Reward Modelling(RM)and Reinforcement Learning from Human Feedback(RLHF)for Large language models(LLM)技术初探
一、RLHF 技术的背景
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮,它面对多种多样的问题对答如流,似乎已经打破了机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。
过去几年里各种 LLM 根据人类输入提示 (prompt) 生成多样化文本的能力令人印象深刻。然而,对生成结果的评估是主观和依赖上下文的,例如,
- 我们希望模型生成一个有创意的故事
- 一段真实的信息性文本
- 可执行的代码片段
这些结果难以用现有的基于规则的文本生成指标 (如 BLEU 和 ROUGE) 来衡量。
除了评估指标,现有的模型通常以预测下一个单词的方式和简单的损失函数 (如交叉熵) 来建模,没有显式地引入人的偏好和主观意见。
为了解决上述问题,如果我们 用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型,那不是更好吗?这就是 RLHF 的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。
RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
二、RLHF 技术分解
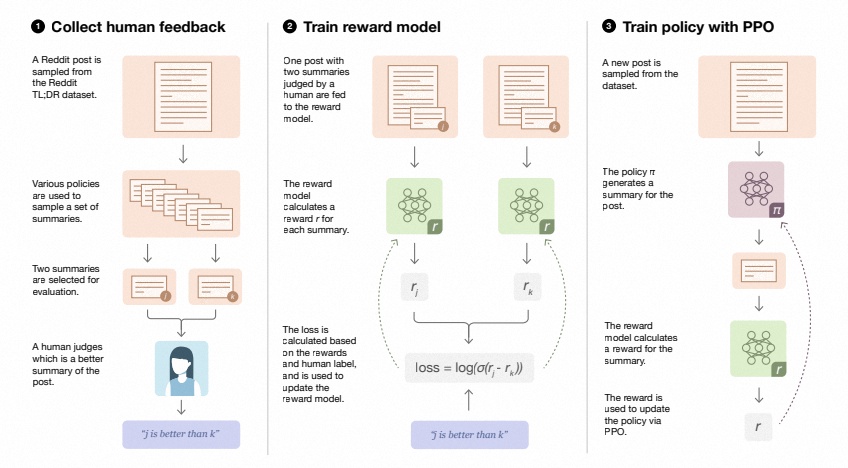
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,根据OpenAI的思路,RLHF分为三步:
- 收集人类反馈,并根据人工标注数据(prompt-completions pairs),预训练/微调一个语言模型
- 用多个模型(可以是初始模型、finetune模型、人工等等)给出同一个问题的多个回答,然后人工给这些问答对按一些标准(可读性、无害、正确性blabla)进行排序,聚合问答数据并训练一个奖励模型(Reward Model,RM)来进行打分
-
问题一,为什么不人工直接打分?因为打分是主观的需要归一化,而排序一般大家会有共同的结论:对同一个问题,A和B哪个回答更好。人类反馈的不是标准答案,而是对更好的答案的偏好,这种偏好以排序的形式展现。事实上多数问题没有标准最好的答案。
-
问题二,有了一组一组的偏序(A>B, A>C, C>B)怎么得到每个回答的奖励分数?这一步在Hug的博客里用了Elo排名系统,打网游排位赛、看足球篮球比赛的可能都知道。把每个偏序当作比赛,把奖励分数看作排位分,这里我们是用Elo得到一个完整排序后,经过归一化得到了奖励分数。
-
问题三,这个RM用什么模型?只要用Elo系统打分后归一化,然后直接上个LM做回归就行,可以从零训练也可以用老LM做finetune。这里有个有趣的事情在于,做问答和做评分都需要输入所有的文本,实际上两个模型的容量(或者说理解能力)应该是差不多的,而现有的RLHF模型都使用了两个不同大小的模型。
-
问题四,有没有其他方式训练打分的模型?张俊林老师指出对偏序直接用pairwise learning to rank做打分,大概更符合常规的思路,具体效果如何就需要看实践。
-
- 用强化学习 (RL) 方式微调 Pretrain LM,得到一个SFT-LM
参考链接:
https://zhuanlan.zhihu.com/p/591474085 https://zhuanlan.zhihu.com/p/613315873?utm_id=0
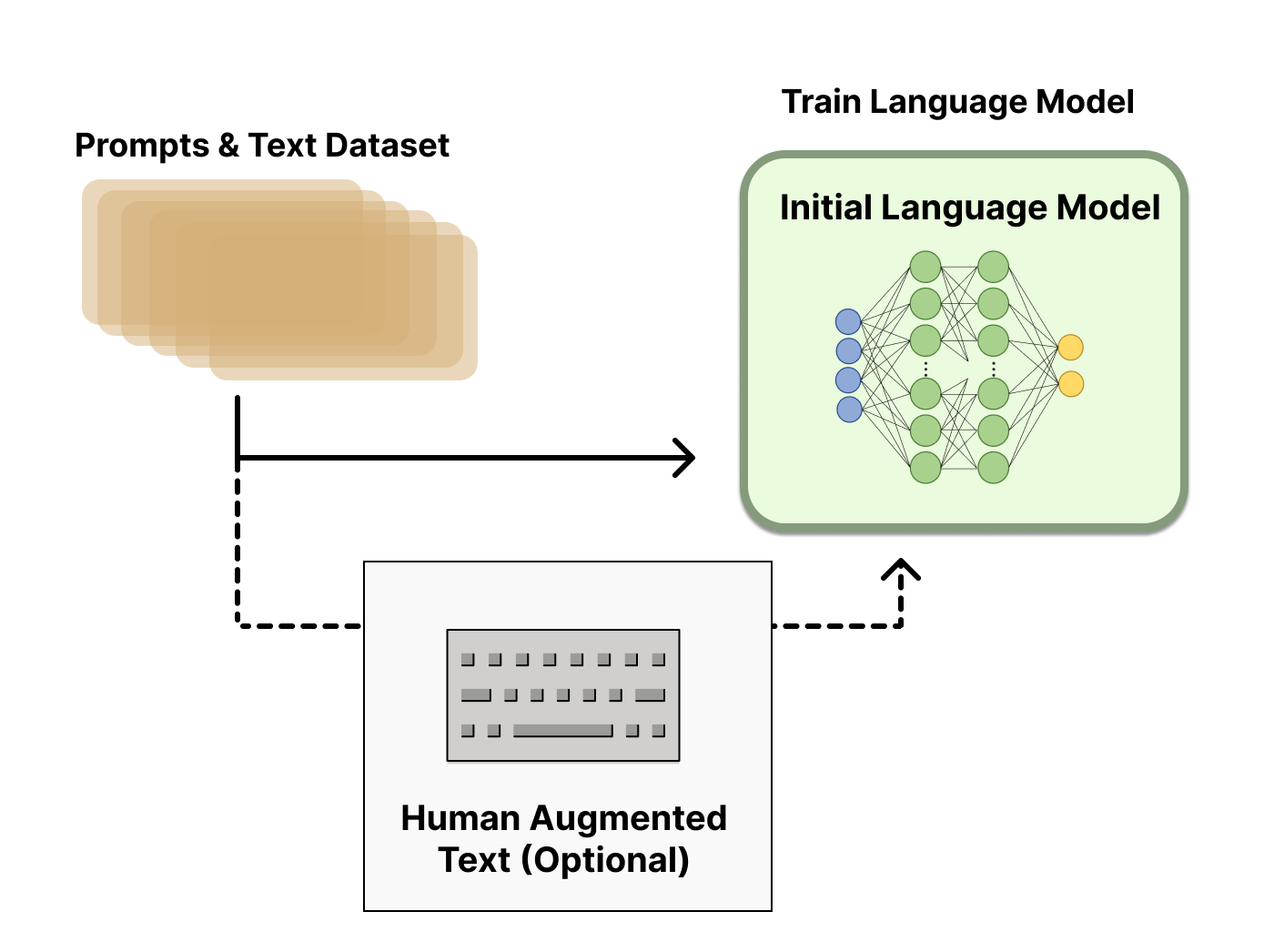
三、收集人类反馈,并根据人工标注数据(prompt-completions pairs by human feedback),预训练/微调一个语言模型(SFT LLM)
可用于收集人类反馈的模型主要有两类:
- 预训练模型(Base LLM),即只经过预料库训练而不经过 fine-tune 的模型
- 监督基线模型(SFT LLM),即在预训练模型基础上使用测试数据集 fine-tune 的模型
对于上述模型产生的结果,由专门的研究人员 labeler 去进行相对好坏的的评价,最终得到”prompt-completions pairs by human feedback“。接下来可以使用经典的微调方法训练一个sft语言模型。对这一步的模型,
- OpenAI 在其第一个流行的 RLHF 模型 InstructGPT 中使用了较小版本的 GPT-3
- Anthropic 使用了 1000 万 ~ 520 亿参数的 Transformer 模型进行训练
- DeepMind 使用了自家的 2800 亿参数模型 Gopher
这里可以用额外的文本或者条件对这个 LM 进行微调,例如
- OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调
- Anthropic 按 “有用、诚实和无害” 的标准在上下文线索上蒸馏了原始的 LM
注意,这个sft-llm的训练只是一个起点,之后我们要训练一个 RM奖励模型,然后用RM奖励模型继续训练这个sft-llm。
当RM奖励模型参与到SFT训练中,会将RM中包含的人类倾向经验注入到SFT反馈中,最终我们得目标是得到一个高质量的 RLHF-LLM。
四、训练奖励模型(Reward Model)
接下来,我们会基于 sft-llm 来生成训练 奖励模型 (RM,也叫偏好模型) 的数据(prompt对应的completions),并在这一步引入人类的偏好信息(打分和排名)。
0x1:我们为什么需要 reward model?
下图展示当前GPT技术面向特定任务应用的开发范式,

在一般情况下,SFT已经可以满足大多数场景下的需求(我们要做的主要是数据提纯和数据蒸馏),但如果对模型生成质量有更高的需求,则需要采用基于人类反馈的强化学习(RLHF)。
当SFT Model已经可以较好地生成多种不同风格的响应回答,但出于法律、道德、人类价值观、特定领域任务要求等原因,我们需要引导SFT Model选择某种特定风格的回答。因此,我们需要一种向 LLM 提供反馈的方法,以帮助他们了解什么是有用的,什么是无用的,以便我们可以将其输出与公认的人类价值观(例如诚实、乐于助人和无害)保持一致。
综上,出于以下几种原因,我们需要训练一个RM Model:
- 基础SFT-LLM虽然满足基本质量要求,但是依然不完全符合人类对特定任务、价值观、道德、法律相关的约束的倾向
- 出于工作量原因,在训练期间由人类直接提供此类反馈是不切实际的,因此我们需要一个可以模仿人类偏好的模型,以便在训练对齐 LLM 时提供奖励。
- 不管是在模型调优还是模型上线后的日常性能监控中,我们都需要一个自动化的评测标准和评测流程,以此持续监控模型的泛化和衰退情况。
以上正是 LLM 对齐中奖励模型的目标。
0x2:构建 reward model 的挑战
- Amount of feedback data(反馈数据量):生成足够准确的奖励模型所需的数量和种类的人类反馈数据具有挑战性。
- Feedback distribution(反馈分布):理想情况下,我们希望奖励模型不仅能准确预测模型所见数据的奖励,还能准确预测训练数据分布 (OOD) 之外的数据的奖励。
- Reward gaming(奖励博弈):如果奖励函数中存在多个循环黑洞,在 RL 期间,代理可以利用它们获得更多奖励,而不会收敛到预期值。
0x3:Reward Modeling
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本(prompt-completions pairs)并返回一个标量奖励(scores),数值上对应人的偏好。
- 我们可以用端到端的方式用 LM 建模
- 或者用模块化的系统建模(比如对输出进行排名,再将排名转换为奖励),这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
关于模型选择方面,
- RM 可以是另一个经过微调的 LM
- 也可以是根据偏好数据从头开始训练的 LM
例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。
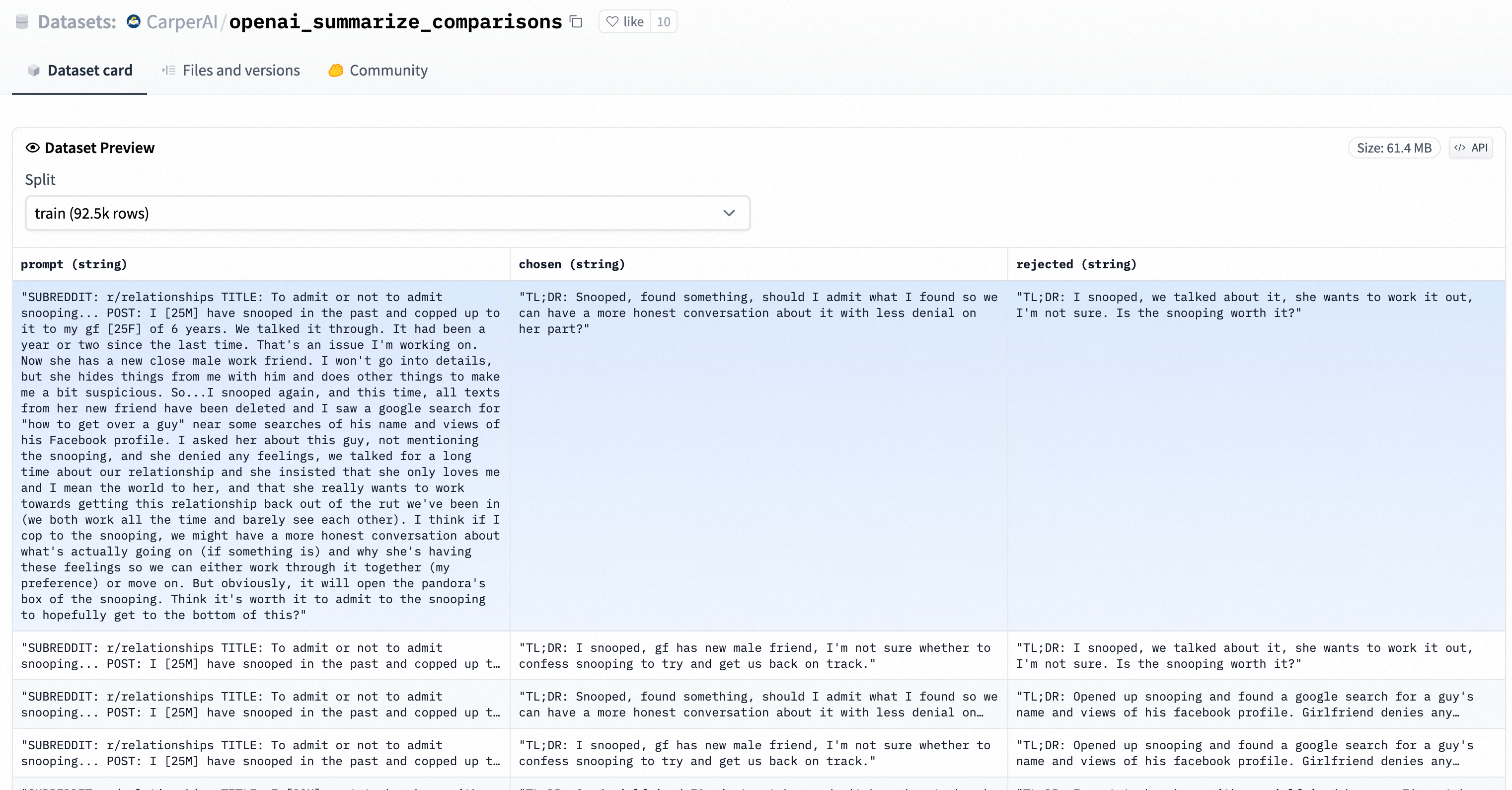
关于训练文本方面,RM 的提示(prompt) - 生成(completions)对(prompt-completions pairs)文本是经过人工打标后的包含completions打分或者completions pair排序的增强文。例如下图所示
关于训练奖励数值方面,这里需要人工对 SFT-LM 生成的回答进行打分,
- 一种想法是直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。
- 另一种想法是通过排名,比较多个模型对同一个prompt的completions输出并,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
关于刻画文本质量的标量数字,用公式表示如下:
![]()
- x 表示 prompt
- y 表示 completions
- rθ 表示参数为 θ 的奖励模型的打分值scores
- σ 表示sigmoid函数
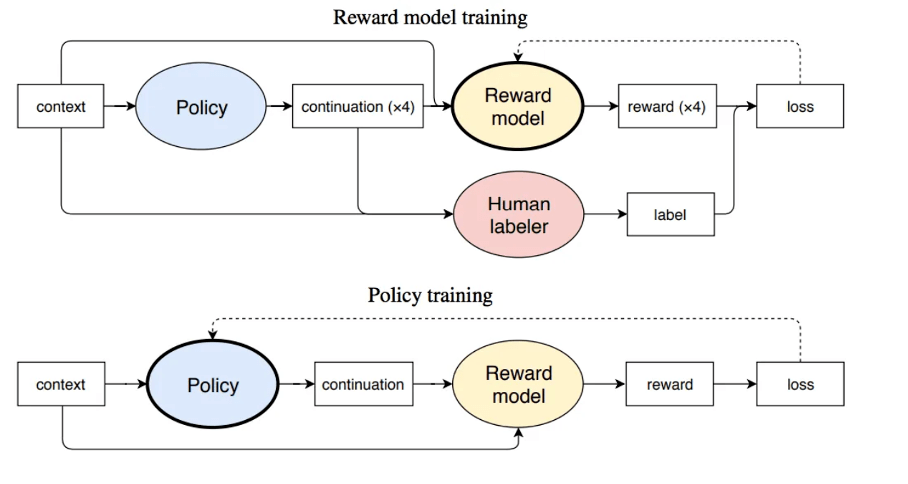
奖励模型接收一系列文本(good or bad prompt-completions pair)并返回一个标量奖励(scores),数值上对应人的偏好。
这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM,例如
- OpenAI 使用了 175B 的 LM 和 6B 的 RM
- Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等
- DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM
一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本,即裁判的能力和运动员要大差不差,才能准确无误地对运动员的表现进行评判。
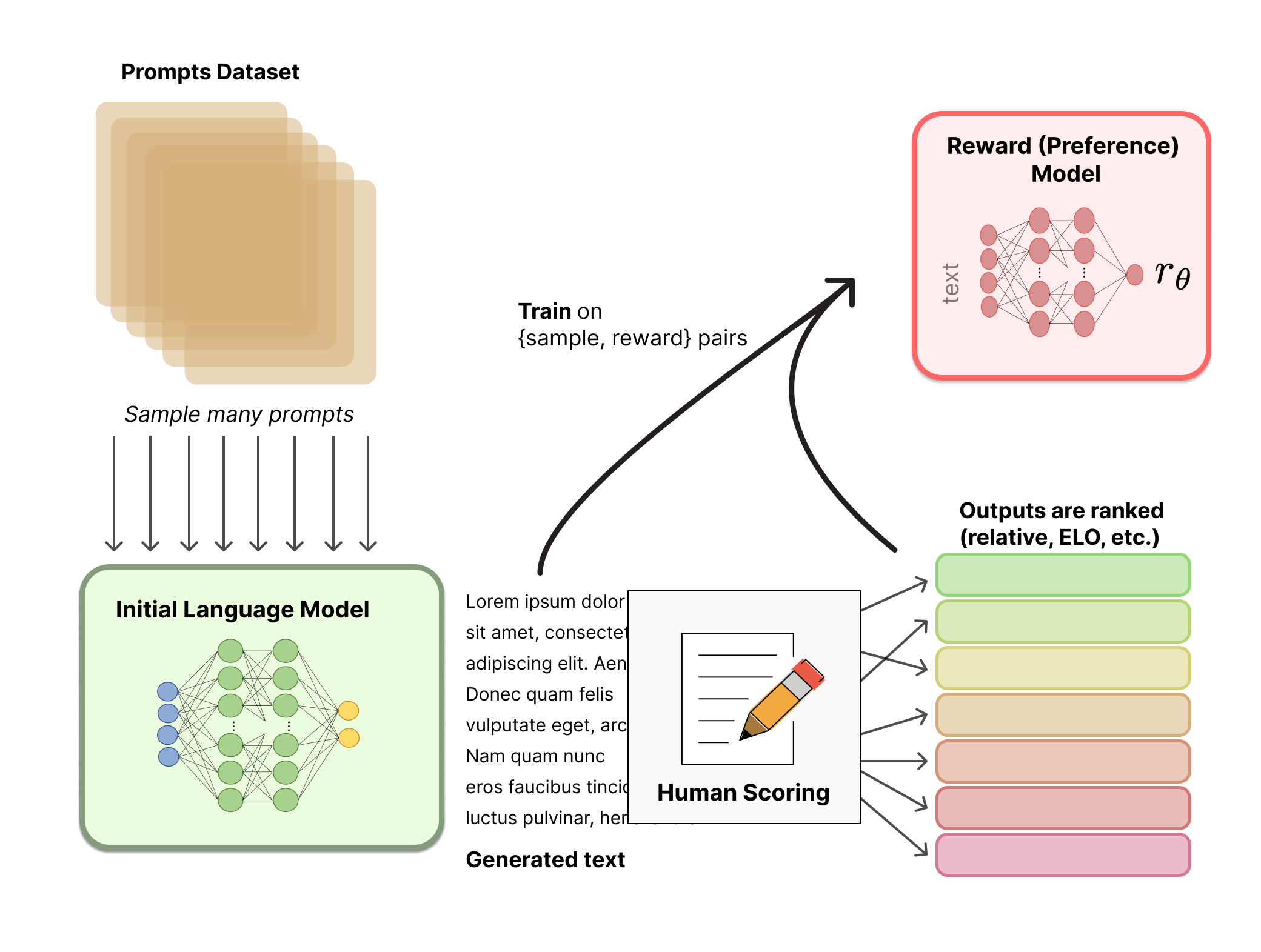
0x4:策略模型训练
首先将初始语言模型的微调任务建模为强化学习(RL)问题,因此需要定义策略(policy)、动作空间(action space)和奖励函数(reward function)等基本要素。
- 策略就是基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布)
- 动作空间就是词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选)
- 观察空间则是可能的输入token序列(即prompt),显然也相当大,为词表所有token在所有输入位置的排列组合
- 奖励函数(reward)则是基于之前我们训好的RM模型计算得到初始reward,再叠加上一个约束项来
整个过程如下所示:
而对于强化学习的算法,常见的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。
1、语言模型的强化学习建模
设词表为![]() ,语言模型为
,语言模型为![]() ,那么对于长度为 n 的序列的概率分布可表示为
,那么对于长度为 n 的序列的概率分布可表示为
![]()
- 输入空间
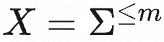
- 输出空间
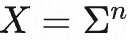
对于输入![]() 可能长度为1000的prompt,
可能长度为1000的prompt,![]() 可能是长度为100的completions。
可能是长度为100的completions。
那么由prompt x 生成completions y 的的概率可表示为:
![]()
初始化策略![]() ,然后使用PPO算法更新策略π,奖励函数定义为 r,则奖励的期望值可表示为:
,然后使用PPO算法更新策略π,奖励函数定义为 r,则奖励的期望值可表示为:
![]()
接下来,PPO 算法优化奖励函数计算步骤如下:
- 将prompt x输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1,y2,将来自当前策略的文本传递给 RM 得到一个标量的奖励 rθ
- 将两个模型的生成文本进行比较,计算差异的惩罚项,通常设计为输出词分布序列之间的Kullback–Leibler (KL) 散度的缩放,即
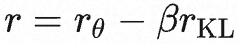 ,其中
,其中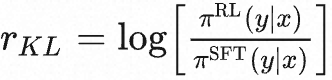
-
这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。
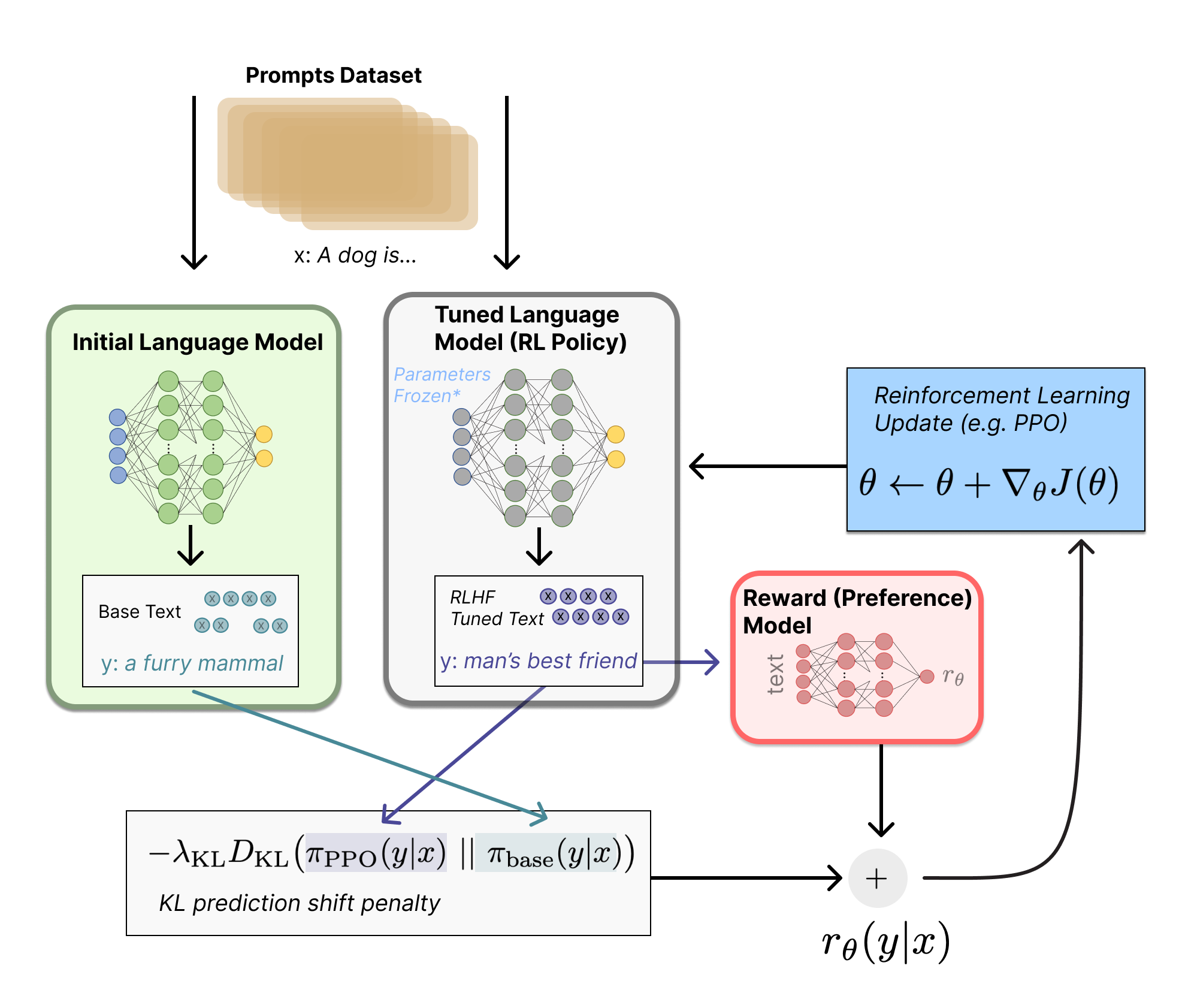 最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性,另外也可以使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。
最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性,另外也可以使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。
0x5:RM & 策略模型训练整体流程
- 从Base LLM(例如GTP-3.5、LLaMA、通义千问)开始,收集提示(prompts)和响应回答(completions)
- 通过人工反馈,给每个prompt的不同completions进行两两比较排名,表明人类人对不同响应回答(completions)的偏好,并通过ELO等算法将两两排序转化为不同completions对应的score分值
- 训练一个RM模型(一般情况下也是一个LLM),输入”prompt-completions pair with score labels数据集“继续训练,训练得到的RM模型,具备输出给定prompt-completions pair的score分值的能力
- 策略模型训练
-
让我们首先将微调任务表述为 RL 问题。首先,该 策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
- PPO 算法确定的奖励函数具体计算如下:
- 将提示 x 输入初始 LM 和当前微调的 LM,分别得到了输出文本 y1, yw
- 将来自当前策略的文本传递给 RM 得到一个标量的奖励
- 最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置,但是使用 A2C (synchronous advantage actor-critic) 算法来优化梯度
-
- 最后得到一个符合人类偏好的RM神经网络,接下去就可以利用 RM 输出的奖励(对不同completions的打分),自动化筛选出更符合人类偏好的completions,以此不断微调优化 SFT-LM
参考链接:
https://karpathy.ai/stateofgpt.pdf https://zhuanlan.zhihu.com/p/616708590 https://openreview.net/forum?id=10uNUgI5Kl https://huggingface.co/blog/zh/rlhf https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons/viewer/CarperAI--openai_summarize_comparisons/train?row=0 https://zhuanlan.zhihu.com/p/450690041
五、训练一个简单的Reward Model
选择WebGPT数据集作为reward model的语料集,如下所示,每一个prompt都对应了一个completions列表。
( 'The USA entered World War I because Germany attempted to enlist Mexico as an ally, and for what other reason?', [ "The United States entered World War I because of Germany's use of submarine warfare against ships in the Atlantic Ocean, which was hurting American exports to Europe. Additionally, Germany tried to enlist Mexico as an ally against the United States, an event which convinced American businessmen and industrialists that the United States should enter the war.", 'The USA entered World War I because Germany attempted to enlist Mexico as an ally and for the Zimmerman Telegram.' ] )
人类反馈强化后的数据集如下:
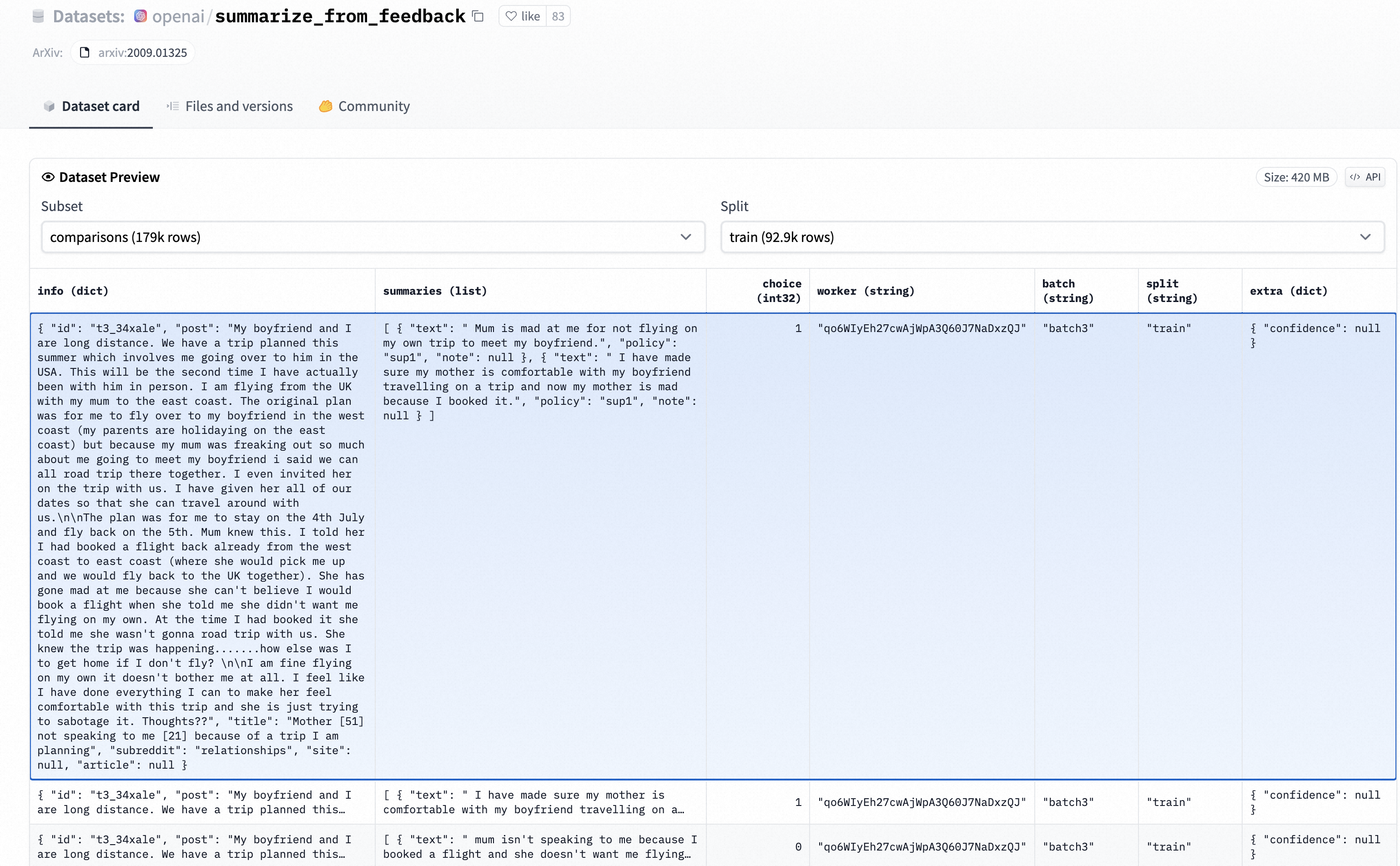
从数据集中选出人类反馈的最佳回答的处理逻辑如下:
class WebGPT: name = "openai/webgpt_comparisons" def __init__(self, split: str = "train"): super().__init__() self.split = split dataset = load_dataset(self.name, split=self.split) self.dataset_dict = defaultdict(dict) for item in dataset: post_id = item["question"]["id"] if post_id not in self.dataset_dict.keys(): self.dataset_dict[post_id] = { "full_text": item["question"]["full_text"], "answers": [], } if item["score_0"] > 0: answers = [item["answer_0"], item["answer_1"]] elif item["score_0"] < 0: answers = [item["answer_1"], item["answer_0"]] else: answers = [] answers = [re.sub(r"\[\d+\]", "", answer) for answer in answers] answers = [ ".".join([sent.strip() for sent in answer.split(".")]) for answer in answers ] if answers: self.dataset_dict[post_id]["answers"].extend(answers) else: _ = self.dataset_dict.pop(post_id) self.post_ids = list(self.dataset_dict.keys()) def __len__(self): return len(self.post_ids) def __getitem__(self, idx): question, answers = self.dataset_dict[self.post_ids[idx]].values() return question, answers
然后,在将数据输入模型之前,使用整理功能进行额外的数据准备,例如标记化和填充。 根据数据集,每个提示的完成次数可能会有所不同,因此我将维护一个额外的变量 batch_k_lens 以指示批次中每个提示的可用完成次数。 这将帮助我们计算损失。
@dataclass class RMDataCollator: tokenizer: PreTrainedTokenizer max_length: int = 512 def format_example(self, example, eos, prompt=False): sp_token = SPECIAL_TOKENS["prompter"] if prompt else SPECIAL_TOKENS["assistant"] return "{}{}{}".format(sp_token, example, eos) def process_example(self, example): trunc_len = 0 eos = self.tokenizer.eos_token prefix, outputs = example prefix = self.format_example(example, eos, prompt=True) outputs = [self.format_example(output, eos) for output in outputs] prefix_tokens = self.tokenizer.encode(prefix) input_ids, attention_masks = [], [] for output in outputs: out_tokens = self.tokenizer.encode( output, ) if len(prefix_tokens) + len(out_tokens) > self.max_length: trunc_len = max( 0, len(prefix_tokens) + len(out_tokens) - self.max_length ) prefix_tokens = prefix_tokens[trunc_len:] out_tokens = prefix_tokens + out_tokens out_tokens = out_tokens[: self.max_length] pad_len = self.max_length - len(out_tokens) attn_masks = [1] * len(out_tokens) + [0] * pad_len out_tokens += [self.tokenizer.pad_token_id] * pad_len input_ids.append(out_tokens) attention_masks.append(attn_masks) return input_ids, attention_masks def __call__(self, examples): batch_k_lens = [0] input_ids, attention_masks = [], [] for i, example in enumerate(examples): inp_ids, attn_masks = self.process_example(example) input_ids.extend(inp_ids) attention_masks.extend(attn_masks) batch_k_lens.append(batch_k_lens[i] + len(inp_ids)) return { "input_ids": torch.tensor(input_ids), "attention_mask": torch.tensor(attention_masks), "k_lens": batch_k_lens, }
对于reward model模型架构,有两种选择:
- 使用 BERT、Roberta 等纯编码器模型,并在顶部添加一个线性层。 任何支持 AutoModelForSequenceClassification 的模型都可以。
- 使用像 GPT 这样的纯解码器架构,并在顶部添加一个自定义线性层。 仅解码器模型更具可扩展性。 任何支持 AutoModelForCausalLM 的模型都可以。
我现在选择 GPTNeoXModel,我将对最后一个隐藏层进行平均池化,并添加顶部的自定义头部以生成标量输出。
@dataclass class GPTNeoxRMOuptput(ModelOutput): """ Reward Model Output """ logits: torch.FloatTensor = None class GPTNeoXRM(GPTNeoXPreTrainedModel): """ """ def __init__( self, config, ): super().__init__(config) self.gpt_neox = GPTNeoXModel(config) self.out_layer = nn.Linear(config.hidden_size, 1) def forward( self, input_ids, attention_mask, **kwargs, ): return_dict = ( kwargs.get("return_dict") if kwargs.get("return_dict") is not None else self.config.use_return_dict ) outputs = self.gpt_neox( input_ids, attention_mask, return_dict=return_dict, **kwargs, ) hidden_states = outputs[0] if attention_mask is None: hidden_states = hidden_states.mean(dim=1) else: hidden_states = (hidden_states * attention_mask.unsqueeze(-1)).sum( dim=1 ) / attention_mask.sum(dim=1).unsqueeze(-1) lm_logits = self.out_layer(hidden_states) if not return_dict: return (lm_logits,) + outputs[1:] return GPTNeoxRMOuptput(logits=lm_logits)
对于损失函数,我将使用额外的 L2 归一化因子,以防止过度拟合。 对于每个提示prompt的k个响应回答completions,存在![]() 个两两比较。
个两两比较。
损失是针对每个提示单独计算的,并取平均值以获得批量平均损失。
class RMLoss(nn.Module): """ """ def __init__( self, reduction=None, beta=0.001, ): super().__init__() self.reduction = reduction self.beta = beta def forward( self, logits, k_lens=None, ): total_loss = [] indices = list(zip(k_lens[:-1], k_lens[1:])) for start, end in indices: combinations = torch.combinations( torch.arange(start, end, device=logits.device), 2 ) positive = logits[combinations[:, 0]] negative = logits[combinations[:, 1]] l2 = 0.5 * (positive**2 + negative**2) loss = ( -1 * nn.functional.logsigmoid(positive - negative) + self.beta * l2 ).mean() total_loss.append(loss) total_loss = torch.stack(total_loss) if self.reduction == "mean": total_loss = total_loss.mean() return total_loss view raw
最后,我们会将所有这些连同训练参数一起传递给自定义训练器来训练和评估我们的模型。
记住!我们最终的目标是训练出一个”裁判“,这个”裁判“代表了人类反馈的倾向,它可以对prompt的completions进行打分和排序(本质上是实现训练集蒸馏)。
一旦训练出一个好的”裁判“,LLM SFT的开发就可以进入一个正向循环,一个整体的开发流程如下:
- 基于Base LLM进行prompt engining,生成一批初始数据集data_v1
- 基于初始数据集对Base LLM进行SFT,得到一个sft-llm_v1
- 引入领域业务专家,对初始数据集进行倾向打标和排序,得到一份强化数据集data_v2
- 基于强化数据集data_v2,训练一个reward model,reward_v1
- 基于sft-llm_v1进行prompt engining,得到一份新的prompt-completions数据集data_v3
- 基于reward_v1对data_v3进行打标和排序,得到data_v4
- 引入领域业务专家,对data_v4进行倾向打标和排序,得到一份强化数据集data_v5
- 基于强化数据集data_v5,训练一个reward model,reward_v2
- 基于data_v5对sft-llm_v1进行SFT,得到一个sft-llm_v2
- .....
- 反复循环上述步骤,通过领域业务专家的反馈,不断优化reward model和sft llm
- 当reward model的性能和人工专家基本齐平时,后续的训练将不再需要人工的介入,可以让reward model自动对sft llm的completions进行打分和排序,整个训练优化过程进入全自动化
参考链接:
https://explodinggradients.com/reward-modeling-for-large-language-models-with-code https://huggingface.co/datasets/openai/summarize_from_feedback/viewer/axis/test?row=0
六、通过trlx的rlhf案例学习一个完整的RLHF开发流程
以trlx的 rlhf案例 为例,深入了解整个过程。
0x1:零样本冷启动
对于大多数特定领域任务LLM的开发来说,项目的初期基本都是从零样本冷启动开始的。因此,task-LLM的第一步就是数据准备工作。
我们分两种情况讨论零样本启动流程。
1、基础大模型能力相对目标任务领域有泛化能力较差
- 已经具备至少一种基础大模型,可以输入prompt生成completions
- 基础大模型对于目标任务领域的泛化能力相对较弱,生成的completions不太符合目标任务领域的需求
当处于这种情况时,我们需要分别采取prompt engining、样本提纯蒸馏等过程,循环迭代不断扩展我们的基础样本。
- 步骤一:prompt engining(prompt工程):
- 用Base LLM,对种子样本进行prompt,人工对打标结果进行挑选修改
- 持续子步骤a,不断筛选出高质量的prompt指令集
- 用最优的prompt指令集,输入通义千问基模型,得到”基础prompt-completions数据集“
- 步骤二:sample distillation(样本蒸馏/提纯)
- 人工从基础prompt-completions数据集中,挑选出符合最低质量要求的good case样本,进行样本提纯
- 人工对不符合要求的bad case样本进行completions修正,使其符合最低质量要求,以保证总体样本数量基本不变
- 样本蒸馏/提纯过程可以分批,不断增量扩展,不断给模型注入泛化能力。每轮迭代不断累计,得到一批数量不断扩大的”提纯prompt-completions数据集“
- 步骤三:sft train(微调自监督训练)
- 基于”提纯prompt-completions数据集“,基于Base-LLM进行微调,得到微调后模型sft-llm
- 步骤四:rm奖励模型开发 & RLHF人工反馈训练
- 开发评测网页版,人可以通过看模型的输出给模型打分,
- 基于sft-llm微调模型打标新样本,对同一个prompt生成2条以上completions,生成“sft-prompt-completions数据集”
- 人工选取good case、bad case,对“sft-prompt-completions数据集”进行排序rank,通过elo转换为不同completions的分数,喂给rm模型进行学习,得到一个奖励模型
- 通过ppo train,对sft-llm进行fine-tune,最终得到RLHF-llm
- 步骤五:循环进行prompt engining和RLHF过程
- 基于RLHF-llm充当步骤一的基础模型
- 重新循环进行新一轮的prompt engining(prompt工程)
- 重新循环进行新一轮的sample distillation(样本蒸馏/提纯)
- 重新循环进行新一轮的sft train(微调自监督训练)
- 重新循环进行新一轮的rm奖励模型开发 & RLHF人工反馈训练
- 步骤六:auto RLHF
- 奖励模型可作为模型上线后的自动化评估机制和反馈机制
- 当rm性能只够好时(已经充分拟合人工的倾向经验),人工介入程度可以减少,让奖励模型rm来辅助sft-model不断循环微调,最终得到SOTA-RLHF model
2、基础大模型能力能够生成基本符合相对目标任务领域的样本
- 已经具备至少一种基础大模型,可以输入prompt生成completions
- 基础大模型对于目标任务领域的泛化能力表现优异,生成的completions对于目标领域任务质量很高
当处于这种情况时,sample distillation(样本蒸馏/提纯)这一步可以基本省略,其他步骤保持不变。
基础大模型生成的completions基本都满足目标任务领域的最低质量要求,重点的工作就要放在强化奖励模型的开发和RLHF微调训练上。
0x2:训练基础SFT模型
我们使用”CarperAI/openai_summarize_tldr“,基于”EleutherAI/gpt-j-6B“进行SFT,
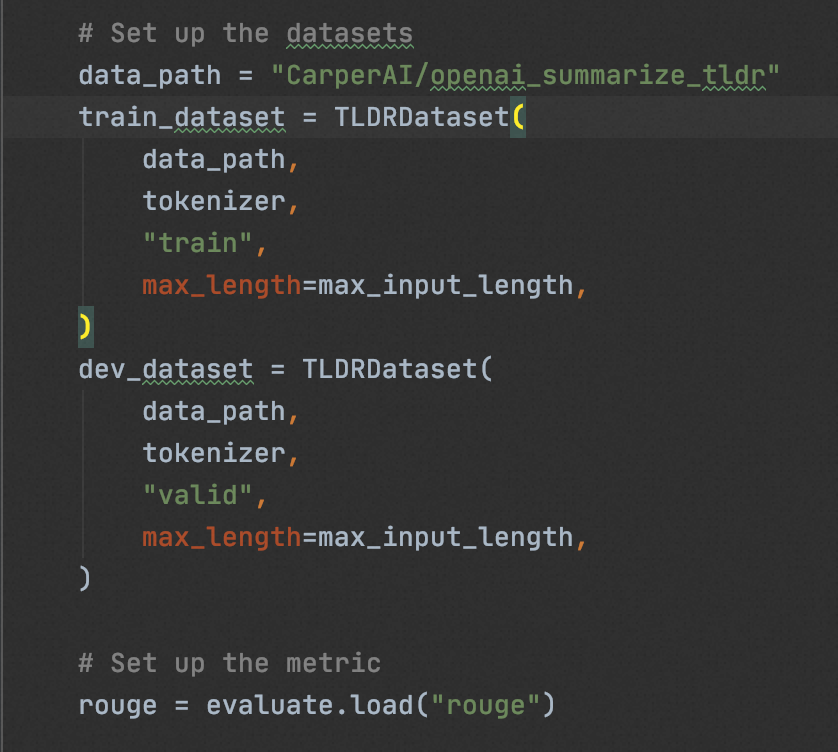
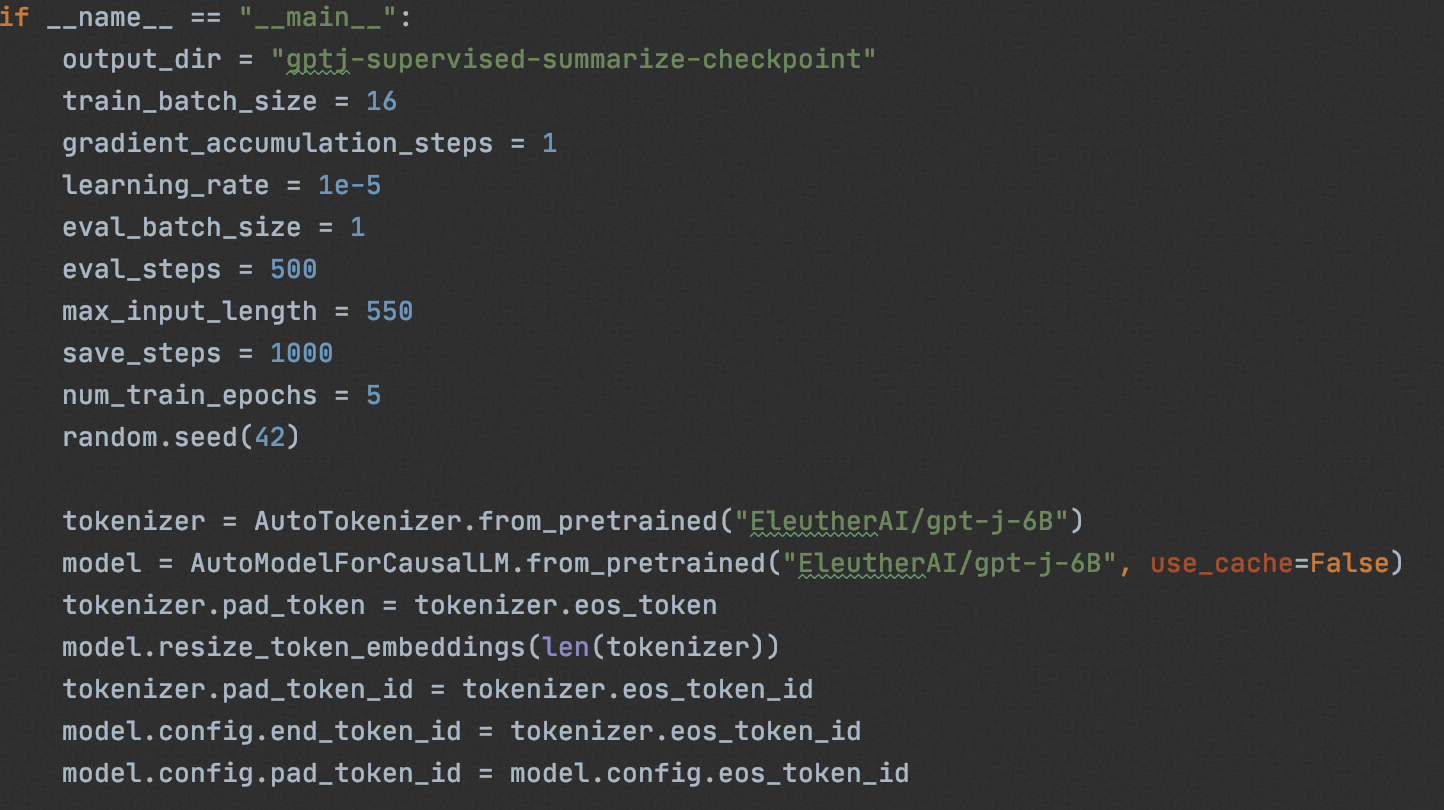
# 单GPU cd sft/ && CUDA_VISIBLE_DEVICES=0 python3 train_gptj_summarize.py # 多GPU cd sft/ && deepspeed train_gptj_summarize.py
通过sft,得到了一个和summarize任务对齐了的sft-llm。
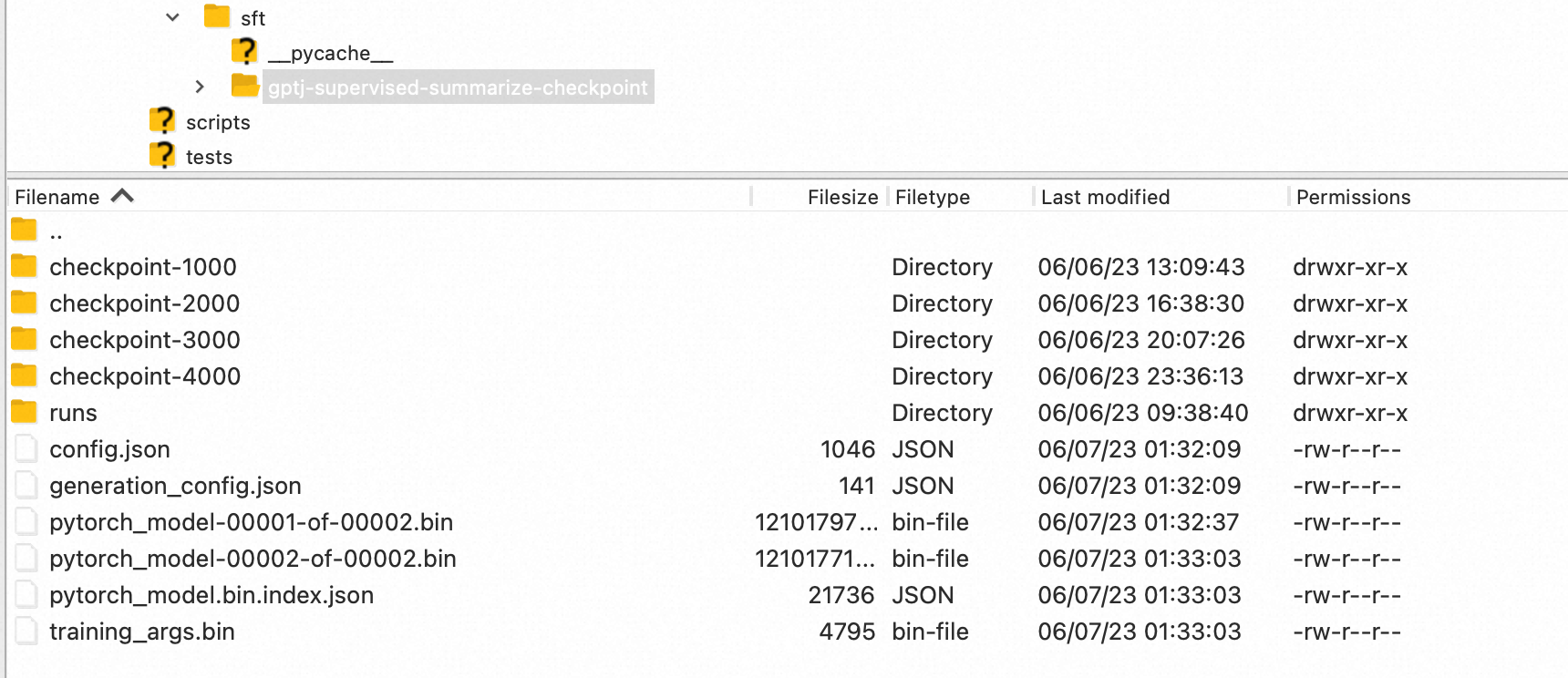
0x3:奖励模型(Reward Model)的训练
1、数据集准备工作(completions打分、排名)
在一般的项目开发中,我们需要雇佣数据承包商或者外包人员,对base-llm、sft-llm、人工等方式生成的completions进行排序(rank)。这一步非常消耗时间,但对最终模型的效果来说又非常重要。
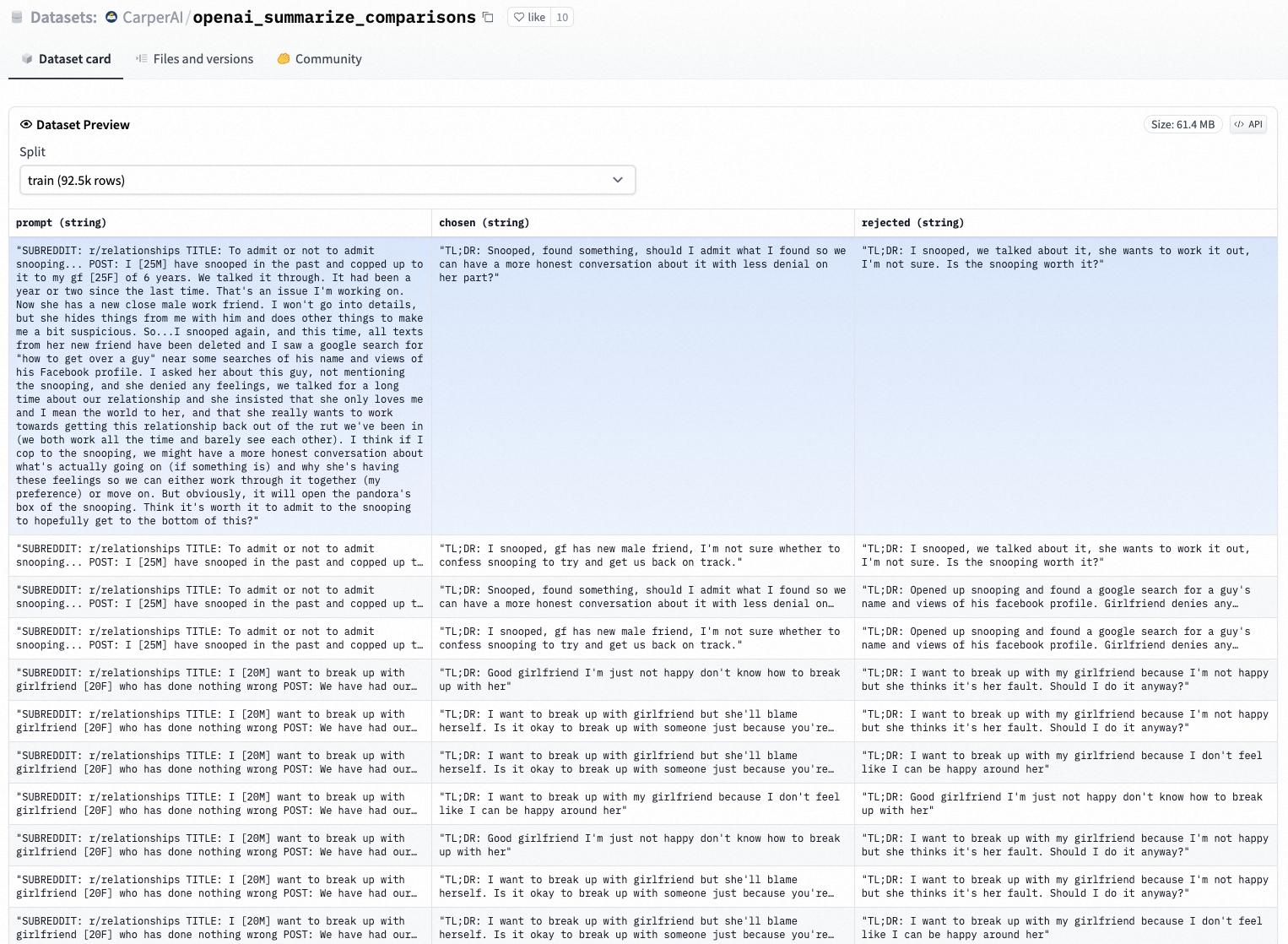
这里我们使用hugeface上开源的”CarperAI/openai_summarize_comparisons“进行演示。
2、hugface数据集(已完成rank排序的completions数据集)加载与预处理
使用开源数据集,创建一个由字典的组成的列表,每一个字典有3个key,
- prompt:原始prompt
- chosen:该prompt对应的summary被人工打标为”接受“,即代表rank更高
- rejected:该prompt对应的summary被人工打标为”拒绝“,即代表rank更低
def create_comparison_dataset(path="CarperAI/openai_summarize_comparisons", split="train"): dataset = load_dataset(path, split=split) pairs = [] for sample in tqdm(dataset): pair = {} prompt = sample["prompt"] chosen_summary = sample["chosen"] rejected_summary = sample["rejected"] if chosen_summary == rejected_summary: continue if len(chosen_summary.split()) < 5 or len(rejected_summary.split()) < 5: continue pair["chosen"] = prompt + "\n" + chosen_summary pair["rejected"] = prompt + "\n" + rejected_summary pairs.append(pair) return pairs
拼接prompt-completions pair对,
- prompt+chosen
- prompt+rejected
针对处理完的 pair 对,进行分词处理,并构造成可供训练的数据集形式
class PairwiseDataset(Dataset): def __init__(self, pairs, tokenizer, max_length): self.chosen_input_ids = [] self.chosen_attn_masks = [] self.rejected_input_ids = [] self.rejected_attn_masks = [] for pair in tqdm(pairs): chosen, rejected = pair["chosen"], pair["rejected"] chosen_encodings_dict = tokenizer( "<|startoftext|>" + chosen + "<|endoftext|>", truncation=True, max_length=max_length, padding="max_length", return_tensors="pt", ) rejected_encodings_dict = tokenizer( "<|startoftext|>" + rejected + "<|endoftext|>", truncation=True, max_length=max_length, padding="max_length", return_tensors="pt", ) self.chosen_input_ids.append(chosen_encodings_dict["input_ids"]) self.chosen_attn_masks.append(chosen_encodings_dict["attention_mask"]) self.rejected_input_ids.append(rejected_encodings_dict["input_ids"]) self.rejected_attn_masks.append(rejected_encodings_dict["attention_mask"]) def __len__(self): return len(self.chosen_input_ids) def __getitem__(self, idx): return ( self.chosen_input_ids[idx], self.chosen_attn_masks[idx], self.rejected_input_ids[idx], self.rejected_attn_masks[idx], )
上述数据不便于同时输入模型进行训练,需要进一步整理数据,构造成如下形式:
- input_ids: 将 input_ids 的 chosen 和 rejected 在0维度上 concat
- attention_mask: 将 attention_mask 的 chosen 和 rejected 在0维度上 concat
- labels: 将 chosen 部分置0,rejected 部分置1,并在0维度上concat。这一步完成stirng label的数字向量化。
需要说明的是,经过上述处理,batch size 变为原来的2倍
class DataCollatorReward: def __call__(self, data): batch = {} batch["input_ids"] = torch.cat([f[0] for f in data] + [f[2] for f in data]) batch["attention_mask"] = torch.cat([f[1] for f in data] + [f[3] for f in data]) batch["labels"] = torch.tensor([0] * len(data) + [1] * len(data)) return batch
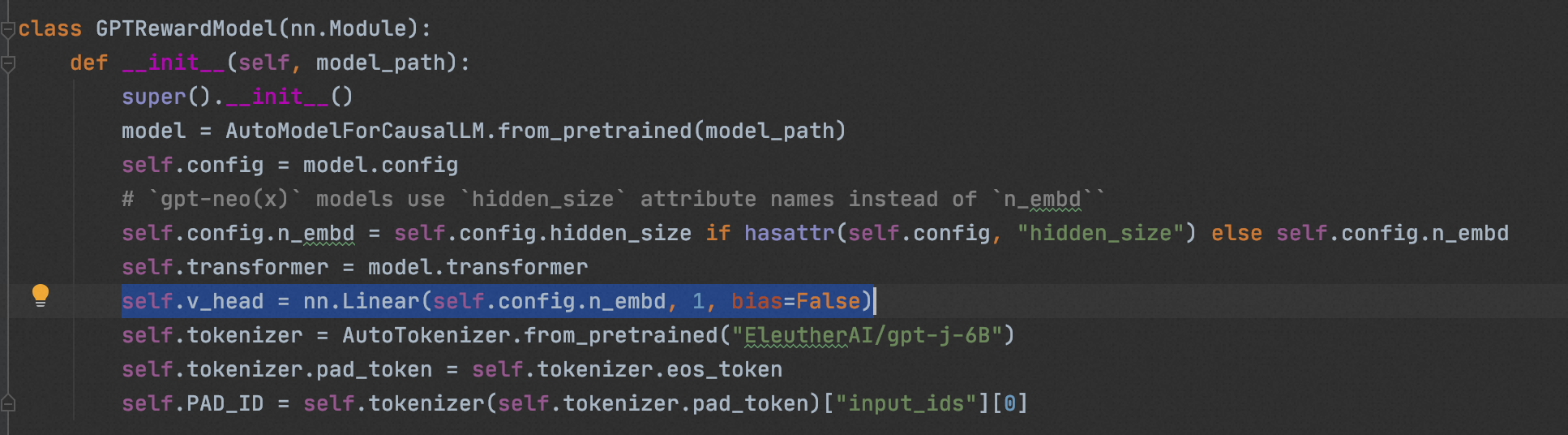
3、构建奖励模型
RM 的结构相对简单,即 transformer 结构+线性分类头。
- transformer使用”CarperAI/openai_summarize_tldr_sft“预训练llm模型,并freeze 70%的神经元不进行参数微调,即保留原始sft-llm对文本的理解能力
- Linear线性分类器,用于输出dim=1的score分数,用于对completions进行打分
定义loss公式,
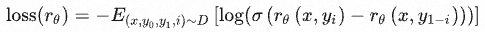
- RM模型对prompt-completions pair预测为chose,则返回0;RM模型对prompt-completions pair预测为rejected,则返回1
- loss优化函数的目标是让RM输出的0/1,和训练数据的0/1,尽量多的符合接近,符合地越多,loss越小
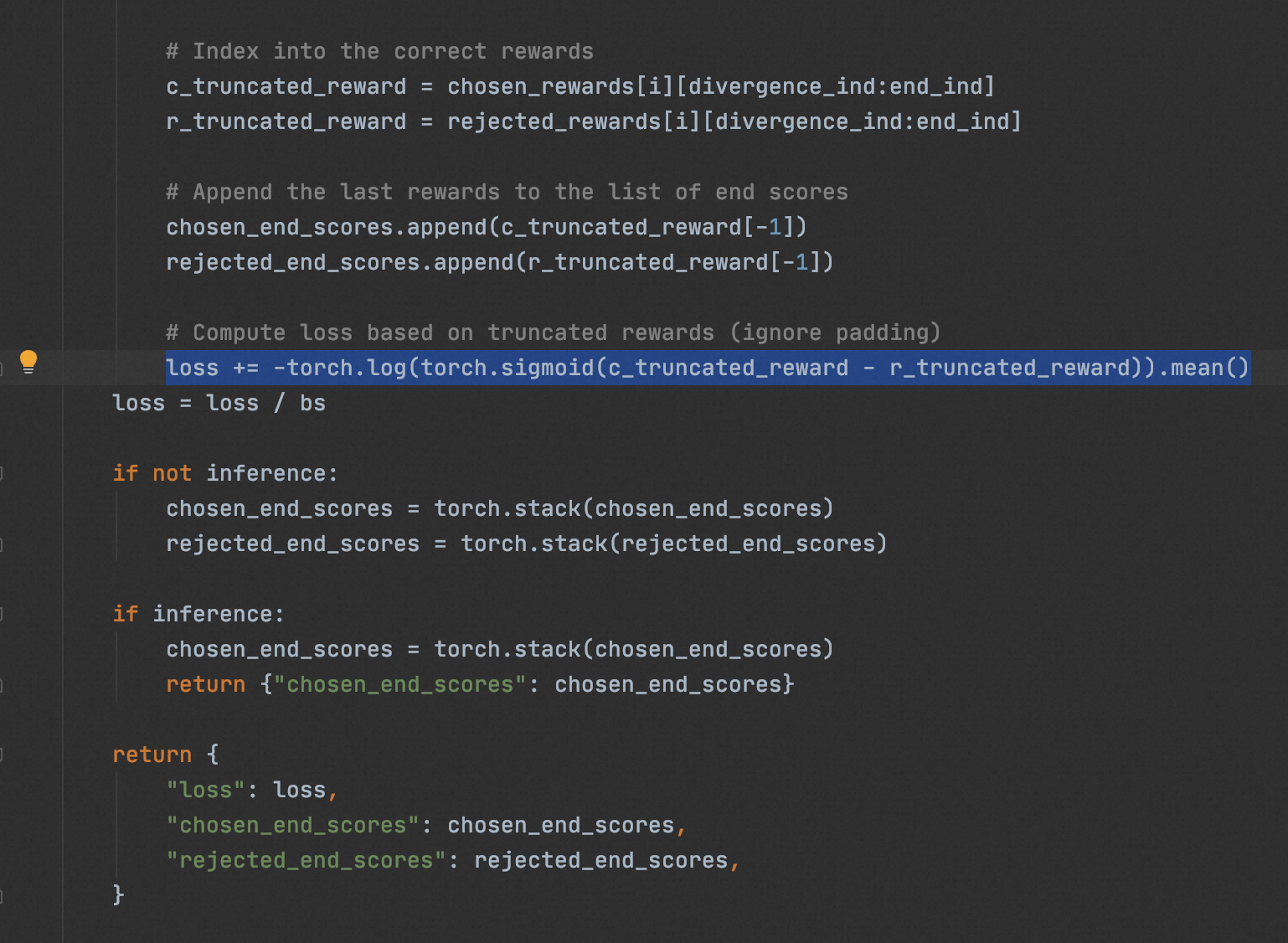
class GPTRewardModel(nn.Module): def __init__(self, model_path): super().__init__() model = AutoModelForCausalLM.from_pretrained(model_path) self.config = model.config # `gpt-neo(x)` models use `hidden_size` attribute names instead of `n_embd`` self.config.n_embd = self.config.hidden_size if hasattr(self.config, "hidden_size") else self.config.n_embd self.transformer = model.transformer self.v_head = nn.Linear(self.config.n_embd, 1, bias=False) self.tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B") self.tokenizer.pad_token = self.tokenizer.eos_token self.PAD_ID = self.tokenizer(self.tokenizer.pad_token)["input_ids"][0] def forward( self, input_ids=None, past_key_values=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, mc_token_ids=None, labels=None, return_dict=False, output_attentions=False, output_hidden_states=False, ): loss = None transformer_outputs = self.transformer( input_ids, past_key_values=past_key_values, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, ) hidden_states = transformer_outputs[0] rewards = self.v_head(hidden_states).squeeze(-1) chosen_end_scores = [] rejected_end_scores = [] # Split the inputs and rewards into two parts, chosen and rejected assert len(input_ids.shape) == 2 bs = input_ids.shape[0] // 2 chosen = input_ids[:bs] rejected = input_ids[bs:] chosen_rewards = rewards[:bs] rejected_rewards = rewards[bs:] loss = 0 inference = False for i in range(bs): if torch.all(torch.eq(chosen[i], rejected[i])).item(): c_inds = (chosen[i] == self.PAD_ID).nonzero() c_ind = c_inds[0].item() if len(c_inds) > 0 else chosen.shape[1] chosen_end_scores.append(chosen_rewards[i, c_ind - 1]) inference = True continue # Check if there is any padding otherwise take length of sequence c_inds = (chosen[i] == self.PAD_ID).nonzero() c_ind = c_inds[0].item() if len(c_inds) > 0 else chosen.shape[1] r_inds = (rejected[i] == self.PAD_ID).nonzero() r_ind = r_inds[0].item() if len(r_inds) > 0 else rejected.shape[1] end_ind = max(c_ind, r_ind) # Retrieve first index where trajectories diverge divergence_ind = (chosen[i] != rejected[i]).nonzero()[0] assert divergence_ind > 0 # Index into the correct rewards c_truncated_reward = chosen_rewards[i][divergence_ind:end_ind] r_truncated_reward = rejected_rewards[i][divergence_ind:end_ind] # Append the last rewards to the list of end scores chosen_end_scores.append(c_truncated_reward[-1]) rejected_end_scores.append(r_truncated_reward[-1]) # Compute loss based on truncated rewards (ignore padding) loss += -torch.log(torch.sigmoid(c_truncated_reward - r_truncated_reward)).mean() loss = loss / bs if not inference: chosen_end_scores = torch.stack(chosen_end_scores) rejected_end_scores = torch.stack(rejected_end_scores) if inference: chosen_end_scores = torch.stack(chosen_end_scores) return {"chosen_end_scores": chosen_end_scores} return { "loss": loss, "chosen_end_scores": chosen_end_scores, "rejected_end_scores": rejected_end_scores, }
将以上部分组合起来,即可以训练RM
# Initialize the reward model from the (supervised) fine-tuned GPT-J model = GPTRewardModel("CarperAI/openai_summarize_tldr_sft") # Freeze the first 70% of the hidden layers of the reward model backbone layers = model.transformer.h num_layers = len(layers) num_unfrozen = int(0.3 * num_layers) for layer in layers[:-num_unfrozen]: layer.requires_grad_(False) # Create the comparisons datasets data_path = "CarperAI/openai_summarize_comparisons" train_pairs = create_comparison_dataset(data_path, "train") val_pairs = create_comparison_dataset(data_path, "test") # Make pairwise datasets for training max_length = 550 train_dataset = PairwiseDataset(train_pairs, tokenizer, max_length=max_length) val_dataset = PairwiseDataset(val_pairs, tokenizer, max_length=max_length) # Create the collator to gather batches of pairwise comparisons data_collator = DataCollatorReward() Trainer( model=model, args=training_args, train_dataset=train_dataset, compute_metrics=compute_metrics, eval_dataset=val_dataset, data_collator=data_collator, ).train()
4、启动BP训练
cd reward_model/ && deepspeed train_reward_model_gptj.py
如果想要加快时间,也可以直接下载hugeface上已经开源的训练好的reward model,
mkdir reward_model/rm_checkpoint wget https://huggingface.co/CarperAI/openai_summarize_tldr_rm_checkpoint/resolve/main/pytorch_model.bin -O reward_model/rm_checkpoint/pytorch_model.bin


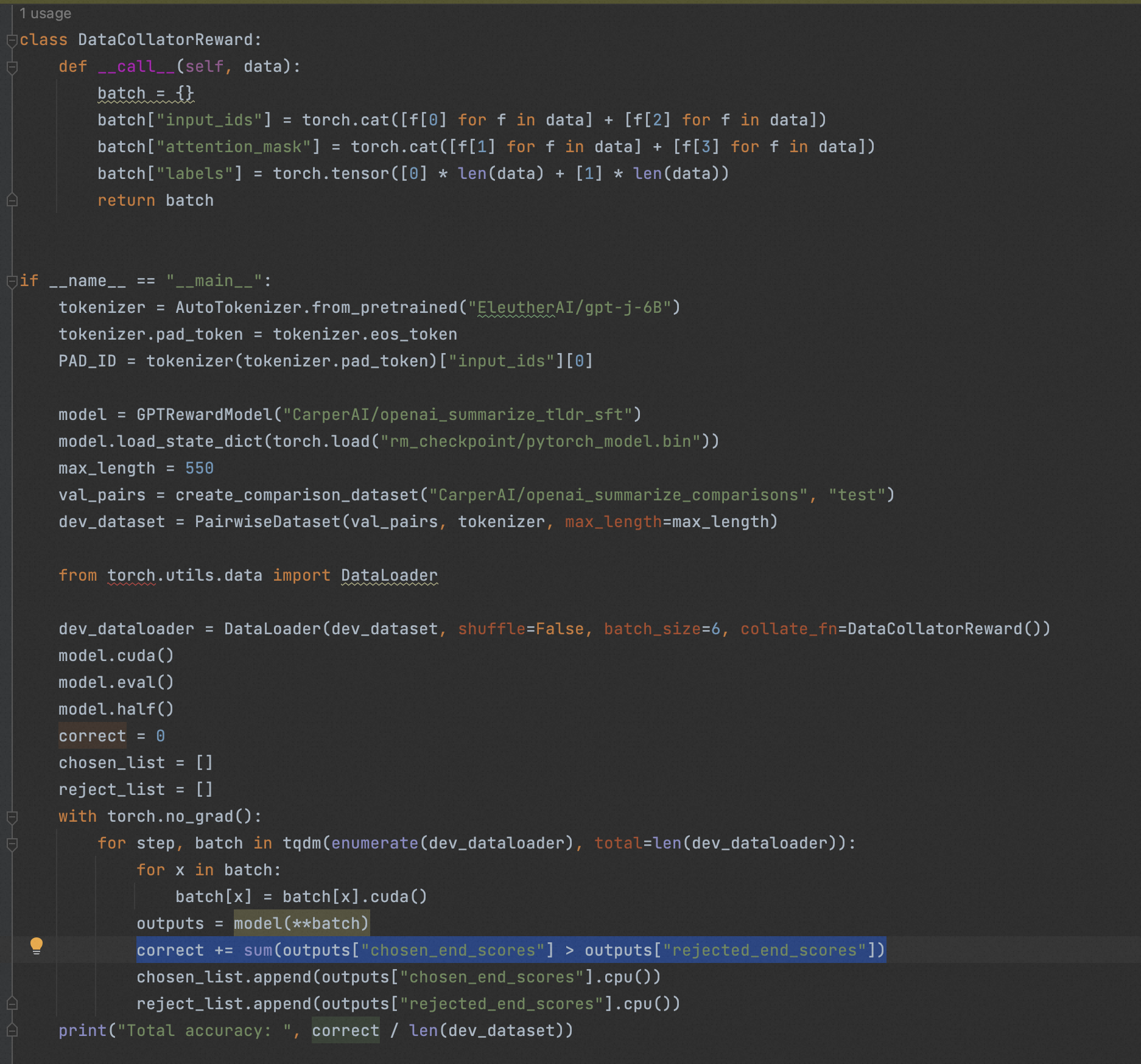
基于训练得到的RM模型,对“CarperAI/openai_summarize_comparisons”的测试机进行score生成,以此验证RM模型的打分效果。
python3 gptj_reward_test.py

0x4:策略模型(PPO)的训练
由于PPO算法的值函数可以是一个深度学习模型,在本例中则是一个 transformer 模型,策略梯度方法的基本思想将值函数表示为策略参数的某个函数,然后可以根据RM的反馈值进行更新。
1、标准化(Normalization)
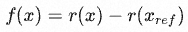
其中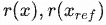 分别表示模型得分和人为得分。代码实现如下:
分别表示模型得分和人为得分。代码实现如下:
def reward_fn(samples: List[str]): # get humans summarizes posts = [sample.split('TL;DR')] for sample in samples] ref_samples = [post + 'TL;DR' + post_summ_dict[post] for post in post] samples_encodings = reward_tokenizer(samples) samples_scores = reward_model(**samples_encodings) # get scores from reward model for samples ref_samples_encodings = reward_tokenizer(ref_samples) # get scores from reward model corresponding references samples ref_samples_scores = reward_model(**ref_samples_encodings) norms_rewards = samples_scores - ref_samples_scores return norms_rewards
2、KL 散度(KL Divergence)
当使用 PPO 做 fine-tuning 的时候,summary 由策略(LLM)生成。生成的 summary传到奖励模型生成奖励分,进而更新策略。 由于上述操作是 batch-wise 的,同时由于 RL 训练的噪声很大,特别是在初始阶段,这些可能会导致策略偏移过大。为防止这个问题,引进KL散度作为惩罚项,以避免策略模型偏差过大。
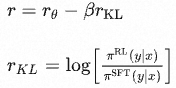
其中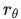 表示奖励模型的输出分数,
表示奖励模型的输出分数,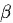 表示系数,
表示系数,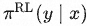 表示策略模型,
表示策略模型,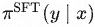 表示监督模型。
表示监督模型。
3、启动PPO训练
accelerate launch --config_file configs/default_accelerate_config.yaml trlx_gptj_text_summarization.py
0x5:Results
SFT vs PPO
| Model | Rouge-1 | Rouge-2 | Rouge-L | Average |
|---|---|---|---|---|
| SFT | 0.334 | 0.125 | 0.261 | 0.240 |
| PPO | 0.323 | 0.109 | 0.238 | 0.223 |
ROUGE scores
| Model | Average Reward | Reward Δ |
|---|---|---|
| SFT | 2.729 | -0.181 |
| PPO | 3.291 | +0.411 |
Reward scores
参考链接:
https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons/viewer/CarperAI--openai_summarize_comparisons/train?row=0 https://link.zhihu.com/?target=https%3A//github.com/CarperAI/trlx/tree/main/examples/summarize_rlhf https://github.com/CarperAI/trlx https://github.com/CarperAI/trlx/tree/main/examples/summarize_rlhf
七、RL4LMs - A modular RL library to fine-tune language models to human preferences
参考资料:
https://github.com/allenai/RL4LMs
八、RLHF的局限和未来工作
- RLHF 范式训练出来的这些模型虽然效果更好,但仍然可能输出有害或事实上不准确的文本。这种不完美则是 RLHF 的长期挑战和优化目标。
- 在基于 RLHF 范式训练模型时,人工标注的成本是非常高昂的,而 RLHF 性能最终仅能达到标注人员的知识水平。此外,这里的人工标注主要是为RM模型标注输出文本的排序结果,而若想要用人工去撰写答案的方式来训练模型,那成本更是不可想象的,而实际上,对SFT-LLM或者RLHF-LLM来说,真正有价值和重要的信息是人工撰写的completions输出结果。
- RLHF的流程还有很多值得改进的地方,其中,改进 RL 优化器显得尤为重要。PPO 是一种基于信赖域优化的相对较旧的RL算法,但没有其他更好的算法来优化 RLHF 了。
九、Reward Model开发的另一种范式
RM总共有两种作用场景:
- 接收prompt-completions pair,给出一个数值评分(或者一个多维度数值向量,由人类专家定义)
- 辅助SFT-LLM进行强化学习训练
如果场景1,其实还可以有另一种范式,即通过构造prompt template实现一个“prompt-completions pair文本质量推理链”,prompt template包含如下几个元素:
- prompt-completions pair输入
- 问题定义
- 评价标准定义
- 评价结果输出(可以设计成格式化)
一个例如如下:
You are a fair AI assistant for checking the quality of the answers of other two AI assistants. [Question] {data['query']} [The Start of Assistant 1's Answer] llama chains: {data['llama_chains']} llama answer: {data['llama_answer']} [The End of Assistant 1's Answer] [The Start of Assistant 2's Answer] chatgpt chains: {data['chatgpt_chains']} chatgpt answer: {data['chatgpt_answer']} [The End of Assistant 2's Answer] We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above. Please first judge if the answer is correct based on the question, if an assistant gives a wrong answer, the score should be low. Please rate the quality, correctness, helpfulness of their responses based on the question. Each assistant receives an overall score on a scale of 1 to 10, where a higher score indicates better overall performance, your scores should be supported by reasonable reasons. Please first output a single line containing only two values indicating the scores for Assistant 1 and 2, respectively. The two scores are separated by a space. In the subsequent line, please provide a comprehensive explanation of your evaluation, avoiding any potential bias, and the order in which the responses were presented does not affect your judgement. If the two assistants perform equally well, please output the same score for both of them.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号