Solr简介
# 搜索引擎
搜索引擎,Search Engine是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,再对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎和免费链接列表等。
一个搜索引擎由搜索器、索引器、检索器和用户接口四个部分组成:
1. **搜索器** 的功能是在互联网中漫游,发现和搜集信息。
2. **索引器**的功能是理解搜索器搜索到的信息,从中抽取出索引项,用过表示文档以及生成文档库的索引表。
3. **检索器**的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。
4. **用户接口**的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
搜索引擎现在主要为全文索引和目录索引,垂直搜索引擎由于其在特定领域的更高的用户体验,以及更小的硬件成本,也开始逐渐兴起。
## 分类
### 全文搜索引擎
搜索引擎的自动信息搜集功能分两种。
一种是*定期搜索*,即每隔一段时间搜索引擎主动派出爬虫程序,对一定IP地址范围内的互联网网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。
另一种是*提交网站搜索*,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向你的做网站派出爬虫程序,扫描你的网站并将有关信息存入数据库,以备用户查询,随着搜索引擎索引规则的变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊算法——通常根据网页中关键词的匹配程度、出现位置、频次、链接质量——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户,这种引擎的特点是搜全率比较高。
### 目录索引
也称为**分类检索**,是网上最早提供www资源查询的服务,主要通过搜集和整理网上的资源,根据搜索到网页的内容,将其网址分配到相关分类主题目录的不同层次类目之下,形成像图书馆一样的**分类树形结构索引**,目录索引无需要输入任何文字,只要根据网站提供的主题分类目录,层层点击进入,便可查到所需的网络信息资源。
严格意义上,目录索引不能称为搜索引擎。
* 目录索引与搜索引擎不同:
+ 搜索引擎为程序自动索引;而目录索引则依赖人为操作。
+ 搜索引擎不考虑网站分类,根据关键词网站频率构建搜索索引;而目录索引需要甄别网站的分类目录位置。
+ 搜索引擎检索到信息是程序爬虫自动获取的,没有或少有过滤机制,而目录索引有大量的人为审查过滤机制,因而信息目录构建也相对缓慢。
* 目录索引与搜索引擎的融合
现在的搜索引擎也提供分类查询功能,如Google使用open Directory目录提供分类查询,在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如中国的搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。这种引擎的特点是检索的准确率比较高。
### 垂直搜索引擎
专注于特定搜索领域和搜索需求(如机票搜索、旅游搜索、生活搜索、小说搜索、视频搜索、购物搜索……)在其特定的搜索领域有更好的用户体验。相比通用搜索动辄数千台检索服务器,垂直搜索需要的硬件成本低、用户需求特定、查询的方式多样,比较适合中小型公司和创业型公司的搜索服务。
## Lucene
一个全文检索引擎工具包,是一个架构,提供了完整的查询引擎和索引引擎,部分分析引擎,不是一个完整的全文检索引擎。
Lucene为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者在Lucene基础上建立完整的全文检索引擎,Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻,它是一个检索程序库,而不是搜索引擎。
全文搜索引擎有Google、Fast/AlTheWeb、AltaVista、Inktomi、Teoma、WiseNut、Baidu。
## 倒排索引
倒排索引源于实际应用中需要根据属性值找记录,这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引,inverted index.
### 应用背景
在关系数据库里,索引是检索数据最有效率的方式,但对于搜索引擎,它并不能满足其特殊要求:
1. **海量数据**: 搜索引擎面对的是海量数据,像Google,百度这样的大型商业搜索引擎索引都是亿级甚至百亿级的网页数量,面对如此海量数据库系统很验难有效管理。
2. **数据操作简单**: 搜索引擎使用的数据操作简单,一般而言,只需要增、删、改、查几个功能,而且数据都有特定的格式,可以针对这些应用设计出简单高效的应用程序,而*一般的数据库系统则支持大而全的功能,同时损失了速度和空间* ,最后搜索引擎面临大量的用户检索需求,*这要求搜索引擎在检索程序的设计上要分秒必争,尽可能的将大运算量的工作在索引建立时完成,使检索运算尽量少。*一般的数据库系统很承受如此大量的用户请求,而且在*检索响应时间和检索并发度*上都不及专门设计的索引系统。
### 倒排列表
利用合拢索引方式构建而成的单词与文档的映射,其中文档部分的结构就是倒排列表。
倒排列表用来记录有哪些文档包含了某个单词,一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号DocID、单词在这个文档中出现的次数TF及位置等信息,这样与一个文档相关的信息被称作**倒排索引项**(Posting),包含这个单词的一系列倒排索引项形成了列表结构,就是这个单词对应的倒排列表。
在**实际的搜索引擎中,并不存储倒排索引项中的实际文档编号,而是代之以文档编号差值(D-Gap)**。文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出来的文档编号,所以文档编号差值总是大于0的整数,这样做可以更好地对数据进行压缩,原始文档编号一般都是大数值,**通过差值计算,就有效在将大数值转换为了小数值,而这有助于增加数据的压缩率**。
### 倒排索引
也称**反向索引**,转入档案或反向档案,是一种索引方法,被**用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射**。它是文档索引系统中最常用的数据结构,通过倒排索引可以根据单词快速获取包含这个单词的文档列表,倒排索引主要由两个部分组成,**单词词典**和**倒排文件**。
倒排索引有两种不同的反向索引形式:
* 一条记录的水平反向索引(或反向档案索引)包含每个引用单词的文档的列表。
* 一个单词的水平反射索引(或完全反射索引)又包含每个单词在一个文档中的位置。
后者的形式提供了更多的兼容性,比如短语搜索,但是需要更多的时间和空间来创建。现代搜索引擎的索引都是基于倒排索引,相比“签名文件”、“后缀树”等索引结构,“倒排索引”是实现单词到文档映射关系的最佳实现方式和最有效的索引结构。
#### 构建方法
构建方法有简单法和合并法两种。
##### 简单法
索引的构建相当于**从正排表到倒排表的建立过程**,当我们分析完网页时,得到的是以网页为主码的索引表,当索引建立完成后,应得到倒排表,流程如下:
1. 将文档分析成单词term;
2. 使用hash去重单词term;
3. 对单词生成倒排列表。
倒排列表是文档编号DocID,没有包含其他的信息(如词频、单词出现位置等),这就是简单的索引。
这个简单索引功能可以用于小数据,例如索引几千个文档,它有两点限制:
* 需要有足够的内存来存储倒排表,对于搜索引擎来说,都是G级别数据,特别是当规模不断扩大时,基本不可能提供这么多的内存。
* 算法是顺序执行,不便于并行处理。
##### 合并法
每次将内存中数据写入磁盘时,包括词典在内的所有中间结果信息都被写入磁盘,这样内存所有内容都可以被清空,后续建立索引可以使用全部的内存。流程:
1. 页面分析,生成临时倒排数据索引A、B,当临时倒排数据索引A、B占满内存后,将内存索引A、B写入临时文件生成临时倒排文件,
2. 对生成的多个临时倒排文件,执行多路归并,输出最终的倒排文件(inverted file)。
索引创建过程中的页面分析,特别是分词为主要时间开销,算法的第二步相对很快,这样创建索引算法的优化就集中在分词效率上了。
#### 更新策略
更新策略有四种:完全重建、再合并策略、原地更新策略以及混合策略。
1. 完全重建:当新文档到达一定数量,将新文档和原先的老文档整合,然后利用静态索引创建方法对所有文档重新索引,新索引建立完成后老索引被遗弃,此法代价高,但是主流商业搜索引擎一般是采用此方式来维护索引的更新。
2. 再合并策略:当亲增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排列表末尾追加倒排列表项,一旦临时索引将指定内存消耗光,即进行一次索引合并。
3. 原地更新:这是再合并策略的改进,需要提交分配一定的空间给未来插入,如果分配的空间不够了,需要迁移。其索引更新效率比再合并策略要低。
4. 混合策略:出几点是能够结合不同索引更新策略的长处,将不同索引更新策略混合以形成更高效的方法。
## Solr
搜索总体上分为两个过程**索引**和**搜索**.

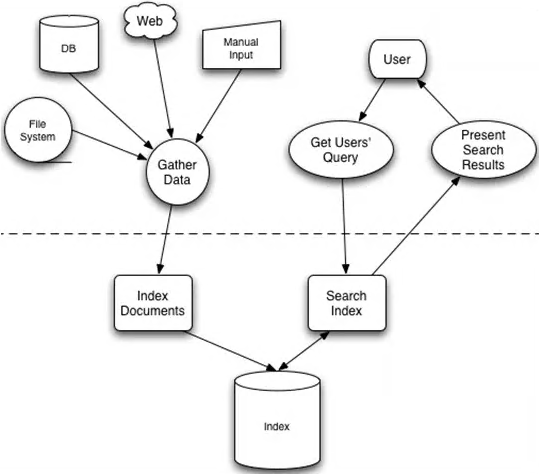
### 索引Indexing
Solr/Lucene采用的是反向索引方式,即从关键词到文档的映射过程。
通过构建关键词和文档之间的关系,在查询关键词的过程中能够快速定位文档位置。索引创建步骤:
* 索引文档词条化(文档Document — 词汇单元Token)
把原始待索引文档内容交给**分词组件(Tokenizer)**,分词组件通过Tokenize过程将文档分解为词汇单元(Token)。
* 语言分析再处理(词汇单元Token —词Term)
此过程是**语言处理组件(Linguistic Processor)**对词汇单元Token的再处理工作,通常是根据不同的语种来进行相应的特性处理,如英语语种会进行的操作有:转为小写Lowercase,单词缩为词根形式stemming,单词转变为词根形式Lemmatization等。
词汇单元Token经过此过程处理后得到**词Term**
* 倒排索引构建索引库
此过程会由**索引组件(Indexer)**将上一步得到的词Term与文档Document之间建立索引关系,从而成型索引库,在这个过程中索引组件会对所有词进行创建词典,排序,和合并相同词等操作,从而保证可检索词的唯一性。
索引库中包含了以下几列:词Term、文档频率Document Frequency、文档中还会拥有文档ID DocumentID、频率Frequency。其中,词term即为构建索引库后要检索的关键词,而它对应的文档频率则表明这个词在多少篇文档中出现了。文档中的文档ID用来和词连接,从而能根据词索引到文档,而频率则说明了,所搜索的词在该文档中出现的次数。
### 搜索Search
搜索是面向用户接口的主要操作,对检索的处理是搜索技术是否能够达到预期效果的重要一步。
我们在构建索引时,将文档切分为Term,那么当我们要根据关键词或者语句进行检索时,怎么通过语句来寻找Term,再通过Term来找到对应的文档呢?
反过来想,根据面向文档的思想,其实用户界面输入的关键词也是一篇文档,那么当我们使用构建索引的操作对关键词进行分词构建索引之后,通过这些索引去搜索匹配索引库中的索引,就可以找到相对应的结果了。
而匹配搜索之后我们需要根据关键词和各文档之间的相关性进行排序,这时候之前对关键词构建的索引又派上用场,这里我们就可以使用**空间向量模型算法**来评价文档结果集中的文档的索引和关键词索引之间的相关性了。
这个过程,就是判断关键词Term对文档的重要性,称计算词的权重TermWeight。
#### 计算权重TermWeight
影响一个词Term在一篇文档中的重要性主要有两个因素:
* Term Frequency,TF:即此词在此文档中出现了多少次,TF越大,此词越重要;
* Document Frequency,DF:即有多少文档包含此词,DF越大,此词越不重要。
$$
w_{t,d}={tf}_{t,d}\times\log{\frac{n}{{df}_t}}
$$
其中
w_{t,d}=the weight of the term **t** in document **d**;
{tf}_{t,d}=frequency of term **t** in document **d**;
$n$=total number of documents;
{df}_t=the number of documents that contain term **t**.
$$
score(q,d)=\frac{{\vec V_q}\cdot{\vec V_d}}{{\left|\vec V_q\right|}{\left|\vec V_d\right|}}=\frac{\sum_{i=1}^{n} w_{i,q} w_{i,d}}{\sqrt{\sum_{i=1}^n w_{i,q}^2} \sqrt{\sum_{i=1}^n w_{i,d}^2}}
$$


上面是一个简单而典型的计算权重公式,实际情况可能不同。
#### 向量空间模型VSM算法
判断Term之间的关系从而得到文档相关性的过程,把文档看做一系列Term,通过和关键词文档的Term的计算,每一个词都获得一个权重,通过空间向量模型算法,根据这些权重为不同词与文档的相关性计算打分。
### SolrHome
`server/solr`是一个完整的SolrHome,安装好Solr直接启动时它是主目录,但是Solr给出的一些示例会更改主目录,比如,使用`bin/solr start -e cloud`启动时,主目录是`example/cloud`.
SolrHome包含重要的配置信息,并且是Solr存储索引的地方,SolrHome中包含SolrCore。在独立模式下与在SolrCloud模式下运行Solr时,SolrHome布局有所不同。
**独立模式**
```
<solr-home-directory>/
solr.xml
core_name1/
core.properties
conf/
solrconfig.xml
managed-schema
data/
core_name2/
core.properties
conf/
solrconfig.xml
managed-schema
data/
```
**SolrCloud 模式**
```
<solr-home-directory>/
solr.xml
core_name1/
core.properties
data/
core_name2/
core.properties
data/
```
### Solr 配置文件
* solr.xml: Solr服务器实例的配置;
* SolrCore
+ core.prpperties: 每个SolrCore的配置,如名称、所属集合、模式的位置等;
+ solrconfig.xml: 高级行为,如可以为数据目录指定备用位置;
+ managed-schema: 描述Solr索引的文档,将文档定义为字段的集合,可以定义字段、字段类型、字段类型的处理方案(分词存储等);
+ data/: 包含索引文件。
注意Cloud模式下,SolrCore中不包括conf目录,该模式下,core配置文件存储在ZooKeeper中,在集群中共享。
## Solr 安装
在windows上安装solr7.4步骤。
### 下载安装
在apache官网上下载solr安装文件《solr-7.4.0.zip》,
`http://archive.apache.org/dist/lucene/solr/7.4.0/`
sha1: `f63157ae606a081a48513d5d9ae0a5d0d9741ce2`
解压缩到安装目录下: `D:\Solr74`
### 配置
#### 环境变量
在bin目录下找到《solr.in.cmd》文件,文件中的所有内容都是注释掉的,在文件的相关位置添加下面几个环境变量:
```
set SOLR_JAVA_HOME=D:/jdk8
set SOLR_HOME=D:/var/SolrHome
set SOLR_LOGS_DIR=D:/var/SolrHome/logs
```
#### SolrHome
创建上面选定的SolrHome目录,在其中创建《solr.xml》文件,内容如下:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<solr>
</solr>
```
目录`Solr74/server/solr`下有一系列示例文件,可以从这里复制一个solr.xml文件过来,solr.xml文件中默认的配置都是部署SolrCloud时才用到的。
### 启动
运行下面的命令启动、查看、停止Solr服务器。
```
D:\Solr74\bin>solr.cmd start
D:\Solr74\bin>solr.cmd status
D:\Solr74\bin>solr.cmd stop -p 8983
```
注意关闭时需要指定端口号。
另外用于Windows的solr.cmd脚本中有一个bug,file:协议后边少了三个斜杠,导致启动时报出关于log4j2.xml文件的异常,解决办法很简单,只有将solr.cmd文件中的所有"file:"替换为"file:///"即可。
> URI的规范写法是这样的:
>
> scheme://user:password@host:port/path?k1=v1&k2=v2#fragment
>
> 但是对于file来说没有host等主机、用户信息,所有就出现三个斜杠了:
>
> file:///D:/var/SolrHome/logs
启动之后,可以通过下面的url访问solr控制台:
`http://localhost:8983/solr`
### 创建SolrCore
执行命令`solr.cmd create -c myCore`会在SolrHome目录下创建一个solrCore,配置文件是从Solr提供的默认配置集中复制的.
`D:\var\SolrHome\myCore`
`D:\Solr74\server\solr\configsets\_default\conf`
### ik中文分词
下载《ik-analyzer-7.4.0.jar》文件,
```xml
<!-- Maven仓库地址 -->
<dependency>
<groupId>com.github.magese</groupId>
<artifactId>ik-analyzer</artifactId>
<version>7.4.0</version>
</dependency>
```
将下载的jar放到`Solr74\server\solr-webapp\webapp\WEB-INF\lib`目录下.
将下面五个文件放到`Solr74\server\solr-webapp\webapp\WEB-INF\classes`下:
* IKAnalyzer.cfg.xml
* ext.dic
* stopword.dic
* ik.conf
* dynamicdic.txt
> github上ik-analyzer-solr7工程中有上面五个文件的样例及ik使用说明。
>
> `https://github.com/magese/ik-analyzer-solr7`
这样Solr服务器就增加ik中文分词器了,还要在想使用ik的SolrCore中配置使用:
在新建的SolrCore下找到配置文件`var\SolrHome\myCore\conf\managed-schema`,在其中增加下面的配置,它定义了一个字段类型`text_ik`,并配置这个字段类型通过ik来进行分词索引及查询.
```xml
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
```
现在重启Solr服务,可以在控制台上测试ik分词器了。
根据业务需要还可以在managed-schema文件中配置text_ik类型的字段。
### SolrJ
#### 索引
```java
String solrUrl = "http://localhost:8983/solr/myCore";
SolrClient client = new HttpSolrClient.Builder(solrUrl)
.withConnectionTimeout(10000)
.withSocketTimeout(60000)
.build();
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", UUID.randomUUID().toString());
doc.addField("content", "这几天心里颇不宁静。今晚在院子里坐着乘凉,忽然想起日日走过的荷塘,在这满月的光里,总该另有一番样子吧...");
client.add(doc);
client.commit();
```
#### 查询
```java
SolrClient client = ...;
Map<String, String> queryParam = new HashMap<String, String>();
queryParam.put("q", "*:*");
// queryParam.put("fl", "id, content");
queryParam.put("sort", "id asc");
SolrParams query = new MapSolrParams(queryParam);
QueryResponse response = client.query(query);
SolrDocumentList docs = response.getResults();
for (SolrDocument doc: docs) {
Collection<String> names = doc.getFieldNames();
String docStr = "";
for (String k : names) {
String v = doc.getFirstValue(k).toString();
docStr = docStr + k + " = " + v + ", ";
}
System.out.println(docStr);
}
```
#### 删除
```java
SolrClient client = ...;
UpdateResponse response = client.deleteById("ce077e3f-05ce-41be-94d6-d393fa95fdb7");
client.commit();
```
## SolrCloud安装
### 准备zookeeper集群
#### 安装
下载zookeeper安装包,并解压缩到安装目录下,共解压三份:
`D:\zookeeper\zk1`,`D:\zookeeper\zk2`,`D:\zookeeper\zk3`。
在`D:\zookeeper\zk1\conf`中创建配置文件`zoo.cfg`,内容如下:
```properties
tickTime=2000
initLimit=10
syncLimit=5
dataDir=D:\\var\\zkData\\data1
dataLogDir=D:\\var\\zkData\\log1
clientPort=2181
server.1=127.0.0.1:2881:3881
server.2=127.0.0.1:2882:3882
server.3=127.0.0.1:2883:3883
```
conf目录下有该配置文件的样例。
同样在`D:\zookeeper\zk2\conf`中创建配置文件`zoo.cfg`,数据目录改为data2,日志目录改为log2,端口改为2182.
同样在`D:\zookeeper\zk3\conf`中创建配置文件`zoo.cfg`,数据目录改为data3,日志目录改为log3,端口改为2183.
注意这三份配置文件中,要指定各个zk节点的数据目录、日志目录、客户端连接端口各不相同,而`server.x=...`必须都相同,它们配置了集群中各节点所在的服务器,各节点同步数据的端口,各节点选举的端口,其中`x`指的是各个节点的编号。
下面在各节点的数据目录中分别声明自己的节点编号:
* 在`D:\var\zkData\data1`目录下创建文件《myid》内容为一个字符:"1";
* 在`D:\var\zkData\data2`目录下创建文件《myid》内容为一个字符:"2";
* 在`D:\var\zkData\data3`目录下创建文件《myid》内容为一个字符:"3";
#### 启动
依次执行下面三条命令,启动三个节点:
```
D:\zookeeper\zk1\bin\zkServer.cmd
D:\zookeeper\zk2\bin\zkServer.cmd
D:\zookeeper\zk3\bin\zkServer.cmd
```
可能需要在三个命令行窗口中执行,在全部节点启动成功之前,集群中先起来的节点无法连接到兄弟节点,会报错,没有关系。`Ctrl + C`或者关闭命令行窗口,就会关闭节点。
也可以写一个批处理文件,内容如下,运行该文件即可启动集群,关闭运行窗口即关闭集群。
```
start /b D:\zookeeper\zk1\bin\zkServer.cmd
start /b D:\zookeeper\zk2\bin\zkServer.cmd
start /b D:\zookeeper\zk3\bin\zkServer.cmd
```
### 安装SolrCloud
#### 安装配置
将《solr-7.4.0.zip》解压四份,分别放在`D:\SolrCloud\Solr01`,`D:\SolrCloud\Solr02`,`D:\SolrCloud\Solr03`,`D:\SolrCloud\Solr04`,四个目录下。
##### solr.in.cmd
修改`SolrCloud\Solr01\bin\solr.in.cmd`文件,增加下面内容:
```
set SOLR_JAVA_HOME=D:/jdk8
set ZK_HOST=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183/solr
set SOLR_HOME=D:/var/SolrHome01
set SOLR_LOGS_DIR=D:/var/SolrHome01/logs
set SOLR_PORT=8183
```
同样修改`Solr02\bin\solr.in.cmd`,`Solr03\bin\solr.in.cmd`,`Solr04\bin\solr.in.cmd`,注意SolrHome01依次改为`SolrHome02`,`SolrHome03`,`SolrHome04`,端口号依次改为8283,8383,8483。
##### jetty-http.xml
修改`SolrCloud\Solr01\server\etc\jetty-http.xml`文件,找到`/Configure/Call/Arg/New/Set[@name='port']/Property`标签,将default值修改为8183,同样修改其它本个jetty服务器的端口依次为8283,8383,8483。
配置各节点jetty服务器的运行端口
##### IKAnalyzer
添加ik分词器,方法与单机版的Solr相同,向`SolrCloud\Solr01\server\solr-webapp\webapp\WEB-INF\lib\`下添加`ik-analyzer-7.4.0.jar`,向`SolrCloud\Solr01\server\solr-webapp\webapp\WEB-INF\classes\`添加ik有五个配置文件,即可,四个Solr节点都要添加。
##### SolrHome
依据solr.in.cmd中配置的位置准备四个SolrHome,分别为`D:\var\SolrHome01`,`D:\var\SolrHome02`,`D:\var\SolrHome03`,`D:\var\SolrHome04`,每个SolrHome中都要有一个《solr.xml》文件,该文件可以复制`SolrCloud\Solr01\server\solr\solr.xml`,注意修改`hostPort`依次为8183,8283,8383,8483。
##### up_conf_to_zk
SolrCloud需要在zk上共享SolrCore配置,所以准备一份完整的SolrCore配置,可以使用Solr给的默认配置`SolrCloud\Solr01\server\solr\configsets\_default\conf`,注意也要添加使用ik分词的fieldType,所以可以直接把单机版的myCore的配置文件复制一份出来放到`D:\var\SolrConf2zk`。
启动zookeeper集群,现在把准备好的配置文件上传到zookeeper,进入随便一个Solr服务器的`server\scripts\cloud-scripts`目录下,这里有Solr为我们准备好的脚本《zkcli.bat》,执行下面命令上传:
```
zkcli.bat -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183/solr -cmd upconfig -confdir D:/var/SolrConf2zk/conf -confname myCollection01
```
注意:
* zkhost后面添加`/solr`,这与`solr.in.cmd`文件中ZK_HOST配置项的值一致,当ZooKeeper还管理其它集群时,互相之间的配置不会混淆,本SolrCloud的配置都在ZooKeeper的/solr节点下。
* `-cmd upconfig`表示本次要执行的操作是上传配置。
* `-confdir`后面是要上传的配置文件的位置。
* `-confname`为本次上传的配置文件取个名称,可以上传多分配置文件,取不同的名称,SolrCloud创建collection时通过这个名称引用配置。
#### 启动
依次执行下面四条命令,启动四个Solr节点:
```
D:\SolrCloud\Solr01\bin\solr.cmd start -p 8183
D:\SolrCloud\Solr02\bin\solr.cmd start -p 8283
D:\SolrCloud\Solr03\bin\solr.cmd start -p 8383
D:\SolrCloud\Solr04\bin\solr.cmd start -p 8483
```
启动之后可以通过分别通过下面的url访问各节点控制台:
```
http://localhost:8183/solr
http://localhost:8283/solr
http://localhost:8383/solr
http://localhost:8483/solr
```
此时控制台上会在Cloud选项,里边没有collection.
通过下面命令查看节点状态:
`D:\SolrCloud\Solr01\bin\solr.cmd status -p 8183`,查看任意一个节点的状态,都可以看到集群的其它所有节点。
如果要关闭集群,执行下面命令,依次关闭四个节点:
```
D:\SolrCloud\Solr01\bin\solr.cmd stop -p 8183
D:\SolrCloud\Solr02\bin\solr.cmd stop -p 8283
D:\SolrCloud\Solr03\bin\solr.cmd stop -p 8383
D:\SolrCloud\Solr04\bin\solr.cmd stop -p 8483
```
#### 创建collection
可以在任意一个节点的控制台上创建collection,注意选择使用配置文件,也可以通过浏览器访问下面的url创建:
```
http://localhost:8183/solr/admin/collections?action=CREATE&name=myCollection&numShards=2&replicationFactor=2&collection.configName=myCollection01
```
最后一个参数指定了要使用`myCollection01`配置文件,这份配置文件在ZooKeeper上,`myCollection01`是向ZooKeeper上传配置文件时指定的名称。
如果创建collection时不指定collection.configName选项,则SolrCloud会使用Solr提供的默认配置,即任一节点`SolrCloud\Solr0x\server\solr\configsets\_default\conf`目录下的文件,同时,会把这些默认配置上传到ZooKeeper。
返回类似下面的json数据,表示创建完成,在控制台可以看到myCollection的逻辑结构。
```json
{
"responseHeader": {
"status": 0,
"QTime": 10623
},
"success": {
"localhost:8283_solr": {
"responseHeader": {
"status": 0,
"QTime": 8376
},
"core": "myCollection_shard1_replica_n1"
},
"localhost:8383_solr": {
"responseHeader": {
"status": 0,
"QTime": 8599
},
"core": "myCollection_shard1_replica_n2"
},
"localhost:8483_solr": {
"responseHeader": {
"status": 0,
"QTime": 9011
},
"core": "myCollection_shard2_replica_n6"
},
"localhost:8183_solr": {
"responseHeader": {
"status": 0,
"QTime": 9061
},
"core": "myCollection_shard2_replica_n4"
}
}
}
```
到此,SolrCloud安装配置完成,可以使用了。
Happy searching!
## DataImportHandler
很多应用的待索引数据都是从其它数据源获取的,如关系数据库,如基于HTTP的RSS和ATOM种子数据源,如eMail仓库,再如另一个搜索引擎。数据导入处理器(Data Import Handler, DIH)提供了从其它数据源导入数据并建立索引的机制。
DIH分两种,
* 全量导入(full-import),一次性导入全部数据。
* 增量导入(delta-import),当数据源中数据有变化时导入变化的数据。
使用DIH,须在solrconfig.xml文件中添加DataImportHandler,如下:
```xml
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
```
添加`conf/data-config.xml`配置文件,配置数据源、实体、处理器、字段映射等信息。
下面是一个增量导入的data-config.xml配置内容:
```xml
<?xml version="1.0" encoding="utf-8"?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.219.136:3306/demo"
user="xxx" password="xxx"/>
<document>
<entity name="test" pk="id"
query="select * from test"
deltaImportQuery="select * from test where id='${dih.delta.id}'"
deltaQuery="select id from test where last_modified > '${dih.last_index_time}'">
<field column="id" name="id"/>
<field column="cat" name="cat"/>
<field column="name" name="name"/>
<field column="demo" name="demo"/>
<field column="CONTENT" name="content" clob="true" />
</entity>
</document>
</dataConfig>
```
在全量导入模式下,有query属性即可,使用query属性指定的SQL一次查出所有数据。
在增量导入模式下,必须配置deltaImportQuery和deltaQuery,
增量导入模式下,数据库表中应该有个时间类型的字段,Solr先执行deltaQuery,查出所有已变化数据的id,然后执行deltaImportQuery获取增量数据。
Solr会在`conf/dataimport.properties`文件内记录最后一次导入的时间,deltaQuery要通过`${dih.last_index_time}`来引用这个时间,类似地,deltaImportQuery要通过`${dih.delta.id}`来引用增量数据的id。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号