
链表:
快慢指针:一个慢指针(一次走一步)一个快指针(一次走两步)
应用:判断链表是否有环,判断环的入口位置,求中位数,求倒数第k位等
判断链表是否有环:直接一快一慢去走,如果能碰到,那么说明有环,如果快指针走到NULL,那么无环
判断环入口位置:一快一慢走去,如果碰到了,那么将,慢指针放回入口,然后快慢指针同时步长为1,相遇的即为环入口
求中位数:快指针到重点,慢指针所在位置即为中位数,因为步长是他的两倍
树:
二叉排序树:也称为二叉查找树,遵从一个规则,左子树的所有节点的值都比当前节点值小,右子树所有的值都比当前节点的值大
然后直接每次插入一个节点直接去找就好了,但是这样建树会有最坏情况,有可能建出左斜树或者右斜树,复杂度和数组查找相似
难点:删除节点的时候,如果删除的该节点只有一个儿子,那么直接把这个儿子代替父亲的位置即可
如果两个儿子都有的话,这个时候就要好好考虑一下,因为要求删除后还是二叉排序树,那就选择右边子树中的最小的那个节点,这个既可以大于当前节点的所有,又小于右边所有
即一直递归右子树的左子树一直左左左找到最小的那个节点然后代替当前位置即可
平衡二叉树:基于二叉排序树的所有要求,因为二叉排序树有建树可能不完美的情况,所以,又有了平衡二叉树,前提就是必须书二叉排序树
平衡二叉树和二叉排序树的不同就是,平衡树多了平衡因子,当前节点的左右子树高度之差要小于等于1,所以平衡因子的值在【-1,1】之间
平衡二叉树构造的核心要点就是在于插入节点的时候如何把它给转换成平衡二叉树
参考博文:https://blog.csdn.net/isunbin/article/details/81707606
针对化成平衡二叉树的时候有四种情况
LL LR RR RL
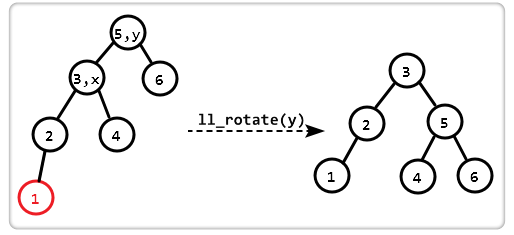
核心要点:三个点而造成的高度差时,只要把三点中间这个点拿出来当作根节点即可,然后移动节点的时候主要要满足二叉查找树的要求即可
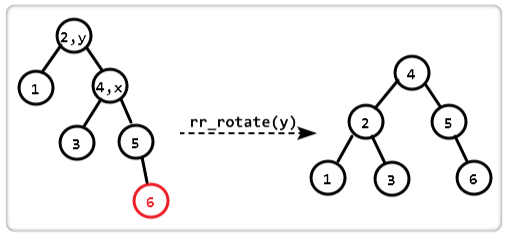
字母含义 LL 代表当前节点的平衡因子不在【-1,1】时候,刚刚插入的节点在左子树的左子树位置,其他类似
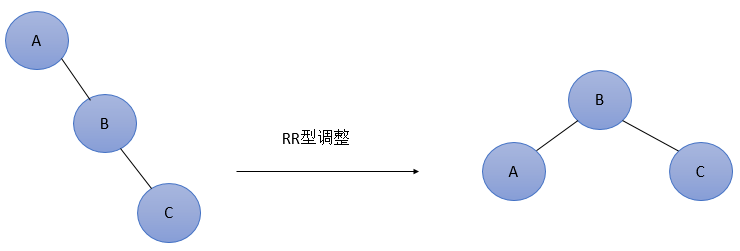
我们可以清晰看到LL RR移动的时候的作用,看图、
LR其实是一样的他要的达到的目的正好是 RR LL可以达到
插入删除都和二叉排序树是一样的,只是插入删除后要判断是四型中的哪一款,然后进行子树修正
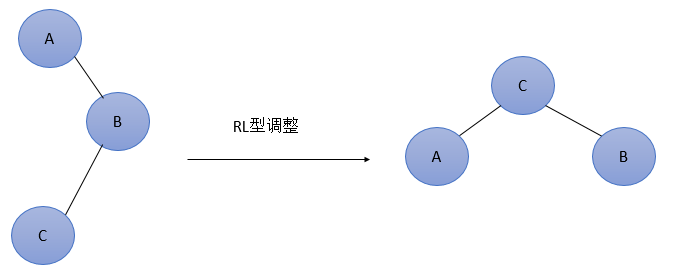
RL其实就是 一次 LL RR来达到的
(下面几张皆是盗的博文中的图,博主莫怪^_^)
LL型
简单形式
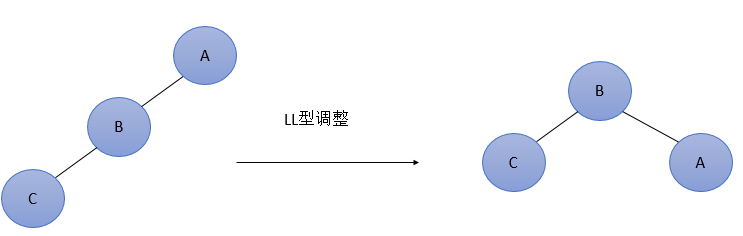
一般形式

具体形式
RR型
简单形式
一般形式
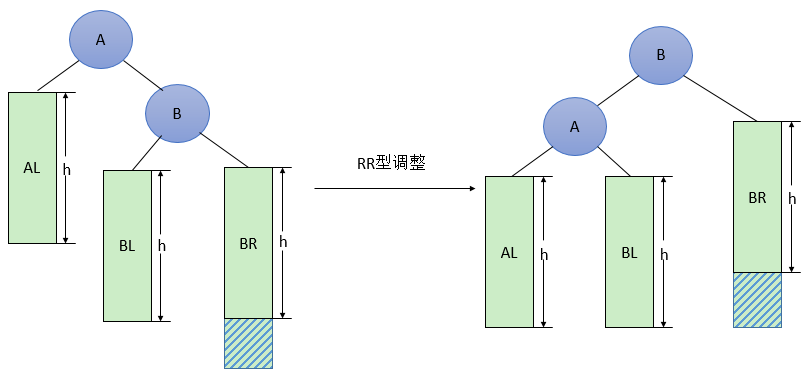
具体形式
LR型
简单形式

一般形式

具体形式

RL型
简单形式
一般形式

具体形式

堆
用数组模拟了二叉树,利用数组索引来模拟左右🌲,当前父节点i,那么左右子树索引分别是 i*2 和 i*2+1
堆的用途
1,优先队列 小根堆大根堆
2,堆排序
堆的两个核心操作 shift-up(上浮) 和 shift-down(下沉)
上浮:实现的是insert操作,我们插入一个数插在树的最后位置,然后利用上浮操作,比较和父亲节点的大小,然后交换,一个递归的操作
下沉:实现的是delete操作,我们大部分都是删除根节点,然后我们把最后一个数放到根节点,利用下沉操作,比较和自己两个儿子的大小,挑一个进行交换
删除的时候可能不是删除根节点,我们有些时候会删除中间的节点,这个时候依然是拿最后一个节点放过来但是这里面临一个选择,就是上浮和下沉都有可能,要进行一个判定再去使用,堆的核心操作就在于上浮和下沉其他都是些小应用
#include<bits/stdc++.h>//堆排序,降序 #define maxn 100005 using namespace std; int n; int a[maxn]; void shift_down(int x,int len){//下沉操作 if(x<=len){ int dex=-1; if(x*2<=len){ dex=x*2; } if(x*2+1<=len&&a[dex]>a[x*2+1]){ dex++; } if(dex!=-1&&a[x]>a[dex]){ swap(a[dex],a[x]); shift_down(dex,len); } } } void build_dui(){//初始化堆 for(int i=n/2;i>=1;i--){ shift_down(i,n); } } void dui_pai(){ build_dui(); for(int i=1;i<=n;i++){ printf("%d ",a[i]); } printf("\n"); for(int i=n;i>=2;i--){ swap(a[1],a[i]); shift_down(1,n-(n-i+1)); } } int main(){ scanf("%d",&n); for(int i=1;i<=n;i++){ scanf("%d",&a[i]); } dui_pai(); for(int i=1;i<=n;i++){ printf("%d ",a[i]); } }
堆的初始化
问题:如何利用给定的数组元素来建造一个堆
建造规则:从末尾第一个非叶子节点开始进行操作,使用上浮下沉操作来保证以当前节点为根节点的子树形成了堆,然后从后往前使用该规则,后面利用该规则会破坏原有孩子的一些平衡,要再次对孩子节点
进行操作

操作过程

二路归并排序
一个序列分成两段,两段都事先有序,然后合并
多路归并排序
参考博文:https://blog.csdn.net/whz_zb/article/details/7425152
作用:也叫k路归并,实质上就是分成k段,然后利用和二路归并相同的思想进行合并,一般用于外部排序,当内存不足以存储全部数据时
外部排序:所有的数据不一次性放入内存中进行排序,多路归并就是
内部排序:把全部数据一次性放入内存中进行排序,快速排序,二路归并...都是内部排序
用途:外部排序,内存不够的时候使用
利用堆优化,记录一个k个元素的数组,然后存入堆中,取的时候记录取的索引是哪一个,然后再放入数进去
利用败者树进行优化,前置知识 树形选择排序
树形选择排序:首先知道选择排序,选择排序即利用n-k次的比较找到最小的数字的下标,然后和最后一个进行交换,但是这个每次要进行n-k次交换,,所以时间是O(n^2)
但是树形选择排序复杂度在O(nlogn) 缺点:内存耗费太大
运行原理:

但是这个建立一个完全二叉树要建立两倍的数组空间,内存花费太大了,所以排序后面提出了堆排序
树形选择排序其实相当于就是胜者树
败者树进行了一些改变
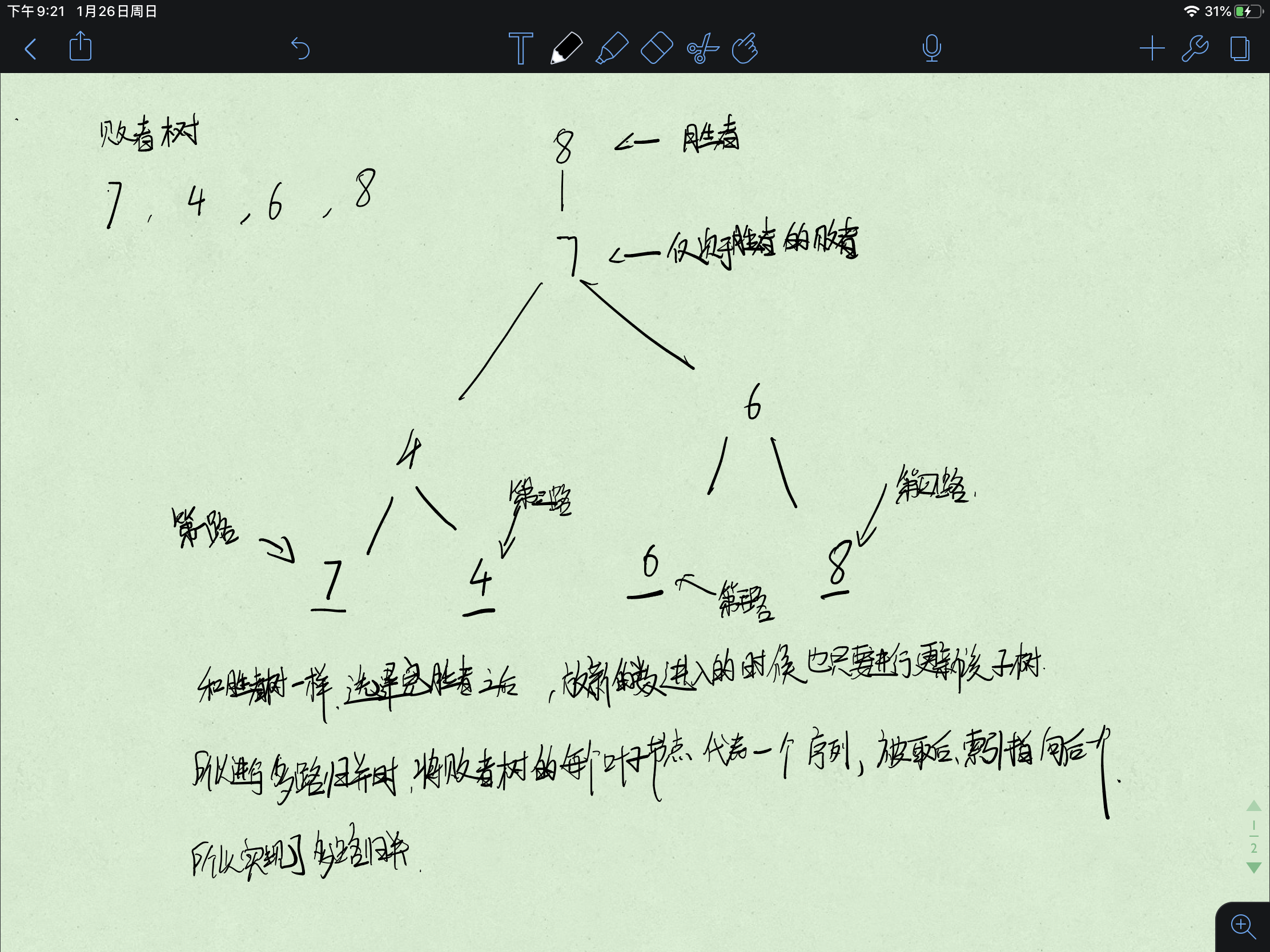
例:
字典树
emmmmmm,写过总结博客,就简单写一下吧
字典树也称为前缀树,键树,目的是利用字符串相同的前缀来节省内存来存储,然后也方便查询
后缀树
把字符串的所有后缀都插入字典树中,然后可以找出字符串任何子串 ,可以用来求公共子串等等
hash
作用:把字符串,数字 映射成整数,然后方便查询
存储方法有:链地址法 开放地址法(除数余数法 平方取余法) 再哈希法 建造冲突区法
用于MD4.MD5. SHA-1
一致性hash

普通集群:现在因为人群大,人流量大,大量的数据,就要采用分布式存储,然后把数据分散存储在多台服务器
一致性hash: 就是把数据和节点分别映射到hash空间内,然后每个数据顺时针去找找到第一个存储节点就代表该数据存在
这个节点
优点:方便删除和添加节点,因为删除添加节点后,只要把该节点上的数据重新找到存储节点即可
一致性哈希内的虚拟节点:如果映射到hash空间分布不均匀的话,这样负载均衡就没有起到作用,所以可以用一个节点分别映射多个虚拟节点
进行操作
海量数据处理
问题:一般对于大量数据的时候,数据量太大不能一次性存入内存,这个时候就要把大文件分割成多个小文件再进行操作
参考博文:https://blog.csdn.net/yangquanhui1991/article/details/52172768
1,分治-hash映射
主要分为三步
1,先hash映射把大文件分割成多个小文件
2,单独对每个小文件进行处理,用hashmap 处理
3,对每个小文件处理出自己需要的数据然后汇总
2,bitmap
c++的bitset就是用这个处理的
3.布隆过滤器
是 bitmap的进化版 ,bitmap作用就是标记数组,只是每一个标记内存只占1bit,但是这样标记受数据大小的限制,那个数组要开最大数据那么大
布隆过滤器也是用位来代表,不过因为内存优化,我们可以想到用hash来优化,但是很容易冲突,所以我们这个为了冲突率尽量低,用了K个hash
然后k个hash值位都置为1,如果全部都是1才代表存在
应用场景:这个不适合零容错地方,这个用于那些低容错低内存场景
4,倒排索引
就是反向操作取交集


 浙公网安备 33010602011771号
浙公网安备 33010602011771号