Gradient descent for neural networks
还是针对之前概览中的这个网络,并且考虑它做的是binary classification;
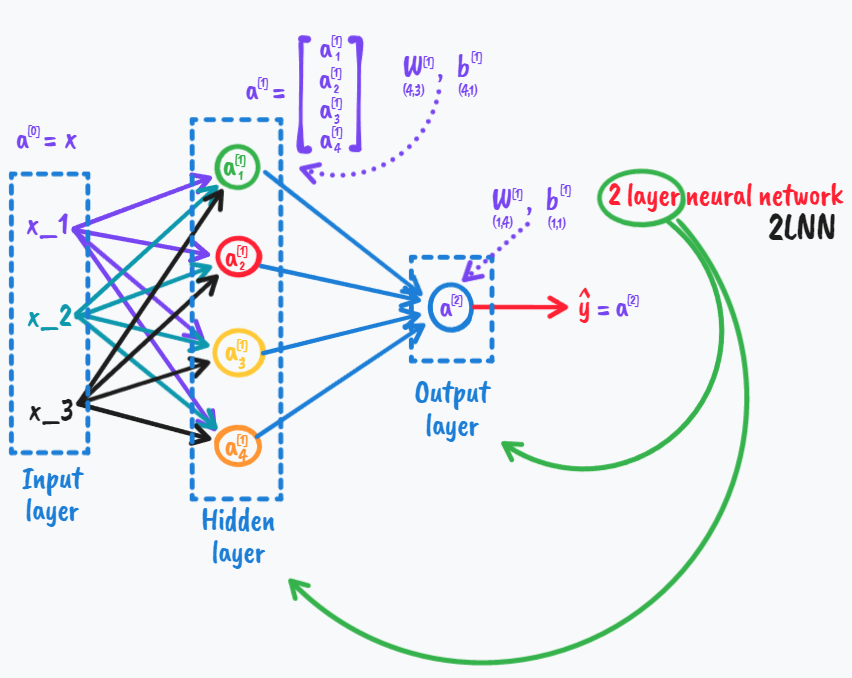
则我们现在来讨论其中的梯度下降方法,
\[Parameters(参数):
\mathop{W^{[1]}}\limits_{(n^{[1]},n^{[0]})},
\mathop{b^{[1]}}\limits_{(n^{[1]},1)},
\mathop{W^{[2]}}\limits_{(n^{[2]},n^{[1]})},
\mathop{b^{[2]}}\limits_{(n^{[2]},1)}
\\n_x=n^{[0]},n^{[1]},n^{[2]}=1
\\Cost\;function:J(W^{[1]},b^{[1]},W^{[2]},b^{[2]})
=\frac{1}{m}\sum^{n}_{i=1}\mathcal{L}(\mathop{\hat{y}}\limits_{\uparrow_{a^{[2]}}},y)
\\Gradient\;descent:
\\Repeat:Compute\;predictions\;(\hat{y}^{(i)},i=1,\cdots ,m)\\
\begin{array}{c}
dW^{[1]} = \frac{ \partial J}{ \partial W^{[1]}},
db^{[1]} = \frac{ \partial J}{ \partial b^{[1]}},\\
dW^{[2]} = \frac{ \partial J}{ \partial W^{[2]}},
db^{[2]} = \frac{ \partial J}{ \partial b^{[2]}},\\
W^{[1]}: = W^{[1]}-\alpha dW^{[1]}\\
b^{[1]}: = b^{[1]}-\alpha db^{[1]}\\
W^{[2]}: = W^{[2]}-\alpha dW^{[2]}\\
b^{[2]}: = b^{[2]}-\alpha db^{[2]}\\
\end{array}
\\(注意:\alpha是学习率,[:=]也可以写成[=],只不过为了更好表示迭代)
\]
那么问题现在显而易见:我们如何去求偏导数呢?
\[Formal\;propagation:\\
Z^{[1]}=W^{[1]}X+b^{[1]}\\
A^{[1]}=g^{[1]}(Z^{[1]})\\
Z^{[2]}=W^{[2]}A^{[1]}+b^{[2]}\\
A^{[2]}=g^{[2]}(Z^{[2]})=\sigma(Z^{[2]})
\]
\[Back\;propagation:\\
dZ^{[2]}=A^{[2]}-Y \quad其中Y=[y^{[1]},y^{[2]},\cdots,y^{[m]}]\\
dW^{[2]}=\frac{1}{m}dZ^{[2]}A^{[1]T}\\
db^{[2]}=\frac{1}{m}np.sum(dZ^{[1]},axis=1,\mathop{keepdims=True}\limits^{to\;maintain\;db^{[2]}\;isn't\;(n^{[2]},)\;but\;(n^{[2]},1)})\\
dZ^{[1]}=\mathop{W^{[2]T}dZ^{[2]}}\limits_{(n^{[1]},m)}*\mathop{g^{[1]'}(Z^{[1]})}\limits_{(n^{[1]},m)}\quad*是对应元素相乘\\
dW^{[1]}=\frac{1}{m}dZ^{[1]}X^T\\
db^{[1]}=\frac{1}{m}np.sum(dZ^{[1]},axis=1,\mathop{keepdims=True}\limits^{to\;maintain\;db^{[1]}\;isn't\;(n^{[1]},)\;but\;(n^{[1]},1)})
\]
下面来直观理解一下这个反向传播过程(通过逻辑斯蒂回归);
\[\begin{array}{c}
\begin{align}
x_\searrow \\
\omega\rightarrow\\
b^\nearrow
\end{align}
z = \omega^Tx+b\rightarrow a = \sigma(z)\rightarrow\mathcal{L} (a,y)\\
\mathcal{L} (a,y)=-yloga-(1-y)log(1-a)
\end{array}
\]
(注意:我们下面的dz,da等等d开头的记法都是指导数的意思可以理解为最终那个损失函数对d后面的变量取导数)
\[da=\frac{\partial\mathcal{L} (a,y)}{\partial a}=-\frac{y}{a}+\frac{1-y}{1-a}
\]
\[dz=da\cdot g'(z)\quad(这里的g(z)=\sigma(z))\\
原因很简单:\\
\frac{\partial\mathcal{L} (a,y)}{\partial z}=\frac{\partial\mathcal{L} (a,y)}{\partial a}\frac{\partial a}{\partial z}\\
其中dz=\frac{\partial\mathcal{L} (a,y)}{\partial z}\\
da=\frac{\partial\mathcal{L} (a,y)}{\partial a}\\
g'(z)=\frac{\partial a}{\partial z}
\]
\[dw=dz\cdot x\\
db=dz
\]
(这里我们需要回忆一下sigma函数的导数)
\[\begin{align}
g'(z) & = \sigma'(z)
\\ & = (\frac{1}{1+e^{-z} } )'
\\ & = (\frac{1}{1+e^{-z} })(1-\frac{1}{1+e^{-z} })
\\ & = \sigma(z)(1-\sigma(z))
\\ & = a(1-a)
\end{align}
\]
则我们有
\[\begin{align}
dz & = da\cdot g'(z)\\
&= da\cdot a(1-a)\\
&= (-\frac{y}{a}+\frac{1-y}{1-a})\cdot a(1-a)\\
&=(a-1)y+a(1-y)\\
&=a-y\\
&(所以我们往往在把两句合成一句写dz=a-y)
\end{align}
\]
而在神经网络中,我们的反向传播是这样的
\[\begin{array}{c}
\begin{align}
x_\searrow \\
W^{[1]}\rightarrow\\
b^{[1]\nearrow}
\end{align}
z^{[1]} = W^{[1]}x+b^{[1]}\rightarrow a^{[1]} = g(z^{[1]})\rightarrow\\
z^{[2]} = W^{[2]}a^{[1]}+b^{[2]}\rightarrow a^{[2]} = \sigma(z^{[2]})\rightarrow
\mathcal{L} (a^{[2]},y)\\
\end{array}
\]
此时我们有
\[dz^{[2]}=a^{[2]}-y\\
dW^{[2]}=dz^{[2]}a^{[1]T}\quad(这一步与dw=dz\cdot x非常像)\\
\]
这里自己理解一下
\[\begin{align}
dW^{[2]} & = \frac{\partial \mathcal{L}}{\partial W^{[2]} }\\
& = \frac{\partial \mathcal{L}}{\partial z^{[2]} }\frac{\partial z^{[2]}}{\partial W^{[2]} }\\
&= dz^{[2]}\frac{\partial z^{[2]}}{\partial W^{[2]} }
\end{align}
\]
其中值得我们可以思考一下的细节是下面这个应该是什么
\[\begin{align}
\frac{\partial z^{[2]}}{\partial W^{[2]} }
\end{align}
\]
\[我们用一个简单的例子来说明\\
假如第二层有四个节点,而第一层有三个节点:\\
\mathop{z^{[2]}}\limits_{(4,1)} =
\mathop{W^{[2]}}\limits_{(4,3)}
\mathop{a^{[1]}}\limits_{(3,1)}
+
\mathop{b^{[2]}}\limits_{(4,1)}\\
则有
\]
\[\begin{align}
\frac{\mathop{\partial z^{[2]}}\limits_{(4,1)}}{\mathop{\partial W^{[2]}}\limits_{(4,3)}}
&=\frac{\partial\begin{bmatrix}
z_1\\
z_2\\
z_3\\
z_4
\end{bmatrix}}
{\partial\begin{bmatrix}
w_{11}&w_{12}&w_{13}\\
w_{21}&w_{22}&w_{23}\\
w_{31}&w_{32}&w_{33}\\
w_{41}&w_{42}&w_{43}
\end{bmatrix}} \\
&=\frac{\partial\begin{bmatrix}
w_{11}a_1+w_{12}a_2+w_{13}a_3+b_1\\
w_{21}a_1+w_{22}a_2+w_{23}a_3+b_1\\
w_{31}a_1+w_{32}a_2+w_{33}a_3+b_1\\
w_{41}a_1+w_{42}a_2+w_{43}a_3+b_1
\end{bmatrix}}
{\partial\begin{bmatrix}
w_{11}&w_{12}&w_{13}\\
w_{21}&w_{22}&w_{23}\\
w_{31}&w_{32}&w_{33}\\
w_{41}&w_{42}&w_{43}
\end{bmatrix}} \\
&=\begin{bmatrix}
a_{1}&a_{2}&a_{3}\\
a_{1}&a_{2}&a_{3}\\
a_{1}&a_{2}&a_{3}\\
a_{1}&a_{2}&a_{3}
\end{bmatrix}\\
&=\begin{bmatrix}
a_{1}&a_{2}&a_{3}\\
\end{bmatrix}\\
&=a^{[2]T}
\end{align}
\]
(其实上面的式子只是根据自己理解写出来的,因为查了一系列资料都没有说矩阵对矩阵求偏导的知识)
至此我们完成了反向传播的一半:
\[dz^{[2]}=a^{[2]}-y\\
dW^{[2]}=dz^{[2]}a^{[1]T}\\
db^{[2]}=dz^{[2]}\\
\]
我们再来进行后半部分,记住下面的这个链
\[\begin{array}{c}
\begin{align}
x_\searrow \\
W^{[1]}\rightarrow\\
b^{[1]\nearrow}
\end{align}
z^{[1]} = W^{[1]}x+b^{[1]}\rightarrow a^{[1]} = g(z^{[1]})\rightarrow\\
z^{[2]} = W^{[2]}a^{[1]}+b^{[2]}\rightarrow a^{[2]} = \sigma(z^{[2]})\rightarrow
\mathcal{L} (a^{[2]},y)\\
\end{array}
\]
则有
\[\begin{align}
da^{[1]} & = \frac{\partial z^{[2]}}{\partial a^{[1]}}\frac{\partial \mathcal{L}}{\partial z^{[2]}}
\\
&=W^{[2]T}dz^{[2]}\quad
\end{align}
\]
可能有点难以理解为什么两个偏导的位置要反过来,但其实在此之前我们发现几乎所有的对矩阵求偏导后的结果总是符合这样的规律(参考这篇文章:分子及分母布局)(另外也说明一下我们下面几乎都是用分母布局)或者只是稍稍做了broadcast一下而已,更形象的例子是(以前面举得只有一个隐层的网络为例如下)
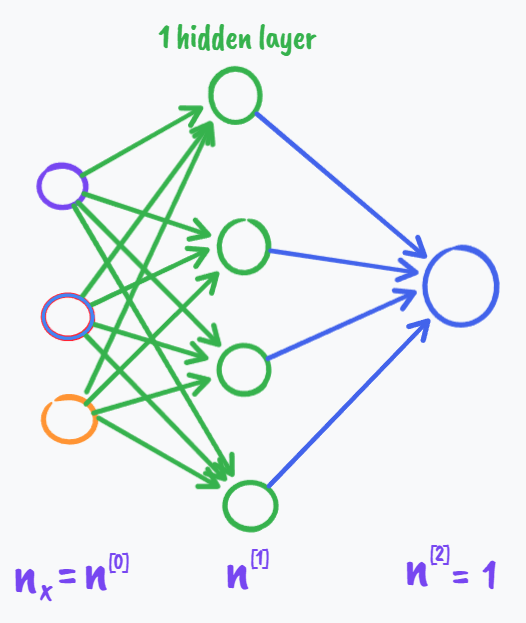
$$
\mathop{dz^{[2]}}_{(1,1)}=
\mathop{a^{[2]}}_{(1,1)}-
\mathop{y}_{(1,1)}\quad(z^{[2]}也是(1,1))\\
\mathop{dW^{[2]}}_{(1,4)}=
\mathop{dz^{[2]}}_{(1,1)}\cdot
\mathop{a^{[1]T}}_{(1,4)}\quad(W^{[2]}也是(1,4)矩阵)\\
\mathop{db^{[2]}}_{(1,1)}
=\mathop{dz^{[2]}}_{(1,1)}\quad(b^{[2]}也是(1,1))
\\
\mathop{da^{[1]}}_{(4,1)}=
\mathop{W^{[2]T}}_{(4,1)}
\mathop{dz^{[2]}}_{(1,1)}\quad(a^{[1]}也是(4,1)矩阵)\\
$$
现在我们知道了一个变量导数的维度总是和变量本身的维度是一样的,接下来我们继续进行反向传播,求dz
\[\begin{align}
dz^{[1]} & = \frac {\partial \mathcal{L}}{\partial z^{[1]}} \\
& = \frac {\partial \mathcal{L}}{\partial a^{[1]}}\frac {\partial a^{[1]}}{\partial z^{[1]}}\\
&=da^{[1]}*\frac {\partial g(z^{[1]})}{\partial z^{[1]}}\\
&=da^{[1]}* {g^{[1]'}}{ (z^{[1]})}\\
\end{align}
\]
注意:这个*号是按元素逐个相乘的意思,因为我们常用的是分母布局,也就很容易了解上面右式中*右边的那个偏导也就是grad,或者说梯度;
\[\mathop{dz^{[1]}}_{(4,1)}
=
\mathop{da^{[1]}}_{(4,1)}
*
\mathop{{g^{[1]'}}{ (z^{[1]})}}_{(4,1)}
\]
而实际应用中我们通常不写出a=……毕竟隐含层我们不太关心,所以可以将上面两步合成一步:
\[\begin{align}
dz^{[1]} & =
da^{[1]}*{g^{[1]'}}{ (z^{[1]})}
\\
&=
W^{[2]T}dz^{[2]}*{g^{[1]'}}{ (z^{[1]})}
\\
\end{align}
\]
更加容易理解的解释是:
\[\begin{align}
\mathop{dz^{[1]} }_{(n^{[1]},1)}
=
\mathop{W^{[2]T} }_{(n^{[1]},n^{[2]})}
\mathop{dz^{[2]} }_{(n^{[2]},1)}
*
\mathop{{g^{[1]'}}{ (z^{[1]})}}\limits_{(n^{[1]},1)}
\\
\end{align}
\]
根据上面的推导,类似地,我们现在可以很快写出最后两步:
\[dW^{[1]}=dz^{[1]}x^T\quad(dW^{[1]}=dz^{[1]}a^{[0]T})\\
db^{[1]}=dz^{[1]}
\]
现在我们很容易整理出六个关键的方程,现在把他们都搁这:
\[\mathop{dz^{[2]}}_{(1,1)}=
\mathop{a^{[2]}}_{(1,1)}-
\mathop{y}_{(1,1)}\\
\mathop{dW^{[2]}}_{(1,4)}=
\mathop{dz^{[2]}}_{(1,1)}\cdot
\mathop{a^{[1]T}}_{(1,4)}\\
\mathop{db^{[2]}}_{(1,1)}
=\mathop{dz^{[2]}}_{(1,1)}
\\
\mathop{dz^{[1]} }_{(4,1)}
=
\mathop{W^{[2]T} }_{(4,1)}
\mathop{dz^{[2]} }_{(1,1)}
*
\mathop{{g^{[1]'}}{ (z^{[1]})}}\limits_{(4,1)}
\\
\mathop{dW^{[1]} }_{(4,3)}
=
\mathop{dz^{[1]} }_{(4,1)}
\mathop{x^T }_{(1,3)}
\\
\mathop{db^{[1]} }_{(4,1)}=\mathop{dz^{[1]} }_{(4,1)}
\]
记得我们之前说过这个网络是针对单样本的,所以现在我们要对整个反向传播向量化,即将多样本的叠加起来,就比如z现在就不再是一个列向量而是一个矩阵了现在(在正向传播中我们用过了这种多样本的向量化Vectorizing across multiple examples);
\[Z^{[1]}=\begin{bmatrix}
\mid & \mid &&\mid \\
z^{[1](1)} & z^{[1](2)} &\cdots &z^{[1](m)}\\
\mid & \mid &&\mid
\end{bmatrix}
_{(n_z\times m)}\\
(n_z个特征值或节点,m个样本)
\]
如这样:
\[Z^{[1]}=W^{[1]}X^{[1]}+b^{[1]}\\
\]
所以对于反向传播,我们也来一次向量化,最终有了开头类似代码的式子:
\[Back\;propagation:\\
dZ^{[2]}=A^{[2]}-Y \\
dW^{[2]}=\frac{1}{m}dZ^{[2]}A^{[1]T}\\
db^{[2]}=\frac{1}{m}np.sum(dZ^{[1]},axis=1,\mathop{keepdims=True})\\
dZ^{[1]}=\mathop{W^{[2]T}dZ^{[2]}}\limits_{(n^{[1]},m)}*\mathop{g^{[1]'}(Z^{[1]})}\limits_{(n^{[1]},m)}\quad*是对应元素相乘\\
dW^{[1]}=\frac{1}{m}dZ^{[1]}X^T\\
db^{[1]}=\frac{1}{m}np.sum(dZ^{[1]},axis=1,\mathop{keepdims=True})
\]
需要注意的小细节有这里的求dW时乘以了1/m,这里稍稍解释一下。原因就是当初定义的损失函数:
\[Cost\;function:J(W^{[1]},b^{[1]},W^{[2]},b^{[2]})
=\frac{1}{m}\sum^{n}_{i=1}\mathcal{L}(\mathop{\hat{y}},y)
\]
现在我们所求的这个dW是相对所有训练样本而言的,就是说它的列数不受Z或X向量化的影响,依然不变;而它的行数只与特征值有关,我们并没有加入更多的特征,所以行数也是不变的:总体而言,多样本时的W的维度还是和单样本时的维度是一样的。
而我们在求和之后要除与平均值,如果看不出这里的向量化后的矩阵相乘后其实相当于求和,可以再举一下上面那个例子
\[\mathop{dz^{[2]}}_{(1,1)}=
\mathop{a^{[2]}}_{(1,1)}-
\mathop{y}_{(1,1)}\\
\mathop{dW^{[2]}}_{(1,4)}=
\mathop{dz^{[2]}}_{(1,1)}\cdot
\mathop{a^{[1]T}}_{(1,4)}\\
\]
向量化之后我们得到了:
\[\mathop{dz^{[2]}}_{(1,m)}=
\mathop{a^{[2]}}_{(1,m)}-
\mathop{y}_{(1,m)}\\
\mathop{dW^{[2]}}_{(1,4)}=
\mathop{dz^{[2]}}_{(1,m)}\cdot
\mathop{a^{[1]T}}_{(m,4)}\\
\]
对于dW的第一个元素(第一列),它的值等于dz中所有的元素线性表出之和,其余的元素也类似;而显然,我们需要的dW是针对单样本的(以后检测和test肯定也是针对个别样本去检测和test),所以要去一个平均值即除以m;而对于db也就更明显了,求和后取平均;而对于dZ因为它本身没有进行过求和,所以我们就无需关心它的平均值。
至此,我们学习完了反向传播(随便一搜我们就很容易知道反向传播对深度学习重新火起来多大的作用,这也几乎是非常精彩的一部分),下面我们继续学习参数的影响,需提一句,我们的W全名是weight,即权重,下面我们学习的便是如何初始化我们的权重参数,即随机初始化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号