
软工实践寒假作业(2/2)
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读构建之法并提出思考;学习github |
| 作业正文 | ... |
| 其他参考文献 | ... |
目录
一、对《构建之法》的思考
问题1
在书中的第一章节讲软件的一些背景知识,我在看到书中第15页,书里讲到什么是好的软件,似乎并没有给出一个明确的答案。那么软件开发
的质量到底是如何衡量的呢?
通过网上查阅资料主要总结为两个方面: 1、外部质量:从用户、使用者角度去衡量;2、内部质量:从员工、开发者角度去衡量;
一、衡量外部质量 1、正确性 2、易用性 3、高效率 4、适应性 5、精确性 6、完整性
二、衡量内部质量 1、可维护性 2、灵活性 3、可移植性 4、可读性 5、可测试性
问题2
在第四章的75页,有对goto进行描述,书中有句话这样说“只要有助于程序逻辑的清晰体现,什么方法都可以使用,包括goto”,
我的观点是不赞同,学过一点关于这个语句的用法,记得以前王灿辉老师也说这个语句最好不用,也极少用这个语句,查资料
goto语句不受限制的跳转,这样会导致结构化设计风格,还会降低代码的可读性,这样我觉得这个语句弊大于利,能不用就不用。
问题3
书中第8章讲了需求分析,在我们着手一个项目开发设计,编码之前需要了解客户需求,怎样才能够准确了解和挖掘他们对软件的
需求,引导出真实的需求,太难了,到底用户调研能不能获取到真实的用户需求,我们如何能够通过比较好的用户交流,比较全面
的了解和弄清他们的需求呢?这有没有好的一套方法流程?这样就会不会在详细设计过程中又反过来讨论需求呢?
问题4
在书中第238页讲了一个表达控制流,有限状态自动机,但是我不知道是怎样来表达控制流的,
我想问这在解决问题建模时怎么来用它?控制流和数据流之间又是怎么进行交流?需要进行什么样的控
制,查阅资料说有限自动机是一种计算模式,是表示有限个状态以及在这些状态之间的转移和动作等行
为的数学模型。
问题5
在书中291页讲到压力测试,书中说压力测试就是验证软件在超过设计负载的情况下是否能返回
正常结果,不产生严重的副作用和崩溃。超负载下我们的程序到底能不能正常运行,不死机,我提出问
题怎样进行压力测试怎样才是刚好?为什么很多“小”问题在加压下就会被放大?我理解的这样进行加
压的测试是不是会因为内存泄露或者资源泄露,产生死锁而得不到压力测试的临界点。
二、WordCount编程
1、Github项目地址
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 400 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 300 | 400 |
| · Code Review | · 代码复审 | 100 | 150 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 40 | 60 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measuremen | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 810 | 1085 |
3、解题思路描述
- 统计文件字符数:按行读取文件并存入字符串s,累加行的长度 s.length()
- 统计文件行数:按行读取文件,每读取一行行数加一
- 统计文件单词总数:将读入的字符串按照分隔符(除了字母数字以外的字符)分开成为可以判断是否为单词的单元,是则单词数加一,否则不加
- 统计单词出现的频次:用上述方法判断单词,若是则存入map容器,map容器的key为单词,value为单词的频数
4、代码规范制定链接
5、设计与实现过程
- 类的设计: WordCount类(主函数入口)Lib类(功能函数)FileUtil类(通过文件路径获取一个File类)
- 功能函数的设计:
1、 统计文件字符和行数的就略过了(比较简单明了)
2、 统计单词数: - 将读入的字符串str用split函数按照分隔符分隔成若干子串存入字符串数组splited中
String splited[] = str.split("[^a-zA-Z0-9]"); - 将splited数组中每一个字符串拿出来判断是否为单词,判断方法:截取splited[i]的前4个字符存入字符串temp,然后将temp字符中除了字母以外的符号去掉,
若此时temp长度仍>=4,说明splited[i]前四个字符都是字母,符合单词的特征。具体代码如下:
for (int i = 0; i < splited.length; i++) {
if (splited[i].length() >= 4 ) {
String temp = splited[i].substring(0, 4);
temp = temp.replaceAll("[^a-zA-Z]", "");
if (temp.length() >= 4) {
if (map.containsKey(splited[i].toLowerCase())) {
map.put(splited[i].toLowerCase(), map.get(splited[i].toLowerCase())+1);
}
else {
map.put(splited[i].toLowerCase(), 1);
}
}
}
}
3、 统计单词频数:
- 第一步判别单词采用上述的方法,并将结果存入map容器,map容器的key为单词,value为单词的频数
- 第二步则是单词的排序,通过重写比较器来实现,代码如下:
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
// 通过比较器来实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
// 降序排序
return o2.getValue().compareTo(o1.getValue());
}
});
6、性能改进
- 采用BufferReader和BufferWriter类,即缓冲数据流来提高读写效率
- 中途修改了几个正则表达式,提高了判断的精度
7、单元测试
使用Junit进行单元测试,下列代码为其中的一个函数wordsCount的测试示例
@org.junit.jupiter.api.Test
void wordsCount() throws Exception {
Lib lib = new Lib();
FileUtil fileUtil = new FileUtil();
String pathname = System.getProperty("user.dir") + "\\src\\input.txt";
File file = fileUtil.getFile(pathname);
int n = lib.wordsCount(file);
System.out.println(n);
}
测试结果如下图:
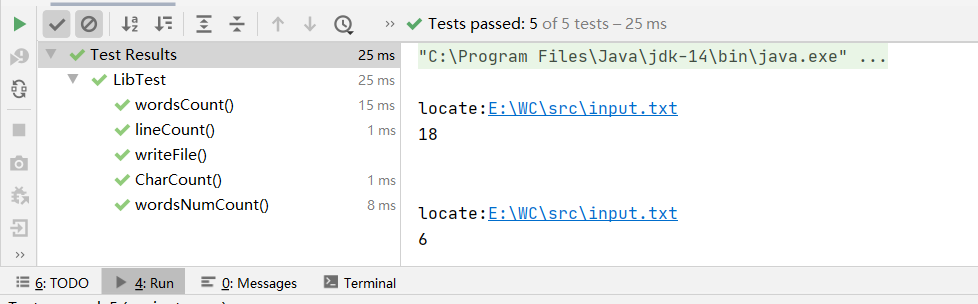
覆盖率截图:
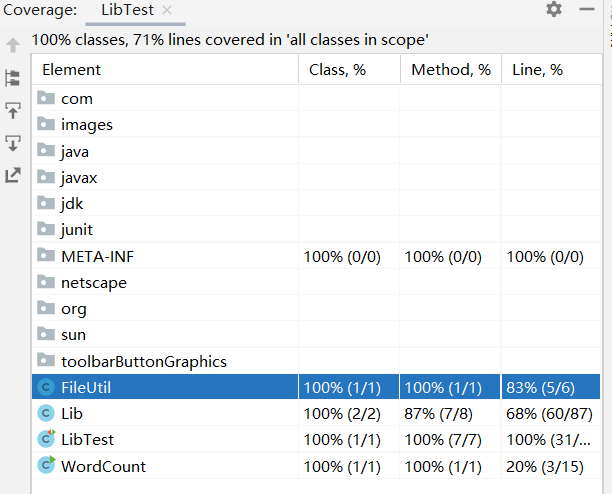
8、异常处理说明
只做了文件异常处理(找不到文件等等)
9、心路历程与收获
一开始看到作业感觉好复杂,github之前没怎么接触过,又因为最近在准备考研,所以有点抵触这个作业,但是终究还是要做的。由于太久没碰过java了,所以打代码的过程中也是磕磕碰碰,尤其是编码的问题出现一个bug,当时找不到问题出在哪,浪费了很多时间,把自己搞的很烦躁,还好室友华央哥救了我一命,感谢万能的他!
虽然打乱了自己的复习计划,但是这个作业还是学到了挺多的,也复习了java的知识,磨练了耐心,增强了抗压力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号