.xpath('//p[@class="index-num"]/span//text()')) # 累计票房数 item = {'China_name': China_name, 'English_name': English_name, 'profession': profession, 'birthday': birthday, 'height': height, 'works': works, 'fans': fans, 'box_office': box_office} print(China_name, English_name, profession, birthday, height, works, fans, box_office) return item def get_md5(url): """ :return: url的md5值 """ md5 = hashlib.md5() md5.update(url.encode('utf-8')) return md5.hexdigest() def save(item, url): """ 将获取的结果保存到mongoDB中 :param item: :param url: :return: """ item['_id'] = get_md5(url) collection.update_one({'_id': item['_id']}, {'$set': item}, True) def parse(content): """ 解析css加密的字体 :param content: :return: """ for code, font in font_dict.items(): content = content.replace('&#x' + code[3:].lower() + ';', font) return content def seen_url(url): """ redis去重 :param url: :return:添加成功的素数量。 """ res = r.sadd("actor_url", get_md5(url)) return res def run(): """ 引擎函数 :return: """ while True: if scheduler.empty(): break url = scheduler.get() # 判断当前的url是否请求过,若返回值非零则没有请求 if seen_url(url): # 调度下载器,下载网页源代码 response = downloader(url) # 下载字体加密的woff文件 woff = get_woff(response.text) # 获取加密码字体的编码列表 code_list = get_font_code(woff) # 获取编码列表和对应字体构成的替换字典 get_font_dict(code_list) # 解析html中所有的加密字体,返回正常文本 content = parse(response.text) # 调用爬虫组件,爬取解析文本后的字段 item = spider(content) # 将爬取的字段保存到mongo数据库中 save(item, url) # 爬取相关影人的url并存放至调度器中 html = etree.HTML(content) related_url = html.xpath('//div[@class="rel-item"]/a/@href') for url in related_url: ful_url = 'https://maoyan.com' + url scheduler.put(ful_url) if __name__ == '__main__': # 连接MongoDB数据库 client = pymongo.MongoClient(host='127.0.0.1', port=27017) db = client['movies'] collection = db['actors'] # 连接redis数据库,用于指纹去重 r = redis.Redis(host='127.0.0.1', port=6379) # 定义滑块验证后url,初始值为空 check_url = "" # 实例化Options对象 options = Options() # 启动开发者模式 options.add_experimental_option('excludeSwitches', ['enable-automation']) options.add_experimental_option('useAutomationExtension', False) # 起始的url start_url = [ 'https://maoyan.com/films/celebrity/789', 'https://maoyan.com/films/celebrity/6365', 'https://maoyan.com/films/celebrity/31444', 'https://maoyan.com/films/celebrity/12070' ] # 被css加密的字体列表 font_list = ['6', '3', '7', '9', '1', '8', '0', '4', '2', '5'] # 定义破解字体加密的字体替换字典,键值为字体码,值为字体列表所对应的值 font_dict = {} # 每次请求的请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36' } # 创键url调度队列 scheduler = Queue() for url in start_url: scheduler.put(url) # 启动程序 run()
天青色等烟雨而我在等你!

