后缀自动机(SAM)学习笔记
后缀自动机的概念比较抽象,首先给出SAM的讲义
一、SAM的性质:
1.SAM是个状态机。一个起点,若干终点。原串的所有子串和从SAM起点开始的所有路径一一对应,不重不漏。所以终点就是包含后缀的点。
2.每个点包含若干子串,每个子串都一一对应一条从起点到该点的路径。且这些子串一定是里面最长子串的连续后缀。
3.SAM问题中经常考虑两种边:
(1) 普通边,类似于Trie。表示在某个状态所表示的所有子串的后面添加一个字符。
(2) Link、Father。表示将某个状态所表示的最短子串的首字母删除。这类边构成一棵树(在一些文章中被称为 parent 树)。
二、SAM的构造思路
1.endpos(s):子串s所有出现的位置(尾字母下标)集合。SAM中的每个状态都一一对应一个endpos的等价类。
2.endpos的性质:
(1) 令 s1,s2 为 S 的两个子串 ,不妨设 |s1|≤|s2| (我们用 |s| 表示 s 的长度 ,此处等价于 s1 不长于 s2 )。则 s1 是 s2 的后缀当且仅当 endpos(s1) ⊇ endpos(s2) ,s1 不是 s2 的后缀当且仅当 endpos(s1) ∩ endpos(s2)=∅ 。
(2) 两个不同子串的endpos,要么有包含关系,要么没有交集。
(3) 两个子串的endpos相同,那么短串为长串的后缀。
(4) 对于一个状态 st ,以及任意的 longest(st) 的后缀 s ,如果 s 的长度满足:|shortest(st)|≤|s|≤|longest(st)| ,那么 s∈substrings(st) 。
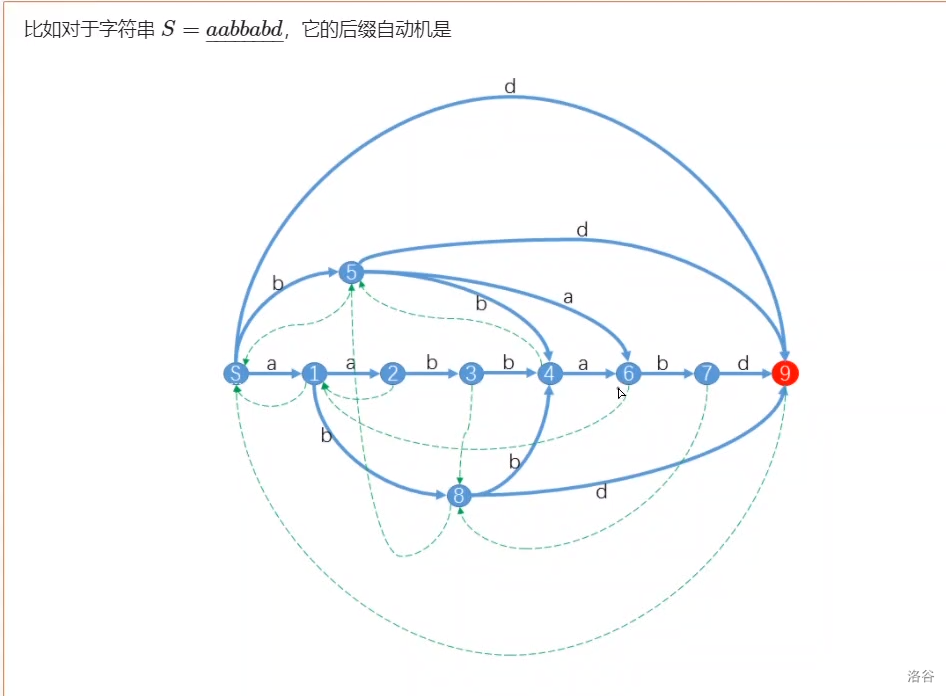
下面以这个自动机为例解释SAM的性质和构造思路。
一、SAM的性质:
1.从图中就可以看出路径和子串一一对应。
2.以四号节点为例,最长子串为 \(\underline{aabb}\),所对应的子串集合为 {\(\underline{aabb}\),\(\underline{abb}\),\(\underline{bb}\) }。
3.图中的蓝色边为普通边,绿色边为构成树的边。蓝色边构成一个 DAG,表示在该点所对应的所有状态后面补上一个字符;绿色边表示当前所有的子串中最短的一个子串删去第一个字符后所对应的节点所对应的节点与当前节点的连边(由性质1可知,这个节点有且仅有一个。这个子串实际上就是下一个后缀),以 \(4\) 节点为例,删去后的子串就是 \(\underline{b}\),所对应的节点是 \(5\),那么就从 \(4\) 向 \(5\) 连一条边,其中 \(5\) 是父节点。
二、SAM的构造思路
1.以 \(E\) 来代表 \(endpos\),例如 $E(\underline{ab})={ 3,6 } $。所有出现位置相同即 \(E\) 相同的子串对应一个等价类,如 $E(\underline{abb})=E(\underline{aabb})= 4 $。
2.endpos的性质:
(1) 本条性质正确性显然。
(2) 本条性质从性质 (1) 可以推出。
(3) 本条性质实际上就是性质(1)的特例。
(4) 状态指的是 \(E\) 相同的子串,即等价类。例如某一个等价类里同时包含子串 \(\underline{abcdefg}\) 和 \(\underline{defg}\),那么这个等价类中必然还存在子串 \(\underline{bcdefg}\) 和 \(\underline{cdefg}\)。可以根据夹逼定理证明本条性质。
根据上面提到的性质,一个子串的连续子串,以状态 \(4\) (也就是节点 \(4\) 所代表的子串)为例,它包含 {\(\underline{aabb}\),\(\underline{abb}\),\(\underline{bb}\) }。但是它不包含 \(\underline{b}\)。因为越短的子串越可能在此之前就出现过,根据图上绿色边的定义,节点 \(4\) 所指向的节点 \(5\) 就是以 \(\underline{b}\) 开始的连续后缀。就可以得到 \(\min_i=\max_{fa_i}+1\) (其中 \(\min,\max\) 均表示子串长度的最值,下面还会用到)。接下来考虑几个常见的问题。
1.如何求不同子串的数量。可以用后缀数组求解,这里再介绍一下如何利用后缀自动机求解。
根据路径和子串一一对应的关系,那么每个点所表示的所有串都互不相同。那么只需求出每个点表示的不同子串的数量,它们的累加和就是答案。
根据 \(endpos\) 的性质(1),点 \(i\) 所对应的不同子串数量就是 \(\max_i-\min_i+1\)。其中 \(\min_i\) 的维护方法已经在上面提到过。
2.如何求每个子串的出现次数。不难发现,求子串 \(S\) 的出现次数等价于求 \(|E(S)|\),即集合 \(E(S)\) 的元素数量。
利用绿色边的性质,父亲节点中的子串一定能由儿子节点中的任意子串删去开头的若干字符得到。根据 \(E\) 的性质(2),该父亲节点的任意两个儿子节点之间的交集一定为空,那么直接累加即可。
另外,如果该节点所对应的子串是原串的前缀,就代表也可以从这些子串开始删除(因为实际上我们就是通过删除前缀的开头字符来得到不同子串),需要额外加上(实际上就是图中的 \(1,2,3,4,6,7,9\) 节点,各自对应一个前缀,需要额外 \(+1\))。
后缀自动机的构造过程证明比较复杂,主要是分类讨论,正确性证明可以自行百度。主要看代码实现。
【模板】后缀自动机
给定一个只包含小写字母的字符串 \(S\),
请你求出 \(S\) 的所有出现次数不为 \(1\) 的子串的出现次数乘上该子串长度的最大值。
数据范围
\(1 \leq |S| \leq 10^6\)。
思路
对于一个等价类中的子串,出现次数相同,要求最大值,那么只需用该等价类的最长子串更新答案。
code:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=2e6+10;
char s[N];
long long ans,f[N];
struct SAM{
int ch[26];
int len,fa;//len表示的是最长子串的长度,下面简称长度
}node[N];
int last=1,tot=1;//由于后面要判空,最好用1号节点代表起始点
void extend(int c)
{
int p=last,np=last=++tot;
node[np].len=node[p].len+1;//新建节点就是在原来节点的最后面增加一个字符,故最长度也+1
f[tot]=1;
while(p&&!node[p].ch[c]) node[p].ch[c]=np,p=node[p].fa;//从p往父亲上跳,没有c儿子的都将c儿子更新为np
if(!p) node[np].fa=1;//如果p的祖先都没有c儿子,那么就说明np节点所代表的最短子串就是c一个字符,删去后就是空字符,自然就指向起点
else
{
int q=node[p].ch[c];
if(node[q].len==node[p].len+1) node[np].fa=q;
//如果q的长度恰好是p的长度+1,那么就说明q恰好就是p删去最短子串开头后所得到的子串对应的节点(可以画图理解)
else//否则就新建一个节点代表p的父亲
{
int nq=++tot;
node[nq]=node[q];node[nq].len=node[p].len+1;//nq完全复制q的信息
node[q].fa=node[np].fa=nq;//nq就成为q和np的父亲
while(p&&node[p].ch[c]==q) node[p].ch[c]=nq,p=node[p].fa;//这条链上所有指向q的节点都指向q
}
}
}
struct edge{int v,nex;}e[N];
int h[N],idx; void add(int u,int v){e[++idx].v=v;e[idx].nex=h[u];h[u]=idx;}
void dfs(int u)
{
for(int i=h[u];i;i=e[i].nex)
{
int v=e[i].v;dfs(v);
f[u]+=f[v];
}
if(f[u]>1) ans=max(ans,1ll*f[u]*node[u].len);//别忘了题意要求出现次数大于1
}
int main()
{
scanf("%s",s);for(int i=0;s[i];i++) extend(s[i]-'a');
for(int i=2;i<=tot;i++) add(node[i].fa,i);
dfs(1);printf("%lld\n",ans);
return 0;
}
【例题】玄武密码
经过分析,我们可以用东南西北四个方向来描述台城城砖的摆放,不妨用一个长度为 N 的序列来描述,序列中的元素分别是 E,S,W,N,代表了东南西北四向,我们称之为母串。
而神秘的玄武密码是由四象的图案描述而成的 M 段文字。
这里的四象,分别是东之青龙,西之白虎,南之朱雀,北之玄武,对东南西北四向相对应。
现在,考古工作者遇到了一个难题。
对于每一段文字,其前缀在母串上的最大匹配长度是多少呢?
简化版题意
给出一个文本串,多次询问模式串的前缀与其的最长公共子串的长度。
数据范围
\(1≤N≤10^7\),\(1≤M≤10^5\)。
思路
其实本题才是SAM的最简单的模板题。只需在SAM上按照类似于 Trie 树的方法往下走,直到不能走为止就可以了。子串和路径一一对应保证了正确性,下一题也需要用到。
code:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=2e7+10;
char s[N];
struct SAM{
int ch[4],fa,len;
}node[N];
int get(char c)
{
if(c=='W') return 0;
if(c=='S') return 1;
if(c=='E') return 2;
return 3;
}
int last=1,tot=1,n,m;
void extend(int c)
{
int p=last,np=last=++tot;node[np].len=node[p].len+1;
while(p&&!node[p].ch[c]) node[p].ch[c]=np,p=node[p].fa;
if(!p) node[np].fa=1;
else
{
int q=node[p].ch[c];
if(node[p].len+1==node[q].len) node[np].fa=q;
else
{
int nq=++tot;node[nq]=node[q];node[nq].len=node[p].len+1;
node[q].fa=node[np].fa=nq;
while(p&&node[p].ch[c]==q) node[p].ch[c]=nq,p=node[p].fa;
}
}
}
int main()
{
scanf("%d%d%s",&n,&m,s);for(int i=0;s[i];i++) extend(get(s[i]));
while(m--)
{
scanf("%s",s);int ans=0,p=1;
for(int i=0;s[i];i++)
{
if(node[p].ch[get(s[i])]) p=node[p].ch[get(s[i])],ans++;
else break;
}
printf("%d\n",ans);
}
return 0;
}
【例题】最长公共子串
给定 \(n\) 个字符串,试求出这些字符串的最长公共子串。
数据范围
\(2≤n≤11\) ,每个字符串的长度不超过 \(10000\),字符串均由小写字母构成。
思路
相较于上题,本题求的是多个字符串的最长公共子串,没有特定要求前缀。先考虑一下如何用 SAM 求两个字符串的最长公共子串。
最朴素的思路,首先以 A 串建立 SAM。以 B 串第一个字符开始向后匹配,直到不能匹配更新答案,再从第二个字符开始重新匹配。以此类推。复杂度可以达到 \(O(n^2)\)。但是仔细想想 SAM 的一些性质,假设当前匹配到的最后一个节点为 \(i\),那么根据 SAM 的性质 2,直到它的最短串都是要匹配到 \(i\) 点,也还是不能继续匹配(相当于 B 串从第 \(k\) 个字符开始匹配时,\(A\) 串也匹配到了 \(i\) 点对应的第 \(k\) 长的子串,接下来要匹配的字符还是一样),那么就可以直接从 \(i\) 点的父亲开始匹配。类似于 KMP 算法中的失配指针,时间复杂度就可以降低到 \(O(n)\)。
回到本题中,如果 B 串在 \(i\) 点匹配到的长度为 \(5\),C 串在 \(i\) 点匹配到的长度为 \(6\),根据性质2,B 串的这一段长度为 \(5\) 的子串就是 C 串中这一段长度为 \(6\) 的子串的后缀。也就是只有这段长度为 \(5\) 的子串一定在 A,B,C 三个子串中同时出现过。于是就可以先在每一次匹配时在每个节点取最大值,接着在所有的匹配中取节点匹配的最小值,再在所有节点中取最大值。
需要注意的是,当前的字符串完全匹配完后,还需要在 parent 树上自底而上更新节点匹配的最大值。这是因为如果 B 和 C 都在 A 中完全出现,但是只有 B 和 C 的公共后缀是同时出现,那么此时如果不传给父亲,答案就是 \(0\)(如 \(abcd,abc,bcd\) 这组数据,但在某些 OJ 上数据比较水,不上传最大值也能通过。。。)。此时由于更新后长度可能会超过当前点对应的最大子串的长度,需要将答案的初始值设为最大子串的长度。
code:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=2e5+10;
char s[N];
struct edge{int v,nex;}e[N];
int h[N],idx; void add(int u,int v){e[++idx].v=v;e[idx].nex=h[u];h[u]=idx;}
int res,ans[N],now[N],n,last=1,tot=1;
struct SAM{int ch[26],fa,len;}node[N];
void extend(int c)
{
int p=last,np=last=++tot;node[np].len=node[p].len+1;
while(p&&!node[p].ch[c]) node[p].ch[c]=np,p=node[p].fa;
if(!p) node[np].fa=1;
else
{
int q=node[p].ch[c];
if(node[p].len+1==node[q].len) node[np].fa=q;
else
{
int nq=++tot;node[nq]=node[q];node[nq].len=node[p].len+1;
node[q].fa=node[np].fa=nq;
while(p&&node[p].ch[c]==q) node[p].ch[c]=nq,p=node[p].fa;
}
}
}
void dfs(int u)
{
for(int i=h[u];i;i=e[i].nex)
{
int v=e[i].v;dfs(v);
now[u]=max(now[u],now[v]);
}
}
int main()
{
scanf("%s",s);
for(int i=0;s[i];i++) extend(s[i]-'a');
for(int i=2;i<=tot;i++) add(node[i].fa,i);
for(int i=1;i<=tot;i++) ans[i]=node[i].len;
while(scanf("%s",s)!=EOF)
{
memset(now,0,sizeof(now));int p=1,t=0;
for(int i=0;s[i];i++)
{
int c=s[i]-'a';
while(p>1&&!node[p].ch[c]) p=node[p].fa,t=node[p].len;
if(node[p].ch[c]) p=node[p].ch[c],t++;//这两行类似于KMP算法
now[p]=max(now[p],t);//这里只更新了p点,但是它的父亲没有更新
}
dfs(1);for(int i=1;i<=tot;i++) ans[i]=min(ans[i],now[i]);
}
for(int i=1;i<=tot;i++) res=max(res,ans[i]);
printf("%d\n",res);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号