【Service Center】深入分析
为什么需要服务注册中心?
老式单体结构非常臃肿,部署在一个集群上,不够灵活。在演进的过程中,架构师分散地进行了拆分,慢慢演进成微服务的架构。
单体架构到微服务架构的演进中的确带来了很多好处,比如架构业务实现了解耦,单一职责,而且每一个服务可以独立运行。在开发运维上成本也更低,迭代上线周期更短,解放了程序员的生产力。
但同时也引入了新的问题。比如业务间的通信发生了变化,需要远程通信调用。要解决通信上的问题,除了定制一个业务间通信的标准协议之外,还需要一个具有服务注册和服务发现能力的组件,能够保存业务进程的一些实例信息,还能提供查询实例IP地址的标准接口给各个业务去使用。
适合做服务注册中心的开源组件
有Service Center,eureka,etcd,zookeeper和consul。
Service Center
从微服务到服务管理中心_实例缓存机制
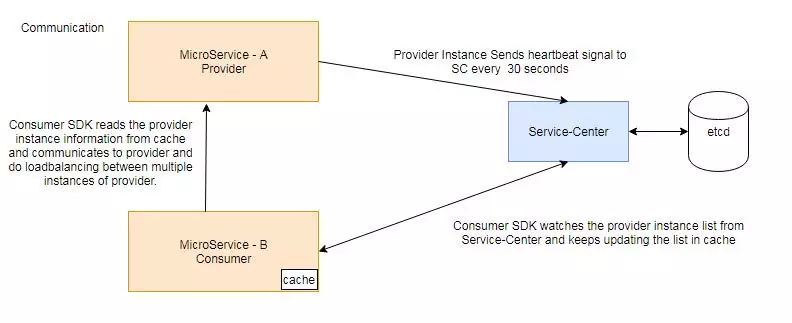
基于ServiceComb的SDK开发的微服务在第一次消费provider时,会进行一次实例发现的操作,此时内部会请求Service Center拉取provider存活的实例集合,并保存到内存缓存中。后续消费请求就依据该缓存实例集合,按照自定义的路由逻辑发送到Provider的一个实例服务中。
这样处理的好处是,已经运行态的SDK进程,始终保留一份实例缓存;虽然暂时无法感知实例变化及时刷新缓存,但当重新连上ServiceCenter后会触发一缓存刷新,保证实例缓存是最终有效的;在此过程中SDK保证了业务始终可用。

从微服务到服务管理中心——心跳保活机制
ServiceCenter的微服务实例设计上是存在老化时间的,SDK通过进程上报实例心跳的方式保活,当Provider端与ServiceCenter之间心跳上报无法保持时,实例自动老化,此时ServiceCenter会通知所有Consumer实例下线通知,这样Consumer刷新本地缓存,后续请求就不会请求到该实例,也就微服务的实现动态发现能力。
这样做的好处是,解决了业务某个实例进程下线或异常时,依赖其业务的微服务实例,会在可容忍时间内,切换调用的目标实例,相关业务依然可用。
从微服务管理中心到etcd——异步缓存机制
在ServiceCenter内部,因为本身不存储数据,如果设计上单纯的仅作为一个Proxy服务转发外部请求到etcd,这样的设计可以说是不可靠的,原因是因为一旦后端服务出现故障或网络访问故障,必将导致ServiceCenter服务不可用,从而引起客户端实例信息无法正确拉取和刷新的问题。所以在设计之初,ServiceCenter引入了缓存机制。

-
启动之初,ServiceCenter会与etcd建立长连接(watch),并实时资源的变化。 -
每次watch前,为防止建立连接时间窗内发生资源变化,ServiceCenter无法到这些事件,会进行一次全量list查询资源操作。 -
运行过程中,List & watch所得到的资源变化会与本地缓存比对,并刷新本地缓存。 -
微服务的实例发现或静态数据查询均使用本地缓存优先的机制。
异步刷新缓存机制,可以让ServiceCenter与etcd之间的缓存同步是异步的,微服务与ServiceCenter间的读请求,基本上是不会因为etcd不可用而阻塞的;虽然在资源刷新到ServiceCenter watch到事件这段时间内,会存在一定的对外呈现资源数据更新延时,但这是可容忍范围内的,且最终呈现数据一致;这样的设计即大大提升了ServiceCenter的吞吐量,同时保证了自身高可用。
从微服务管理中心到etcd——异步心跳机制
中心化设计,另一个难题是,性能问题,基于心跳保活机制,随着实例数量增加,ServiceCenter处理心跳的压力就会越大;要优化心跳处理流程,首先了解下ServiceCenter怎么实现实例心跳的。
实例心跳,主要是为了让ServiceCenter延长实例的下线时间,在ServiceCenter内部,利用了etcd的KeyValue的lease机制来计算实例是否过期。lease机制的运作方式是,需保证在定义的TTL时间内,发送keepalive请求进行保持存储的数据不被etcd删除。基于这个机制,ServiceCenter会给每个实例数据设置下线时间,外部通过调用心跳接口触发ServiceCenter对etcd的keepalive操作,保持实例不下线。
可以知道,这样设计会导致上报心跳方因etcd延时大而连接阻塞,上报频率越高,ServiceCenter等待处理连接队列越长,最终导致ServiceCenter拒绝服务。

在这里ServiceCenter做了一点优化,异步心跳机制。
ServiceCenter会根据上报实例信息中的心跳频率和可容忍失败次数来推算出最终实例下线时间,比如:某实例定义了30s一次心跳频率,最大可容忍失败是3次,在ServiceCenter侧会将实例定义为120s后下线。另外,在实例上报第一次心跳之后,ServiceCenter会马上产生一个长度为1的异步队列,进行请求etcd,后续上报的心跳请求都会在放进队列后马上返回,返回结果是最近一次请求etcd刷新lease的结果,而如果队列已有在执行的etcd请求,新加入的请求将会丢弃。
这样处理的好处是持续的实例心跳到ServiceCenter不会因etcd延时而阻塞,使得ServiceCenter可处理心跳的能力大幅度的提高;虽然在延时范围内返回的心跳结果不是最新,但最终会更新到一致的结果。
从微服务管理中心到etcd——自我保护机制
前面提到的缓存机制,保证了ServiceCenter在etcd出现网络分区故障时依然保持可读状态,ServiceCenter的自我保护(Self-preservation)机制保证了Provider端与ServiceCenter在出现网络分区故障时依然保持业务可用。
现在可以假设这样的场景:全网大部分的Provider与ServiceCenter之间网络由于某种原因出现分区,Provider心跳无法成功上报心跳。这样的情况下,在ServiceCenter中会出现大量的Provider实例信息老化下线消息,ServiceCenter将Provider实例下线事件推送到全网大部分的Consumer端,最终导致一个结果,用户业务瘫痪。可想而知对于ServiceCenter乃至于整个微服务框架是灾难性的。
为了解决这一问题,ServiceCenter需要有一个自我保护机制(Self-preservation)
-
ServiceCenter在一个时间窗内监听到etcd有80%的实例下线事件,会立即启动自我保护机制。 -
保护期间内,所有下线事件均**保存在待通知队列**中。 -
保护期间内,ServiceCenter收到队列中实例上报注册信息则将其从队列中移除,否则当实例**租期到期**,则推送实例下线通知事件到consumer服务。 -
队列为空,则关闭自我保护机制。
有了自我保护机制后,即使etcd存储的数据全部丢失,这种极端场景下,SDK与ServiceCenter之间可在不影响业务的前提下,做到数据自动恢复。虽然这个恢复是有损的,但在这种灾难场景下还能保持业务基本可用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号