后缀数组学习笔记
定义
记一个长度为 \(n\) 的字符串 \(S\),以 \(S\) 中第 \(i\) 个下标开始到结尾的子串被称为 \(S\) 的第 \(i\) 个后缀。显然,一个长度为 \(n\) 的字符串有 \(n\) 个后缀。
下面介绍一种倍增算法实现 \(O(n \log n)\) 对后缀按字典序进行排序。
倍增算法
记 \(sa[i]\) 表示排名第 \(i\) 位的后缀,$ rk[i]$ 表示第 \(i\) 个后缀的排名。\( height[i]\) 表示 \(sa[i]\) 与 \(sa[i-1]\) 的最长公共前缀。
以字符串 aababb 为例,它的六个后缀分别为 aababb,ababb,babb,abb,bb,b。
第一次排序时只关注每个后缀的第一个字符,如果第一个字符相同,则不改变原来的相对顺序。得到 aababb,ababb,abb,babb,bb,b。对于此操作,可以用基数排序做到 \(O(n)\) 复杂度。
假设当前已经按照前 \(k\) 位排序(若后缀不足 \(k\) 位则补上空字符)。接下来将每个后缀的前 \(k\) 个字符当成第一关键字,将 \(k+1 \sim 2k\) 个字符作为第二关键字进行排序。每一轮结束后将所有后缀的第一关键字离散化。 那么就可以使用用基数排序,同时每次排序的字符数会扩大两倍,那么就得到了一个 \(O(n\log n)\) 的算法。
大体的思路就是这样,接下来讨论一下基数排序。
基数排序的复杂度与排序的值域相关。例如 \(5,2,2,1,1,3\),统计每个数字的出现次数后,利用前缀和求出 \(s[i]\),表示小于等于 \(i\) 的数的个数。从后往前遍历原数组,此时遍历到的 \(s[a[i]]\) 就是该数字排序后所在的位置,此时再将 \(s[a[i]]--\),这样就可以保证排序后相同数字的相对顺序不变。
其余的一些实现细节可以看代码。接下来讨论 height 数组。
记 \(lcp(i,j)\) 表示后缀 \(i\) 和 \(j\) 的最长公共子串。显然有 \(lcp(i,j)=lcp(j,i)\) ,不妨设 \(i < j\)。
对于所有的 \(i \leq k \leq j\),都有 \(lcp(i,j)=\min(lcp(i,k),lcp(k,j))\)。证明很简单,在每一个字符串前取 \(lcp\) ,对于排序后的字符串,显然有 \(i \leq k \leq j\),且 \(i=j\),那么自然就有 \(i=k=j\)了(这里的 \(i,j,k\) 代表取的子串)。
根据上面提到的性质,就有:
\(lcp(i,j)=\min(lcp(i,i+1),lcp(i+1,i+2)....lcp(j-1,j))\)。
而 \(lcp(i,i+1)\) 恰好就是 \(height[i+1]\)。
定义 h 数组,\(h[i]=height[rk[i]]\)。表示第 \(i\) 个后缀和它排序后前一个后缀的 \(lcp\)。可以得到一个性质:\(h[i] \geq h[i-1]-1\)。这个性质的证明比较复杂,这里以后缀 \(i-1\) 小于后缀 \(i\) 为例。
假设排序后排在 \(i-1\) 前面一位为后缀 \(k\),排在 \(i\) 前面一位为后缀 \(j\)。
若 \(h[i-1]=lcp(i-1,k)=0\),那么显然 \(h[i] \geq -1\)。
若 \(h[i-1]=lcp(i-1,k) \geq 1\),那么两个后缀的第一个字符相同,而对于这两个后缀从第二个字符开始的后缀,也就是后缀 \(i\) 和 \(k+1\),显然就有 \(rk[k+1] < rk[i]\),\(lcp(i,k+1)=lcp(k,i-1)-1=h[i-1]-1\) (就是减去开头的那个字符)。这里假设 \(rk[k+1] > rk[i-1]\),对于小于的情况同理。根据 \(lcp(k+1,i)=\min(lcp(k+1,j),lcp(j,i))\)。就有 \(lcp(j,i) \leq lcp(k+1,i)\),即 \(h[i] \geq h[i-1]-1\)。
利用这个性质,在求 \(h[i]\) 时就可以直接从第 \(h[i-1]-1\) 位开始枚举。也就可以将求 \(height\) 数组的复杂度降到 \(O(n)\)。
模板题代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e6+10;
int n,m;char s[N];
int sa[N],height[N],rk[N];//sa[i]:排名为i的后缀
int x[N],y[N],cnt[N];//x[i]表示第i个后缀离散化后对应的数字,y[i]表示按第二关键字排序后的排名为i的后缀
void get_sa()
{
for(int i=1;i<=n;i++) cnt[x[i]=s[i]]++;
for(int i=2;i<=m;i++) cnt[i]+=cnt[i-1];
for(int i=n;i>=1;i--) sa[cnt[x[i]]--]=i; //基数排序
for(int k=1;k<=n;k<<=1)
{
int num=0;
for(int i=n-k+1;i<=n;i++) y[++num]=i;
//对于最后k个后缀,它们的第二关键字为空,那么显然比前面的都小,按照第二关键字排序自然就在最后面,顺序遍历是不改变相对关系
//可以发现第i个后缀的第二关键字就是第i+k个字符的第一关键字,下面的j就是在枚举i+k
for(int j=1;j<=n;j++) if(sa[j]>k) y[++num]=sa[j]-k;
//对于原串的前k个后缀是无法作为其他后缀的第二关键字,而对于剩下的后缀,第二关键字排序就是i+k的第一关键字
//第二关键字排序结束
for(int i=1;i<=m;i++) cnt[i]=0;
for(int i=1;i<=n;i++) cnt[x[i]]++;
for(int i=2;i<=m;i++) cnt[i]+=cnt[i-1];
for(int i=n;i>=1;i--) sa[cnt[x[y[i]]]--]=y[i],y[i]=0;
//本处其实就是双关键字排序,由于需要保证当第一关键字相同后第二关键字有序,最里面的就是y[i]
swap(x,y); num=1;x[sa[1]]=1;
for(int i=2;i<=n;i++) x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
//离散化操作,如果第一和第二关键字都相同就默认二者相同
if(num==n) break;//如果没有相同的,即排序完毕
m=num;
}
}
void get_height()
{
for(int i=1;i<=n;i++) rk[sa[i]]=i;//排名为i的后缀排名为i
for(int i=1,k=0;i<=n;i++)
{
if(rk[i]==1) continue;//排名第一的后缀
if(k) k--;//即 h[i]>=h[i-1]-1,注意是h而不是height,因为下面的j!=i-1
int j=sa[rk[i]-1];//即排在i前面的后缀
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) k++;
height[rk[i]]=k;
}
}
int main()
{
scanf("%s",s+1);n=strlen(s+1);m=122;//'z'=122
get_sa();get_height();
for(int i=1;i<=n;i++) printf("%d ",sa[i]);puts("");
for(int i=1;i<=n;i++) printf("%d ",height[i]);puts("");
return 0;
}
【模板】品酒大会
一年一度的“幻影阁夏日品酒大会”隆重开幕了。
大会包含品尝和趣味挑战两个环节,分别向优胜者颁发“首席品酒家”和“首席猎手”两个奖项,吸引了众多品酒师参加。
在大会的晚餐上,调酒师 Rainbow 调制了 \(n\) 杯鸡尾酒。
这 \(n\) 杯鸡尾酒排成一行,其中第 \(i\) 杯酒 (\(1≤i≤n\)) 被贴上了一个标签 \(s_i\) ,每个标签都是 \(26\) 个小写英文字母之一。
设 \(str(l,r)\) 表示第 \(l\) 杯酒到第 \(r\) 杯酒的 \(r−l+1\) 个标签顺次连接构成的字符串。
若 \(str(p,p0)=str(q,q0)\),其中 \(1≤p≤p0≤n\), \(1≤q≤q0≤n\), \(p≠q\),\(p0−p+1=q0−q+1=r\) ,则称第 \(p\) 杯酒与第 \(q\) 杯酒是“ \(r\) 相似” 的。
当然两杯“ \(r\) 相似”\((r>1)\)的酒同时也是“ \(1\) 相似”、“ \(2\) 相似”、……、“ \((r−1)\) 相似”的。
特别地,对于任意的 \(1≤p\),\(q≤n\),\(p≠q\),第 \(p\) 杯酒和第 \(q\) 杯酒都是“ \(0\) 相似”的。
在品尝环节上,品酒师 Freda 轻松地评定了每一杯酒的美味度,凭借其专业的水准和经验成功夺取了“首席品酒家”的称号,其中第 \(i\) 杯酒 \((1≤i≤n)\) 的美味度为 \(a_i\) 。
现在 Rainbow 公布了挑战环节的问题:本次大会调制的鸡尾酒有一个特点,如果把第 \(p\) 杯酒与第 \(q\) 杯酒调兑在一起,将得到一杯美味度为 \(a_p×a_q\) 的酒。
现在请各位品酒师分别对于 \(r=0\),\(1\),\(2\),\(⋯\),\(n−1\) ,统计出有多少种方法可以选出 \(2\) 杯“ \(r\) 相似”的酒,并回答选择 \(2\) 杯“\(r\) 相似”的酒调兑可以得到的美味度的最大值。
数据范围
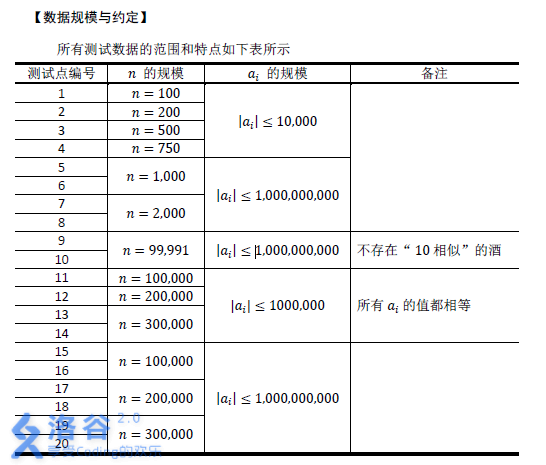
思路
先对原串的所有后缀进行排序,可以发现任意两个后缀的 \(r\) 一定小于等于它们的最长公共前缀,根据之前提到的 \(height\) 数组的性质,对于排序后的后缀,如果一段区间内的 \(height\) 最小值大于等于 \(r\),那么这个区间内的所有后缀必然是 \(r\) 相似的。反之,如果有 \(height[i] < r\),那么对于 \(\forall l,r\) 满足 \(1 \leq l <i,i<r \leq n\),\(l\) 和 \(r\) 不可能是 \(r\) 相似的。
这提示我们可以在排序后的后缀序列中满足 \(height[i]=r-1\) 切一刀,将原序列划分成若干个区间。每个区间内的任意两个后缀就必然是 \(r\) 相似的。接下来讨论如何记录区间内的美味度最大值。
1.两个后缀的美味度都为正数,那么必然就是最大值和次大值相乘得到的最大。
2.两个后缀的美味度都为负数,那么必然就是最小值和次小值相乘得到的最大。
3.两个后缀的美味度为一正一负,出现这种情况只可能是区间只有两个数时,那么也就是区间的最大值和次大值相乘。
综上,只需要维护区间内的最大值、次大值、最小值和最大值即可求出美味度的最大值。
由于区间分裂时的区间最值不好维护,可以想到按照 \(r\) 从大到小来枚举,这样就只会合并区间,就可以用到并查集维护所有的信息。
code:
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<vector>
using namespace std;
#define LL long long
const int N=3e5+10;
const LL INF=1e9+10;
const LL INFF=2e18;
int fa[N],siz[N],n,m,c[N],x[N],y[N],height[N],sa[N],rk[N];char s[N];
vector<int>hs[N];
LL ans[N][2],max1[N],max2[N],min1[N],min2[N],w[N];
LL get(LL x){return x*(x-1)/2ll;}
int find(int x){return fa[x]==x?x:fa[x]=find(fa[x]);}
void get_sa()
{
for(int i=1;i<=n;i++) c[x[i]=s[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i>=1;i--) sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1)
{
int num=0;
for(int i=n-k+1;i<=n;i++) y[++num]=i;
for(int i=1;i<=n;i++) if(sa[i]>k) y[++num]=sa[i]-k;
for(int i=1;i<=m;i++) c[i]=0;
for(int i=1;i<=n;i++) c[x[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i>=1;i--) sa[c[x[y[i]]]--]=y[i],y[i]=0;
swap(x,y);num=1,x[sa[1]]=1;
for(int i=2;i<=n;i++) x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k]?num:++num);
if(num==n) break;m=num;
}
}
void get_height()
{
for(int i=1;i<=n;i++) rk[sa[i]]=i;
for(int i=1,k=0;i<=n;i++)
{
if(rk[i]==1) continue;
if(k) k--;
int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) k++;
height[rk[i]]=k;
}
}
int main()
{
scanf("%d",&n);m=122;scanf("%s",s+1);
get_sa(),get_height();
for(int i=1;i<=n;i++) scanf("%lld",&w[i]);
for(int i=2;i<=n;i++) hs[height[i]].push_back(i);
LL res=-INFF,cnt=0;
for(int i=1;i<=n;i++)
{
fa[i]=i;siz[i]=1;
max1[i]=min1[i]=w[sa[i]];//记住,这里是排序后的后缀
max2[i]=-INF;min2[i]=INF;
}
for(int r=n-1;r>=0;r--)
{
for(int i=0;i<hs[r].size();i++)
{
int x=find(hs[r][i]),y=find(hs[r][i]-1);
cnt-=get(siz[x])+get(siz[y]);siz[x]+=siz[y];cnt+=get(siz[x]);
fa[y]=x;
if(max1[x]>=max1[y]) max2[x]=max(max2[x],max1[y]);
else max2[x]=max(max1[x],max2[y]),max1[x]=max1[y];
if(min1[x]<=min1[y]) min2[x]=min(min2[x],min1[y]);
else min2[x]=min(min1[x],min2[y]),min1[x]=min1[y];
res=max(res,max(max1[x]*max2[x],min1[x]*min2[x]));
}
ans[r][0]=cnt,ans[r][1]=(res==-INFF?0ll:res);
}
for(int i=0;i<n;i++) printf("%lld %lld\n",ans[i][0],ans[i][1]);
return 0;
}
【例题】生成魔咒
魔咒串由许多魔咒字符组成,魔咒字符可以用数字表示。
例如可以将魔咒字符 \(1\)、\(2\) 拼凑起来形成一个魔咒串 \([1,2]\)。
一个魔咒串 \(S\) 的非空字串被称为魔咒串 \(S\) 的生成魔咒。
例如 \(S=[1,2,1]\) 时,它的生成魔咒有 \([1]\)、\([2]\)、\([1,2]\)、\([2,1]\)、\([1,2,1]\) 五种。
\(S=[1,1,1]\) 时,它的生成魔咒有 \([1]\)、\([1,1]\)、\([1,1,1]\) 三种。
最初 \(S\) 为空串。
共进行 \(n\) 次操作,每次操作是在 \(S\) 的结尾加入一个魔咒字符。
每次操作后都需要求出,当前的魔咒串 \(S\) 共有多少种生成魔咒。
数据范围
\(1≤n≤10^5\),
用来表示魔咒字符的数字 \(x\) 满足 \(1≤x≤10^9\)。
思路
首先来考虑一个静态的问题,即长度为 \(n\) 的字符串中有多少个不同的子串。
注意到所有后缀的前缀集合就是的子串集合。考虑先将所有的后缀排序,此时相邻的两个后缀 \(i\) 和 \(i-1\) 中,相同的前缀数就是 \(height[i]\)。对于前两个后缀,正确性显然。对于后面的所有后缀,根据前面提到的夹逼定理,\(\forall j<i-1\),必然有 \(lcp(i,i-1)>lcp(i,j)\)。等价于 \(i\) 和前面所有后缀的最长公共前缀就是和前一个后缀的最长公共前缀。
记 \(len[i]\) 表示排序后第 \(i\) 个后缀的长度。那么总的不同子串数就是 \(\sum len[i]-height[i]\)。
由于每次往后添加数字会改变所有后缀,考虑转化一下题意,即每次向序列开头加入一个字符。那么每次更新只会增加一个后缀。和上一道题思路类似,再转化为每次从开头删去一个字符。那么就是要在后缀序列中删除一个后缀,那么就可以用链表来维护。根据 \(lcp(i,j)=\min(lcp(i,k),lcp(k,j)) (i \leq k \leq j)\)。\(height\) 数组是可以 \(O(1)\) 维护的。
最后,由于字符的范围比较大,在进行基数排序前记得离散化。
code:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e5+10;
#define LL long long
int num[N],a[N],x[N],y[N],c[N],height[N],sa[N],rk[N],n,m,lef[N],rig[N];
LL ans[N],res;
void get_sa()
{
for(int i=1;i<=n;i++) c[x[i]=a[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i>=1;i--) sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1)
{
int num=0;
for(int i=n-k+1;i<=n;i++) y[++num]=i;
for(int i=1;i<=n;i++) if(sa[i]>k) y[++num]=sa[i]-k;
for(int i=1;i<=m;i++) c[i]=0;
for(int i=1;i<=n;i++) c[x[i]]++;
for(int i=2;i<=m;i++) c[i]+=c[i-1];
for(int i=n;i>=1;i--) sa[c[x[y[i]]]--]=y[i],y[i]=0;
swap(x,y),num=1,x[sa[1]]=1;
for(int i=2;i<=n;i++) x[sa[i]]=(y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k])?num:++num;
if(num==n) break;m=num;
}
}
void get_height()
{
for(int i=1;i<=n;i++) rk[sa[i]]=i;
for(int i=1,k=0;i<=n;i++)
{
if(rk[i]==1) continue;
if(k) k--;
int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&a[i+k]==a[j+k]) k++;
height[rk[i]]=k;
}
}
int main()
{
scanf("%d",&n);for(int i=n;i>=1;i--) scanf("%d",&a[i]),num[i]=a[i];
sort(num+1,num+n+1);m=unique(num+1,num+n+1)-num-1;
for(int i=1;i<=n;i++) a[i]=lower_bound(num+1,num+m+1,a[i])-num;
get_sa();get_height();
for(int i=1;i<=n;i++)
{
res+=n-sa[i]+1-height[i];
lef[i]=i-1,rig[i]=i+1;
}
rig[0]=1,lef[n+1]=n;
for(int i=1;i<=n;i++)
{
ans[i]=res;int k=rk[i],j=rig[k];
res-=n-sa[j]+1-height[j];
res-=n-sa[k]+1-height[k];
height[j]=min(height[j],height[k]);
res+=n-sa[j]+1-height[j];
lef[rig[k]]=lef[k];
rig[lef[k]]=rig[k];
}
for(int i=n;i>=1;i--) printf("%lld\n",ans[i]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号