
类的扩展之 DataReader的扩展
看了关于DataReader的扩展,发现能节省很多代码。从数据库读取数据最原始方法就是while()然后做循环,如果数据库添加一个字段那么你所有读取数据库的方法全部添加。通过扩展这个类就摆脱了这种令人恶心的方式,关于效率我进行测试,当读取不多的时候效率相差不大,当读取几十万条而至数百万的时候可能效率就不如手写这种普通的方式,大家如果有兴趣可以自己去测试。好了,开始写
我先贴一张比较难看的图
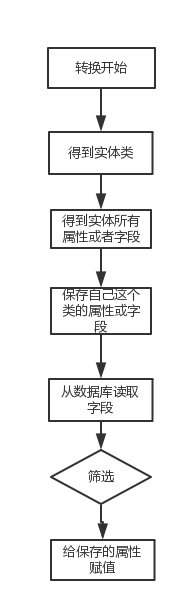
但是这就是转换的一个过程:我贴代码
1:
/// <summary> /// 将数据转换为实体集合 /// </summary> /// <typeparam name="T">类型</typeparam> /// <param name="dr">DbDataReader对象</param> /// <returns>实体集合</returns> /// <remarks></remarks> public static List<T> ToEntitys<T>(this IDataReader dr) where T : new() { if (dr == null) return null; var type = typeof(T);//获取实体类型 var hs = new Hashtable();//目的存所有实体的属性 var propts = type.GetProperties();//获取所有实体属性 foreach (var info in propts)//存入hash表中 { hs[info.Name.ToUpper()] = info; } var entitys = new List<T>(); while (dr.Read()) { var t = new T(); for (var index = 0; index < dr.FieldCount; index++) { var info = (PropertyInfo) hs[dr.GetName(index).ToUpper()];//从dr中读取字段,然后看hash表中是否存在此属性 if ((info == null) || !info.CanWrite) continue;//如果没有或者不可写则继续 var data = dr.GetValue(index);//获取属性值 var dType = data.GetType();//获取属性类型 if (dType == typeof (Guid)) info.SetValue(t, data == DBNull.Value ? null : data.ToString(), null);//把Guid转换成string else info.SetValue(t, data == DBNull.Value ? null : data, null); } entitys.Add(t); } dr.Close();//关闭流 return entitys; }
注释1:this就表示扩展这个类(我的理解)
注释2:SetValue() 这个就是填充值的。t是我们的实体类,data是属性值,通过这种方式把值赋给类对应的属性(映射)比喻一个实体类User的一个属性Name,然后dr读取数据库对象也存在Name这样一来就对应上了,然后在进行赋值。
2:进行测试
第一步:我插入数据库14万条数据
第二步:用普通方式读取10条
/// <summary> /// 常规读取数据库 /// </summary> [Test] public void CommonReadTest() { string StrSql = "select top 10 * from DataReaderDB"; SqlDataReader reader = DbHelperSQL.ExecuteReader("", CommandType.Text, StrSql, null); List<UserInfo> userInfos=new List<UserInfo>(); while (reader.Read()) { UserInfo user =new UserInfo(); user.Id = reader["Id"].ToString(); int age = 0; user.Age = int.TryParse(reader["Age"].ToString(), out age) ? age : 0; user.Name = reader["Name"].ToString(); user.Title = reader["Title"].ToString(); user.RealName = reader["RealName"].ToString(); user.DContent = reader["DContent"].ToString(); user.Systime = DateTime.Parse(reader["Systime"].ToString()); userInfos.Add(user); } Assert.AreEqual(10, userInfos.Count); }
运行速度(第一次由于加载导致慢。所以我选取的不是第一次,你可以多测几次)

第三步:扩展方式读取10条
/// <summary> /// 扩展流读取数据库 /// </summary> [Test] public void ExtensionReadTest() { string StrSql = "select top 10 * from DataReaderDB"; SqlDataReader reader = DbHelperSQL.ExecuteReader("", CommandType.Text, StrSql, null); List<UserInfo> userInfos = reader.ToEntitys<UserInfo>(); Assert.AreEqual(10, userInfos.Count); }

第四步:普通方式读取14万条(只贴效果图)

第五步:扩展方式读取14万条

总结:从中我们可以看出当数据量越来越大的时候扩展就相对来说慢些,当时数量不大两者相差不大,反而扩展更快,也许我测的不准,可以自己测试(注意第一次加载可能导致慢一定多测试几次),我个人觉得如果不是太考虑效率应该用扩展,因为便于项目的维护(最后注意数据库字段和实体类属性记得保持一致)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号