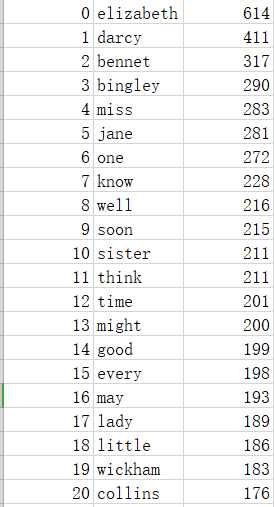
复合数据类型,英文词频统计
本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
一、列表,元组,字典,集合分别如何增删改查及遍历
1、列表
•增
list1=['空无之钥','雨后誓言','永暮双狼','犹大誓约','阿芙洛狄忒'] print(list1) #在列表末尾添加新的对象 list1.append('鲜血之舞') print(list1) #将对象插入列表 list1.insert(1,'幽色咏叹调') print(list1) list2=list(range(4)) #在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list1.extend(list2) print(list1)

•删
list1=['空无之钥',1,'雨后誓言','永暮双狼','犹大誓约',1,'阿芙洛狄忒'] print(list1) #移除列表中的一个元素(默认最后一个元素) list1.pop() print(list1) list1.pop(2) print(list1) #移除列表中某个值的第一个匹配项 list1.remove(1) print(list1) #删除列表下标为1的值 del list1[1] print(list1) #删除列表 del list1

•改
list1=['空无之钥',1,'雨后誓言','永暮双狼','犹大誓约',1,'阿芙洛狄忒'] print(list1) #修改列表下标为1的元素 list1[1]='草履虫' print(list1)

•查
list1=['空无之钥',1,'雨后誓言','永暮双狼','犹大誓约',1,'阿芙洛狄忒'] print(list1) #输出列表下标为2的元素 print(list1[2]) #输出右侧倒数第三个元素 print(list1[-3]) #输出下标为2到4的元素 print(list1[2:5]) #输出从第三个元素开始后的所有元素 print(list1[2:])

2、元组
元组与列表类似,不同之处在于元组的元素不能修改;
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用;
元组中的元素值不允许修改,但可以对元组进行连接组合。
tup1 = (50) # 不加逗号,类型为整型 print(type(tup1))
tup1 = (50,) # 加上逗号,类型为元组 print(type(tup1))
tup1=tuple(range(4)) tup2='a','b','c','d' print('元组1:',tup1) print('元组2:',tup2) #输出元组1中下标为1的元素 print('tup1[1]:',tup1[1]) #输出元组1中元素最小值 print('元组1中元素最小值:',min(tup1)) #输出元组2中元素最大值 print('元组2中元素最大值:',max(tup2)) #元组连接组合 tup3=tup1+tup2 print('组合后的元组:',tup3)
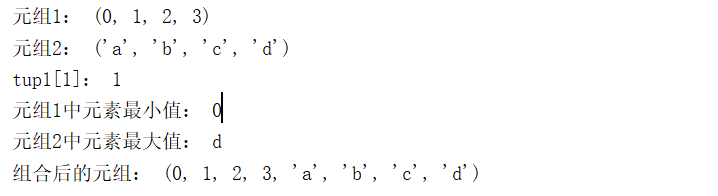
3、字典
字典是另一种可变容器模型,且可存储任意类型对象。
dict1={'空无之钥':'律化娜','雨后誓言':'芽衣','永暮双狼':'浮华','犹大誓约':'德丽莎'}
print(dict1)
#新增键值对
dict1['阿芙洛狄忒']="丽塔"
print(dict1)
#删除单一元素,通过key来指定删除,通过pop()或del方法
dict1.pop('犹大誓约')
print(dict1)
del dict1['雨后誓言']
print(dict1)
#修改,值可以取任何数据类型,但键必须是不可变的
dict1['空无之钥']='草履虫'
print(dict1)

4、集合
集合(set)是一个无序的不重复元素序列,可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
set1={'空无之钥','雨后誓言','永暮双狼','犹大誓约','阿芙洛狄忒'}
print(type(set1))
print(set1)
#新增元素,若元素已存在,则不进行任何操作
set1.add('鲜血之舞')
print(set1)
#新增元素,update(),参数可以是列表,元组,字典等
set1.update(['卡莲','八重樱'])
print(set1)
#删除元素
#remove()方法,如果元素不存在,则会发生错误
set1.remove('八重樱')
print(set1)
#discard()方法,元素不存在也不会发生错误
set1.discard('八重樱')
print(set1)

二、总结列表,元组,字典,集合的联系与区别。
列表list用[]表示,有序序列,元素可变,可重复,可通过下标索引查找,如list[1];
元组tup用()表示,有序序列,元素不可变,可重复,可通过下标索引查找,如tup[0];
字典dict用{}表示,无序序列,元素中键不可重复,值可以取任何数据类型,可以重复,元素以键值对的方式存储,一般通过键(key)查找,如dict[key];
集合set用{}表示,无序序列,元素可变,不可重复,不能通过下标索引查找。
三.词频统计
from nltk.corpus import stopwords import re import pandas as pd #读取文本 def get_text(file): #打开文件,并将所文本转换成小写 fp=open(file,'r',encoding='utf-8').read().lower() #正则表达式移除文本中的数字 fp = re.sub(r'[1-9]\d*','',fp) sep = '-,.?!:\"\'\n' #将sep中的符号替换成空格 for i in sep: fp = fp.replace(i,' ') return fp #词频统计 def get_wordsort(fp): #分隔单词 words_list = fp.split() stop_words = {'mr','could','would','said','mrs','much','must','though','never'} #获取英文停用词 words = stopwords.words('english') #移除停用词 words_set = set(words_list)-set(words)-stop_words words_dict = {} #将单词存入字典 for i in words_set: words_dict[i] = words_list.count(i) #排序 words_sort = sorted(words_dict.items(),key=lambda x:x[1],reverse=True) #输出词频top20 for i in range(20): print(words_sort[i]) return words_sort if __name__ == '__main__': fp = get_text('Pride and Prejudice1.txt') words_sort = get_wordsort(fp) #将排序后的单词列表保存为CSV文件 pd.DataFrame(data=words_sort).to_csv('top20.csv',encoding='utf-8')