一.内外部命令和命令执行流程
type : 查看命令是外部命令还是内部命令
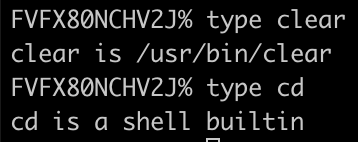
1. type clear : 是一个外部命令,属于用户自己安装的,需要找到这个可执行文件之后然后再让内核执行(找目录的过程是在PATH里面的路径中找执行文件,而不是从整个系统中寻找)
![]()
2. type cd : 是一个内部命令,代表是shell自带的,用户将命令发送给shell之后,直接让内核执行
命令执行流程
1.客户端发送命令给shell
2.切割字符串,第一个命令,其他是命令参数
3.判断是内外部命令
4.如果是外部命令,找到执行文件
5.让内核执行命令
二.查看命令帮助文档
man : 查看命令的帮助文档,防止自己不记得命令
回车:换行
空格:下一页

三.定义变量和进程简单管理
定义变量

echo : 打印数据,上面 a 为变量 arr为数组
进程简单管理

ps -ef : 查看当前所有的进程
top : 动态显示所有进程的情况
echo $$ : 打印shell程序运行的进程ID(shell接受命令,其实也是一个程序,所以需要一个进程运行起来,比如vim都会用到一个进程)
kill 9 PID : 杀死PID进程
显示视图
UID :程序被该 UID 所拥有
PID :就是这个程序的 ID
PPID :则是其上级父程序的ID
C :CPU使用的资源百分比
STIME :系统启动时间
TTY :登入者的终端机位置
TIME :使用掉的CPU时间。
CMD :所下达的是什么指令
四.外部命令查询的优化
过程:前面说过主要流程是先判断是外部还是内部命令,然后外部的话回去$PATH那里查找,linux在这个过程中做了一个优化
第一次查询:在path中查找,然后会存在hash中,后面查询会直接告诉可执行文件在哪
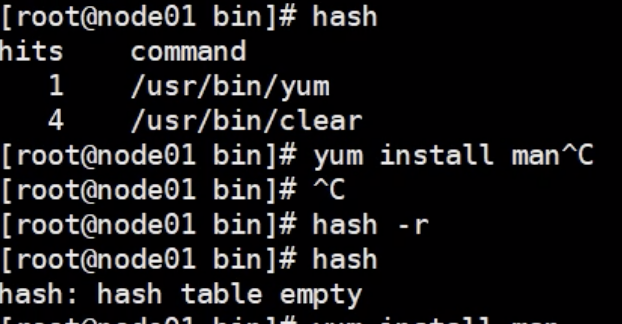
hash : 查看当前hash中存储了哪些执行路径
hash -r : 删除hash中的所有数据
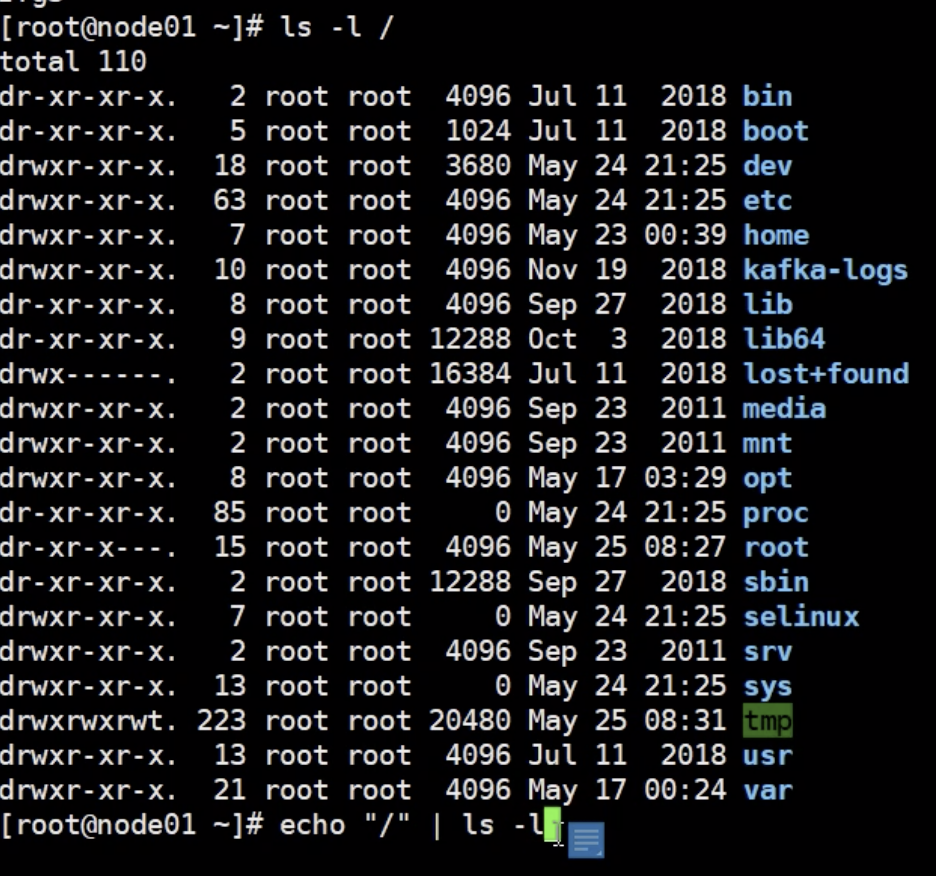
五.文件系统
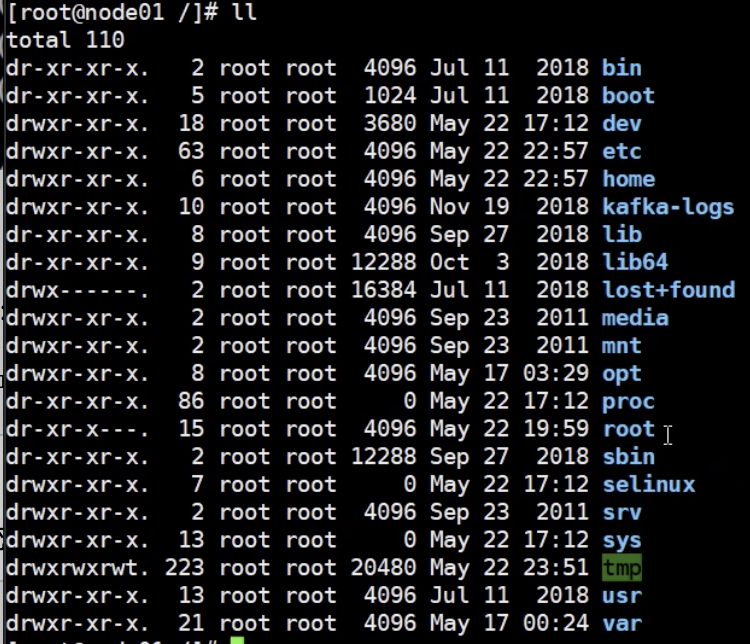
ls -ll : 查看文件夹下所有文件,并显示文件权限等相关信息
bin: 里面都是一些可执行文件,存储了一些用户命令

Linux 下面一块儿磁盘分了三个分区 sda1 tmpfs sda3分别代表
boot :内核程序
sda1 : boot目录下,存储的是linux内核的一些程序的分区
tmpfs : 用于内存与磁盘进行交互的分区
sda3 : 挂在了根目录下面,存储都是存储在这上面
dev :设备文件(比如鼠标键盘的信息文件)
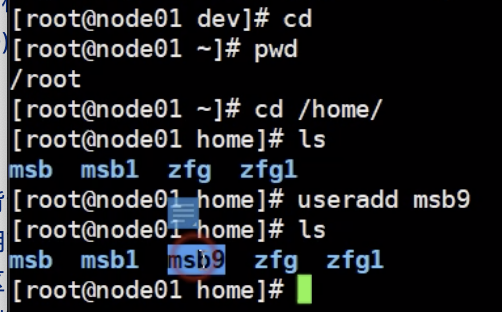
home : 普通用户的根目录
root : 管理员的根目录
lib : 库文件
opt : 可选程序,安装第三方程序的目录(比如mysql之类的)
mnt : 临时文件目录

数字都是代表一个进程,然后里面都是他自己包含的一些信息

这里显示是进入8951进程,里面就是这个进程包含的一些信息
proc: 伪文件系统,内核映射文件,里面包含当前运行的进程的信息文件,都是一个符号链接,所以大小为0

六.文件系统相关命令
![]()
文件类型-文件权限前的字符,比如下图中的d属于目录文件
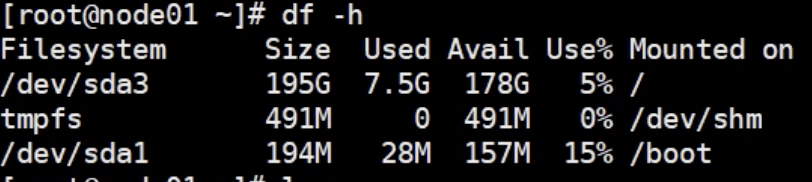
df -h : 显示磁盘分区,不同区的使用情况
![]()

du -h : 显示当前文件夹下的空间使用情况
![]()

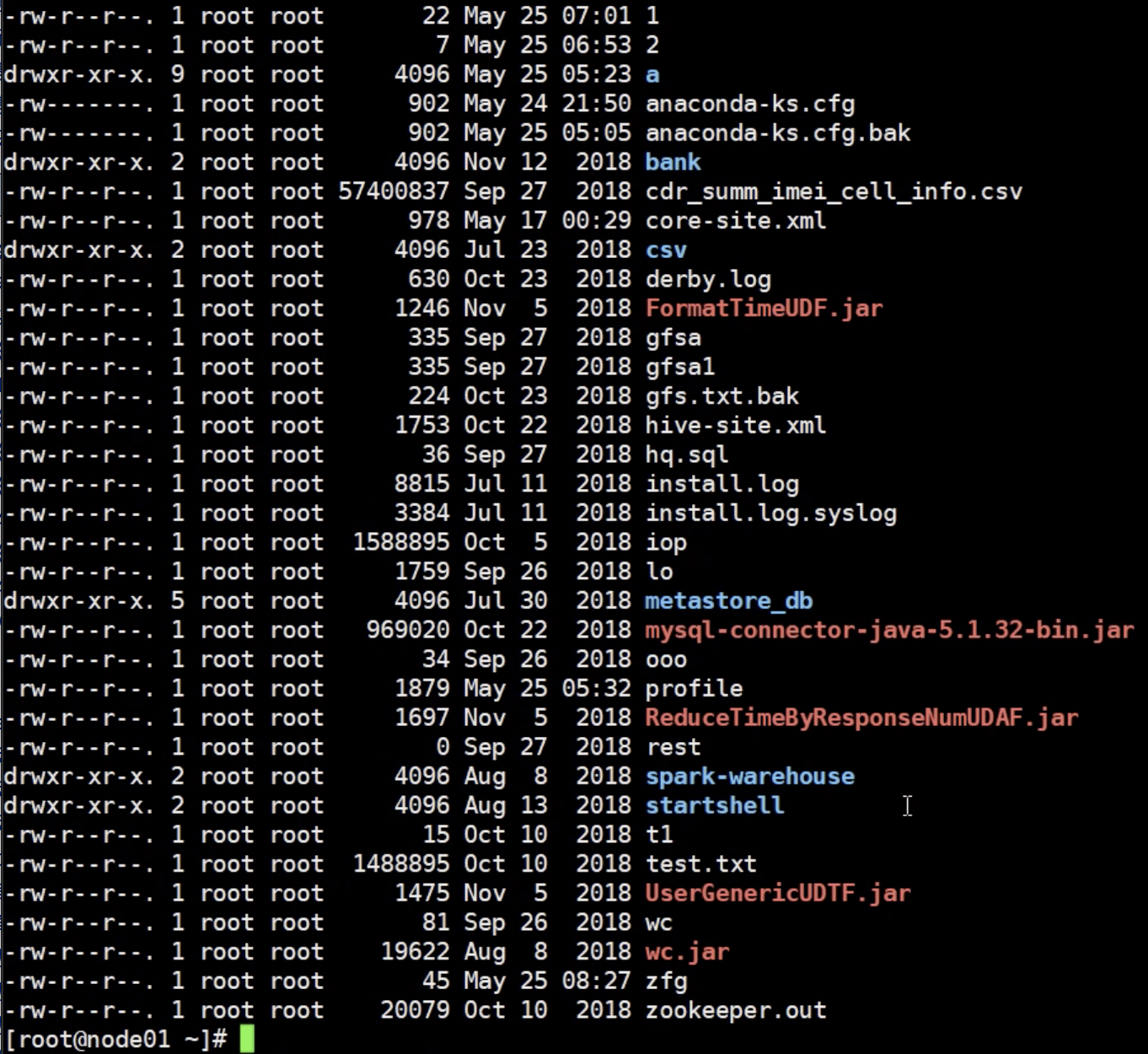
ls -l : 按文件顺序展示,会展示文件的权限相关
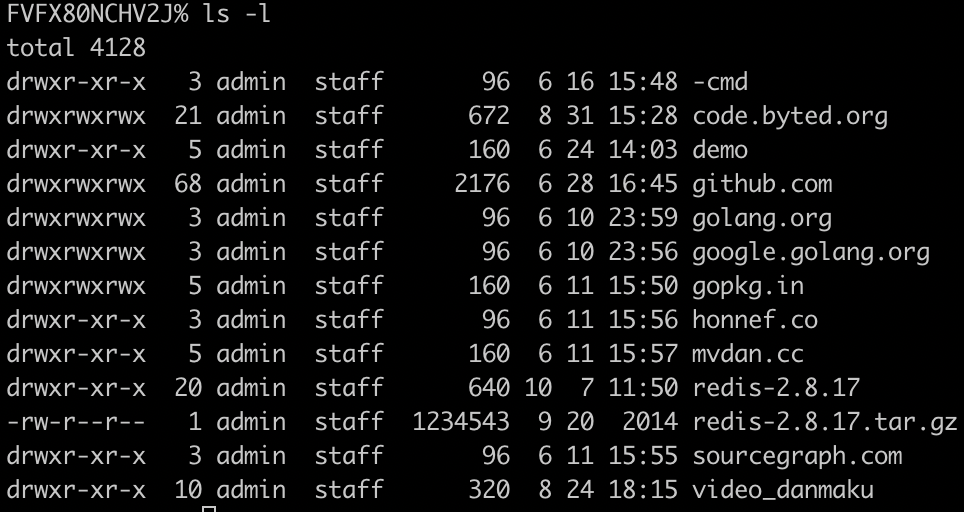
解析:
total 代表总共加起来多大
第一列
一个文件肯定是一个用户创建的,那么创建的用户就是属主
文件权限 d 之后9位字符, 3位一组,分成3组,分表代表 属主(创建该文件的用户)的权限, 同组的人的权限,其他人的权限
r:read 读
w:write 写
x:exe 执行
第二列
硬连接的数量
第三列
属主
第四列
属主所在的组,因为必须要判断其他用户是否是在这个组或者是这个属主来分配权限,所以需要存储
七.文件系统相关命令

mkdir :创建目录
mkdir -p : 如果中间有文件夹不存在,那么也一并创建了,比如上面 a/b/c,会同时创建a/b/c‘
mkdir a/{1,2,3}dir : 代表在a文件夹下面创建了 1dir, 2dir ,3dir三个文件夹,这是一种简写的一种方式
rm : 删除文件和目录

rm -f : 删除文件
rm -rf : 删除目录
in 链接
- Linux(主要目的节省内存)
- 硬连接和软连接
- 首先Linux操作数据就是通过innoB保存了一些文件属性和block 的地址,再通过地址找到block
- block就是数据块,主要用来存放数据,平常的操作就是 innoB->block
- 硬连接:类似C++智能指针,多个指针指向一个东西,有计数器,都指向一个innoB
- 软连接:类似C++双重指针,一个innoB->block1(取出block2的地址)-> block2
C 是真正的存储数据的数据块 A文件指向了C
硬链接:B硬连A文件会指向C,所以就算删除A文件,B也没有影响,采用的是计数器记录多少指向数据块
软链接:B软连A文件会指向A,所以删除A文件,B文件将会不能够使用 , ls -l下 权限前面文件属性是l的话代表是软连接
八. 文件系统相关
stat : 查看文件的详细信息
创建时间 (Access): 如果touch重新创建 这三个时间都会变成当前时间
内容修改时间 (Modify): 如果修改了文件内容的话,这个时间会变成当前时间
元数据修改时间(Change): 如果修改了文件权限类似的关于文件本身,这个时间会变成当前时间
![]()

touch :
作用1:如果文件不存在,会创建一个文件
作用2:如果文件存在,会刷新文件的三个时间
![]()
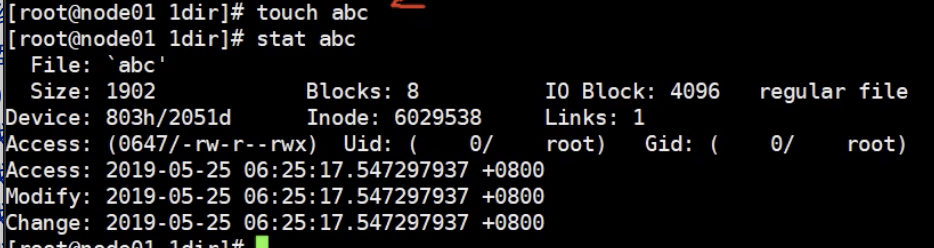
结合使用:在写脚本的时候,可以设置文件如果哪个修改时间修改了就触发个事件执行事情,然后每次用stat命令查看,
是的话就触发事件,然后使用touch重新刷新时间
九.文本相关操作的命令
cat : 显示文件中的所有内容,会直接打印在屏幕上,需要翻到最上面才能开始看
more : 分页来展示所有内容,还有百分比显示但是阅读了多少内容,但是只可以往后翻页 空格翻页,回车下一行
![]()

less : 分页展示,支持向前向后翻页 空格往后翻页,b向前翻页
head : 显示文件前面多少行,默认显示10行,可以加 -数字 来控制显示行数
tail : 显示文件后面多少行,默认显示最后10行,可以加 -数字 来控制显示行数
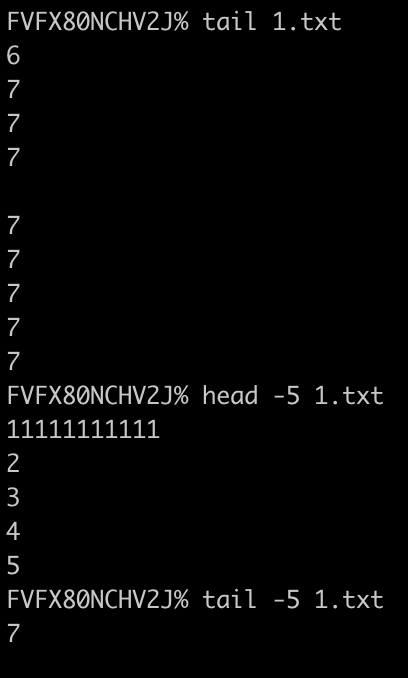
tail -f : 一直阻塞,监控文件是否追加内容,追加内容会被打印出来,但是如果修改文件,不会被显示
more 和 less 的区别
more 不可以往上回滚,不是加载到内存中的
less 可以支持,代表一直运行在内存中,所以如果文件大小超过内存,就不可以使用
十,文本相关命令(管道)
输出流 | 输入流 (会将左边输出流的数据给到输入流做筛选,格式中间加一个 | 隔开两边
![]()

解释:这个相当于将整个文件数据查出来,然后把数据全部发送给head -3,head -3 就会只取前面三行数据
解释:这种不可以是因为只是把数据发送给数据,但是这的原义是把 / 发送给 然后再ls -l,所以失败了
解决:可以加 xargs 代表把参数接到后面
用途:我如果要查第五行数据,那么可以 head -5 | tail -1
十一. vi编辑器的使用
编辑模式
![]()
![]()
dd : 删除一行数据
dw : 删除一个单词
yw : 复制一个单词
yy : 复制当前行
p : 粘贴在光标下面
P : 粘贴在光标上面
模式间的转换
![]()


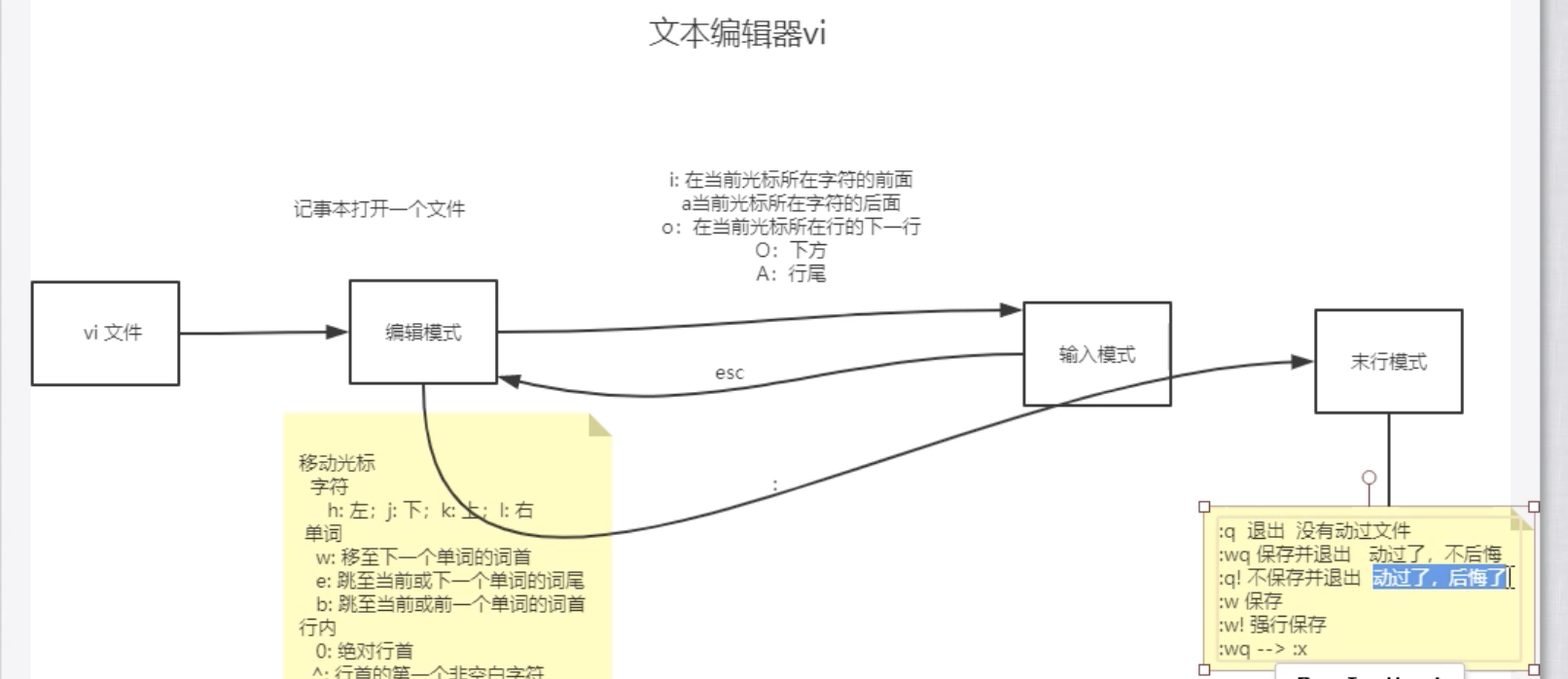
编辑模式:主要用做复制粘贴,删除等操作
输入模式:用来编写文件
末行模式: 用来保存文件之类的无关文本内容的事情
末行模式
![]()
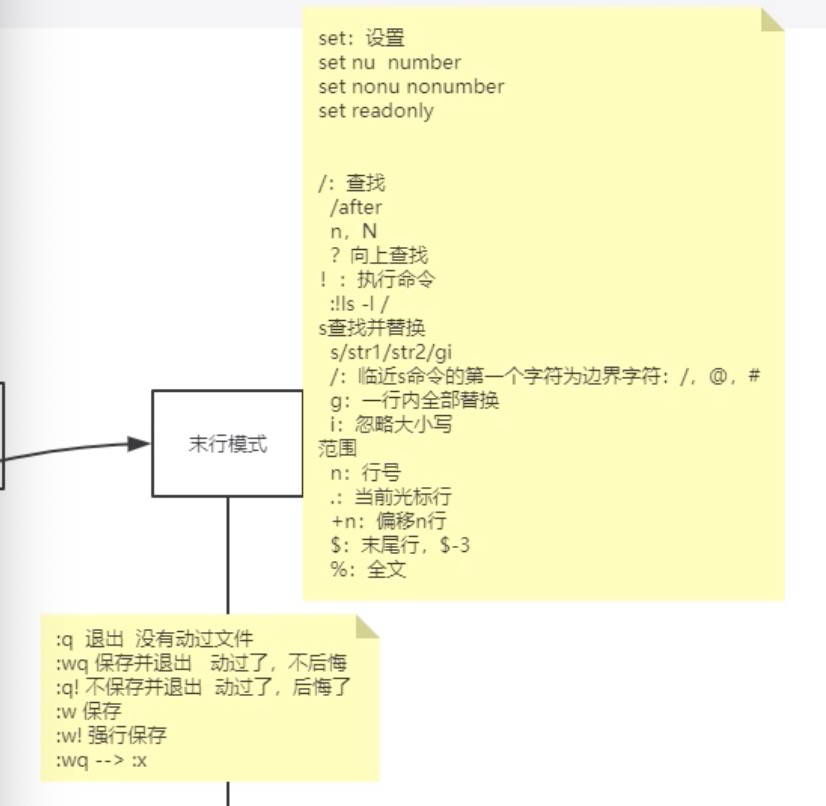
set nu|number : 给每一行加上行号

set nonu|nonumber: 取消行号
/after : 查找after在文本中的位置 n:找下一个 N:找上一个
?after : 查找after在文本中的位置 n:找上一个 N:找下一个
s/after/www : 将光标所指的行after 替换成www , 只替换一个
s/after/www/g : 将光标所指行after全部替换成www
s/after/www/gi : 大小写都会全部替换
控制范围
.,+n : 控制范围为 当前行 - 往下+n行
🌰:.,+3s/after/www/gi : 控制当前到下面3行,总共四行,全部替换包括大小写
% : 全文替换
0,n : 控制0-n行全部替换
范围删除:0,3d 删除前四行
范围复制:0,3y 复制前四行
十二.正则表达式

grep -n "^hello" 1.txt : 在1.txt文件中找到所有hello 开头的行,并且输出行号,
[0-9] : 代表数字都可以
[12] : 数字1,2 都可以
[^12] : 除了数字12
问题:包含三位数字的全部行搜出来
grep -E "([^0-9][0-9]|^[0-9])[0-9]([0-9][^0-9]|[0-9]$)" 1.txt
-E : 代表 ( ,),^ , | 等字符都直接可以使用,不需要加\进行转义
(|) : 代表|左右都是一种选择,然后上面两种选择分别是 前一个字符非数字+一个数字 后一个是前一个是数字并且位于行首 中间一个数字 最后一个匹配规则是
一个数字+非数字 一个数字位于行尾
问题:找出hello单词出行首的单词
grep "\<hello\>" 1.txt
<> : 用来隔开中间的字符
问题:找出出现2-3次l的行,比如ll ,lll
grep "l\{2,3\}" 1.txt
{n,m}: 代表出现n-m次
问题:找出 hi hello hi hello 结构的行
grep "hi.*hello.*hi.*hello.*" 1.txt
. : 匹配一个字符
* : 匹配多个字符

简约写法:后面1,2代表是前面括号括起来的
十三.其他文本处理命令
![]()
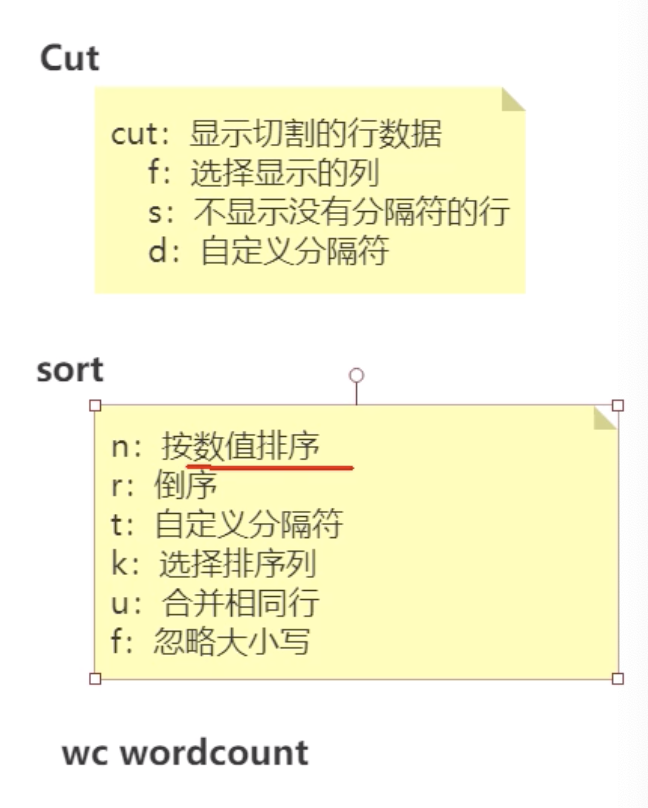
cut -d ' ' -f1,2,3 1.txt : 自定义分隔符为空格,然后显示1,2,3列
sort -t ' ' -k1 -u 1.txt : 按第一列排序,列之间以空格分隔
![]()
行数 单词数 字符数
十四. 行编辑器

原理:会将符合条件的加载入内存中,默认会输出内存空间里面的行,然后再输出满足条件的行 ,如果想不输出内存空间里面的行,就使用-n选项
显示出1-3行
sed -n “1,3p” 1.txt

使用version变量来动态控制修改后的数值
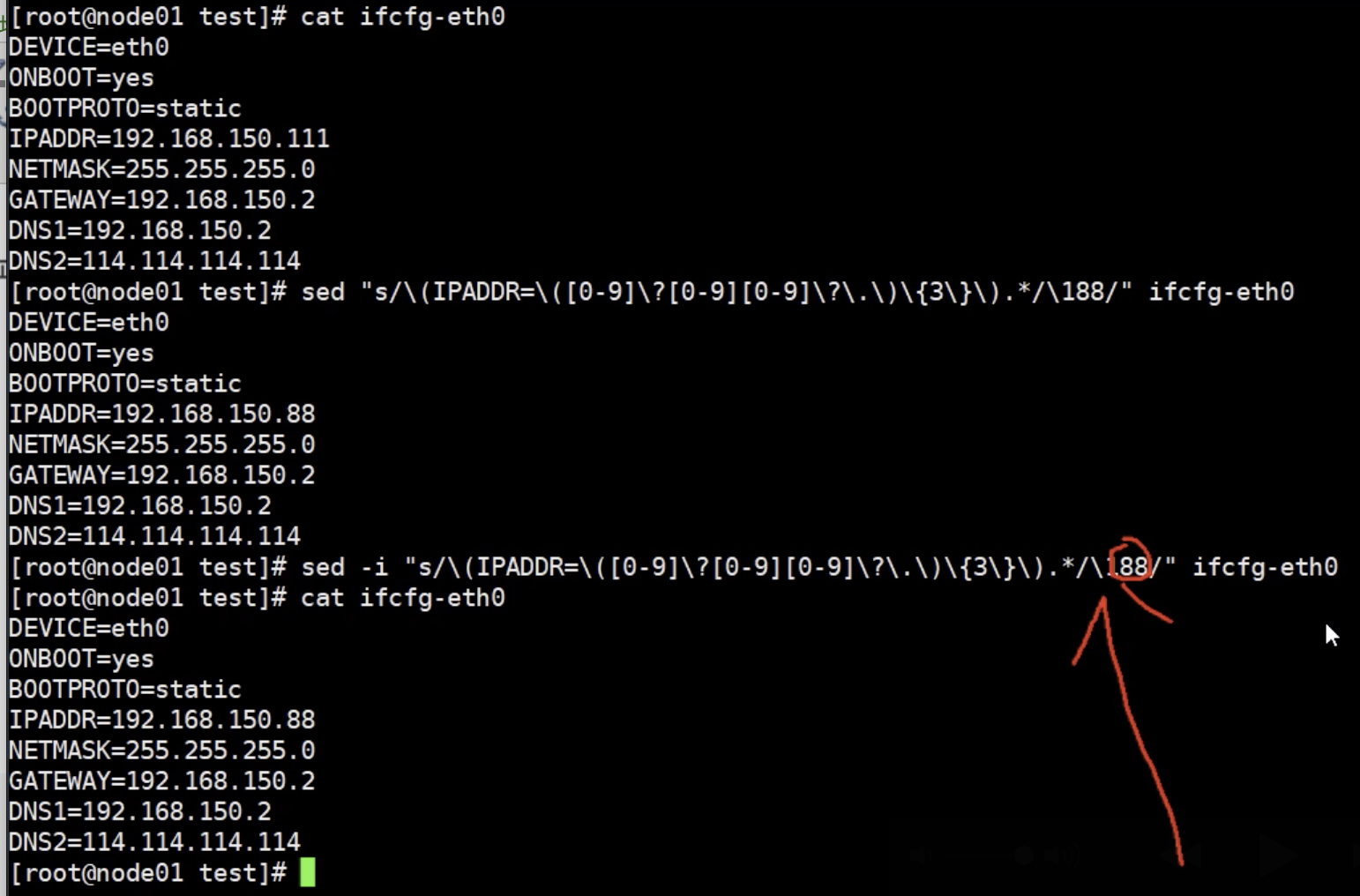
将正则表达式用于行编辑器
s//: 查找替换
() : 代表后面可以使用括号里面的内容
{n} : 代表里面出现前面n次
上面代表IPADDR 改成最后一个数字为88,过程是匹配一个数字 , 其中两位数字都用?代表可出现0-1次,这样考虑1,2,3位数的情况,然后再设置出现三次,最后一次 .* 代表至少匹配一个字符,匹配最后
一个数字的部分
十五.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号