南京大学 静态软件分析(static program analyzes)-- Datalog-Based Program Analysis 学习笔记
一、Motivation:Datalog-Based Program Analysis
声明式语言和指令式语言的区别
Datalog是一种声明式(Declarative)的编程语言,与之相对的另一种语言是命令式(Imperative)编程语言。
举一个例子说明说明两者之间的区别,

- 命令式语言是直接告诉程序需要做哪些指令(how to do),典型的如C、JAVA
- 声明式语言是告诉程序要得到什么结果(what to do),典型的如sql,声明式语言更加精炼
使用哪种语言去实现PTA?
1、使用Imperative(命令式)
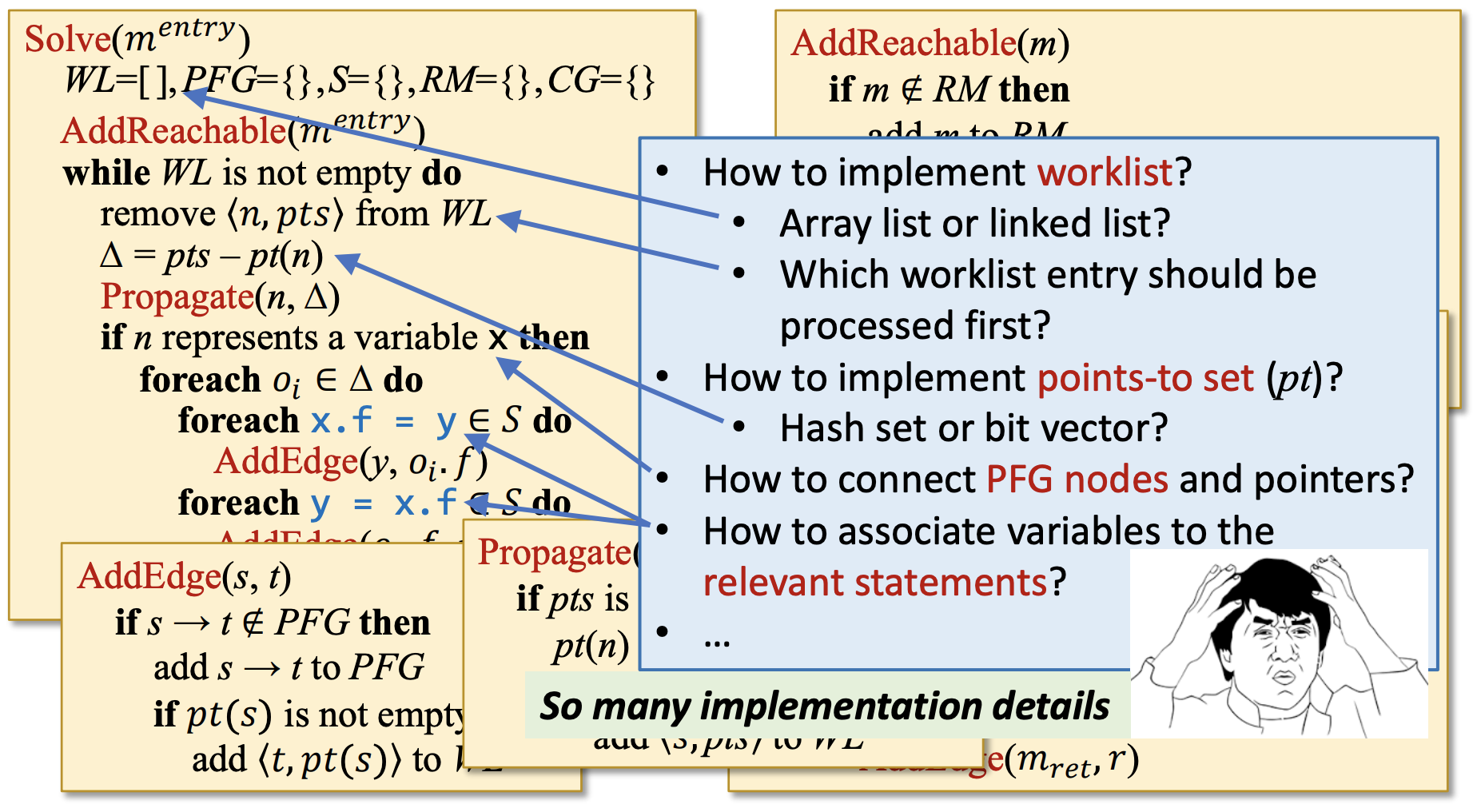
若使用命令式实现PTA,实现复杂。
- worklist数据结构是数组list还是链表,是先进先出还是先进后出?
- 如何表示指针集合,hash集还是bit向量?
- 如何关联PFG节点和指针?
- 如何联系相关语句和其中的变量?
2、使用Datalog(声明式)

声明式PTA实现有以下优点:
- 简洁
- 可读性好
- 易于实现
二、Introduction to Datalog
Datalog:是声明式编程语言,是Prolog的子集,最初用于数据库,现在广泛应用于程序分析、网络定义、大数据、云计算等。
Datalog=Data+Logic(and,or,not)
- Datalog没有副作用(没有赋值)
- 没有控制流
- 没有函数
- 非图灵完备
Predicates (Data)
1、谓词Predicates
谓词(Predicates)是datalog中的一个主要组成部分,可以看作是数据所组成的一个表(table of data),谓词中的每一行都代表一个事实(fact)。例如:

- (”Xiaoming“,18)是一个fact
- (”Abal“,23)在该数据集中找不到,不是一个fact
- Age是一个谓词、Person也可以是一个谓词,对应到SQL里就是某个数据集中的一列
谓词Predicate可以看作一系列陈述的集合,陈述某事情的事实(真假)。如
- Age,表示一些人的年龄
- Person,表示一些人的姓名
总体上,谓词可以分为两类,
- EDB (extensional database):在程序运行前,这些数据已经给定
- IDB (intensional database):这一类数据仅由规则推导得来

2、事实Fact
表示一个组合是否属于一种关系,比如
- ("Xiaoming", 18)可以表示“Xiaoming的年龄是18岁”,但注意这个陈述不一定值为True。
3、原子Atoms
原子(Atoms)是Datalog中的基本元素,原子Atoms的基本格式是:P(X1, X2, ... , Xn),
- P表示谓词名
- Xi表示参数
比如Age("Xiaoming", 18)
形式化表述和例子如下:

Atoms可以分成两类:
- Relational Atoms
- Arithmetic Atoms

Datalog Rules (Logic)
Datalog使用规则来进行推导(inference),总共有如下几种推导类型,
- Logic And
- Logic Or
- Logic Not/Negation
- Recursion
1、Logic And
定义如下:

当Body中的所有表达式都为True时,Head才为True,如:

求解过程(Interpretation of Datalog Rules)是枚举Body中所有关系表达式的可能取值组合,进而得到新的predicate/table。例如:

2、Logic Or
逻辑或有两种写法,

注意,逻辑与的优先级比逻辑或的优先级高。
建议在书写程序时用括号明确地标识期望的运算优先级:H<-A,(B;C)。
3、Logic Not/Negation

4、Recursion


Rule Safety
Rule的安全性问题需要特别关注,注意看这两条Rules看起来有什么问题,

上面两条Rule都是非安全的,这里最核心的问题在于:
由于x有无限的取值能满足规则,所以生成的A是一个无限大的关系。因此上述两条规则是不安全的。在Datalog中,只接受安全的规则。
这里我们需要记住一个判定的准则:
- 产生的数据必须有穷:如果规则中的每个变量至少在一个non-nageted relational atom中出现一次,那么这个规则是安全的。这实际上是借助已有的predicates(它们必定是有限的)来限制变量的取值范围。
类似地,还有这样的规则:

对应地有第二个准则:
-
推导规则不能出现悖论(H和Bi间出现矛盾):不要把recursion和negation写在同一条规则里,即避免写出非A推导出A这样的循环悖论规则。
Execution of Datalog Programs
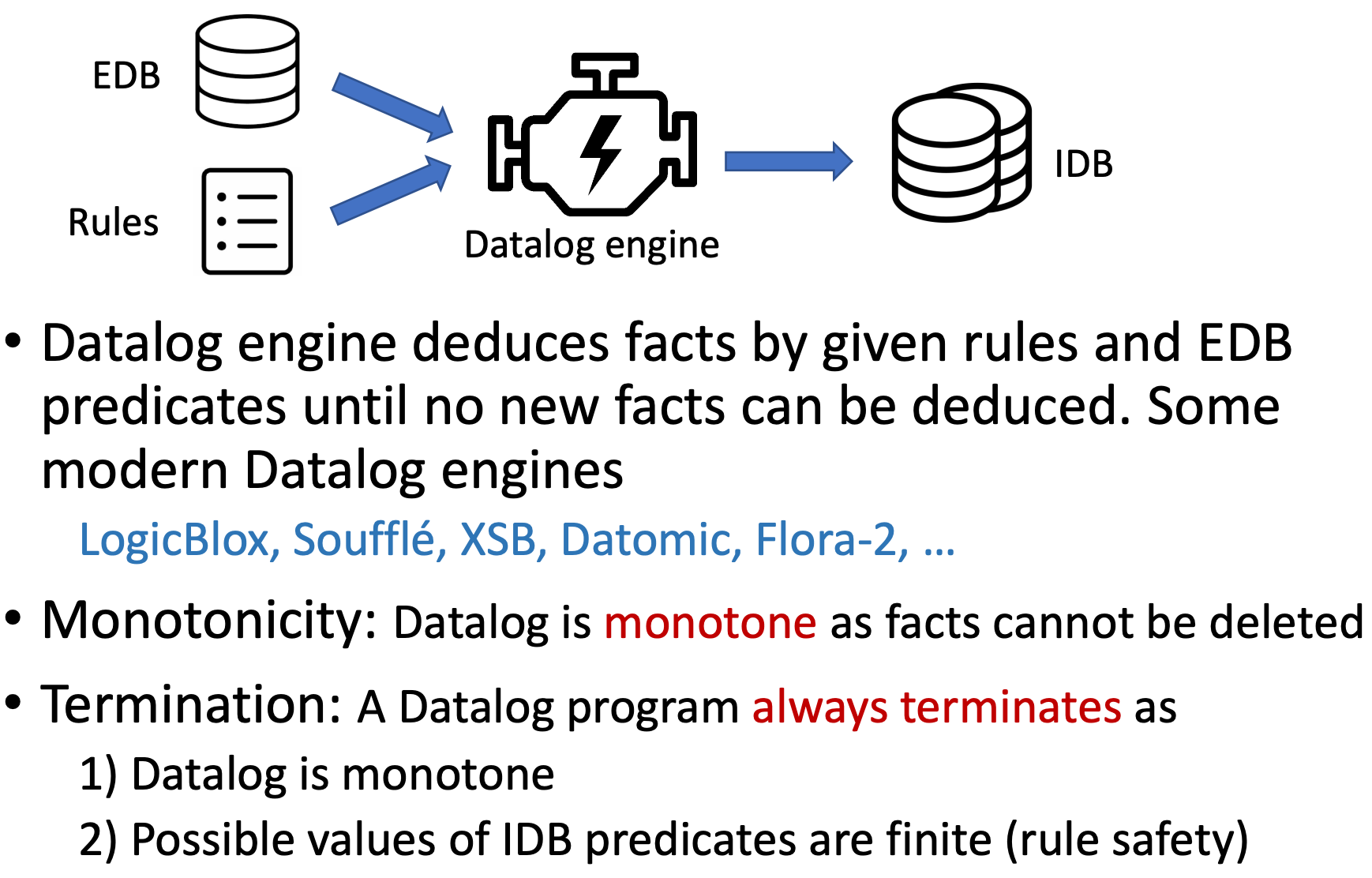
Datalog的两大重要特性:
- 单调性。因为事实(facts)不会被删除的。
- 必然终止。
- 事实的数量是单调的。
- 由Rule Safety,所能得到的IDB的大小也是有限的。
三、Pointer Analysis via Datalog
了解了Datalog的基本语法和性质,我们就可以用它来实现声明式的指针分析算法。
关于声明式的指针分析算法,三个重要的部分如下:
- EDB: pointer-relevant information that can be extracted from program syntactically
- IDB: pointer analysis results
- Rules: pointer analysis rules
Datalog Model for Pointer Analysis-EDB&IDB
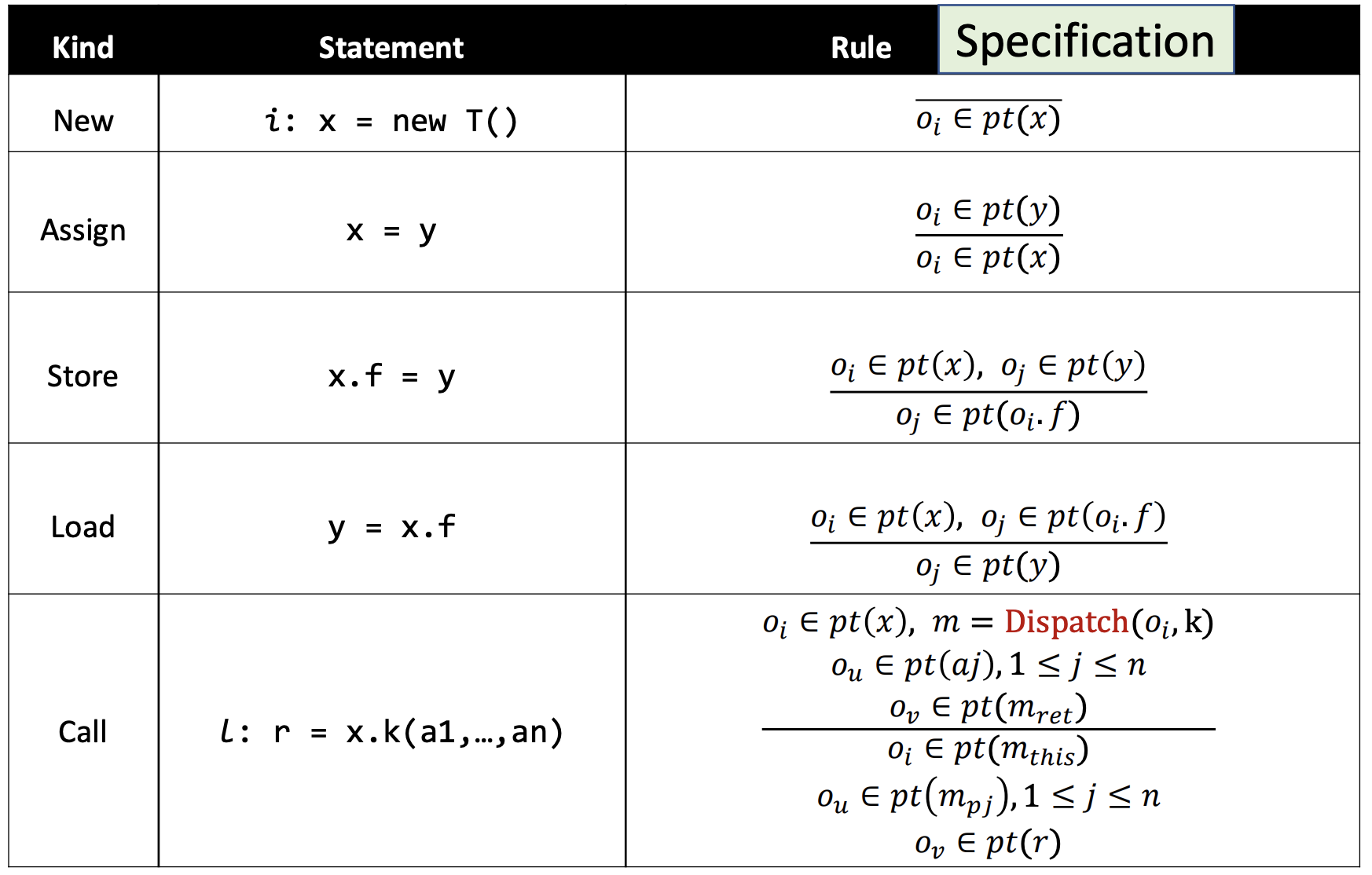
1、基本语句(New、Assign、Store、Load)
我们首先需要对前四条语句建模。输入的EDB代表了4个存储相应类型语句的table,输出为Variable和Field的指向关系。

举一个例子说明怎么对指针分析中的基本语句建模为EDB,

2、Method Calls语句
处理This
对于基于Datalog的PTA,首先,我们需要引入新的EDB和IDB:

- EDB:
- VCall(方法调用)
- Dispatch(表格的形式表达找到的函数)
- ThisVar(储存变量)
- IDB:
- Reachable(可达方法)
- CallGraph
处理Parameters
接下来要处理参数的传递,与之前类似,需要引入新的EDB和IDB:

- EDB:
- Argument(调用语句行号,参数标号和参数本身)
- Parameter(被调用方法,参数标号和参数本身)
- IDB:空
对应用Datalog书写的规则如果用自然语言描述,就是处理行号l处对m的调用时,根据形参和实参的信息,将实参已经有的指向关系传递给形参数。
处理返回值
引入新的EDB和IDB:

- EDB:
-
方法的返回值
-
在调用点处的接收返回值的变量
-
- IDB:空
Sum up
以上三个部分总结起来,就能得到以下的Datalog Rules。

Datalog Model for Pointer Analysis-Rules
对于New,创建语句推导出指针对对象的指向

对于Assign,赋值语句和指向信息推导出新的指向信息

对于Store,x和y的指向信息和Store语句推导出域指向信息

对于Load,Load语句、x的指向信息和域指向信息推导出y的指向信息

- Body代表前提(红线)
- Head代表结论(蓝线)
An Example
根据Datalog算法和Datalog的执行规则,分析下面这段代码,给出推导结束后的IDB。
如前面所属,EDB已知,

处理new语句,
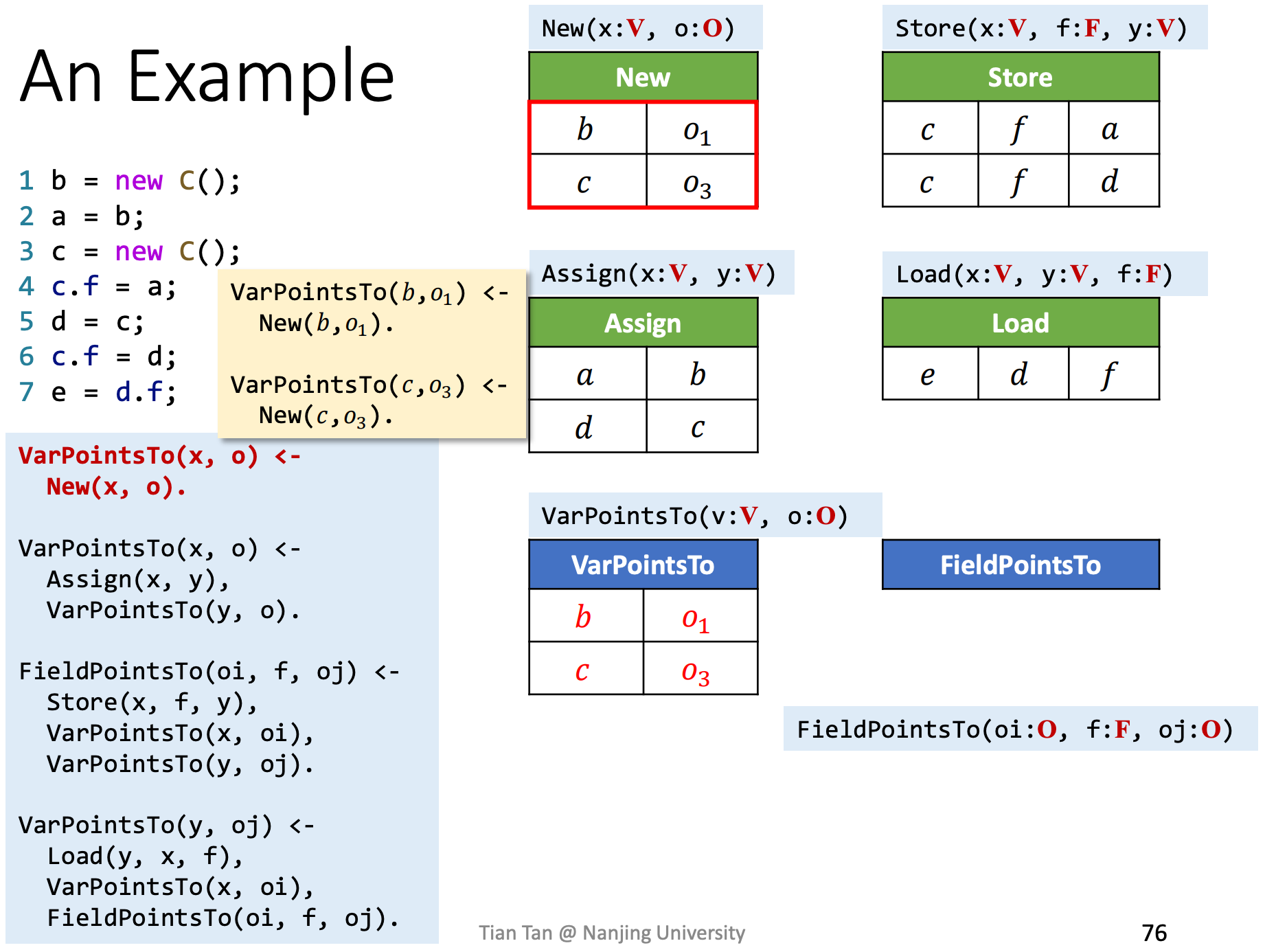
处理assign语句,

处理store语句,
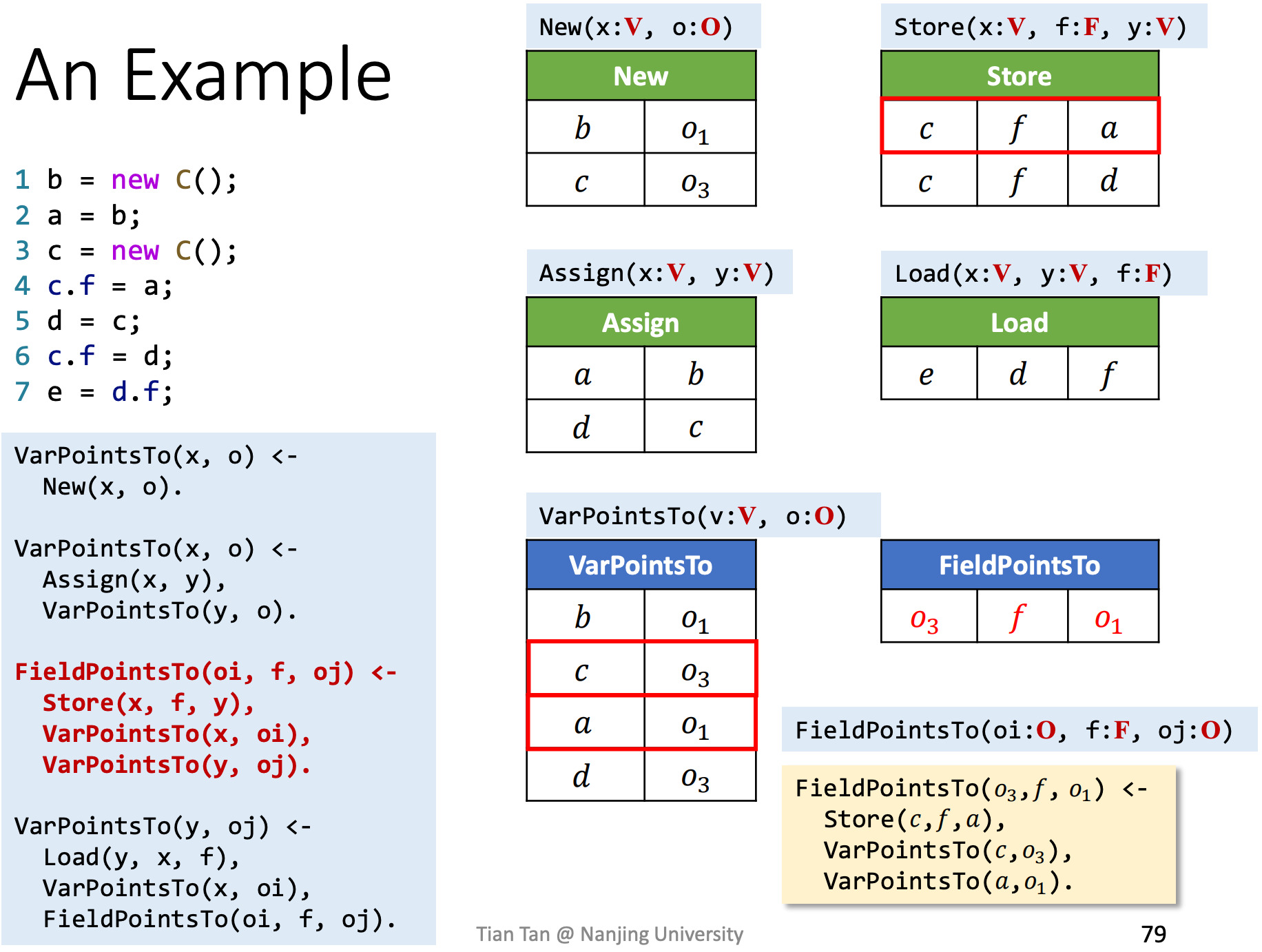

处理load语句,

最终IDB结果如下:

Whole-Program Pointer Analysis
综上,得到全程序的分析算法如下。
值得一提的是,在VarPointsTo(x,o)规则中,添加Reachable(m)跳过不可达方法中的对象。而其他规则不需要加这一条件,则是因为它们都有VarPointsTo规则作为Body的一部分。

四、Taint Analysis via Datalog
Datalog Model
使用Datalog进行污点分析,需要用户提供Source和Sink。输出被标记的数据可能流到的Sink方法。
- DB:
- Source(m : M):source函数
- Sink(m : M):sink函数
- Taint(l : S, t : T):关联调用点和调用点处的污点数据
- IDB:
- TaintFlow(t : T, m : M):识别出的污染流处理规则(source和sink的处理):

Datalog Rules

- 对于source,首先找到一条调用边,它是source,取出返回值接收变量r,以及调用点关联的污点数据t;推导出r指针指向污点数据t。
- 对于sink,首先找到一条调用边,它是sink,取出形参(不关心哪个形参),形参指向的污点数据以及确认的污染数据t(不关心t来源于哪一行);推导出污染数据t会传给sink函数m,得到一条污染流。
五、Datalog的优缺点
- 优点:
- 简洁可读
- 易于实现
- 得益于已有的成熟的优化引擎,速度快
- 缺点:
- 表达能力受限,非图灵完备,有的情况处理不了(比如有的时候需要中途去掉一些sinks,Datalog就无法实现;表达单个存在很容易,但表达同时满足多个存在比较困难,通常需要双重否定)
- 不能完全控制性能(底层已经实现了,无法再进行优化)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号