
可视化CLIP视觉编码器内部注意力热力图
动机
近期,笔者在研究LLaVA[1]时,注意到LLaVA使用ViT(Vision Transformer)倒数第二层的输出作为视觉特征。消融实验显示,使用倒数第二层的效果略好于最后一层。作者猜测,这可能是因为最后一层特征更关注全局和抽象信息,而倒数第二层更多关注局部信息,从而有利于理解图像细节。
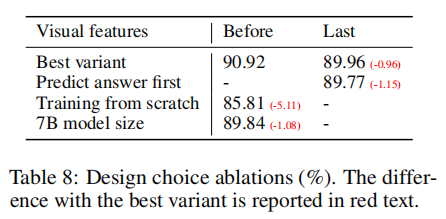
问题
以clip-vit-large-patch14-336为例,将图片resize后,切成26*26即576个图像块,每个图像块进一步embed为vision token输入到transformer blocks。
显然,最初每个vision token仅含有其对应的原始图像块的局部信息;逐层经过transformer block,各个vision token相互交互,逐渐获得了全局语义信息。
由此,笔者产生了两个疑问:
- vision token语义信息从仅关注局部到逐渐关注全局信息的演变过程是什么样的?
- 从LLaVA的结果看,深层(这里指最后2层)的语义信息既关注全局、又关注局部。那么,这些局部信息在深层是否会发生空间上的偏移?比如,对于图片中的某一个人,这个人的局部细节信息最终是否还集中于原始图像中人的位置对应的那些vision token上,还是转移到了图像的其他位置。换句话说,如果问题是“图中的人有没有戴戒指”,我们是否应该关注这个人的手所在图像块对应的vision token,是否只关注这个token就够了?
注意力分数可视化
1. [cls] token的注意力分数热力图
为解决问题1,笔者可视化了ViT每层的[cls] token相对于其他576个vision token的注意力分数热力图如下。
![ViT各层[cls] token注意力热力图](https://img2024.cnblogs.com/blog/3076115/202501/3076115-20250123235148308-864998406.png)

我们知道,在ViT中,[cls] token用于提取整图的语义信息,该注意力分数可以说明不同位置token对整图信息的贡献度。
从可视化结果来看:
- 最初8层:图像的局部细节被普遍关注,注意力集中于主要物体及其边缘,热力图变化不大;
- 第9到12层:热力图发生明显变化,注意力开始集中于某几个特定的token,且这些token的位置没有明显的规律;
- 第13层到最后:注意力始终集中于特定token且没有明显变化。
2. 各层vision token内部的注意力分数热力图
下面可视化各层576个vision token内部的注意力分数热力图如下。

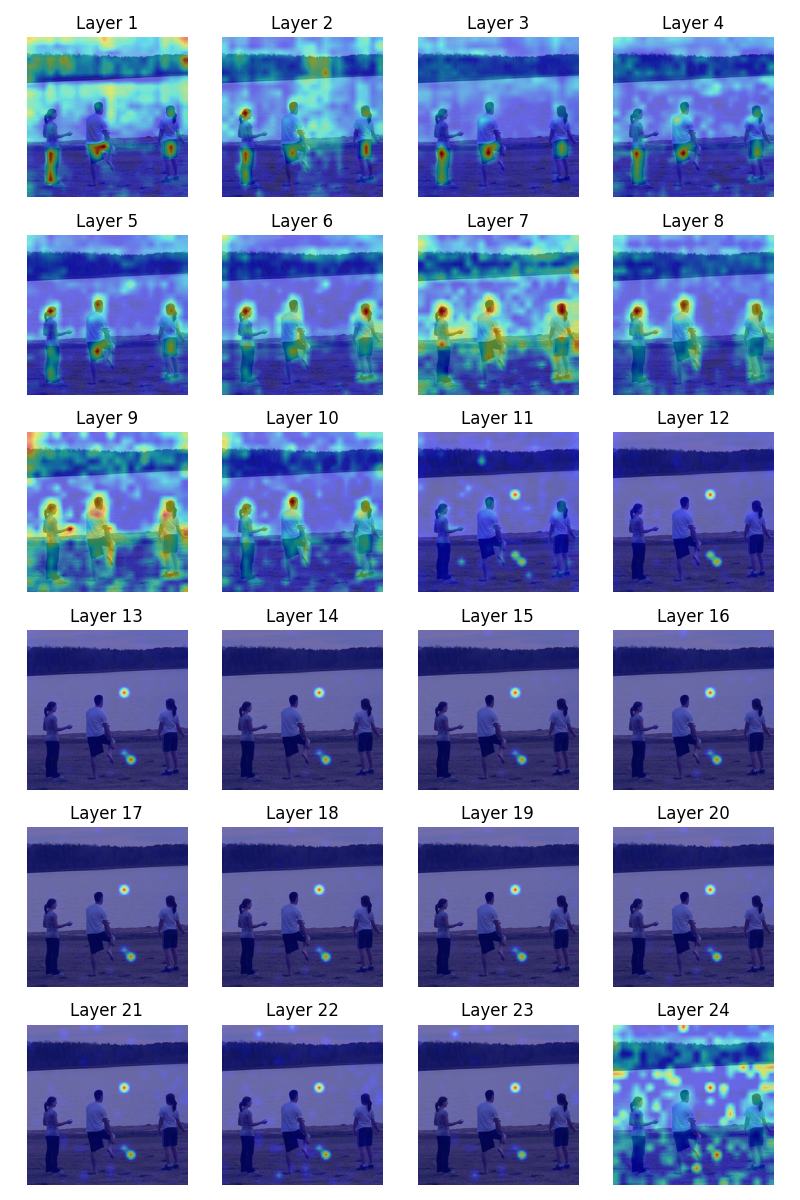
我们可以得出与[cls] token注意力热力图相一致的结果(不看最后一层)。
至于第二个疑问,还不能给出一个完善的解释,注意力只能变相说明重要性而非直接反应语义信息,毕竟“语义信息”是一个玄之又玄、不可解释的概念······
视觉冗余
由上述实验还能初步推断,随着层数加深,图像的全局信息逐渐集中于某些特定的token,这些token可能包含了最丰富的语义。但这并不能说明其他token就不重要了,注意力分数低的token或许包含了局部细节信息。但是,从信息密度而言,这些特定的token应该是最有价值的。
这说明,经过ViT得到的视觉信息是存在严重冗余的。对于大部分的VQA任务,可能根本不需要把全部576个vision token输入给LLM,只需要把那些最受[cls]关注的token输入给LLM就行了。2024年不少工作就采用了这种training-free的方式来缩减vision token数量。
一个问题是,这样会不会造成关键局部信息的损失?笔者认为或多或少肯定是有损失的,关键在于是对哪种任务场景而言。现在的benchmark有很多,对于那些偏简单、通用的基准,这种损失可能是微不足道的,只需要那些少数的、高信息密度的token就能取得很好的基准分数;但是对于高精度、多图等复杂场景,该方法或许效果就欠佳了。
代码
import torch
import numpy as np
import matplotlib.pyplot as plt
from transformers import CLIPVisionModel, CLIPImageProcessor
from PIL import Image
import torch.nn.functional as F
import os
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CLIPVisionModel.from_pretrained('./clip-vit-large-patch14-336', ).to(device)
processor = CLIPImageProcessor.from_pretrained('./clip-vit-large-patch14-336')
# 可视化注意力
def visualize_heatmaps(image_path, output_path):
image = Image.open(image_path)
inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs, output_attentions=True)
attentions = outputs.attentions # (batch, heads, seq_len, seq_len)
img = inputs.pixel_values.squeeze().permute(1, 2, 0).cpu().numpy() # (336, 336, 3)
img = (img - img.min()) / (img.max() - img.min())
num_layers = len(attentions)
cols = 4
rows = (num_layers + cols - 1) // cols
fig, axs = plt.subplots(rows, cols, figsize=(2*4, 2*rows))
axs = axs.ravel()
for i, attn in enumerate(attentions):
# attn: [batch_size, num_heads, seq_len, seq_len]
# [cls] atten
# attn_map = attn.mean(dim=1)[0, 0, 1:].reshape(-1, 1) # (576, 1)
# img atten
attn_map = attn.mean(dim=1)[0, 1:,1:].mean(dim=0).reshape(-1, 1)
# 转换为2D注意力图
config = model.config
patch_size = config.patch_size
image_size = config.image_size
num_patches = (image_size // patch_size) ** 2
attn_map = attn_map[:num_patches].reshape(1, 1, int(np.sqrt(num_patches)), int(np.sqrt(num_patches)))
# 上采样到原图尺寸
attn_map = F.interpolate(
attn_map.to(device),
scale_factor=patch_size,
mode="bilinear",
align_corners=False
).squeeze()
attn_map = attn_map.cpu().numpy()
attn_map = (attn_map - attn_map.min()) / (attn_map.max() - attn_map.min() + 1e-8)
axs[i].imshow(img)
axs[i].imshow(attn_map, cmap='jet', alpha=0.5)
axs[i].set_title(f'Layer {i+1}')
axs[i].axis('off')
for j in range(i+1, len(axs)):
axs[j].axis('off')
# plt.colorbar(im, ax=axs)
plt.tight_layout()
plt.show()
# 保存图像
plt.savefig(output_path)
input_dir = './vg/VG_100K/'
output_dir = './VG_100K_attention_map/'
os.makedirs(output_dir, exist_ok=True)
total_num = 10
for image_file in os.listdir(input_dir):
image_path = os.path.join(input_dir, image_file)
output_path = os.path.join(output_dir, image_file.replace('.jpg', '.png'))
visualize_heatmaps(image_path, output_path)
total_num -= 1
if total_num == 0:
break
参考文献
[1] Liu, Haotian, et al. "Visual instruction tuning." Advances in neural information processing systems 36 (2024).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号