个人项目
个人项目
| 软件工程 | <网工1934> |
|---|---|
| <作业要求> | 1. 在 GitHub 仓库中新建一个学号为名的文件夹。 2. 在开始实现程序之前,在 PSP 表格记录下你估计在程序开发各个步骤上耗费的时间,在实现程序之后,在PSP表格记录下你在程序的各个模块上实际花费的时间。 3. 语言不限,并将编译好的程序发布到 GitHub 仓库中的 releases 中。 4. 提交的代码要求经过 Code Quality Analysis 工具的分析并消除所有的警告。 5. 完成项目的首个版本之后,请使用性能分析工具Studio Profiling Tools来找出代码中的性能瓶颈并进行改进。 6. 使用GitHub来管理源代码和测试用例,代码有进展即签入GitHub。 7. 使用单元测试对项目进行测试,并使用插件查看测试分支覆盖率等指标;写出至少10个测试用例确保你的程序能够正确处理各种情况。 |
| 作业目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 |
1.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 1270 | 1540 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 250 | 350 |
| · Design Spec | · 生成设计文档 | 150 | 100 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 200 | 250 |
| · Coding | · 具体编码 | 300 | 450 |
| · Code Review | · 代码复审 | 100 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 150 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 50 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 50 | 40 |
| · 合计 | 1270 | 1540 |
2. 计算模块接口与实现过程
2.1 主要实现类
2.1.1 工具类
FileUtils类:文件处理工具类,具有读文件,写文件和获取文件名的静态方法
WordUtil类:文件内容分词工具类,具有对输入的字符串进行分词处理并返回的静态方法
Tf_IdfUtil类:查重工具类,具有对两段字符串进行查重(计算文本相似度)的静态方法(使用TF-IDF算法)
ResultUtil类:查重结果处理工具类,具有对查重结果进行处理并返回的静态方法
2.1.2 主类
StartClass类 :程序入口类,其中main方法中的输入参数String[] args可以接收多个参数用以作为输入输出文件的绝对路径(args[0],args[1],args[2]),main方法中调用工具类中的静态方法实现整个查重功能(读文件,分词,计算文本相似度,写文件)。
2.1.3 测试类
testCase类:单元测试类,其中有对分词功能,文本相似度计算功能进行单元测试的方法,均带有@Test注解
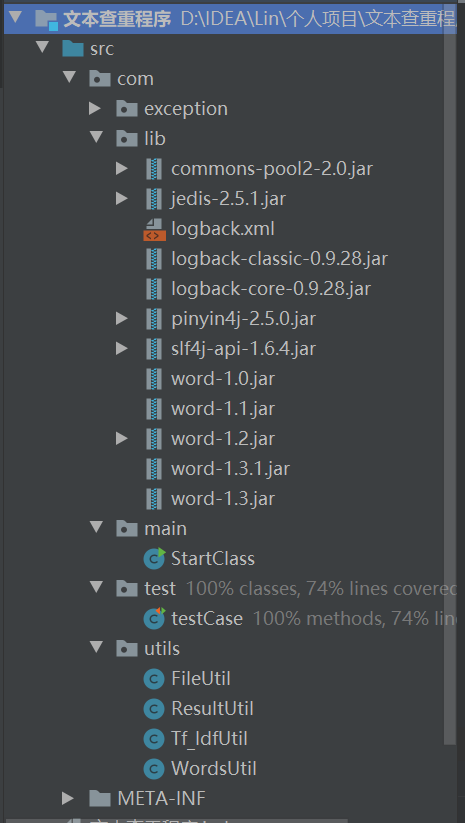
2.2 项目结构
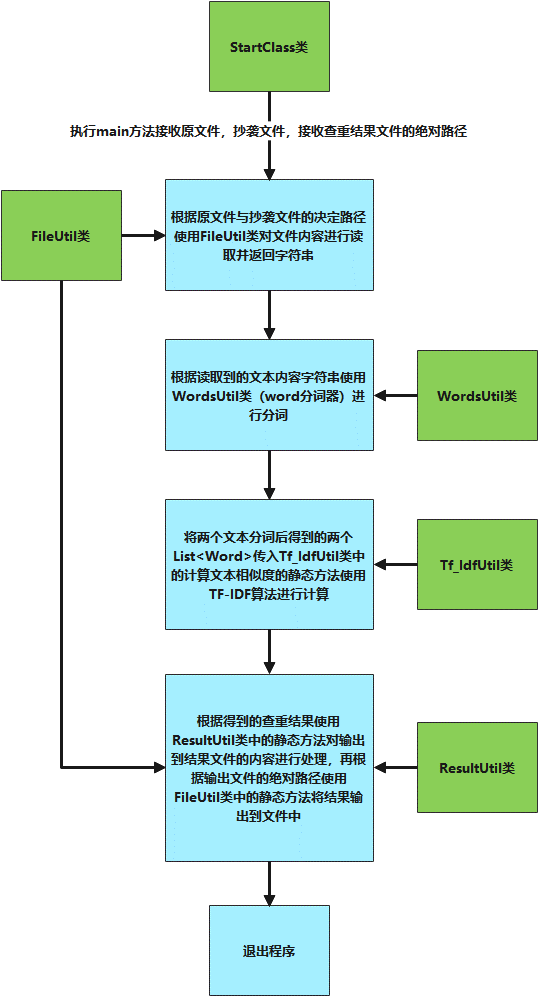
2.3 项目流程(类与类之间的关系)
2.4 关键函数的分析与实现
该项目实现的关键点在于文本的分词和文本相似度算法(查重)
于是在正式开始编写程序之前,我查询了很多关于中文分词器和计算文本相似度算法的资料,参考了以下文章:
经深思熟虑后,我最后选择使用word分词器和TF-IDF算法来完成本次个人项目
2.4.1 TF-IDF算法大致介绍
TF-IDF算法其实就是余弦相似度算法
余弦相似度就是通过一个向量空间中两个向量夹角的余弦值作为衡量两个个体之间差异的大小。把1设为相同,0设为不同,那么相似度的值就是在[0,1],如下图:
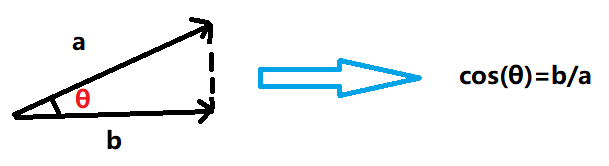
三角形越扁平,说明两个体间的距离越小,相似度越大;反之,相似度越小。但是,文本的相似度计算只是针对字面量来计算的,也就是说只是针对语句的字符是否相同,而不考虑它的语义。如:句子1:你真好看;句子2:你真难看。这两句话相似度75%,但是它们的语义相差巨大,可以说是完全相反。所以在实际中,没有很完美的解决方案。
2.4.2 简单描述两个体的距离计算公式
1. 向量a和向量b是二维
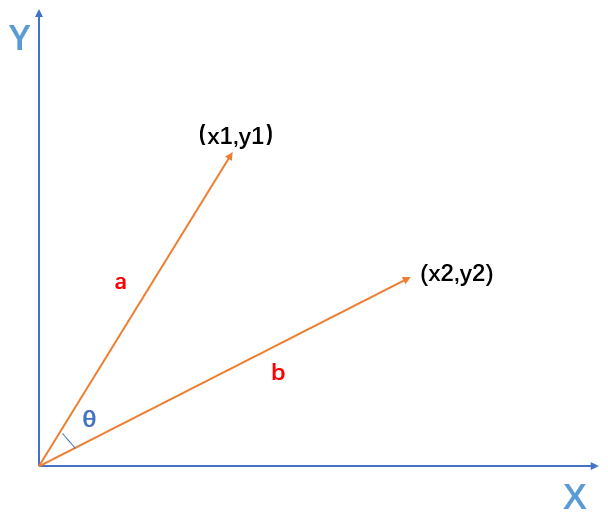
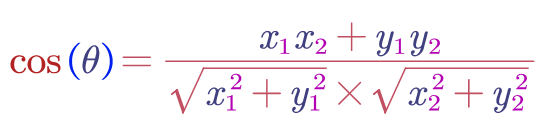
2. 拓展到n维的计算模型
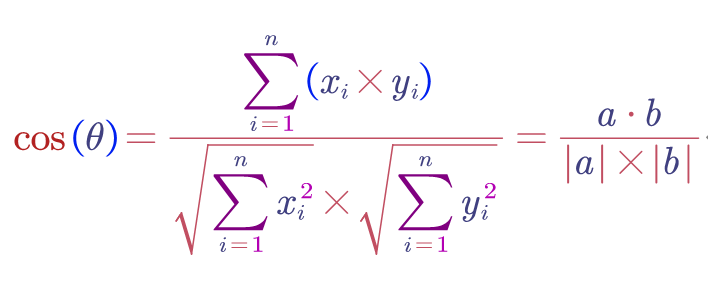
2.4.3 TF-IDF算法计算流程
范例:
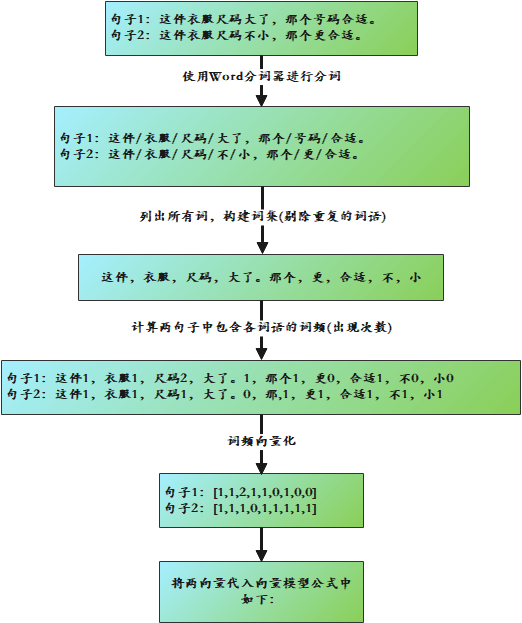
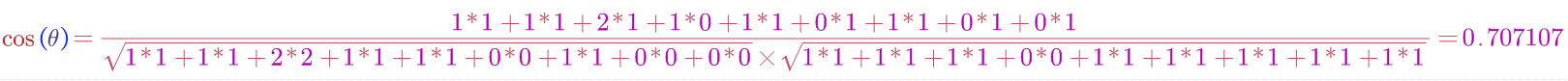
由图可知,两个句子的相似度计算的步骤是:
- 通过中文分词,把完整的句子根据分词算法分为独立的词集合
我使用了Word分词器1.3版本。
- 求出两个词集合的并集(词集)
算法中,我新建一个List集合作为词集,分别遍历两个分词后的List集合,将未出现的存入词集中,已出现的跳过。
- 计算各自词集的词频并把词频向量化
算法中,我使用两个int数组存储两个文本中,对应词集中每个词出现的次数,即词频。
- 带入向量计算模型就可以求出文本相似度
将得到的两个int数组按照n维计算模型的公式进行运算。
计算出两个向量的余弦相似度,值越大就表示越相似。
3. 计算模块接口部分的性能改进
3.1 性能分析准备
1. 在IDEA中下载JProfiler插件
2. 安装JProfiler监控软件并在IDEA中添加可执行文件(.exe)
参考文章:
Intellij IDEA集成JProfiler性能分析神器
3.2 第一版程序
耗时非常大,需要差不多50秒的运行时间,分析可知,可能是因为使用的Word分词器版本过高;
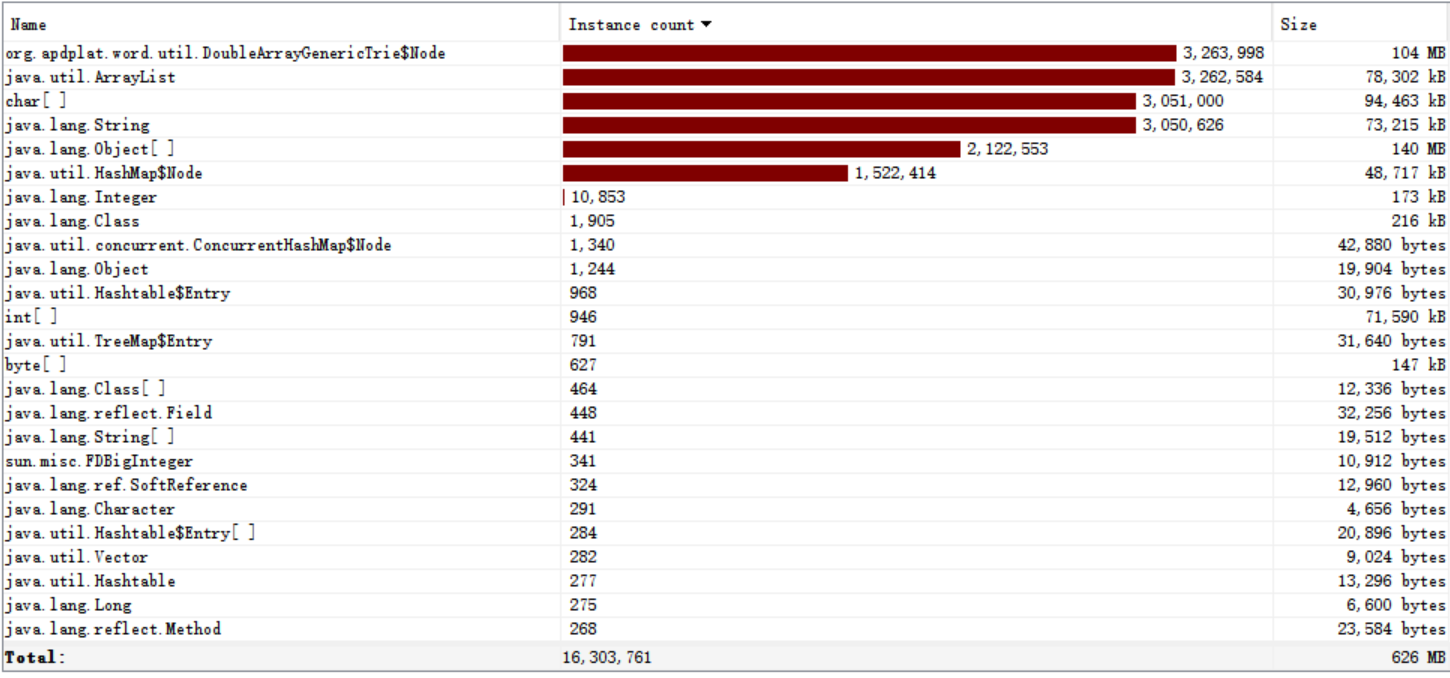
3.3 第二版程序
我将外部依赖中(lib中)的分词器版本下调至1.2,再次进行性能分析,运行速度明显提升很多
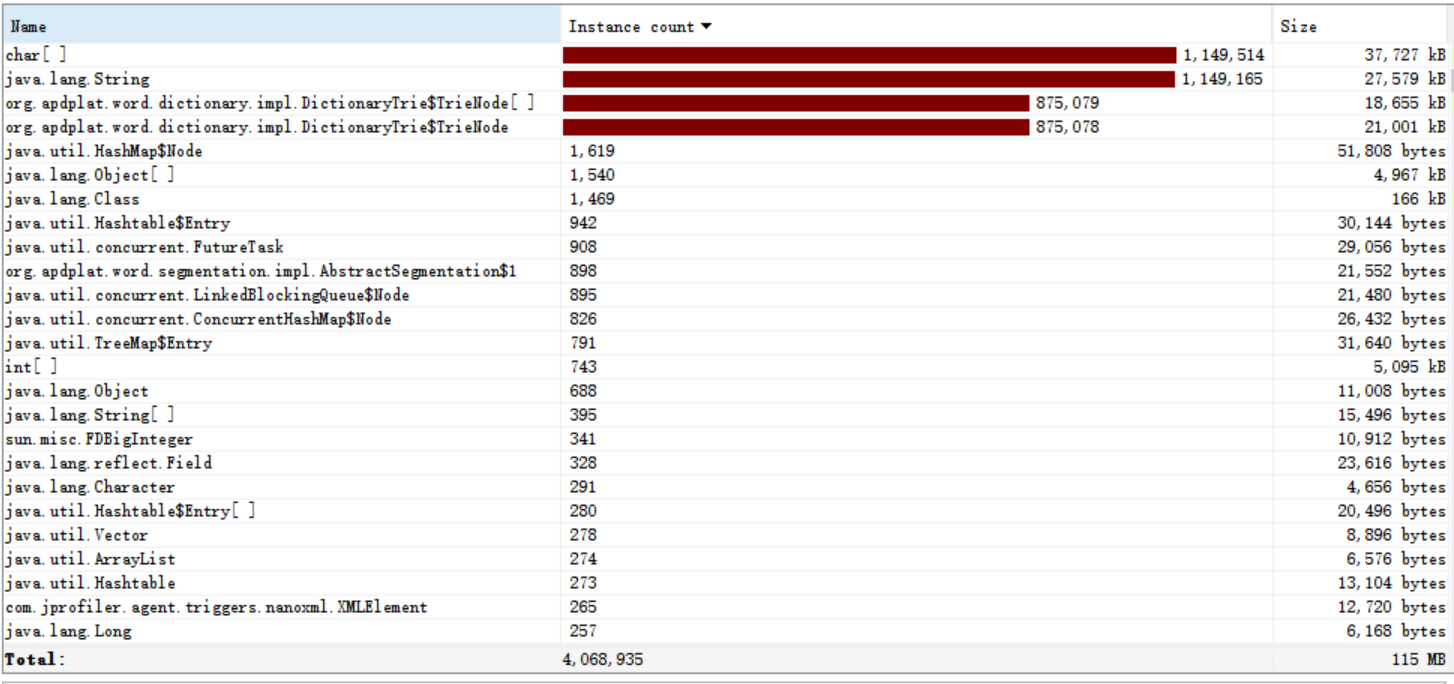
但可发现分词器查询字典函数调用占用非常大,即控制台输出耗费了很多时间,于是我禁用了外部依赖中的控制台输出jar包
3.4 第三版程序
我禁用了外部依赖中的控制台输出jar包,输出时间再次减少
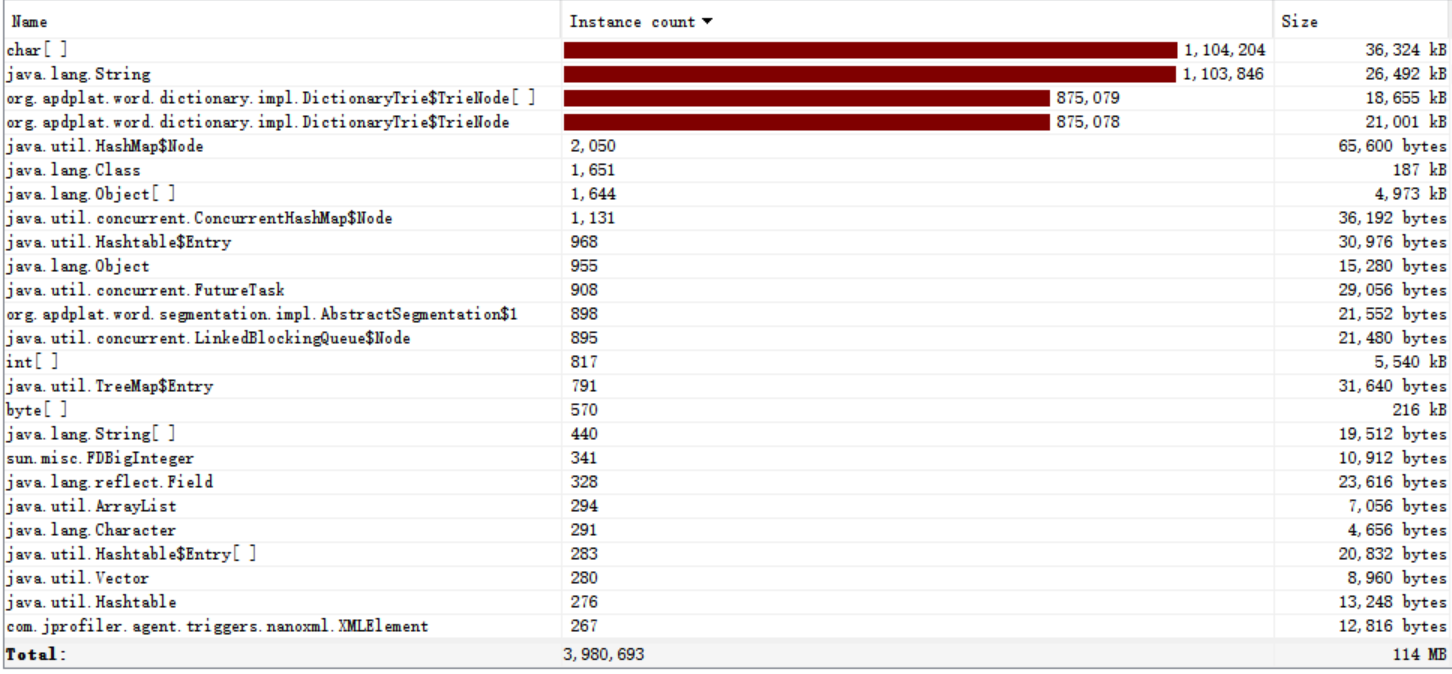
参考文章:
4. 计算模块部分单元测试展示
4.1 单元测试准备
1. 在IDEA中下载JUnitgenerator V2.0插件
2. 在需要单元测试的模块中添加jar包
参考文章:
4.2 WordsUtil类测试
``
// 测试分词功能
@Test
public void testWordsUtil() {
// 测试正常情况下对文本进行分词
List<Word> cutFileContent1 = WordsUtil.cutFileContent("今天是星期天,天气晴,今天晚上我要去看电影。");
System.out.println("正常情况下: " + cutFileContent1);
// 测试字符串倒序情况下对文本进行分词
List<Word> cutFileContent2 = WordsUtil.cutFileContent("影电看去要我上晚天今,晴气天,天期星是天今。");
System.out.println("字符串倒序情况下: " + cutFileContent2);
// 测试字符串中加入乱码情况下对文本进行分词
List<Word> cutFileContent3 = WordsUtil.cutFileContent("今!#%天是星期&&天,天气晴,今天晚**上我要去(看电@影。");
System.out.println("字符串中加入乱码情况下: " + cutFileContent3);
// 测试字符串中有空格情况下对文本进行分词
List<Word> cutFileContent4 = WordsUtil.cutFileContent("今天是星期 天,天 气晴,今天晚 上我要去看电 影。");
System.out.println("字符串中有空格情况下" + cutFileContent4);
// 测试空串情况下对文本进行分词
List<Word> cutFileContent5 = WordsUtil.cutFileContent("");
System.out.println("空串情况下: " + cutFileContent5);
}
测试结果:

4.3 Tf_IdfUtil类测试
``
// 测试文本相关度算法
@Test
public void testTf_IdfUtil() {
List<Word> sourceCutFileContent = WordsUtil.cutFileContent("今天是星期天,天气晴,今天晚上我要去看电影。");
// 测试字符串相同情况
List<Word> copyCutFileContent = WordsUtil.cutFileContent("今天是星期天,天气晴,今天晚上我要去看电影。");
double duplicateCheckingRate = Tf_IdfUtil.similarity(sourceCutFileContent, copyCutFileContent);
System.out.println("字符串相同的情况: " + duplicateCheckingRate);
// 测试字符串倒序情况
copyCutFileContent = WordsUtil.cutFileContent("影电看去要我上晚天今,晴气天,天期星是天今。");
duplicateCheckingRate = Tf_IdfUtil.similarity(sourceCutFileContent, copyCutFileContent);
System.out.println("字符串倒序的情况: " + duplicateCheckingRate);
// 测试字符串增加符号情况
copyCutFileContent = WordsUtil.cutFileContent("今!#%天是星期&&天,天气晴,今天晚**上我要去(看电@影。");
duplicateCheckingRate = Tf_IdfUtil.similarity(sourceCutFileContent, copyCutFileContent);
System.out.println("字符串增加符号情况: " + duplicateCheckingRate);
// 测试字符串存在部分改动情况
copyCutFileContent = WordsUtil.cutFileContent("今天是周末,天气晴朗,我晚上要去看电影。");
duplicateCheckingRate = Tf_IdfUtil.similarity(sourceCutFileContent, copyCutFileContent);
System.out.println("字符串存在部分改动情况: " + duplicateCheckingRate);
// 测试字符串部分缺失情况
copyCutFileContent = WordsUtil.cutFileContent("今天是星期,天晴,今天晚我要去电影。");
duplicateCheckingRate = Tf_IdfUtil.similarity(sourceCutFileContent, copyCutFileContent);
System.out.println("字符串部分缺失情况: " + duplicateCheckingRate);
// 测试字符串为空串的情况
sourceCutFileContent = WordsUtil.cutFileContent("");
copyCutFileContent = WordsUtil.cutFileContent("");
duplicateCheckingRate = Tf_IdfUtil.similarity(sourceCutFileContent, copyCutFileContent);
System.out.println("字符串为空串情况: " + duplicateCheckingRate);
}
测试结果:
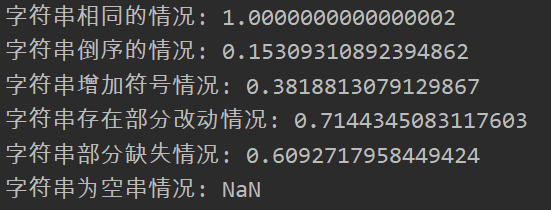
当字符串为空串时,输出为NAN,需要进行异常处理。
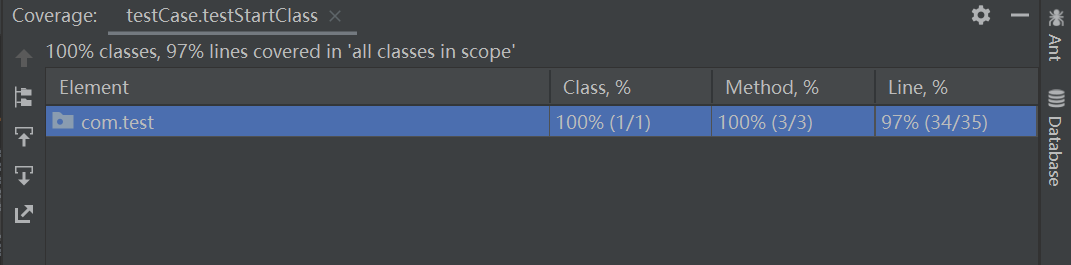
4.4 代码覆盖率
5. 模块部分异常处理说明
5.1 处理空串输入,输出为NAN
由4.3中可知,当两文件内容中存在一个为空时,即会输出为NAN,需要做异常处理(自定义异常类)
5.1.1 自定义异常类
``
package com.exception;
/**
* 自定义异常类:处理空字符串(文件内容为空)
*/
public class NullStringException extends Exception{
public NullStringException() {
}
public NullStringException(String message) {
super(message);
}
}
5.1.2 在WordsUtil中添加异常检测
``
public static List<Word> cutFileContent(String fileContent){
if("".equals(fileContent)){
throw new NullPointerException("文件内容为空! ");
}
// 调用word分词器中的分词函数
List<Word> cutFileContent = WordSegmenter.segWithStopWords(fileContent);
// 返回分词后的内容
return cutFileContent;
}
5.1.3 检测结果
捕获空串异常,在控制台输出

5.2 个人项目测试过程中报错
以下报错:无法加载类,是以为前面我为了提高程序运行速度,将控制台输出相关的jar包去除,对整个程序的查重功能没有影响。

6. 个人项目功能测试
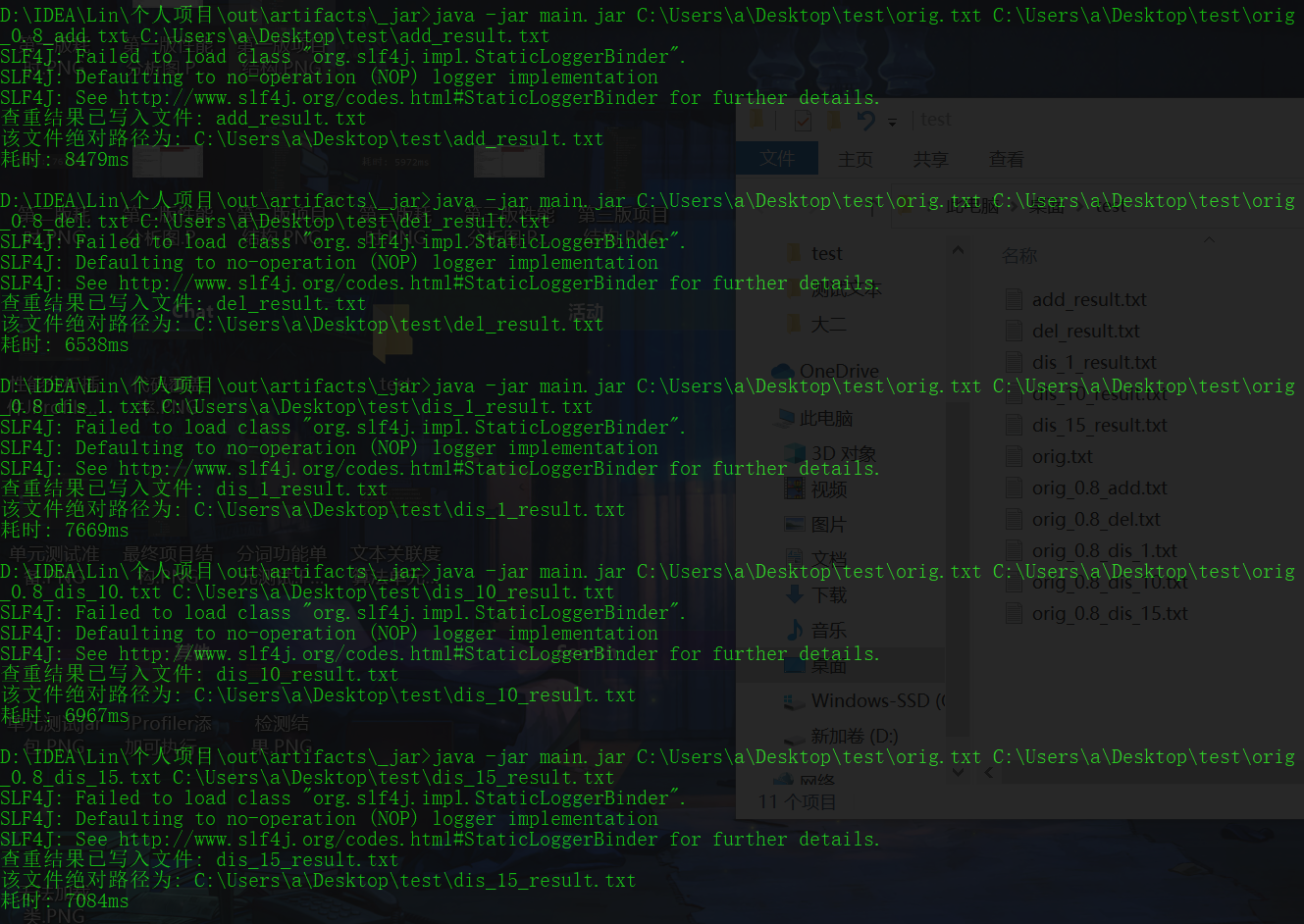
进入到main.jar包所在的目录下,输入:java -jar main.jar 原文文件绝对路径 抄袭文件绝对路径 查重结果文件绝对路径 即可运行该程序,输出结果为结果文件所在位置以及程序耗时,结果文件中包括此次查重涉及的两文件(原文件,抄袭文件)和查重率。
6.1 测试结果
6.2 文件结构
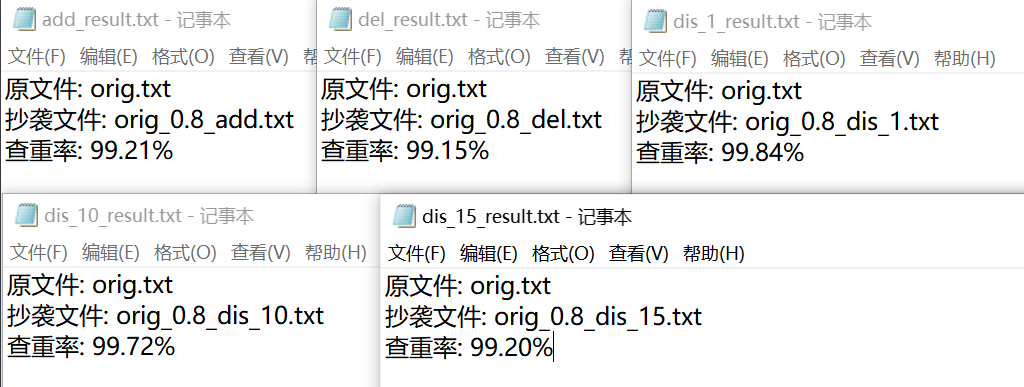
6.3 查重结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号