Toolformer:LLM语言模型插件化初探
一、背景简介
大型语言模型在各种任务(prompt)上实现了令人深刻的零样本(zero-shoht prompt)和少样本(few-shot prompt)结果,但是仍存在一些局限性,包括无法获取最新信息,幻觉倾向,精确计算,不知道时间的推移等。
Bing Chat利用Bing搜索关键词并将结果通过embedding注入prompt中调用底层大模型,解决了一些实时性和数值计算方面的问题。但是其能力有限,无法执行逻辑操作(本质还是在静态的历史数据库中进行搜索)。
克服这些限制的一个简单方法是让它们能够使用搜索引擎(动态获取外部世界最新的事实性知识)、计算器或日历等外部工具。然而,现有的方法要么依赖于大量的人工注释,要么仅将工具的使用限制在特定任务的设置中,阻碍了在LMs中更广泛地使用工具。
在论文中,作者提出了Toolformer,以自监督的方式微调语言模型,在不失模型的通用性下,让模型学会自动调用API。通过调用一系列工具,包括计算器、问答系统、搜索引擎、翻译系统和日历,Toolformer在各种下游任务中实现了实质性改进的零样本性能,通常可与更大的模型竞争,而不牺牲其核心语言建模能力。
参考链接:
https://arxiv.org/abs/2302.04761
二、Toolformer技术原理
0x1:构造增强数据集
作者将每个API调用表示为元组 c = (ac,ic) ,其中:
- ac是API的名称
- ic是相应的输入
API输出为 r。
不包括和包括输出的API调用的线性化序列分别表示为:
- e (c) = <API> ac(ic) </API>
- e (c,r) = <API> ac(ic)-> r </API>
其中“<API>”、“</API>”和“→” 是特殊的token,用于指示LLM指令边界和输出边界的位置。
插入文本序列的API调用的一些示例如图所示:
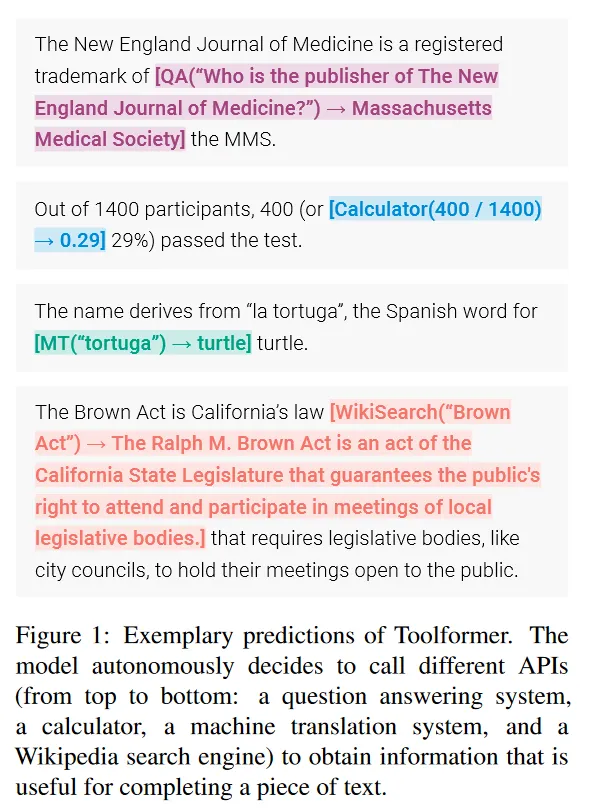
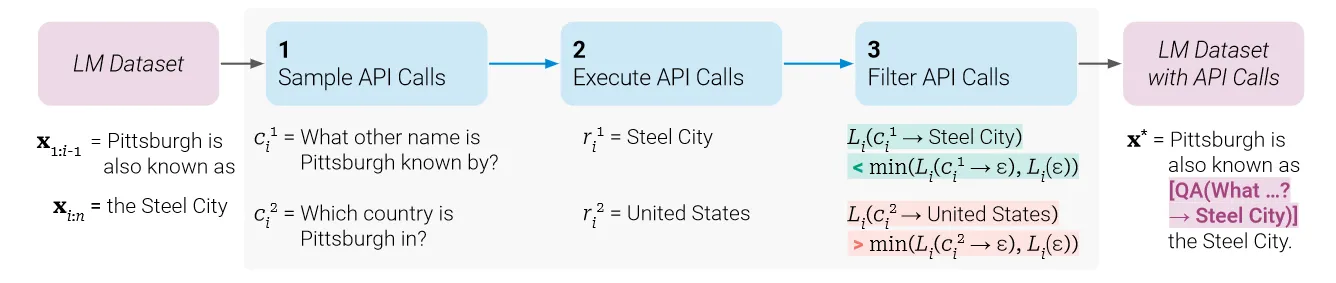
给定纯文本的数据集 ,首先将该数据集转换为通过API调用增强的数据集 C∗ 。包含三个步骤:
,首先将该数据集转换为通过API调用增强的数据集 C∗ 。包含三个步骤:
- 采样API调用
- 执行API调用
- 过滤API调用
1、采样API调用
对于每个API,首先编写一个prompt P(x) ,prompt里包含一些人工构造的演示样例,输入为 x=x1,…,xn 。
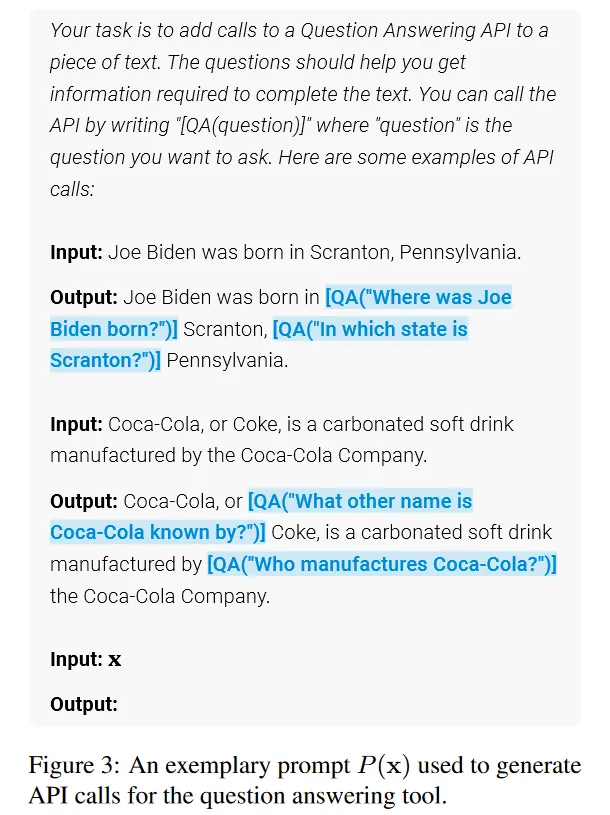
首先需要判断在哪些位置需要调用QA API,然后得到生成API的输入(问题)
采样位置:对于每个 i ∈ {1,…,n} ,根据 x1:i−1 计算第 i 个token预测为 <API> 的概率
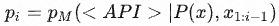
- 给定采样阈值 τs ,保留所有大于阈值的位置 I = { i | pi > τs}
- 如果有超过 k 个这样的位置,只保留topK。这个k决定了要计算多少比例token的API query结果正确性的概率熵,k越大,训练时的计算量就越大
在每个位置生成API调用(的输入问题):对于每个位置 i ∈ I,将 [P(x),x1,…,xi−1,<API>] 作为前缀输入到M中生成若干次(只保留以</API>token结尾的输出),从而获得m个API调用 ci1,…,cim
2、执行API调用
执行M生成的所有API调用,以获得相应的结果。每个API调用 ci 的响应都需要是一个单独的文本序列 ri3、过滤API调用
设位置 i 处的API调用 ci 的响应输出为 ri 。以 z 为前缀,模型 M 在token x1,…,xn 上的加权交叉熵损失为:
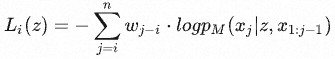
( wi | i ∈ N)是一个权重序列,越靠近API调用,权重越大,以确保API调用发生在API提供的信息对模型有帮助的地方附近。
- 当前缀为API调用及其结果时,即 z = e(ci,ri) ,损失记为 Li+ = Li (e(ci,ri))
- 当前缀为空,即根本不进行API调用时,损失记为 Li(ε) ( ε 表示一个空序列)
- 当前缀为只包含API调用但不提供响应时,损失记为 Li(e(ci,ε)) ;
因此,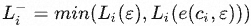 代表根本不接收API调用或只接收其输入的交叉熵。
代表根本不接收API调用或只接收其输入的交叉熵。
给定过滤阈值 τf ,只保留满足条件的API调用:
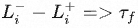
即,与不进行任何API调用或不从中获得结果相比,过滤出添加API调用及其结果将损失至少减少 τf 的调用。
0x2:微调和推理
1、微调
过滤后,通过合并对不同工具(计算器、问答系统、搜索引擎、翻译系统和日历)的API调用,得到增强的数据集 C∗,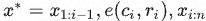 。
。
在此数据集使用标准的语言建模目标微调 M 。
2、推理
当用 M 生成文本时,执行常规解码,直到 M 生成“ → ” token,指示它接下来期望对API调用的响应。此时,中断解码过程,调用API以获得响应,并在插入响应和 </API> token后继续解码过程。
这一步需要LLM能够和外部系统按照一定的协议和交互进行指令和数据交互。
0x3:核心思路通俗理解
构造增强数据集这个步骤是这个算法设计最精彩的地方,笔者提请读者朋友思考一个问题:
基于一段原始的正常的语料文本,你该如何让程序自动化地识别出哪些地方(词)需要扩展为通过API query获取更高质量的结果吗?
现在让我们先从一个最基本的常识开始入手,
世界上的知识从大略上可以分为两种类型:
- 常识性知识,基于一些底层的知识框架可以推理得出,在不同的时空和语境下结论基本不变。这部分内容适合LLM生成
- 事实性知识,和具体的对象、时间、空间、语境等多方面因素都有关,内容不确定且处于不断变化中。这部分内容适合通过数据库搜索、计算器、程序模拟器等外部工具生成。
基于以上认知,我们就可以通过概率损失,将任何一段语料文本的内容(主要是词)分为【常识性内容】和【事实性内容】。
大致的逻辑流程如下:
- 逐token遍历整段语料,针对每一个token都生成一个API query元组。通俗地理解就是说:逐字尝试看看用API query后能得到什么结果。
- 在训练开始前,原始语料的每一个token都被增加一个API query元组。通俗地理解就是说:假设原始语料每一个token都属于常识性知识,但是每一个token都有概率是事实性知识,到目前为止我们还不知道谁是谁不是,需要通过训练和损失函数优化,来筛选出两拨人。
- 通过损失目标函数,引导生成的API query元组尽量满足以下2个特性:
- API query生成的内容,尽量和该API query元组附近的token接近。通俗地理解就是,API query生成的内容,尽量和原始语料中该token以及该token附近的词接近,即更接近正确答案。可以想象,如果原本该token对应的是事实性知识,那么API query的结果和原始语料的结果应该相对比较接近(语义和词义熵),那么最终的损失熵相对就会很低
- API query应该尽量去产生结果内容,避免不做就会错的优化倾向
- 通过极大似然概率训练后,得到一份增强数据集M,相比于原始的文本语料,增强数据集语料M中的某一些token后增加API query元组,表明该token属于一个事实性知识,需要调用外部插件进行额外处理。
- 将增强数据集M输入原始的LLM进行fine-tune,让LLM对齐学会对特定的事实性知识token之后增加一个API query元祖,本质上就是让LLM学会在输出语料的特定token后新增了一个特定的”协议定界符“,这个”协议定界符“可以标明该处需要调用特定的外部插件进行额外的数据扩展处理
- 微调对齐后的LLM,在之后的文本生成任务中,自动就会在生成的语料中包含特定的”协议定界符“,这些”协议定界符“是非常容易被标准化程序处理的,到了这一步就是常规的协议处理和接口调用的逻辑了,难度不大。
https://www.jianshu.com/p/9f9aa24090f0
三、Toolformer实验
0x1:Baseline
- GPT-J:一个没有任何微调的常规GPT-J模型,参数为6.7B。
- GPT-J+CC:GPT-J在没有任何API调用的CCNet子集C上进行了微调。
- Toolformer:GPT-J对 C∗ 进行了微调, C∗ 是CCNet子集通过API调用进行了增强后的数据集。
- Toolformer(disabled):与Toolformer的模型相同,但在解码过程中会禁用API调用。
对于大多数任务,作者还与OPT(66B)和GPT-3 (不加微调的davinci,175B)进行了比较。
0x2:对比实验
LAMA基准的SQuAD、GoogleRE和T-REx子集,任务是完成一个简短的陈述,其中缺少一个事实(例如,日期或地点):

此任务下,Toolformer被禁用维基百科API
数学推理:
问答:
 此任务下被禁用问答API
此任务下被禁用问答API多语言:
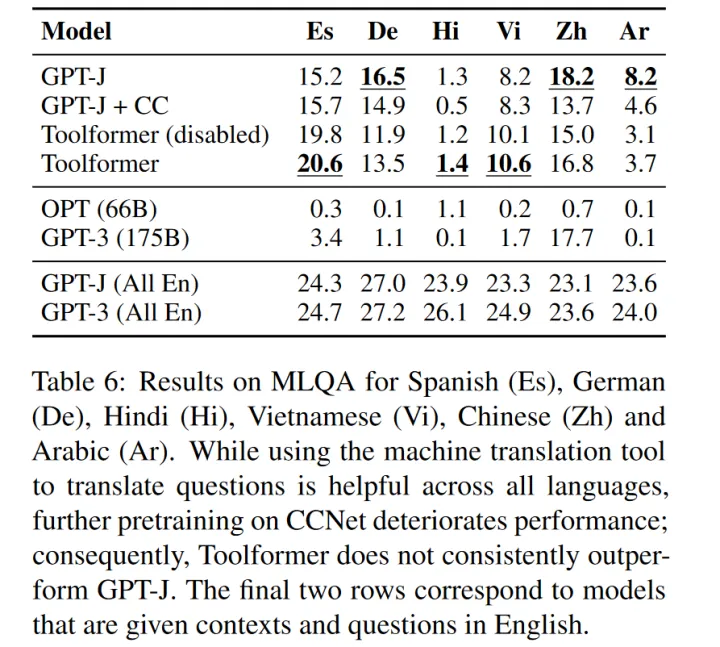
每个问题的上下文段落都是用英语提供的,问题是多种语言。
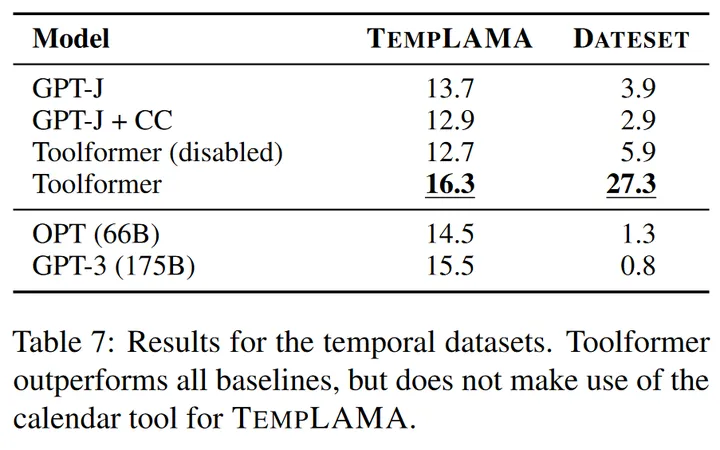
时间数据集:
0x3:模型尺寸的影响
作者不仅将该方法应用于GPT-J(6.7B),还应用于GPT-2家族的四个较小模型,分别具有124M、355M、775M和1.6B的参数。
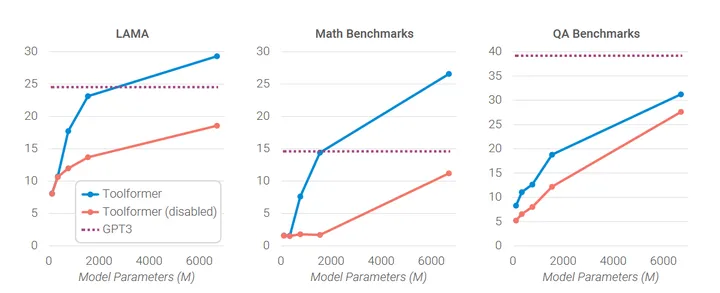
结果显示,只有在775M左右的参数下模型才能利用所提供的工具,对于这里最大的模型GPT-J,使用和不使用API调用的预测之间仍然存在很大的差距。
0x4:算法局限性
- 法链式使用工具(即,将一个工具的输出用作另一个工具)。这是由于每个工具的API调用都是独立生成的,因此,在微调数据集中没有使用链式工具的例子。
- 不允许LM以交互方式使用工具,这对于一些应用API,比如搜索引擎,可能至关重要。
参考链接:
https://zhuanlan.zhihu.com/p/618901006
四、代码示例
Models are available on huggingface! toolformer_v0
安装依赖:
pip install --upgrade google-api-python-client
pip install wolframalpha
pip install transformers
pip install openai
pip install langchain
0x1:Data generation(生成增强数据集)
python3 data_generator.py --num_devices=x, --device_id=y //Will let you run it without collision on x devices, so if you only have one, python3 data_generator.py --num_devices=1, --device_id=0


import os import torch from transformers import ( AutoModelForCausalLM, AutoTokenizer, ) from datasets import load_dataset from prompts import retrieval_prompt from data_generation.retrieval import RetrievalPostprocessing from data_generation.calendar import CalendarPostprocessing from data_generation.calculator import CalculatorPostprocessing from data_generation.api_checker import check_apis_available import json import time import argparse if __name__ == "__main__": parser = argparse.ArgumentParser(description='do some continuations') parser.add_argument('--device_id', type=int, default=0) parser.add_argument("--num_devices", type=int, default=8) args = parser.parse_args() gpt_tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B") prompt_tokens = gpt_tokenizer(retrieval_prompt, return_tensors="pt")["input_ids"] start_tokens = [ gpt_tokenizer("[")["input_ids"][0], gpt_tokenizer(" [")["input_ids"][0], ] end_tokens = [ gpt_tokenizer("]")["input_ids"][0], gpt_tokenizer(" ]")["input_ids"][0], ] # TODO: keep second? api_handler = RetrievalPostprocessing(start_tokens, end_tokens) model = AutoModelForCausalLM.from_pretrained( "EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16, low_cpu_mem_usage=True, ).cuda() dataset = load_dataset("c4", "en", split="train", streaming=True) iter_data = iter(dataset) test = False counter = 0 file_counter = 0 found_examples = 0 output_dataset = list() start_time = time.process_time() num_examples = int(25000.0/float(args.num_devices)) start_count = -1 if os.path.isfile(f"retrieval_data_{args.device_id}.json"): with open(f"retrieval_data_{args.device_id}.json") as f: output_dataset = json.load(f) start_count = output_dataset[-1]['file_index'] for item in output_dataset: num_examples -= len(item['retrieval_outputs']) while found_examples < num_examples: data = next(iter_data) if file_counter < start_count: file_counter += 1 continue if file_counter % args.num_devices != args.device_id: file_counter += 1 continue available = check_apis_available(data, gpt_tokenizer) test = available.retrieval if test: data_outputs = api_handler.parse_article(data, model, gpt_tokenizer) output_dataset.append( { "file_index": file_counter, "text": data["text"], "retrieval_outputs": data_outputs } ) prev_found = found_examples found_examples += len(output_dataset[-1]["retrieval_outputs"]) eta_s = (num_examples - found_examples) * (time.process_time()-start_time) / max(1, found_examples) eta_m = eta_s // 60 eta_h = eta_m // 60 eta_m = eta_m - (eta_h*60) eta_s = eta_s - ((eta_m*60) + (eta_h*60*60)) print(f"Found: {found_examples}/{num_examples}, ETA: {eta_h}H:{eta_m}M:{eta_s}s") if found_examples//100 > prev_found//100: with open(f"retrieval_data_{args.device_id}.json", 'w') as f: json.dump(output_dataset, f, indent=2) counter += 1 file_counter += 1 with open(f"retrieval_data_{args.device_id}.json", 'w') as f: json.dump(output_dataset, f, indent=2)
数据增强前的训练语料如下:

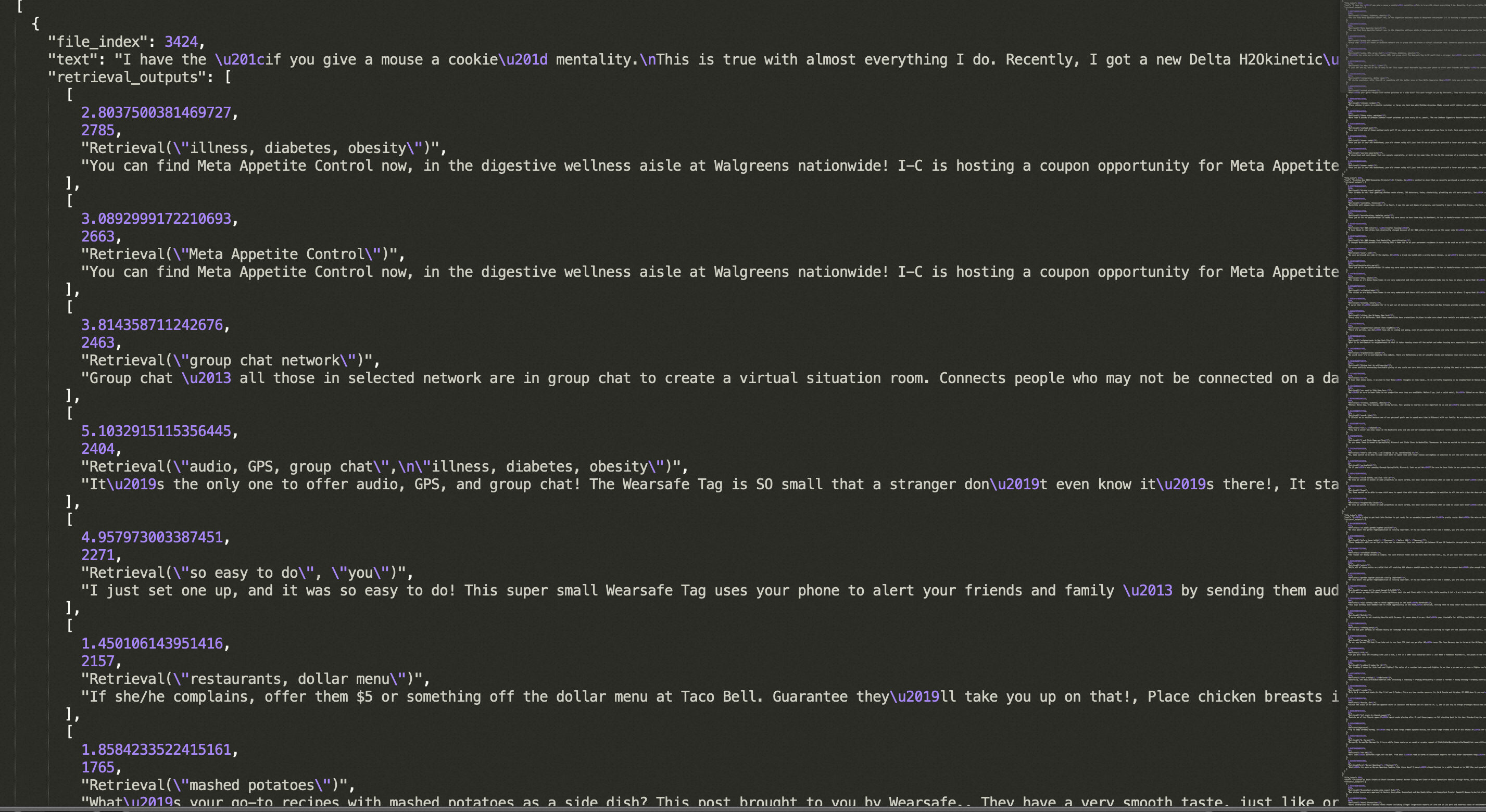
数据增强后的训练语料如下:


可以看到,训练语料中特定事实性token后面跟上了API query定界符。
0x2:使用增强数据集( tool-augmented corpus)进行LLM微调训练
We used huggingface's run_clm.py which we put in this repository as train_gptj_toolformer.py.
We used a batch size of 32 (8/device), command used is below
# 使用hugface上已经开源的处理好的增强数据集 CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python3 train_gptj_toolformer.py --model_name_or_path=EleutherAI/gpt-j-6B --per_device_train_batch_size=4 \ --num_train_epochs 20 --save_strategy=epoch --output_dir=finetune_toolformer_v0 --report_to "wandb" \ --dataset_name dmayhem93/toolformer-v0-postprocessed --tokenizer_name customToolformer \ --block_size 2048 --gradient_accumulation_steps 1 --do_train --do_eval --evaluation_strategy=epoch \ --logging_strategy=epoch --fp16 --overwrite_output_dir --adam_beta1=0.9 --adam_beta2=0.999 \ --weight_decay=2e-02 --learning_rate=1e-05 --warmup_steps=100 --per_device_eval_batch_size=1 \ --cache_dir="hf_cache" --gradient_checkpointing=True # 使用本地处理好的增强数据集
0x3:Inference example
注意!在更一般化地LLM App研发场景中,用户的输入往往只有一段简单的问题,需要由模型自己翻译为包含需要API调用的prompt
- 比如利用思维链技术展开为包含需要API调用的多步骤推理过程
- 或者预先定义好一些包含API调用范式的instruction prompt template
这里我们演示第二种方法,即“预先定义好一些包含API调用范式的instruction prompt template"。
这里假设已经完成了prompt的构建,通过few-shot技术,输入toolformer LLM模型,生成出包含形式化API调用的形式化prompt,并完成真实API调用并获取结果。
calculator_prompt = """ Your task is to add calls to a Calculator API to a piece of text. The calls should help you get information required to complete the text. You can call the API by writing "[Calculator(expression)]" where "expression" is the expression to be computed. Here are some examples of API calls: Input: The number in the next term is 18 + 12 x 3 = 54. Output: The number in the next term is 18 + 12 x 3 = [Calculator(18 + 12 * 3)] 54. Input: The population is 658,893 people. This is 11.4% of the national average of 5,763,868 people. Output: The population is 658,893 people. This is 11.4% of the national average of [Calculator(658,893 / 11.4%)] 5,763,868 people. Input: A total of 252 qualifying matches were played, and 723 goals were scored (an average of 2.87 per match). This is three times less than the 2169 goals last year. Output: A total of 252 qualifying matches were played, and 723 goals were scored (an average of [Calculator(723 / 252)] 2.87 per match). This is twenty goals more than the [Calculator(723 - 20)] 703 goals last year. Input: I went to Paris in 1994 and stayed there until 2011, so in total, it was 17 years. Output: I went to Paris in 1994 and stayed there until 2011, so in total, it was [Calculator(2011 - 1994)] 17 years. Input: From this, we have 4 * 30 minutes = 120 minutes. Output: From this, we have 4 * 30 minutes = [Calculator(4 * 30)] 120 minutes. Input: The number in the next term is 18 + 12 x 1 = 31. Output: """ retrieval_prompt = """ Your task is to complete a given piece of text. You can use a Retrieval API to look up information from previous sentences. You can do so by writing "[Retrieval(term)]" where "term" is the search term you want to look up. Here are some examples of API calls: Input: As we mentioned before, the colors on the flag of Ghana have the following meanings: red is for the blood of martyrs, green for forests, and gold for mineral wealth. Output: As we mentioned before, the colors on the flag of Ghana have the following meanings: red is for [Retrieval("Ghana flag color")] the blood of martyrs, green for forests, and gold for mineral wealth. Input: But what are the risks during production of nanomaterials? Some nanomaterials may give rise to various kinds of lung damage. Output: But what are the risks during production of nanomaterials? [Retrieval("nanomaterial production risks")] Some nanomaterials may give rise to various kinds of lung damage. Input: Metformin is the first-line drug for patients with type 2 diabetes and obesity. Output: Metformin is the first-line drug for [Retrieval("illness, diabetes, obesity")] patients with type 2 diabetes and obesity. Input: <REPLACEGPT> Output: """ llmchain_prompt = """ Your task is to complete a given piece of text. You can use a Large Language Model to predict information. You can do so by writing "[LLMChain(term)]" where "term" is the search term you want to look up. Here are some examples of API calls: Input: As we mentioned before, the colors on the flag of Ghana have the following meanings: red is for the blood of martyrs, green for forests, and gold for mineral wealth. Output: As we mentioned before, the colors on the flag of Ghana have the following meanings: red is for [LLMChain("Ghana flag color")] the blood of martyrs, green for forests, and gold for mineral wealth. Input: But what are the risks during production of nanomaterials? Some nanomaterials may give rise to various kinds of lung damage. Output: But what are the risks during production of nanomaterials? [LLMChain("nanomaterial production risks")] Some nanomaterials may give rise to various kinds of lung damage. Input: Metformin is the first-line drug for patients with type 2 diabetes and obesity. Output: Metformin is the first-line drug for [LLMChain("Metformin is a drug for")] patients with type 2 diabetes and obesity. Input: <REPLACEGPT> Output: """ wikipedia_search_prompt = """ Your task is to complete a given piece of text. You can use a Wikipedia Search API to look up information. You can do so by writing "[WikiSearch(term)]" where "term" is the search term you want to look up. Here are some examples of API calls: Input: The colors on the flag of Ghana have the following meanings: red is for the blood of martyrs, green for forests, and gold for mineral wealth. Output: The colors on the flag of Ghana have the following meanings: red is for [WikiSearch("Ghana flag red meaning")] the blood of martyrs, green for forests, and gold for mineral wealth. Input: But what are the risks during production of nanomaterials? Some nanomaterials may give rise to various kinds of lung damage. Output: But what are the risks during production of nanomaterials? [WikiSearch("nanomaterial production risks")] Some nanomaterials may give rise to various kinds of lung damage. Input: Metformin is the first-line drug for patients with type 2 diabetes and obesity. Output: Metformin is the first-line drug for [WikiSearch("Metformin first-line drug")] patients with type 2 diabetes and obesity. Input: x Output: """ machine_translation_prompt = """ Your task is to complete a given piece of text by using a Machine Translation API. You can do so by writing "[MT(text)]" where text is the text to be translated into English. Here are some examples: Input: He has published one book: O homem suprimido (“The Supressed Man”) Output: He has published one book: O homem suprimido [MT(O homem suprimido)] (“The Supressed Man”) Input: In Morris de Jonge’s Jeschuah, der klassische jüdische Mann, there is a description of a Jewish writer Output: In Morris de Jonge’s Jeschuah, der klassische jüdische Mann [MT(der klassische jüdische Mann)], there is a description of a Jewish writer Input: 南 京 高 淳 县 住 房 和 城 乡 建 设 局 城 市 新 区 设 计 a plane of reference Gaochun is one of seven districts of the provincial capital Nanjing Output: [MT(南京高淳县住房和城乡建设局 城市新 区 设 计)] a plane of reference Gaochun is one of seven districts of the provincial capital Nanjing Input: x Output: """ calendar_prompt = """ Your task is to add calls to a Calendar API to a piece of text. The API calls should help you get information required to complete the text. You can call the API by writing "[Calendar()]" Here are some examples of API calls: Input: Today is the first Friday of the year. Output: Today is the first [Calendar()] Friday of the year. Input: The president of the United States is Joe Biden. Output: The president of the United States is [Calendar()] Joe Biden. Input: The current day of the week is Wednesday. Output: The current day of the week is [Calendar()] Wednesday. Input: The number of days from now until Christmas is 30. Output: The number of days from now until Christmas is [Calendar()] 30. Input: The store is never open on the weekend, so today it is closed. Output: The store is never open on the weekend, so today [Calendar()] it is closed. Input: x Output: """
示例代码如下,
import torch from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline tokenizer = AutoTokenizer.from_pretrained(r"dmayhem93/toolformer_v0_epoch2") model = AutoModelForCausalLM.from_pretrained( r"dmayhem93/toolformer_v0_epoch2", torch_dtype=torch.float16, low_cpu_mem_usage=True, ).cuda() generator = pipeline( "text-generation", model=model, tokenizer=tokenizer, device=0 ) calculator_prompt = """ Your task is to add calls to a Calendar API to a piece of text. The API calls should help you get information required to complete the text. You can call the API by writing "[Calendar()]" Here are some examples of API calls: Input: Today is the first Friday of the year. Output: Today is the first [Calendar()] Friday of the year. Input: The president of the United States is Joe Biden. Output: The president of the United States is [Calendar()] Joe Biden. Input: The number of days from now until Christmas is 30 Output: """ output_to_check = generator(calculator_prompt, do_sample=True, top_k=50, max_new_tokens=256) print("output_to_check: ", output_to_check)

output_to_check: [ { 'generated_text': '\n Your task is to add calls to a Calendar API to a piece of text.\n The API calls should help you get information required to complete the text.\n You can call the API by writing "[Calendar()]"\n Here are some examples of API calls:\n Input: Today is the first Friday of the year.\n Output: Today is the first [Calendar()] Friday of the year.\n Input: The president of the United States is Joe Biden.\n Output: The president of the United States is [Calendar()] Joe Biden.\n Input: The number of days from now until Christmas is 30\n Output: \n The number of days from now until [Calendar()] Christmas is \n Thirty.\n Tags: Date, future, holiday, now, past, present, quick, weekday, years, week, year, weekday name, ISO dates, Google Calendar API, Calendar app for Android, calendar app, iCal, ical, iPhone, ios, Mac Calendar, Mac Calendar app, windows\n Structure: Calendar Challenge 3 is a single PDF document. It contains 5 Word files and 1 Spreadsheet. It also has an interactive Table of Contents to make finding the Challenge information a bit easier.\n The Word files and Spreadsheet come into their own when you’re trying to print a summary of the Challenges. The summary lists each Date, the Calculus-based Challenge it belongs to, and the correct answer. This way you can simply print it off and complete the challenges on your own. If you don’t fancy doing it alone, you can print the whole thing off and complete the challenges at a different time (I did this each time I found a new Challenge in the list). You’ll even gain 2 reputation from these activities so go ahead and print off as many summary sheets as you need!\nThe Excel file comes in handy' } ]
可以看到,原始输入中涉及日期的字符周围被插入了[Calendar()]定界符,并返回了真实执行结果。
0x4:使用toolformer-pytorch直接基于API CALL instruction prompt template进行Tool Call Inference
安装:
pip install toolformer-pytorch
Example usage with giving language models awareness of current date and time.
import torch from toolformer_pytorch import Toolformer, PaLM # simple calendar api call - function that returns a string def Calendar(): import datetime from calendar import day_name, month_name now = datetime.datetime.now() return f'Today is {day_name[now.weekday()]}, {month_name[now.month]} {now.day}, {now.year}.' # prompt for teaching it to use the Calendar function from above prompt = f""" Your task is to add calls to a Calendar API to a piece of text. The API calls should help you get information required to complete the text. You can call the API by writing "[Calendar()]" Here are some examples of API calls: Input: Today is the first Friday of the year. Output: Today is the first [Calendar()] Friday of the year. Input: The president of the United States is Joe Biden. Output: The president of the United States is [Calendar()] Joe Biden. Input: [input] Output: """ data = [ "The store is never open on the weekend, so today it is closed.", "The number of days from now until Christmas is 30", "The current day of the week is Wednesday." ] # model - here using PaLM, but any nn.Module that returns logits in the shape (batch, seq, num_tokens) is fine model = PaLM( dim = 512, depth = 2, heads = 8, dim_head = 64 ).cuda() # toolformer toolformer = Toolformer( model = model, model_seq_len = 256, teach_tool_prompt = prompt, tool_id = 'Calendar', tool = Calendar, finetune = True ) # invoking this will # (1) prompt the model with your inputs (data), inserted into [input] tag # (2) with the sampled outputs, filter out the ones that made proper API calls # (3) execute the API calls with the `tool` given # (4) filter with the specialized filter function (which can be used independently as shown in the next section) # (5) fine-tune on the filtered results filtered_stats = toolformer(data) # then, once you see the 'finetune complete' message response = toolformer.sample_model_with_api_calls("How many days until the next new years?") # hopefully you see it invoke the calendar and utilize the response of the api call...
参考链接:
https://huggingface.co/datasets/dmayhem93/toolformer-v0-postprocessed/viewer/dmayhem93--toolformer-v0-postprocessed/train?row=5 https://huggingface.co/datasets/dmayhem93/toolformer_raw_v0/viewer/dmayhem93--toolformer_raw_v0/train https://huggingface.co/datasets/dmayhem93/toolformer_raw_v0/resolve/8432a6615939d947fce807716ed89ace20befbdd/calc_data_0.json https://openi.pcl.ac.cn/yangyang/toolformer/src/branch/master#user-content-data-generation https://huggingface.co/dmayhem93/toolformer_v0_epoch2 https://github.com/conceptofmind/toolformer https://huggingface.co/docs/transformers/pipeline_tutorial https://github.com/lucidrains/toolformer-pytorch/tree/main
五、一些其他的项目
0x1:MOSS
https://github.com/OpenLMLab/MOSS
https://github.com/OpenLMLab/MOSS_WebSearchTool
https://github.com/OpenLMLab/MOSS_WebSearchTool/blob/main/retrieval_backend.py
https://github.com/OpenLMLab/MOSS_WebSearchTool/blob/main/google_search.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号