结对项目——自动生成小学四则运算题目程序
结对项目
| 软件工程 | <19级网络工程三四班> |
|---|---|
| 项目成员 | 3119005383 林泽涛 3119005367 陈益俊 |
| <作业要求> | 1.记录项目成员的姓名、学号和项目的Github项目地址。 2.用PSP表格预估将在程序的各个模块的开发上耗费的时间。 3.进行效能分析:记录下在改进程序性能上花费的时间,描述改进的思路,并展示一张性能分析的图。如果可能,展示程序中消耗最大的函数。 4.设计实现过程:阐述一下代码是如何组织的,比如会有几个类,几个函数,他们之间关系如何,并给出关键函数的流程图 5.代码说明:展示出项目关键代码,并解释思路与注释说明。 6.测试运行:对程序进行测试(至少10个测试用例),说明如何判断程序是正常运行的。 7.实现完程序之后,用PSP表格记录在程序的各个模块上实际花费的时间。 8.项目小结:总结成败得失,分享经验,总结教训。 |
| 作业目标 | 实现一个自动生成小学四则运算题目的程序,可以控制生成题目的个数和题目中数值的范围。 |
1.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 60 | 30 |
| · Design Review | · 设计复审 | 60 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 180 | 240 |
| · Coding | · 具体编码 | 600 | 720 |
| · Code Review | · 代码复审 | 180 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| · 合计 | 1530 | 1620 |
2. 程序设计实现过程
2.1 项目结构
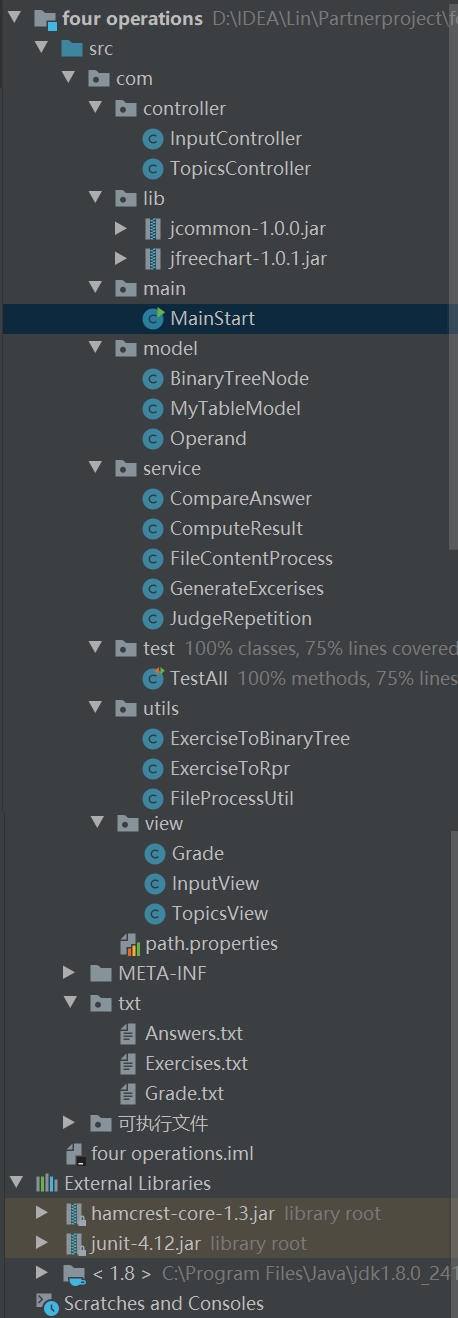
2.2 主要实现类
2.2.1 main包
MainStart类:程序入口类,其中仅创建了controller包下的InputController类,该类继承InputView类,从而达到初始化输入窗口的目标。
2.2.2 view包
InputView类:输入窗口类,其中包括输入窗口的初始化及相关组件的控制方法
TopicsView类:题目窗口类,其中包括输入窗口的初始化及相关组件的控制方法
2.2.3 controller包
InputController类:输入窗口控制类,其中包括对输入窗口部分组件的监听与响应以及生成提示信息的方法
TopicsController类:题目窗口控制类,其中包括对题目窗口部分组件的监听与响应以及生成提示信息的方法
2.2.4 model包
MyTableModel类:表格模型,由于JTable类创建的表格的默认设置无法满足本项目需求,因此新建了该表格模型,继承AbstractTableModel类,重写表格的部分功能方法,从而达到本项目的需求。
Operand类:操作数模型,在本项目中,涉及到操作数的生成与表示,为简化该项目,我们统一将数存储为分数(分子/分母),即整数为分母为1。在该操作数模型中,包括分数约分处理(辗转相除法),分数与字符串表示的相互转换,数与数之间四则运算的方法(add、sub、mul、div)。
BinaryTreeNode类:二叉树模型,由于该项目中存在对生成题目判重处理的需求,所以我们利用二叉树的同构原理的两表达式进行判重处理,即若同构,则重复。
2.2.5 util包
FileProcessUtil类:文件输入输出字符流获取类,通过该工具类可获取输入输出文件的字符流,从而进行文件的读和写,本身我们项目在service包中已经实现了文件的读写类,但我们在生成过程中需要对同一个文件重复的写,service包中的类无法实现该需求,所以我们又重新写了该工具类,满足该项目需求。该类中还包括的资源配置文件中资源的获取方法。
ExerciseToRpr类:表达式转换类,该类中方法实现了中缀表达式转换为后缀表达式,便于对表达式进行求值。
ExerciseToBinaryTree类:表达式转换类,该类中方法先将中缀表达式使用ExerciseToRpr类中的方法转换为后缀表达式,再将后缀表达式转换为二叉树形式,便于对表达式进行判重。
2.2.6 lib包
jcommon-1.0.0.jar和jfreechart-1.0.1.jar是我们引进的外部依赖,实现答案比较进行的饼状图显示。
2.2.7 service包
FileContentProcess类:文件读写类,该类中方法实现了对文件的读和写。
GenerateExerises类:生成题目类,该类是本次项目中最为重要的,也是最为复杂,最中心的一个类,该类中方法实现了题目的生成,其中涉及到操作数个数、数值,操作符个数、位置,括号个数、位置的随机生成,由于该项目括号随机生成过于复杂,且该项目要求操作符不超过3个,枚举出来并不困难,但该方法不是最好的方法,后续有更好的方法可实现我们会加以改进。
CompareResult类:计算答案类,该类中方法对已转换为后缀表达式的题目使用辅助栈进行计算,其原理下文会进行叙述。
JudgeRepetition类:题目判重类,该类中方法将已转换为二叉树形式的题目,利用二叉树同构原理,对两题目进行判重处理,即同构即重复,重复则丢弃该新生成的题目。
CompareAnswer类:比较答案类,该类中方法对用户自填的答案与计算机自动生成的答案进行比较统计,将统计结果写入文件中,并通过饼状图展示宏观的答题情况。
2.2.8 text包
TestAll类:单元测试类,其中有对生成题目功能、题目答案比较功能进行单元测试的方法,均带有@Test注解
2.2.9 资源配置文件
path.properties:该资源配置文件中包括Exercises.txt,Answers.txt,Grade.txt的决定路径,该决定路径中不能含有中文,这样就可以达到不修改代码的情况下修改项目的相关配置。
2.3 项目流程(类与类之间的关系)
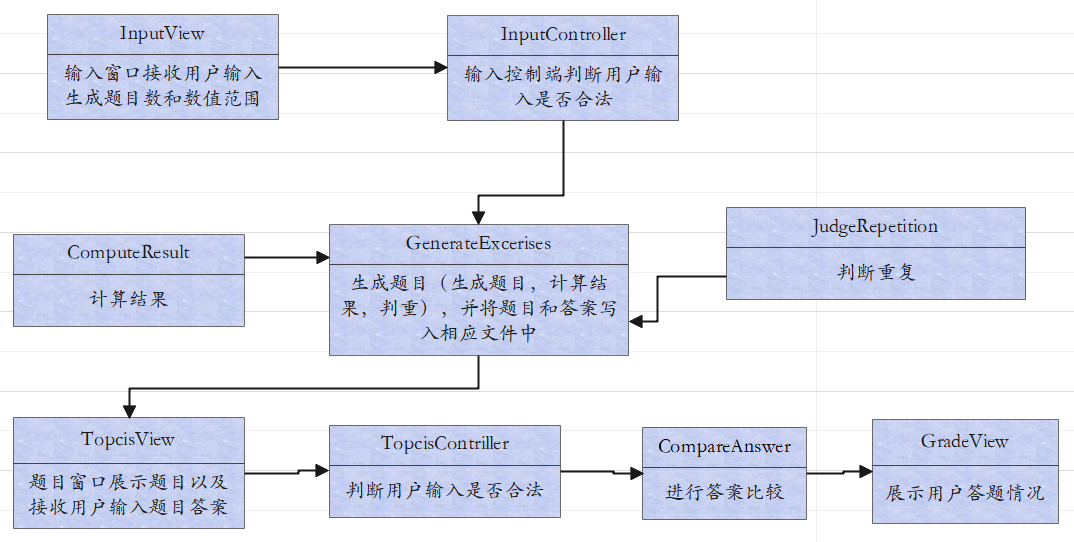
2.4 关键方法的分析与实现
2.4.1 生成题目方法
package com.service;
import com.model.BinaryTreeNode;
import com.model.Operand;
import com.utils.ExerciseToBinaryTree;
import com.utils.FileProcessUtil;
import java.io.FileWriter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
/**
* 随机生成题目的类
*/
public class GenerateExcerises {
// 存储生成的题目及其答案的Map,其中key是题目,value是答案
// 便于进行查重
private static HashMap<String,String> map = new HashMap<>();
// 四则运算符
private static final String[] operators = {" + "," - "," * "," ÷ "};
// 括号
private static final String[] bracket = {"( "," )"};
/**
* 生成题目,计算答案,判断是否符合条件,最后写入到指定文件中
* @param number 题目数量
* @param range 数值范围
* @throws Exception
*/
public static void generateExercises(int number,int range) throws Exception {
// 从配置文件中获取存储题目和答案的文件绝对路径,再获取题目和答案字符输入流
FileWriter exercises = FileProcessUtil.write(FileProcessUtil.resourceBundle("com/path","Exercises.txt"));
FileWriter answers = FileProcessUtil.write(FileProcessUtil.resourceBundle("com/path","Answers.txt"));
// 循环生成题目
for (int i = 0;i < number;i++) {
repeat:
while(true){
// 生成一道题目
String exercise = generateExercise(range);
// 计算题目结果
String answer = ComputeResult.compute(exercise);
// 不符合要求的结果,重新生成题目
if(answer.equals("unqualified")){
continue;
}
// 判断题目是否重复
// 先判断已生成的题目中是否存在与新生成题目答案相同的,存在则再进行查重
if (map.containsValue(answer)){
// 将Map中与当前生成题目答案相同的题目提取出来存到一个List集合
ArrayList<String> arrayList = getKey(map,answer);
// 将新生成题目转化为二叉树形式
BinaryTreeNode treeNode = ExerciseToBinaryTree.exerciseToBinaryTree(exercise);
// 利用二叉树的同构判断题目是否重复
for (String eachExercise : arrayList) {
if (JudgeRepetition.judge(treeNode,ExerciseToBinaryTree.exerciseToBinaryTree(eachExercise))){
// 若两棵二叉树同构,即两题重复,重新生成题目
continue repeat;
}
}
}
// 生成题目不重复,则添加到Map集合中
map.put(exercise,answer);
// 向Exercises.txt文件中写入题目
exercises.write(i + 1 + "、" + exercise + " =\n");
// 向Answers.txt文件中写入该题答案
answers.write(i + 1 + "、" + answer + "\n");
break;
}
}
// 关闭资源
exercises.close();
answers.close();
}
/**
* 生成一道四则运算题目
* @param range 数值范围
* @return 一道四则运算题目
*/
public static String generateExercise(int range){
// exercise存储题目真分数形式
// 后续计算再统一将操作数字符转为操作数对象,计算方便
String exercise = null;
// 随机生成四则运算符个数(1~3)
int operatorNumber = (int)Math.floor((Math.random()*3)+1);
// 随机生成一道题目的运算符数组
String[] opera = generateOperators(operatorNumber);
// 随机生成一道题目的操作数数组
Operand[] oper = generateOperands(operatorNumber+1,range);
// 随机生成题目是否包含括号:1 —— 有,0 —— 无(50%的概率)
int isContainBracket = (int)Math.round(Math.random());
// 若运算符为1个
if(operatorNumber == 1){
exercise = oper[0].toString()+opera[0]+oper[1].toString();
}else{
// 若题目包含括号
if(isContainBracket == 1){
// 若运算符为3个
if (operatorNumber == 3){
// 随机生成一种表达式
int num = (int)Math.floor(Math.random()*10);
switch(num){
case 0:
exercise = bracket[0]+oper[0].toString()+opera[0]+oper[1].toString()+bracket[1]+opera[1]+oper[2].toString()+opera[2]+oper[3].toString();
break;
case 1:
exercise = oper[0].toString()+opera[0]+bracket[0]+oper[1].toString()+opera[1]+oper[2].toString()+bracket[1]+opera[2]+oper[3].toString();
break;
case 2:
exercise = oper[0].toString()+opera[0]+oper[1].toString()+opera[1]+bracket[0]+oper[2].toString()+opera[2]+oper[3].toString()+bracket[1];
break;
case 3:
exercise = bracket[0]+oper[0].toString()+opera[0]+oper[1].toString()+opera[1]+oper[2].toString()+bracket[1]+opera[2]+oper[3].toString();
break;
case 4:
exercise = oper[0].toString()+opera[0]+bracket[0]+oper[1].toString()+opera[1]+oper[2].toString()+opera[2]+oper[3].toString()+bracket[1];
break;
case 5:
exercise = bracket[0]+bracket[0]+oper[0].toString()+opera[0]+oper[1].toString()+bracket[1]+opera[1]+oper[2].toString()+bracket[1]+opera[2]+oper[3].toString();
break;
case 6:
exercise = bracket[0]+oper[0].toString()+opera[0]+bracket[0]+oper[1].toString()+opera[1]+oper[2].toString()+bracket[1]+bracket[1]+opera[2]+oper[3].toString();
break;
case 7:
exercise = oper[0].toString()+opera[0]+bracket[0]+bracket[0]+oper[1].toString()+opera[1]+oper[2].toString()+bracket[1]+opera[2]+oper[3].toString()+bracket[1];
break;
case 8:
exercise = oper[0].toString()+opera[0]+bracket[0]+oper[1].toString()+opera[1]+bracket[0]+oper[2].toString()+opera[2]+oper[3].toString()+bracket[1]+bracket[1];
break;
case 9:
exercise = bracket[0]+oper[0].toString()+opera[0]+oper[1].toString()+bracket[1]+opera[1]+bracket[0]+oper[2].toString()+opera[2]+oper[3].toString()+bracket[1];
break;
}
}else {
// 若运算符为2个
// 随机生成一种表达式
int num = (int)Math.floor(Math.random()*2);
switch(num){
case 0:
exercise = bracket[0]+oper[0].toString()+opera[0]+oper[1].toString()+bracket[1]+opera[1]+oper[2].toString();
break;
case 1:
exercise = oper[0].toString()+opera[0]+bracket[0]+oper[1].toString()+opera[1]+oper[2].toString()+bracket[1];
break;
}
}
}else{
// 题目不包含括号
if(operatorNumber == 3){
// 若运算符为3个
exercise = oper[0].toString()+opera[0]+oper[1].toString()+opera[1]+oper[2].toString()+opera[2]+oper[3].toString();
}else{
// 若运算符为2个
exercise = oper[0].toString()+opera[0]+oper[1].toString()+opera[1]+oper[2].toString();
}
}
}
return exercise;
}
/**
* 随机生成一道题目的运算符数组
* @param number 运算符数量
* @return 运算符数组
*/
public static String[] generateOperators(int number){
// 运算符数组
String[] oper = new String[number];
for(int i = 0; i < number; i++){
// 随机生成一个下标指定运算符
oper[i] = operators[(int)(Math.random()*4)];
}
return oper;
}
/**
* 随机生成一道题目的操作数数组
* @param num 操作数数量
* @param scope 操作数数值范围
* @return 操作数数组
*/
public static Operand[] generateOperands(int num,int scope){
// 操作数数组
Operand[] operands = new Operand[num];
for (int i = 0; i < num; i++) {
// 随机生成一个操作数对象
operands[i] = generateOperand(scope);
}
return operands;
}
/**
* 随机生成一个操作数对象
* 操作数统一用分数存储,整数的分母为1
* @param scope 操作数范围
* @return 操作数对象
*/
public static Operand generateOperand(int scope){
// 分子
int molecule = (int)(Math.random()*scope);
// 分子不为0
if(molecule == 0){
molecule = 1;
}
// 分母
int denominator;
// 一半几率产生整数
if(Math.random() < 0.5){
denominator = 1;
}else{
denominator = (int)(Math.random()*scope);
// 分母不为0和1,分子分母相同时,重置分母
if(denominator <= 1 || denominator == molecule){
denominator = scope-1;
}
}
return new Operand(molecule,denominator);
}
/**
* 根据Map中的value获取key集
* @param map
* @param value
* @return 指定value的key集
*/
public static ArrayList<String> getKey(Map<String,String> map, String value){
ArrayList<String> list = new ArrayList<>();
for(String key : map.keySet()){
if(map.get(key).equals(value)){
list.add(key);
}
}
return list;
}
}
生成题目涉及到运算符,操作数,括号的生成。
1、运算符生成
我们设置一个字符串数组存储+、-、*、÷四种运算符,先随机生成运算符个数,再根据运算符个数进行运算符下标的随机生成,下标对应到字符串数组中,即达到随机生成运算符的目的。
2、操作数生成
在本项目中,为简化该项目,我们统一使用一个操作数模型Operand进行操作数的存储和表示以及操作数间的四则运算,该操作数模型将所有数值都使用分数(分子/分母)进行存储,但数值为整数时,分数的分母为1。
在操作数生成时,我们先随机生成数值范围内的分子,若生成分子为0,则置为1,再生成一0到1之间的随机数,当该随机数小于0.5时,生成分母为1,反之随机生成数值范围内的分子,若生成分母为0或1,则置为数值范围减1,最后将生成的分子分母传入操作数模型中创建操作数对象,创建过程中会对分子分母进行约分(辗转相除法)。
以上操作可以保证生产过程中不会出现数值为0或分母为0的情况,但在后续计算过程中还是有可能会出现分母为0、除数为0、负数(项目需求为题目计算过程中不出现负数)的情况,我们为了完全消除这些情况,在操作数模型做了如下限制:
(1)在构造方法中,当分子为0时,将分母置为1;
(2)在sub方法(操作数相减方法)中,当两操作数相减产生负数时,返回null,提示调用方丢弃表达式;
(3)在div方法(操作数相除方法)中,当除数的分子为0(除数为0)时,返回null,提示调用方丢弃表达式。
以上三个限制即可保证在整个项目运行过程中不会出现分母为0,除数为0,负数的情况,大大简化了项目。
3、括号生成
括号生成涉及到有无括号、括号个数、括号位置的确定。由于括号生成过于复杂,我们两人未发现有较好的方法,且该项目要求操作符不多于3个,所以表达式的枚举并不复杂。因此,我们通过前面已确定的运算符和操作数对表达式进行枚举,一个运算符、2个运算符无括号和3个运算符无括号都仅有一种情况,2个运算符有括号的有2种情况,3个运算符有括号的有10种情况,总共15种情况。
而且在该项目中,我们对表达式中假分数的表示统一使用"整数'分子/分母“,这是写入题目文件所要求的格式,但后续计算的过程中带分数仍需用假分数表示进行运算,这时操作数模型的作用就体现出来了,如果我们不把操作数使用分子分母分开存储,这时对于操作数的四则运算就会极为困难,对于我们使用的操作数模型,我们仅需在计算结果时,将两个操作数字符串传入操作数模型中,使用stringToOperand方法将操作数字符串转换为操作数对象。再使用操作数模型中的简单四则运算方法进行运算即可,最后使用操作数模型中的toString方法将操作数对象转换为操作数字符串。
在该方法中还涉及到题目结果的计算,题目是否重复的判断,所以该方法为整个项目的中枢。
2.4.2 计算结果
2.4.2.1 逆波兰法
package com.utils;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
/**
* 表达式类型转换类
*/
public class ExerciseToRpr {
/**
* 将中缀表达式转换为后缀表达式
* @param exercise 中缀表达式
* @return 后缀表达式
*/
public static String exerciseToRpr(String exercise){
// 调用tranToRpr()方法将中缀表达式转换为后缀表达式队列
Queue<String> rprQueue = tranToRpr(exercise);
// 存储后缀表达式
StringBuffer rpr = new StringBuffer();
for(String str : rprQueue){
rpr.append(str + " ");
}
return rpr.toString();
}
/**
* 使用逆波兰法将中缀表达式转换为后缀表达式队列
* @param exercise 中缀表达式
* @return 后缀表达式链表
*/
public static Queue<String> tranToRpr(String exercise){
// 将中缀表达式按空格分割成操作单元数组
String[] opers = exercise.split(" ");
// 存储中缀表达式转换得到的后缀表达式队列
Queue<String> rprQueue = new LinkedList<>();
// 存储运算符的辅助栈
Stack<String> operatorsStack = new Stack<>();
// 将分割产生的操作单元数组转化为后缀表达式队列
for(String oper : opers){
// 若为数,则进入后缀表达式队列
if(!isOperator(oper)){
rprQueue.offer(oper);
}else{
if("(".equals(oper)){
// 若为"(",入栈
operatorsStack.push(oper);
}else if(")".equals(oper)){
// 若为")",将栈中上一个"("之间的操作符弹出并进入后缀表达式队列
while(!operatorsStack.isEmpty()){
if(operatorsStack.peek().equals("(")){
// 找到"(",与")"抵消,弹出
operatorsStack.pop();
break;
}else{
// 将栈中上一个"("之间的操作符弹出并进入后缀表达式队列
rprQueue.offer(operatorsStack.pop());
}
}
}else{
// 处理除括号外的操作符(+ - * ÷)
while(!operatorsStack.isEmpty()){
if("(".equals(operatorsStack.peek())){
// 若栈顶是"(",入栈
operatorsStack.push(oper);
break;
}else if(isPrior(operatorsStack.peek(),oper)){
// 若栈顶运算符优先级大于或等于oper,将栈顶运算符弹出进入后缀表达式队列
// 优先级相同,则从左往右算
rprQueue.offer(operatorsStack.pop());
}else if(isPrior(oper,operatorsStack.peek())){
// 若栈顶运算符优先级小于oper,运算符入栈
operatorsStack.push(oper);
break;
}
}
// 当栈空时入栈
if(operatorsStack.isEmpty()){
operatorsStack.push(oper);
}
}
}
}
// 栈中剩余运算符弹出进入后缀表达式队列
while(!operatorsStack.isEmpty()){
rprQueue.offer(operatorsStack.pop());
}
// 返回后缀表达式链表
return rprQueue;
}
/**
* 是否为运算符
* @param o
* @return 判断结果
*/
public static boolean isOperator(String o) {
if("(".equals(o) || ")".equals(o) || "+".equals(o) || "-".equals(o) || "*".equals(o) || "÷".equals(o)){
return true;
}else{
return false;
}
}
/**
* 运算符优先级判断
* @param oper1 运算符1
* @param oper2 运算符2
* @return 当 运算符1优先级 >= 运算符2优先级 时,返回true,否则返回false
*/
public static boolean isPrior(String oper1, String oper2) {
if(ofPriority(oper1) >= ofPriority(oper2)){
return true;
}else{
return false;
}
}
/**
* 获取运算符优先级
* @param oper
* @return 运算符优先级
*/
public static int ofPriority(String oper) {
if("+".equals(oper) || "-".equals(oper)){
return 1;
}else if ("*".equals(oper) || "÷".equals(oper)){
return 2;
}else{
throw new IllegalArgumentException("表达式中存在未知(非法)运算符!");
}
}
}
使用逆波兰法先将中缀表达式转换为后缀表达式,再使用辅助栈对后缀表达式进行计算
我们使用栈实现逆波兰法,该方法原理如下:
假设我们需要转化的中缀表达式为:a + b * c + (d * e + f) * g
我们借助一辅助栈stack存储运算符,和一队列queue存储操作数
1、从左到右扫描每一个字符,如果扫描到的字符为操作数(如a、b等),就将该操作数放入队列中
2、如果扫描到的字符是一个操作符,分三种情况:
(1)如果辅助栈stack为空,则将该操作符入栈(push);
(2)如果该操作符的优先级大于或等于辅助栈栈顶的操作符,则将该操作符入栈(push);
(3)如果该操作符的优先级小于辅助栈栈顶的操作符,则将辅助栈栈顶的操作符出栈(pop),放入到队列中,直到该操作符的优先级大于或等于辅助栈栈顶的操作符,则将该操作符入栈(push);
3、如果扫描到的操作符是左括号"(”,就直接将该操作符入栈(push)。该操作符只有在遇到右括号“)”的时候移除。这是一个特殊符号该特殊处理。
4、如果扫描到的操作符是右括号“)”,则将辅助栈栈顶的操作符出栈(pop),放入到队列中,直到遇见左括号“(”。将堆栈中的左括号出栈(pop ),继续扫描下一个字符。
5、直到将表达式所有字符全部扫描完,如果辅助栈中还存在字符,则将该栈中一个一个字符出栈(pop),放入到队列中,直到辅助栈为空,最后得到的队列则为后缀表达式。
最后,转换为的后缀表达式为:a b c * + d e * f + g * +
参考文章:中缀表达式转后缀表达式
2.4.2.2 计算结果
package com.service;
import com.model.Operand;
import com.utils.ExerciseToRpr;
import java.util.Stack;
/**
* 计算结果类
* 使用后缀表达式
*/
public class ComputeResult {
/**
* 计算题目结果并写入结果文件Answers.txt
* @param exercise
* @return
*/
public static String compute(String exercise){
// 计算题目结果
// 先将中缀表达式转换为后缀表达式
String rpr = ExerciseToRpr.exerciseToRpr(exercise);
// 将后缀表达式字符串按照空格分割成操作单元数组
String[] opers = rpr.split(" ");
// 计算操作的辅助栈
Stack<String> stack = new Stack<>();
// 计算结果
Operand result;
for(int i = 0;i < opers.length;i++){
if(!ExerciseToRpr.isOperator(opers[i])){
// 若是数,则入栈
stack.push(opers[i]);
}else{
// 若是运算符,则栈顶两数出栈计算结果再入栈
String n2 = stack.pop();
String n1 = stack.pop();
// 将数字字符串转换为操作数对象
Operand b = Operand.stringToOperand(n2);
Operand a = Operand.stringToOperand(n1);
// 根据运算符类型进行运算
if(opers[i].equals("+")){
result = Operand.add(a,b);
}else if(opers[i].equals("-")){
result = Operand.sub(a,b);
}else if (opers[i].equals("*")) {
result = Operand.mul(a,b);
}else{
result = Operand.div(a,b);
}
// 计算过程出现除数为0或计算结果为负时,丢弃表达式
if(result == null){
return "unqualified";
}
// 把计算结果入栈
stack.push(result.toString());
}
}
return stack.peek();
}
}
以上使用逆波兰法将中缀表达式转换为后缀表达式后,进行表达式计算就非常容易了,在此我们也借助辅助栈stack。
1、从左到右遍历后缀表达式,如果扫描到的字符为操作数,则入栈(push);
2、如果扫描到的字符为运算符,则将辅助栈栈顶的两个操作数出栈进行运算,由于在本项目中,所有操作数生成表达式后以字符串存储,出栈后先使用操作数模型中的stringToOperand方法将操作数字符串转换为操作数对象,在进行操作数间的运算,最后将运算结果使用操作数模型中toString方法将操作数对象转换为操作数字符串入栈(push);
3、直到最终获得结果,并把结果写入Answers.txt文件中。
参考文章:后缀表达式计算
2.4.3 判断重复
先使用上述的逆波兰法将中缀表达式转换为后缀表达式,再将后缀表达式转换为二叉树形式,最后利用二叉树同构原理对表达式进行判重(同构即重复)
2.4.3.1 后缀表达式转换为二叉树
package com.utils;
import com.model.BinaryTreeNode;
import java.util.Queue;
import java.util.Stack;
/**
* 表达式转换为二叉树类
*/
public class ExerciseToBinaryTree {
/**
* 将正常算术表达式(中缀表达式)转换为二叉树
* 先将中缀表达式转换为后缀表达式
* @param exercise
* @return
*/
public static BinaryTreeNode exerciseToBinaryTree(String exercise) {
// 先将中缀表达式转换为后缀表达式链表
Queue<String> rprQueue = ExerciseToRpr.tranToRpr(exercise);
// 用于转化二叉树操作的辅助栈
Stack<BinaryTreeNode> nodeStack = new Stack<>();
// 将逆波兰表达式队列转化为二叉树形式
while(!rprQueue.isEmpty()){
// 弹出队首元素并新建节点
String oper = rprQueue.poll();
BinaryTreeNode node = new BinaryTreeNode(oper);
if(ExerciseToRpr.isOperator(oper)){
// 若为运算符节点,则弹出栈顶两个节点作为运算符结点的左右节点
// 先弹出的作为右节点,后弹出的作为左节点
node.setRightNode(nodeStack.pop());
node.setLeftNode(nodeStack.pop());
// 将运算符节点入栈
nodeStack.push(node);
}else{
// 若为操作数结点,则入栈
nodeStack.push(node);
}
}
// 返回二叉树根节点
return nodeStack.pop();
}
}
我们还是使用辅助栈stack,后缀表达式用队列存储。
1、弹出后缀表达式队列的队首节点并新建节点,若该节点是操作数节点,则将该操作数入栈(push);
2、若该节点是运算符节点,则弹出辅助栈栈顶(pop)的两个节点(运算符节点/操作数节点)作为该运算符节点的左右节点先弹出的节点作为右节点,后弹出的节点作为左节点,最后把该运算符节点入栈(push);
3、直到后缀表达式队列为空,返回辅助栈栈顶节点,即二叉树根节点
2.4.3.2 二叉树同构原理
package com.service;
import com.model.BinaryTreeNode;
/**
* 判断重复类
* 两树是否同构
*/
public class JudgeRepetition {
/**
* 利用树的同构原理,判断两棵树是否同构,即两个题目是否重复
* @param t1 题1二叉树根结点
* @param t2 题2二叉树根结点
* @return 判断结果(true则同构)
*/
public static boolean judge(BinaryTreeNode t1,BinaryTreeNode t2) {
if(t1 == null && t2 == null)
return true;
if(t1 == null && t2 != null){
return false;
}
if(t1 != null && t2 == null){
return false;
}
if(t1.getValue() != t2.getValue()){
return false;
}
return judge(t1.getLeftNode(),t2.getLeftNode()) && judge(t1.getRightNode(),t2.getRightNode())
|| judge(t1.getLeftNode(),t2.getRightNode()) && judge(t1.getRightNode(),t2.getLeftNode());
}
}
二叉树同构:如果二叉树T1可以通过若干次左右孩子互换就变成二叉树T2,则可称这两颗树同构,即两表达式重复。
如下图中前两个图同构,后两个不同构:
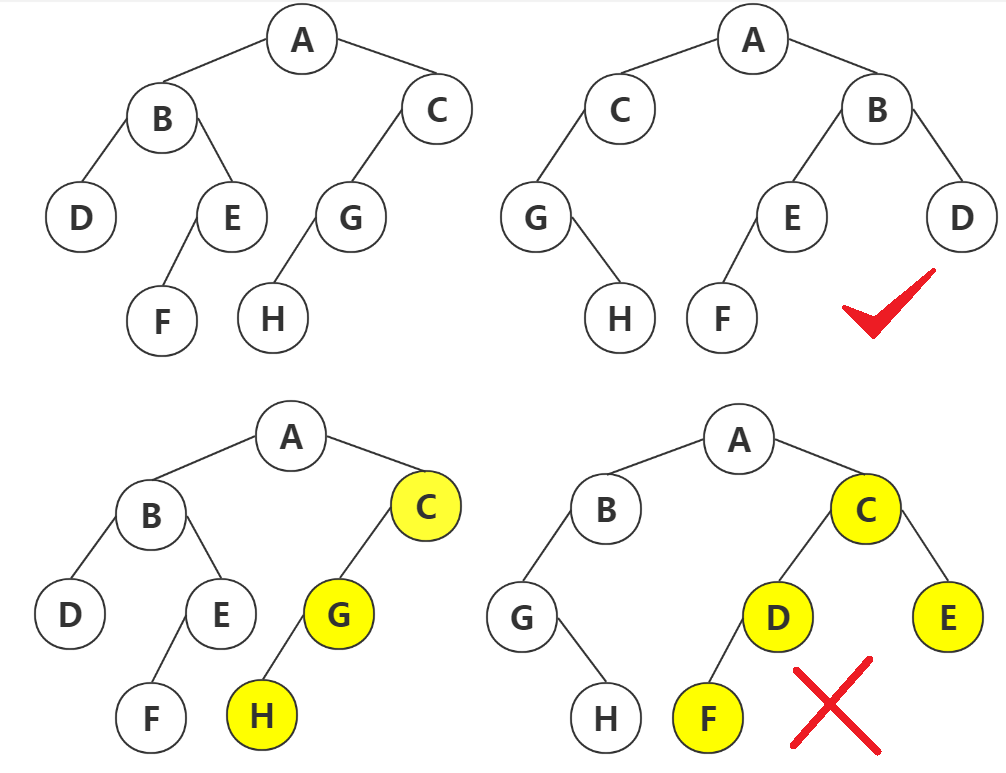
判断二叉树同构的代码,我们使用递归,判断两二叉树左孩子,右孩子,左右孩子,右左孩子四种情况是否完全相同。
参考文章:如何判断两颗二叉树同构
2.4.4 答案比较
package com.service;
import com.utils.FileProcessUtil;
import java.util.ArrayList;
/**
* 答案对比类
*/
public class CompareAnswer {
/**
* 对比自填答案与题目答案,并将结果输出到Grade.txt文件中
* @param answer
* @return
*/
public static int[] compare(ArrayList<String> answer){
// 从Answers.txt文件中读出题目正确答案
String answersPath = FileProcessUtil.resourceBundle("com/path","Answers.txt");
String[] rightAnswerStr = FileContentProcess.read(answersPath).split("\n");
// 题目数
int len = answer.size();
// 正确答案
String[] rightAnswer = new String[len];
// 剔除题号
for(int i = 0;i < len;++i){
rightAnswer[i] = rightAnswerStr[i].split("、")[1];
}
// 正确题目
StringBuffer correct = new StringBuffer();
// 错误题目
StringBuffer wrong = new StringBuffer();
// 循环判断答案
for(int i = 0;i < len;++i){
if(rightAnswer[i].equals(answer.get(i))){
correct.append(i + 1);
correct.append(",");
}else{
wrong.append(i + 1);
wrong.append(",");
}
}
// 正确/错误题目数
int c = 0,w = 0;
// 删除最后一个逗号
if(correct.length() != 0){
correct.deleteCharAt(correct.length()-1);
c = correct.toString().split(",").length;
}
if(wrong.length() != 0){
wrong.deleteCharAt(wrong.length()-1);
w = wrong.toString().split(",").length;
}
// 生成结果
String result = "Correct: " + c + " (" + correct + ")\n" +
"Wrong: " + w + " (" + wrong + ")";
// 获取对比结果文件路径
String gradePath = FileProcessUtil.resourceBundle("com/path","Grade.txt");
// 对比结果写入文件
FileContentProcess.write(gradePath,result);
return new int[]{c,w};
}
}
1、先读取题目窗口中用户的自填答案,同时判断答案格式是否合法,最后存储到一个List集合中;
2、读取Answers.txt文件中所有题目的正确答案,使用String数组进行存储,并将序号和“、”去除;
3、通过遍历List集合进行答案比较并统计答题情况。
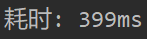
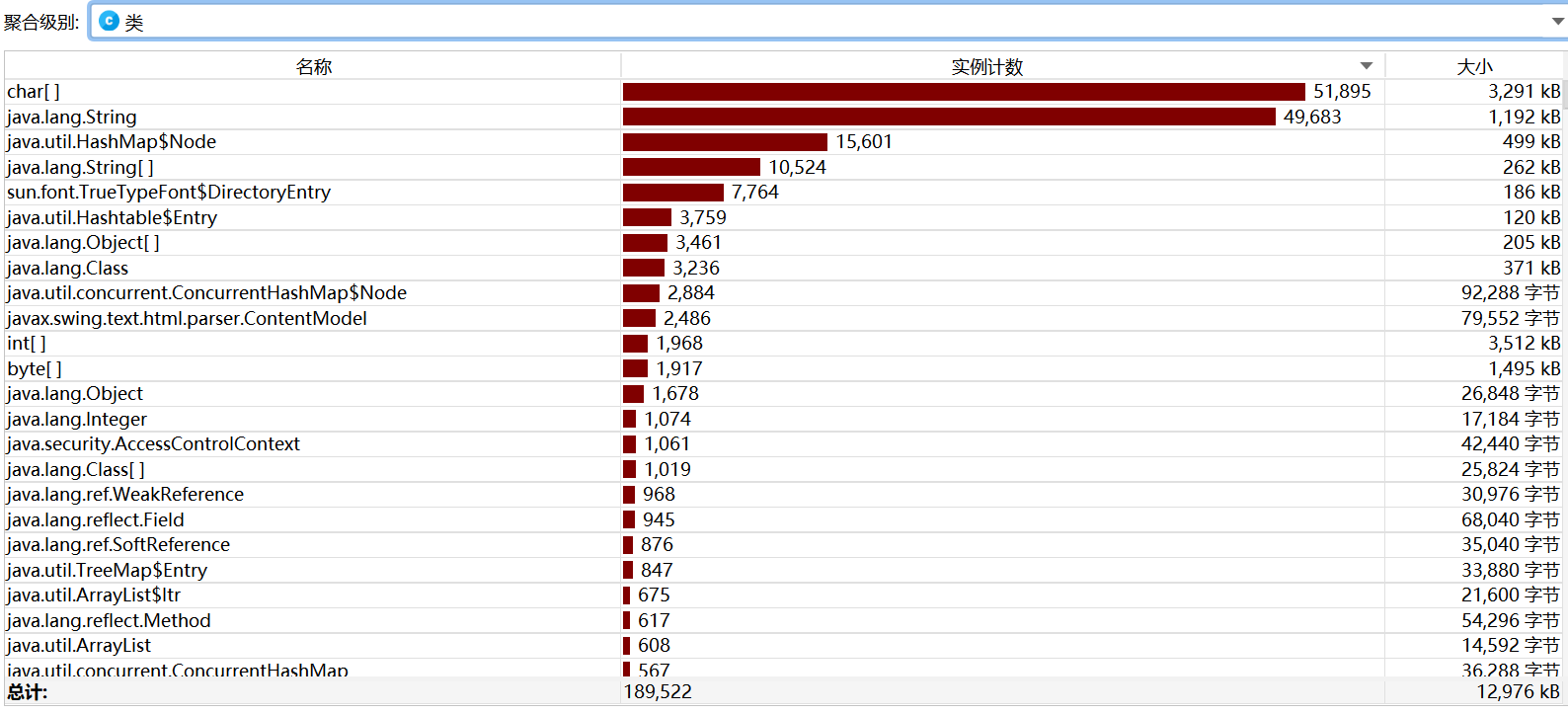
3. 性能分析
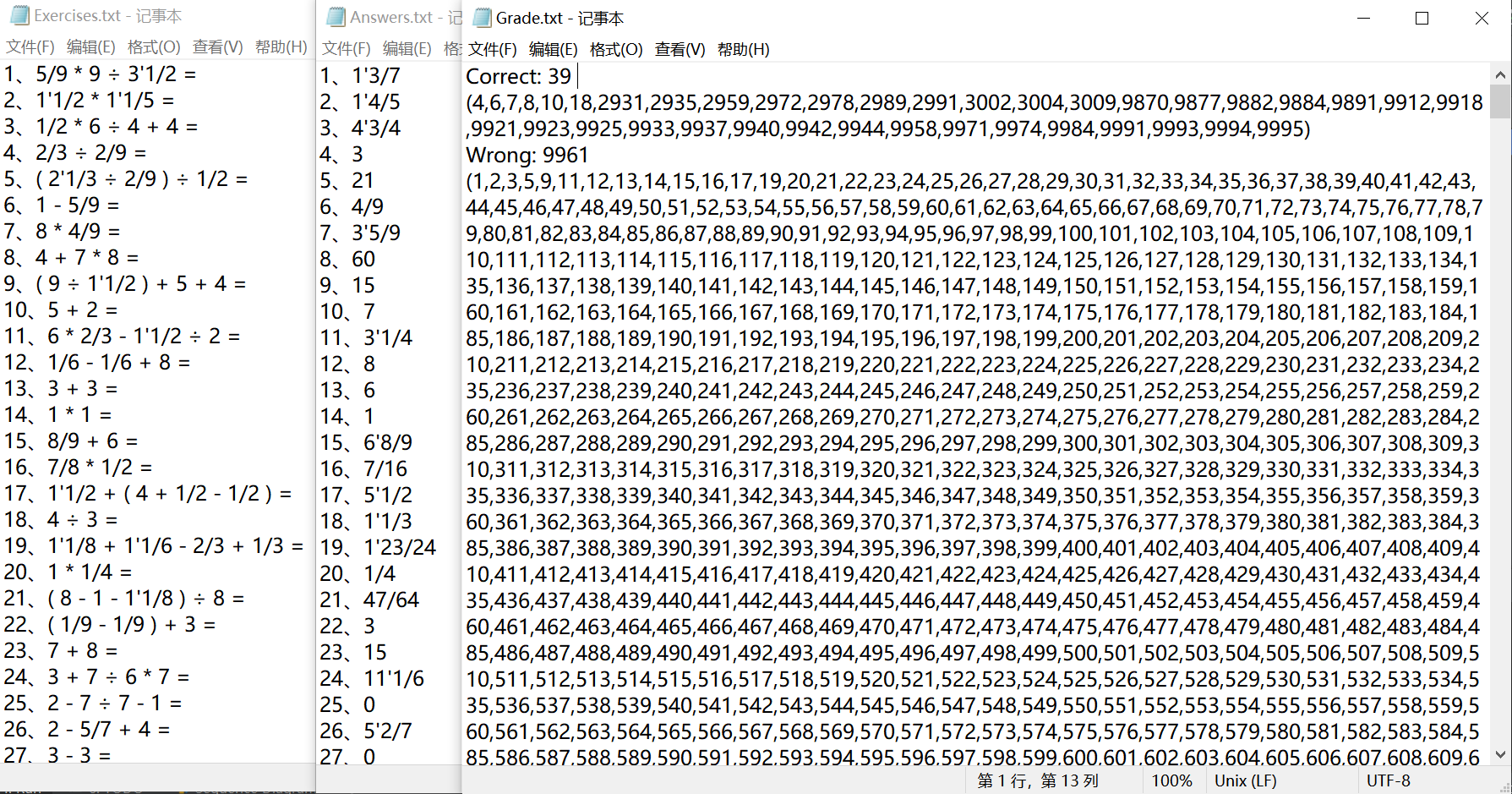
测试生成10000道题目的性能分析:
4. 测试运行
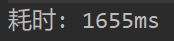
4.1 测试耗时及代码
生成10000题目测试耗时:
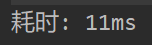
题目答案比较测试耗时:
package com.test;
import com.service.CompareAnswer;
import com.service.GenerateExcerises;
import org.junit.Test;
import java.util.ArrayList;
public class TestAll {
/**
* 测试生成10000道题目
* @throws Exception
*/
@Test
public void testGenerateExercises() {
long start = System.currentTimeMillis();
try {
GenerateExcerises.generateExercises(10000,10);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("耗时: " + (System.currentTimeMillis() - start) + "ms");
}
/**
* 测试程序生成的答案是否完全正确,注意需要先生成题目文件和答案文件
*/
@Test
public void testCheck() {
long start = System.currentTimeMillis();
CompareAnswer.compare(new ArrayList<>());
System.out.println("耗时: " + (System.currentTimeMillis() - start) + "ms");
}
}
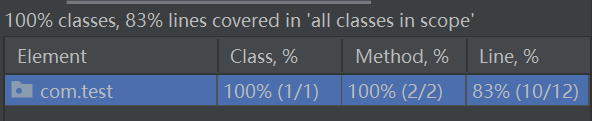
4.2 测试代码覆盖率
5. 项目异常说明
1、输入窗口非法判断
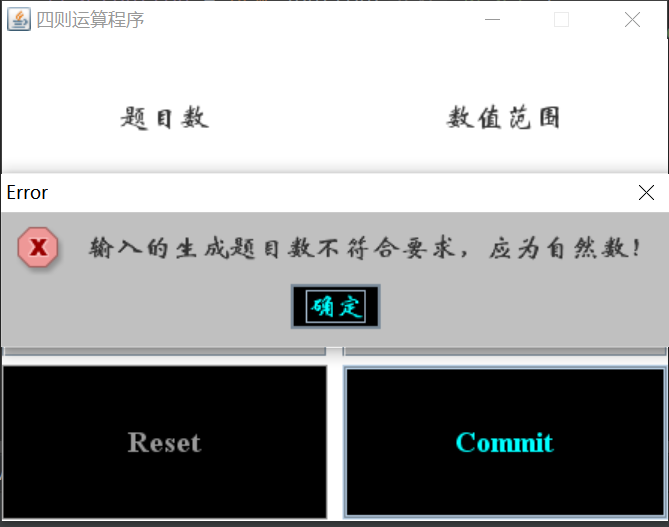
(1)生成题目数不为自然数
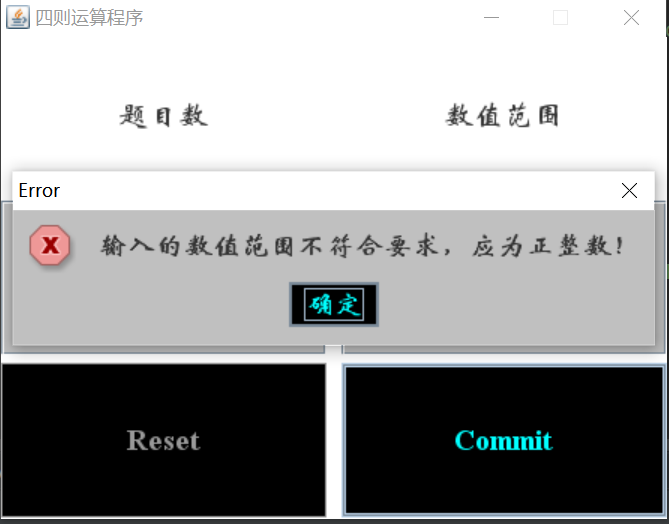
(2)生成题目数不为正整数
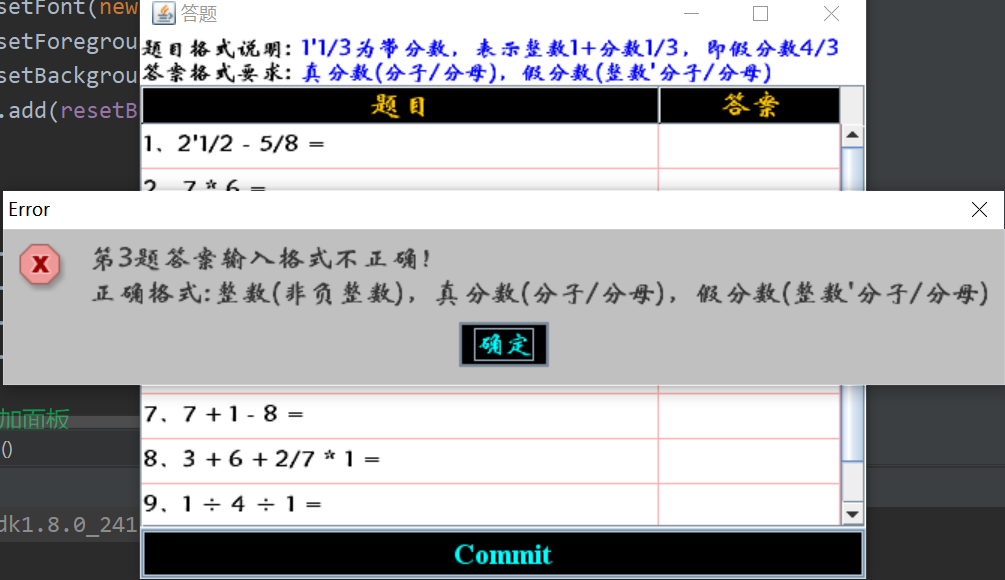
2、题目窗口填写答案非法判断
6. 项目功能测试
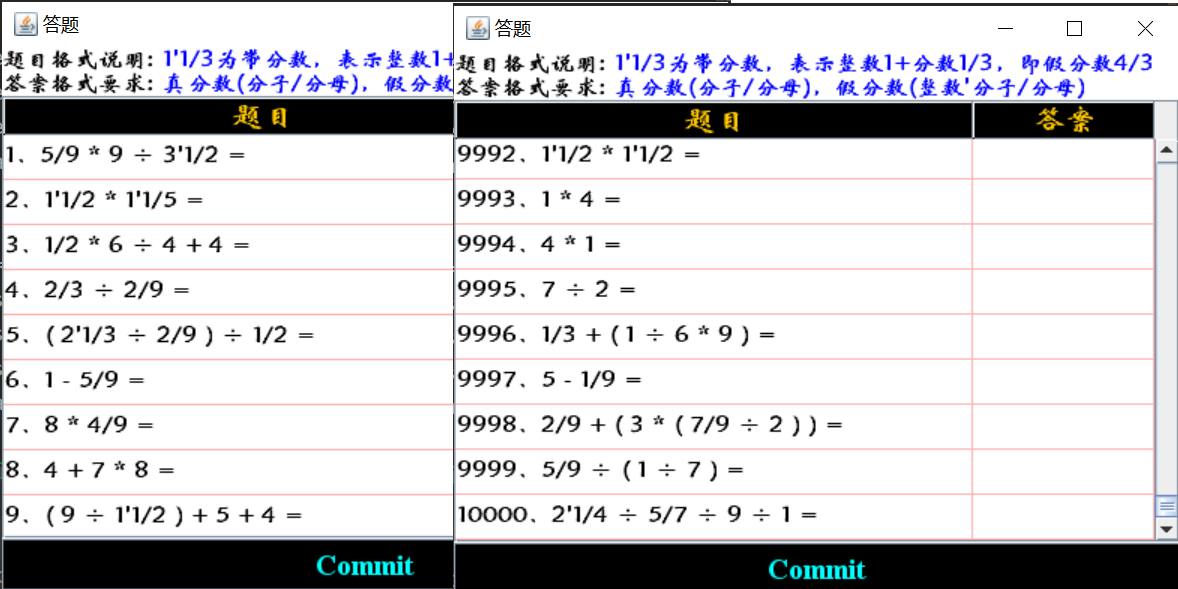
6.1 生成10000道数值10以内的题目
1、输入窗口

2、题目窗口前10道和后10道题
3、结果窗口
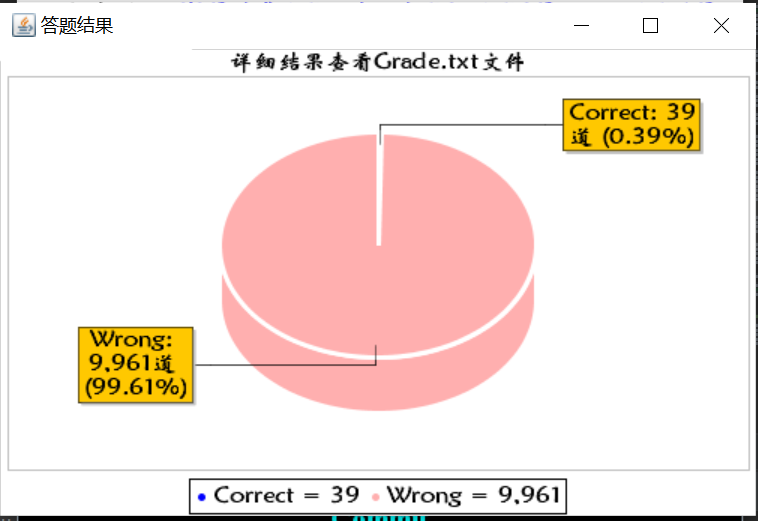
4、题目、答案、结果文件
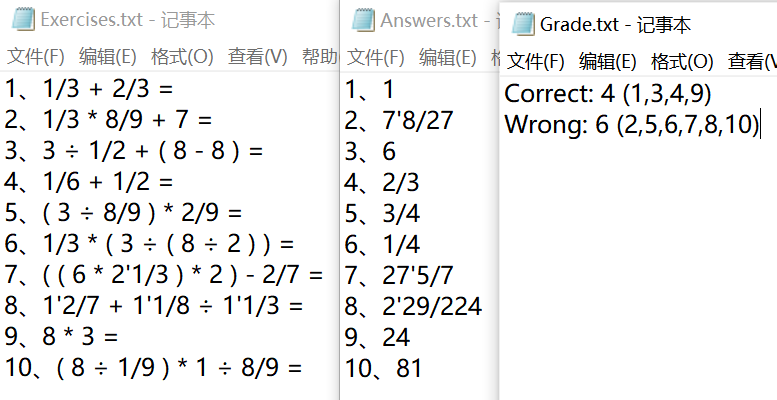
6.2 生成10道数值10以内的题目
1、输入窗口

2、题目窗口

3、结果窗口
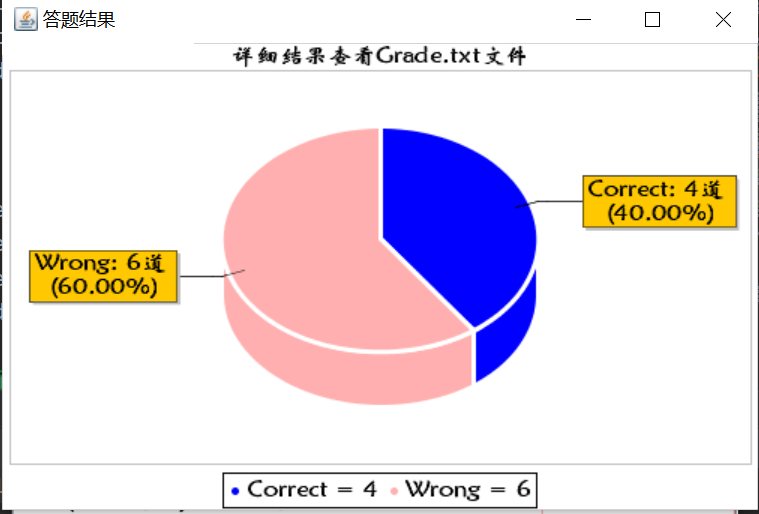
4、题目、答案、结果文件
7. 项目小结
项目开始前,我们本以为这应该是一个中规中矩的项目,后来经过各种讨论和尝试后,才发现需要注意的点挺多的,如数值的非负处理、括号的插入和答案格式的统一等。我们两人陆续查阅和学习了各种资料,最终确定下来用操作数模型将数统一为分数进行存储,使用逆波兰法将常见的中缀表达式转换为后缀表达式便于计算,利用二叉树同构原理来解决查重功能。第一次做结对项目,我们认识到了结对编程的好处,可以更快地确定编程的走向和提出各种问题并一一解决,集思广益,一同进步。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号