Pandas数据分析基础应用
给定数据文件data.csv,其中记录的是用户用电数据。数据中有编号为1~200的200位用户,DATA_DATE表示时间,如:2015/1/1表示2015年1月1日, KWH表示用电量。
文件下载:
链接:https://pan.baidu.com/s/15PvDmfDqgdNM1hXAa59L8A
提取码:a245
请用给定的数据,实现以下任务:
数据转置
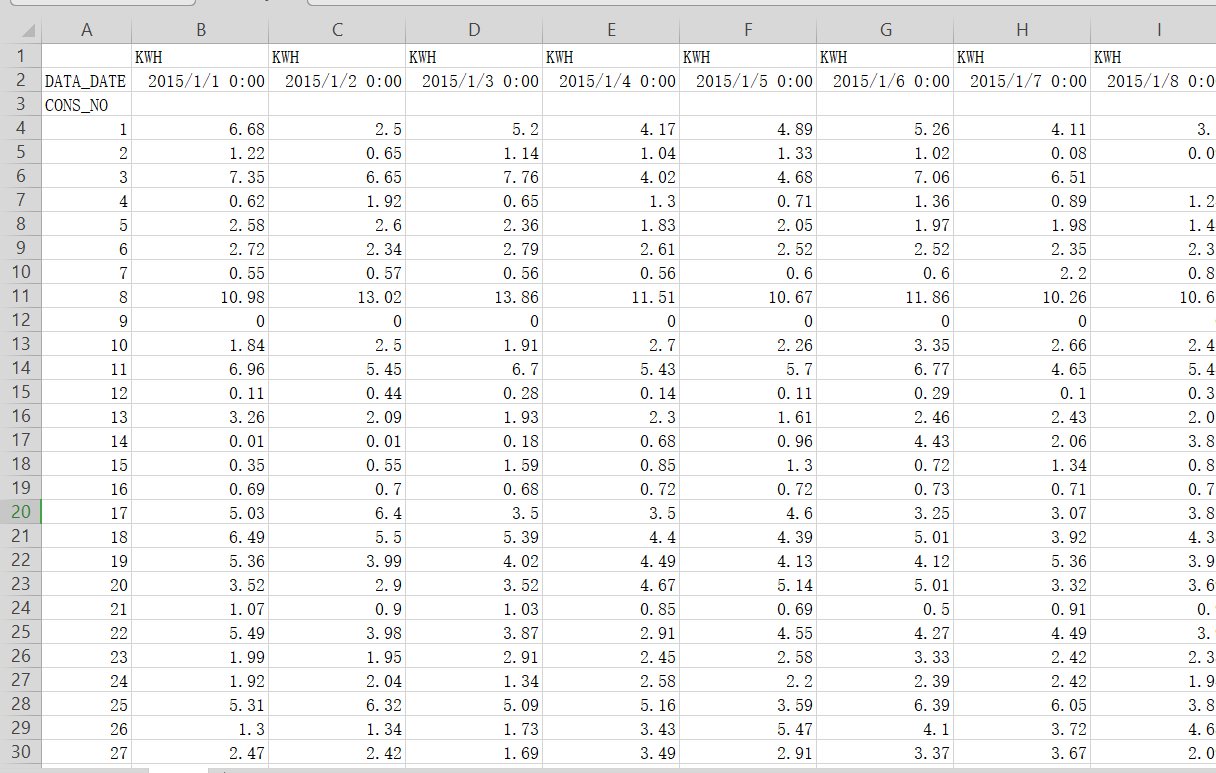
将数据进行转置,转置后型如eg.csv, 缺失值用NAN代替。
分析过程:

转置的话想到了numpy的T,但是他的话是直接转的,和所给的eg.csv格式不相同而且转了之后对数据处理没有任何用处。给的例子是以CONS_NO为索引,DATA_DATE为字段的,脑子里没啥想法,于是百度
pandas的转置,pandas的透视表,我感觉写的很详细了。
找到了pivot_table()函数,即透视表,一种可以对数据动态排布并且分类汇总的表格格式。用pd.pivot_table(data, index='CONS_NO', columns='DATA_DATE')进行转置即可。
在excel里面也是有这个功能的。

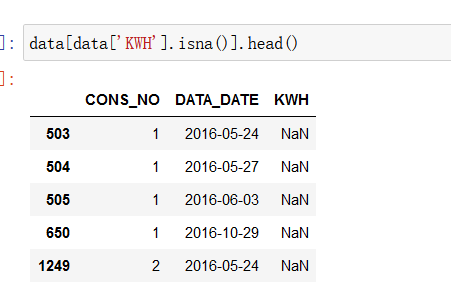
缺失值的识别和替换,用isnull()判断是否为空值,sum()函数对空值进行统计,替换的话用fillna(),功能是填充缺失值,这里要注意不要直接用字符串‘NAN’,要用np.NAN,不然数据类型会不同,很难处理。
读cvs的时候,需要将DATA_DATE以时间类型读入。
还有就是空值和缺失值的区别也要注意:空值在pandas中的空值是"";而缺失值在dataframe中为nan或者naT(缺失时间),在series中为none或者nan。
代码:
import pandas as pd
import numpy as np
#(1)数据转置,缺失值用NAN代替。
data = pd.read_csv('data.csv', parse_dates=[1])
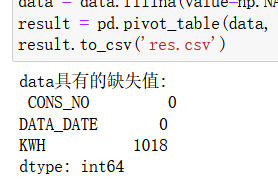
null_value = data.isna().sum() # 缺失值识别
print("data具有的缺失值:\n",null_value)
data = data.fillna(value=np.NAN) # 不要直接用字符串‘NAN’否则数据类型会不同。
result = pd.pivot_table(data, index='CONS_NO', columns='DATA_DATE')
result.to_csv('res.csv')
实验结果:
异常值识别
对数据中的异常值进行识别并用NA代替。
分析过程:
异常值和缺失值是不同的概念,要搞清楚。异常值是指数据中个别值的数值明显偏离其余的数值,有时也成为离群点,检测异常值就是检验数据中是否有录入错误以及是否含有不合理的数据。怎么检测呢,继续百度。
异常值的检测常用的方法有:业务法、3σ原则和箱线图分析。
我采用3σ原则检测异常值:如果数据服从正态分布,异常值被定义为一组测定值中与平均值的偏差超过3倍的值 → p(|x - μ| > 3σ) ≤ 0.003。
异常数据常用处理方法:
1.删除法(前提是异常观测的比例不能太大)
2.替换法(可以考虑使用低于判别上下限的最大值或最小值,均值或中位数替换等)
题目是用NA代替。
代码:
# (2)异常值识别/代替
u = data['KWH'].mean() # 平均值
si = data['KWH'].std() # 标准差
three_si= data['KWH'].apply(lambda x: x>u+3*si or x<u-3*si )
# print(three_si)
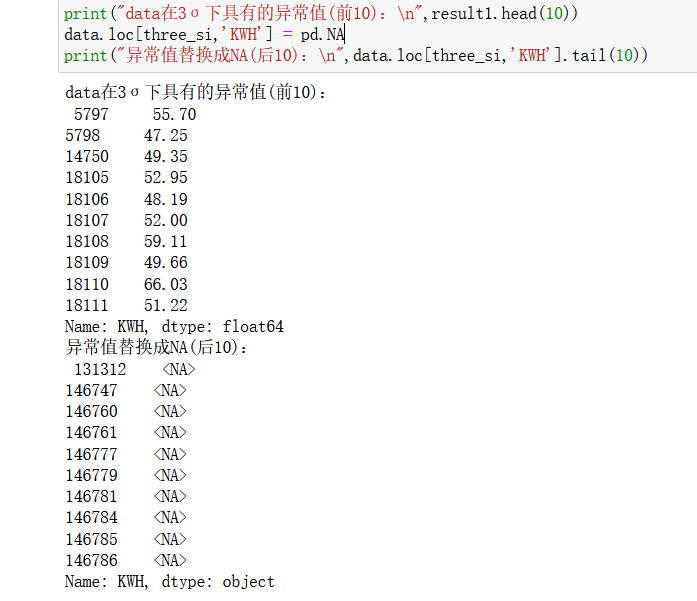
result1 = data.loc[three_si,'KWH'] # 使用3σ方法识别异常值
print("data在3σ下具有的异常值(前10):\n",result1.head(10))
data.loc[three_si,'KWH'] = pd.NA
print("异常值替换成NA(后10):\n",data.loc[three_si,'KWH'].tail(10))
实验结果:
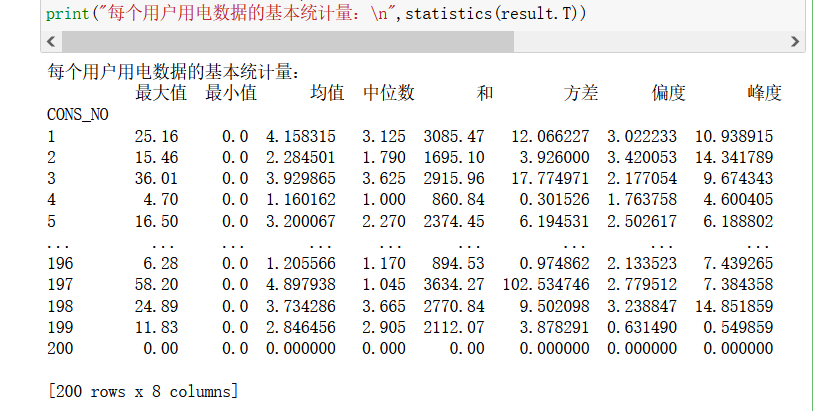
每个用户用电数据的基本统计量
计算每个用户用电数据的基本统计量,包括:最大值、最小值、均值、中位数、和、方差、偏度、峰度。(不包括空值)
分析过程:
主要是几个函数的运用,具体如下:
| 功能 |函数 |功能 |函数|
|--|--|--|--|--|
| 最大值 | df.max() | 和 | df.sum() |
| 最小值 | df.min() | 方差 | df.var() |
| 均值 | df.mean() | 偏度 | df.skew() |
| 中位数 | df.median() | 峰度 | df.kurt() |
因为展示出来的格式对的不太齐,看着很难受,于是也百度了下对表格输出的格式化展示。
代码:
# (3)求每个用户的统计量
def statistics(df): # 数据统计并合并统计量
statistical_table = pd.concat([df.max(), df.min(), df.mean(), df.median(), df.sum(), df.var(), df.skew(), df.kurt()],axis=1)
statistical_table.columns = ['最大值','最小值','均值','中位数','和','方差','偏度','峰度']
return statistical_table
# 对其输出
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.width',180) # 设置打印宽度(**重要**)
print("每个用户用电数据的基本统计量:\n",statistics(result.T))
实验结果:
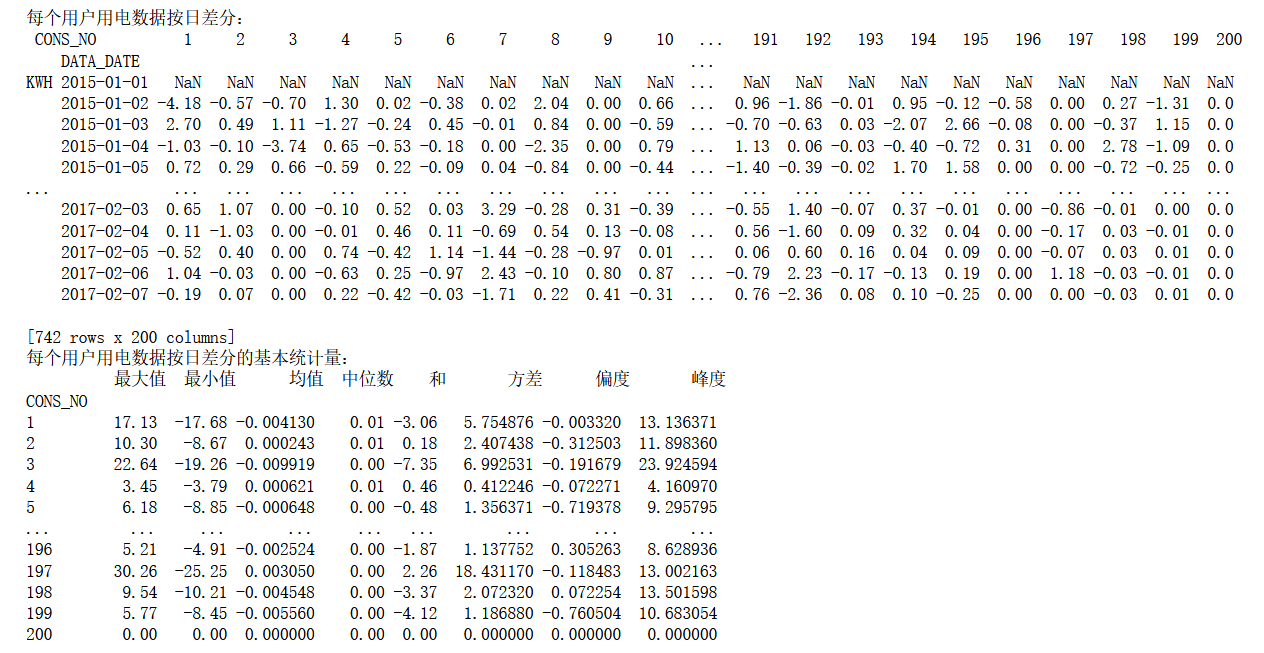
用电数据按日差分
计算每个用户用电数据按日差分,并计算差分结果的基本统计量,统计量同上述第3问。
分析过程:
差分(difference methods):统计学中的差分,就是指离散函数的后一项减去前一项的差。这里可以使用diff方法进行。
diff的基本使用方法:
| 函数 | 功能 |
|---|---|
| df.diff() | 纵向一阶差分,当前行减去上一行 |
| df.diff(axis=1) | 横向一阶差分,当前列减去左边的列 |
| df.diff(periods=2) | 纵向二阶差分 |
| df.diff(periods=2).dropna() | 纵向二阶差分,丢弃空值 |
这里对result进行横向一阶差分,再调用statistics,对按日差分的数据进行统计,并输出所有的基本统计量。
代码:
# (4)每个用户用电数据按日差分,差分结果的基本统计量
difference = result.diff(axis=1) # 横向一阶差分
print("每个用户用电数据按日差分:\n",difference.T)
print("每个用户用电数据按日差分的基本统计量:\n",statistics(difference.T))
实验结果:
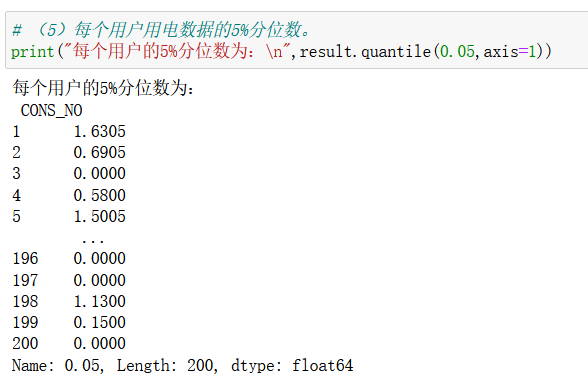
用电数据的5%分位数
计算每个用户用电数据的5%分位数。
分析过程:
运用df.quantile()函数求分位数。
代码:
# (5)用电数据的5%分位数。
print("每个用户的5%分位数为:\n",result.quantile(0.05,axis=1))
实验结果:
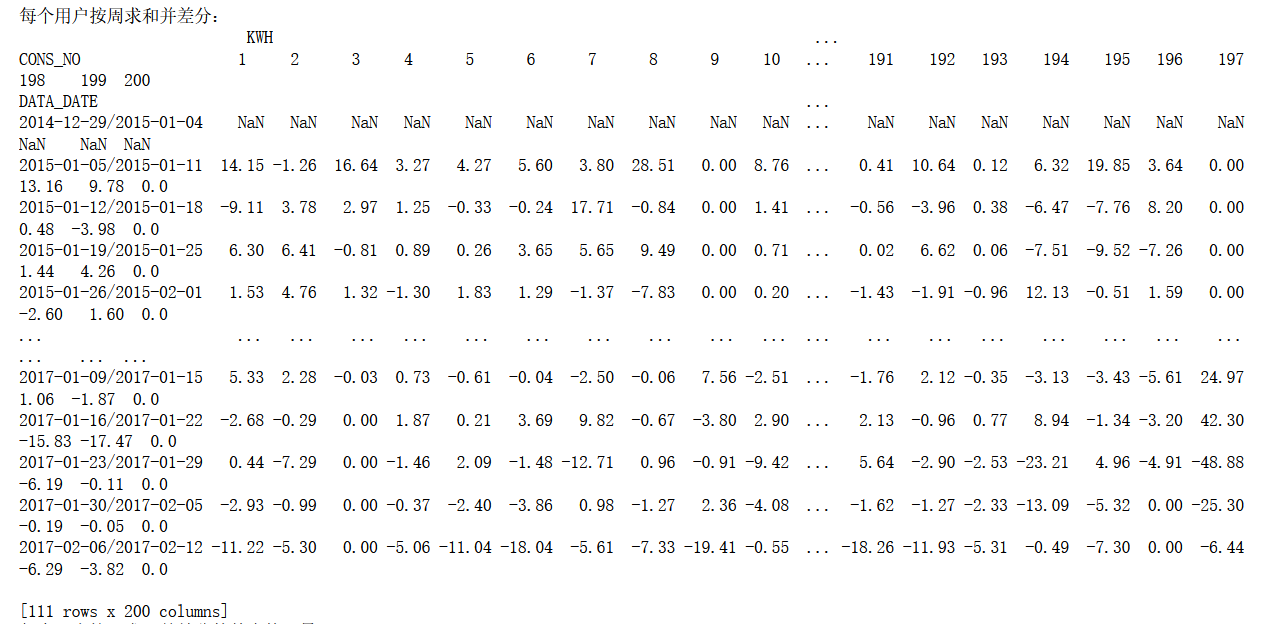
用电数据按周求和并差分
对每个用户的用电数据按周求和并差分(一周7天),计算差分结果的基本统计量,统计量同第3问。
分析过程:
首先要把每周分开,这里使用pd.PeriodIndex重组时间序列 :主要将数据中的分离的时间字段,重组为时间序列,并指定为index。DATA_DATE按周的频率排列,使用rep='w',同时获取其索引。
接着按照CONS_NO及new_index进行分组,并求和。创建透视表,差分,最后使用statistics统计基本统计量。
代码:
# (6) 每个用户数据按周求和并差分(一周7天),差分结果的基本统计量
w_index = pd.PeriodIndex(data['DATA_DATE'], freq='w')
sum_week = data.groupby(by=['CONS_NO', w_index]).sum()
week_table = pd.pivot_table(sum_week, index='DATA_DATE', columns='CONS_NO')
# print(week_table)
diff_week = week_table.diff(1)
print("每个用户按周求和并差分:\n",diff_week)
print("每个用户按周求和并差分的基本统计量:\n",statistics(diff_week))
实验结果:
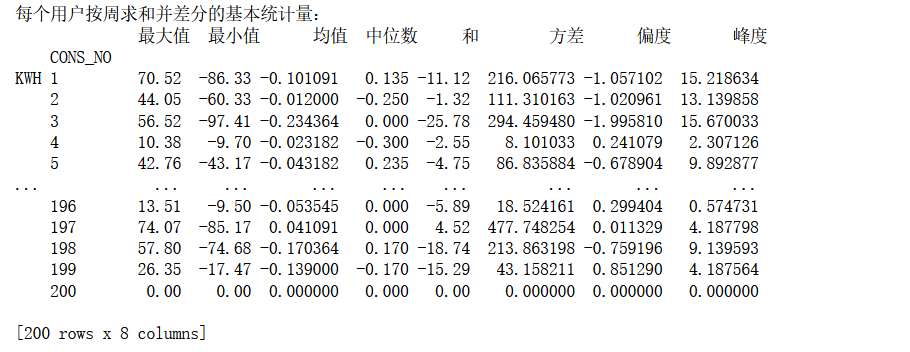
用电数大于‘0.9最大值’的天数
每个用户在一段时间内会有用电数据最大值,统计用电数大于‘0.9最大值’的天数。
分析过程:
apply方法。df.apply(func, axis=0) :将函数func 应用到DataFrame对象df的行或列所构成的一维数组上。
代码:
# (7) 每个用户用电数大于‘0.9最大值’的天数
max_d = result.apply(lambda x:x>x.max()*0.9,axis=1).sum(axis=1)
print("每个用户用电数大于‘0.9最大值’的天数:\n",max_d)
实验结果:

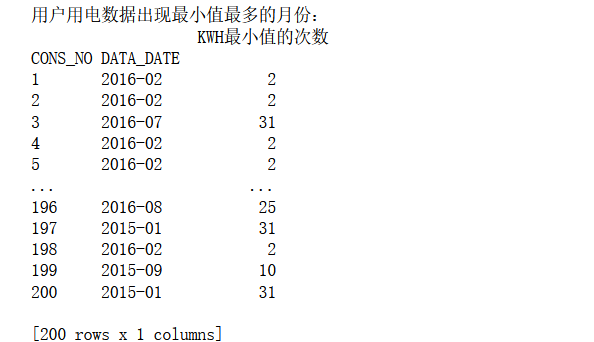
用电数据出现最大值和最小值的月份分析
获取每个用户用电数据出现最大值和最小值的月份,若最大值(最小值)存在于多个月份,则输出含有最大值(最小值)最多的那个月份。我们按天统计每个用户的用电数据,假设1号用户用电量的最小值为0(可能是当天外出没有用电),在一年的12个月,每个月都有可能有若干天用电量为0,那么就输出含有最多用电量为0的天数所在的月份。最大用电量统计同理。
分析过程:
尝试了好多次,本来是想要按月分组,然后找出每个人的最小值,然后统计最小值的月出现最小值的个数,取最大个数得出结论。但是尝试了好4、5个小时,一直失败,什么key有问题啊各种奇奇怪怪的报错,真的要吐了。于是借鉴了网上的方法,我真是菜鸡。
对于最小值,每月基本都有0,所以直接先求出整个data数据中最小值的索引,获得的索引使用iloc进行切片,再使用PeriodIndex方法和groupby使得DATA_DATE以月为单位进行分组。接着使用count()函数计算出每月出现最小值的次数(因为筛选后的数据只有最小值了,所以可以用count)。接下来使用reset_index与idxmax方法获取含有最小值最多的那个月份的索引,最用将获得的索引使用iloc进行切片,得到所需结果。
最大值也是同理,但是没有最小值那么复杂,不过个人觉得代码似乎有些小问题。
代码:
# (8)每个用户用电数据出现最大值和最小值最多的月份
print("用户用电数据出现最小值最多的月份:")
min_index = data[(data.KWH == data.KWH.min())].index # 最小值的索引
min_temp = data.iloc[min_index]
m_index = pd.PeriodIndex(min_temp['DATA_DATE'], freq='m')
min_count_df = pd.DataFrame(min_temp.groupby(['CONS_NO', m_index])['KWH'].count())# 按月进行分组,求最小值个数
min_count_df.columns = ['KWH最小值的次数']
min_count_df_index = min_count_df.reset_index().groupby('CONS_NO')['KWH最小值的次数'].idxmax()# 出现最小值次数最多的月份索引
min_value = min_count_df.iloc[min_count_df_index]
print(min_value) # 输出含有最小值最多的那个月份
print("用户用电数据出现最大值最多的月份:")
m_index = pd.PeriodIndex(data['DATA_DATE'], freq='m')
mon_df =pd.DataFrame(data.groupby(['CONS_NO',m_index])['KWH'].max())# 按月进行分组,并求
max_index = mon_df.reset_index().groupby('CONS_NO')['KWH'].idxmax()
max_value = mon_df.iloc[max_index]
max_value.columns = ['各用户的KWH最大值']
print(max_value) # 输出含有最大值最多的那个月份
实验结果:

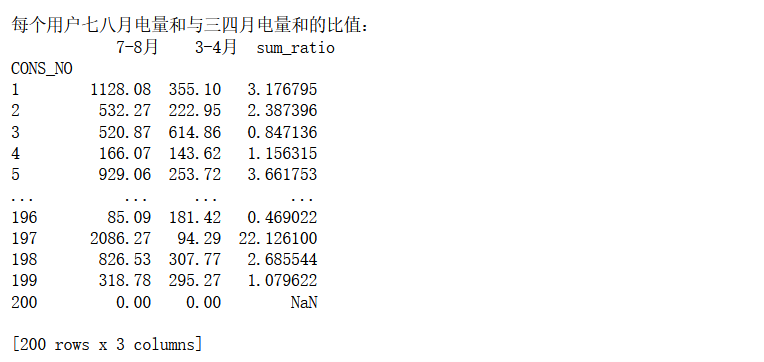
7月和8月用电数据与3月和4月用电数据分析
以每个用户7月和8月用电数据为同一批统计样本,3月和4月用电数据为另一批统计样本,分别计算这两批样本之间的总体和(sum)之比,均值(mean)之比,最大值(max)之比和最小值(min)之比。
分析过程:
因为要统计7、8月和3、4月,所以要按月划分,所以先用一次PeriodIndex和groupby,对于分组后的数据先做第一次分析,及求每月的最大值、最小值、均值、和;接着筛选出7、8月和3、4月的数据,这里用idx = pd.IndexSlice 层级索引创建对象以更轻松地执行多索引切片,得到两个表。接着以'CONS_NO'进行分组,对相关数据进行第二次分析,即所筛选出来的这几个月的最大值、最小值、均值、和,两次分析后得到78月和34月这几个相关值的数据,再写一个函数计算这两个表每列之间的比值,这里要把每列提出来,然后计算,最后将结果放在一个总结表里即可。
代码:
# (9)7、8月和3、4月相关比值
def date_filter(df): # 日期筛选,返回两张表
idx = pd.IndexSlice
mon78 = df.loc[idx[:,['2015-7','2015-8', '2016-7', '2016-8']],:]
mon34 = df.loc[idx[:,['2015-3','2015-4', '2016-3', '2016-4']],:]
return mon78, mon34
def date_merge(df_1, df_2, name): # 合并符合要求的日期,同时进行比值处理
df_ratio = pd.merge(df_1, df_2, on='CONS_NO')
df_ratio.columns = ['7-8月', '3-4月']
df_ratio[name] = df_ratio['7-8月'] / df_ratio['3-4月']
return df_ratio
def analysis(df): # 每月数据统计
a_table = pd.concat([df.max()['KWH'], df.min()['KWH'], df.mean(), df.sum()],axis=1)
a_table.columns = ['最大值','最小值','均值','和']
return a_table
def analysis2(df):# 筛选出来的数据统计
a2_table = pd.concat([df['最大值'].max(),df['最小值'].min(),df['均值'].mean(),df['和'].sum()],axis=1)
return a2_table
m_index = pd.PeriodIndex(data['DATA_DATE'], freq='m')
m_all = data.groupby(['CONS_NO', m_index])# 按月进行分组
mon78,mon34 = date_filter(analysis(m_all))
mon_78 = analysis2(mon78.groupby('CONS_NO'))
mon_34 = analysis2(mon34.groupby('CONS_NO'))
col = ['最大值','最小值','均值','和']
names=['max_ratio','min_ratio','mean_ratio','sum_ratio']
summary_table = pd.DataFrame()
for i in range(4):
print('每个用户七八月电量%s与三四月电量%s的比值:'%(col[i],col[i]))
ratio_table = date_merge(mon_78[col[i]], mon_34[col[i]], names[i])
summary_table[names[i]] = ratio_table[names[i]]
print(ratio_table,'\n')
print('上述比值整合:\n',summary_table)
实验结果:
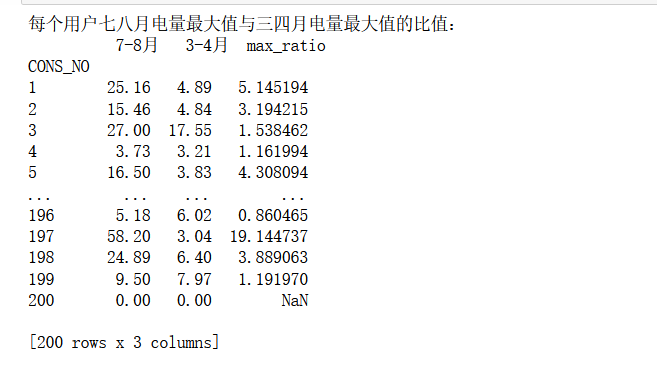

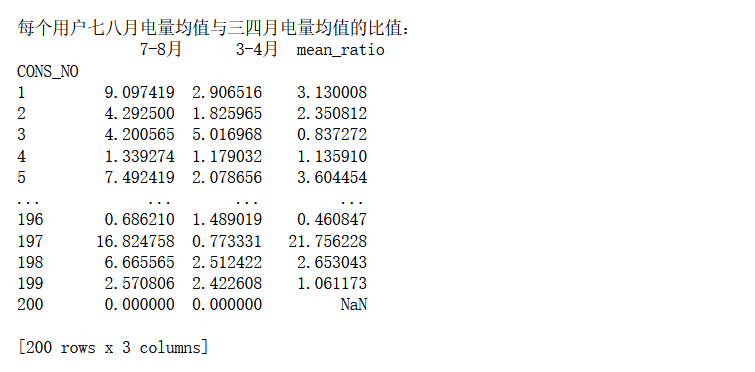
Ps:这里有另外一个注意事项,在jupyter里面看不出来。我再本地又运行了一遍,发现直接按照上述代码,会报错。当时就很懵逼,明明jupyter运行很完美,说明程序没有大问题,但是它在我本地就报错,我就不开心了。报错如下:
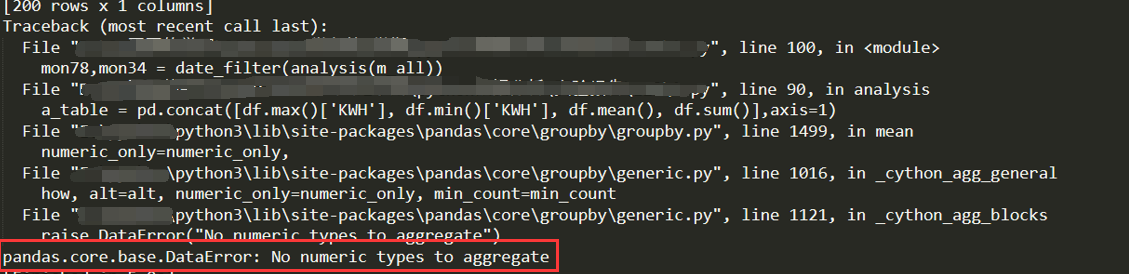
百度了差不多1个小时,讲道理,百度报错解决办法是真的难,冷僻的错误基本上很少有解决办法,不过在我坚持不懈下还是找到了。其实它主要问题是出在mean()上,因为他有可能都是0,或者NAN,就会运算不了,jupyter似乎自己解决了?要修正的话,就是numeric_only=False,再取对应列即可,代码改成如下:

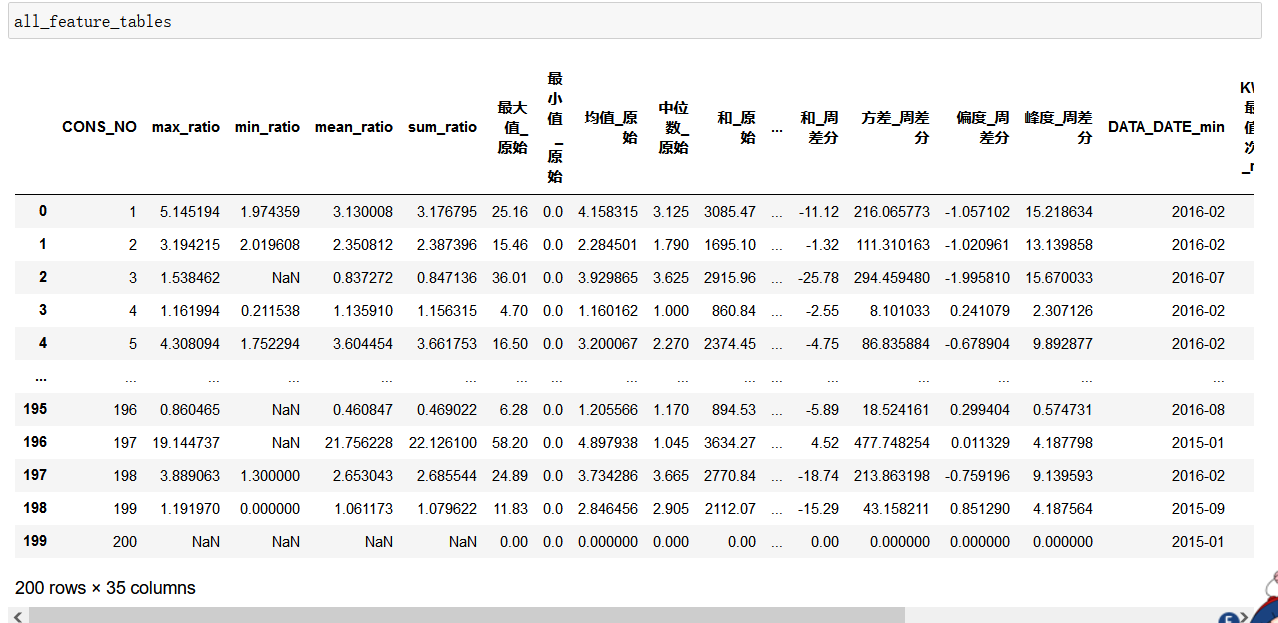
特征合并
将上述统计的所有特征合并在一张表格中显示出来。
分析过程:
上面写了好多特征,原始统计量,日差分统计量等等,上面的代码里面好多个都是直接输出的,并没有存储,而且有些类型是series,不统一。所以第一步就是把他们全部转化成DataFrame。对于合并,不能列名不能相同,好些个统计量都是重名,当然直接合并也可以,程序会直接区分,给你在后面加个_x,或者_y,但是依然不好区分。所以我写了个重命名列的函数,在初始列名后面加个标注或者直接重命名了。这里要注意的是min_value和max_value这两个,这两个首先要rest_index,不然索引会出问题(又是出错了n++++++次之后才领悟的)。我采用的是merge函数进行合并,这个类似于数据库的操作,相比于concat的直接拼接需要用共同的索引连接,但是免去了一个个查看去找要插入的列名。merge()只能完成两张表的连接,若有三个及以上表,需不断两两合并来实现。
代码:
# (10)将上述统计的所有特征合并在一张表格中显示出来
# (concat,merge,join和append)的区别 https://blog.csdn.net/weixin_42782150/article/details/89546357
def rename_columns(df,add):
new_col = list()
for i in df.columns:
if i != 'CONS_NO':
new_col.append(i+add)
else:
new_col.append(i)
df.columns=new_col
return df
df1 ,df2,df3,df4 ,df5= statistics(result.T),statistics(difference.T),statistics(diff_week),min_value.reset_index(),max_value.reset_index()
df6,df7= pd.DataFrame(result.quantile(0.05,axis=1)),pd.DataFrame(max_d)
adds = ['_原始','_日差分','_周差分','_min','_max']
new = ['5%分位数','kwh>0.9max的天数']
dfs=[df1,df2,df3,df4,df5,df6,df7]
all_feature_tables = summary_table
for i in range(len(dfs)):
if i < 5:
a = rename_columns(dfs[i],adds[i])
# print(a.columns)
all_feature_tables = pd.merge(all_feature_tables,a,on='CONS_NO')
elif i < 7:
dfs[i].columns=[new[i-5]]
# print(dfs[i])
all_feature_tables = pd.merge(all_feature_tables,dfs[i],on='CONS_NO')
all_feature_tables.to_csv('all_feature_tables.csv')
实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号