Activation functions
Activation functions
基本激活函数
\[\text{We know that the value of sigmoid function must }\\
\text{between 0 and 1. But Andrew said that an activation }\\
\text{almost always works better than the sigmoid function}\\
\text{and it is the hyperbolic tangent function tanh(x).}\\
\]
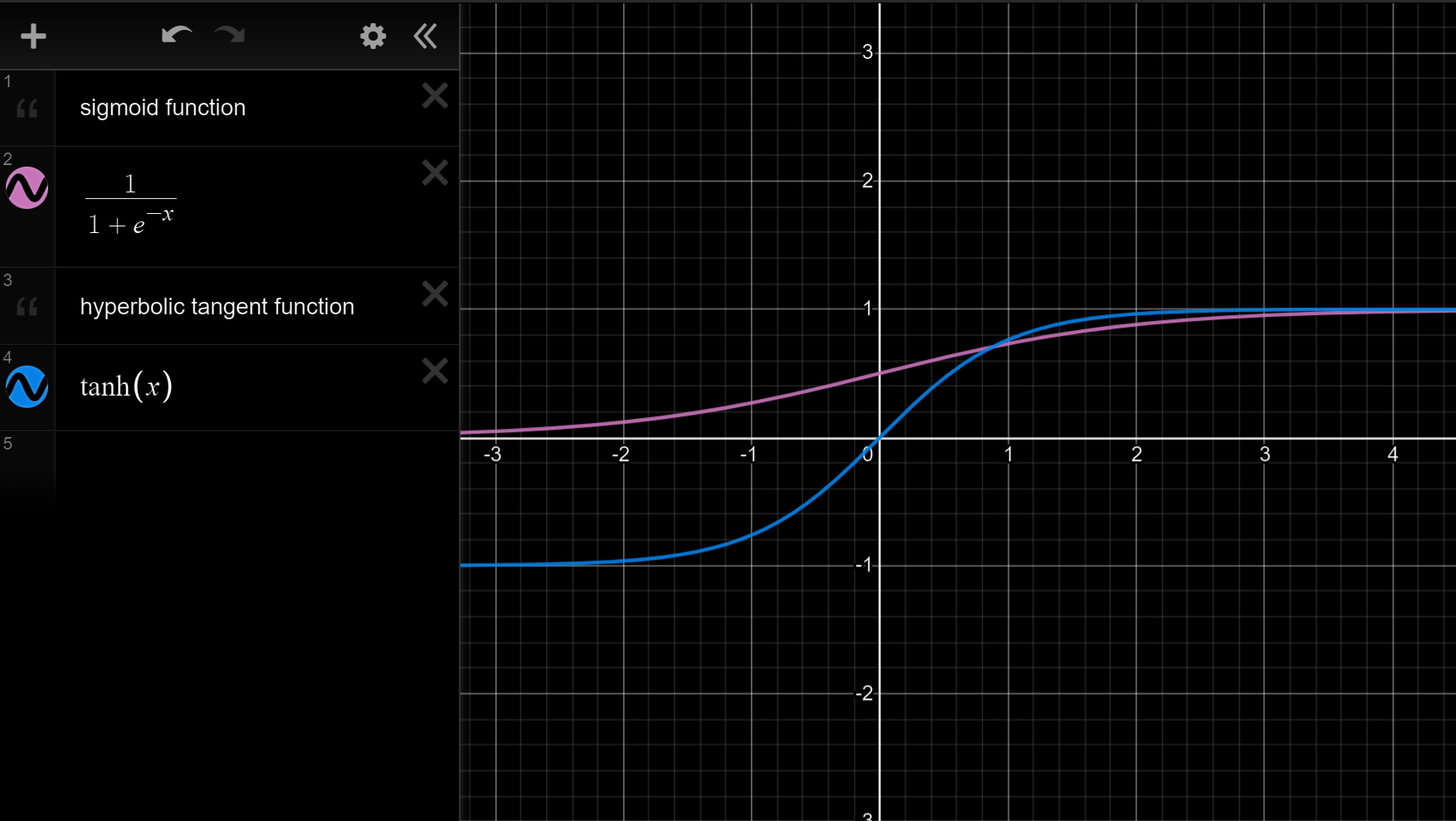 $$
In\;fact,\\
tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}\in(-1,1)\quad x\in\R
$$
$$
In\;fact,\\
tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}\in(-1,1)\quad x\in\R
$$
画上图网站Desmos
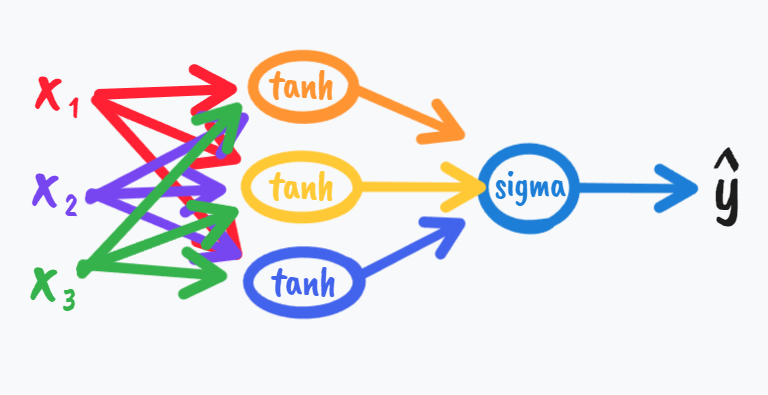
\[一般在我们数据中心化的时候我们往往希望平均值为零,
\\而不是0.5,所以这就决定了我们用tanh的场合可能多于sigma,\\但是如果回到binary\;classification,\\我们就不得不用上sigma了,
\\因为显然\hat{y}\in(0,1)更加合理,我们可以仅在输出层用到sigma,
\\而在隐层都用tanh,比如这样
\]
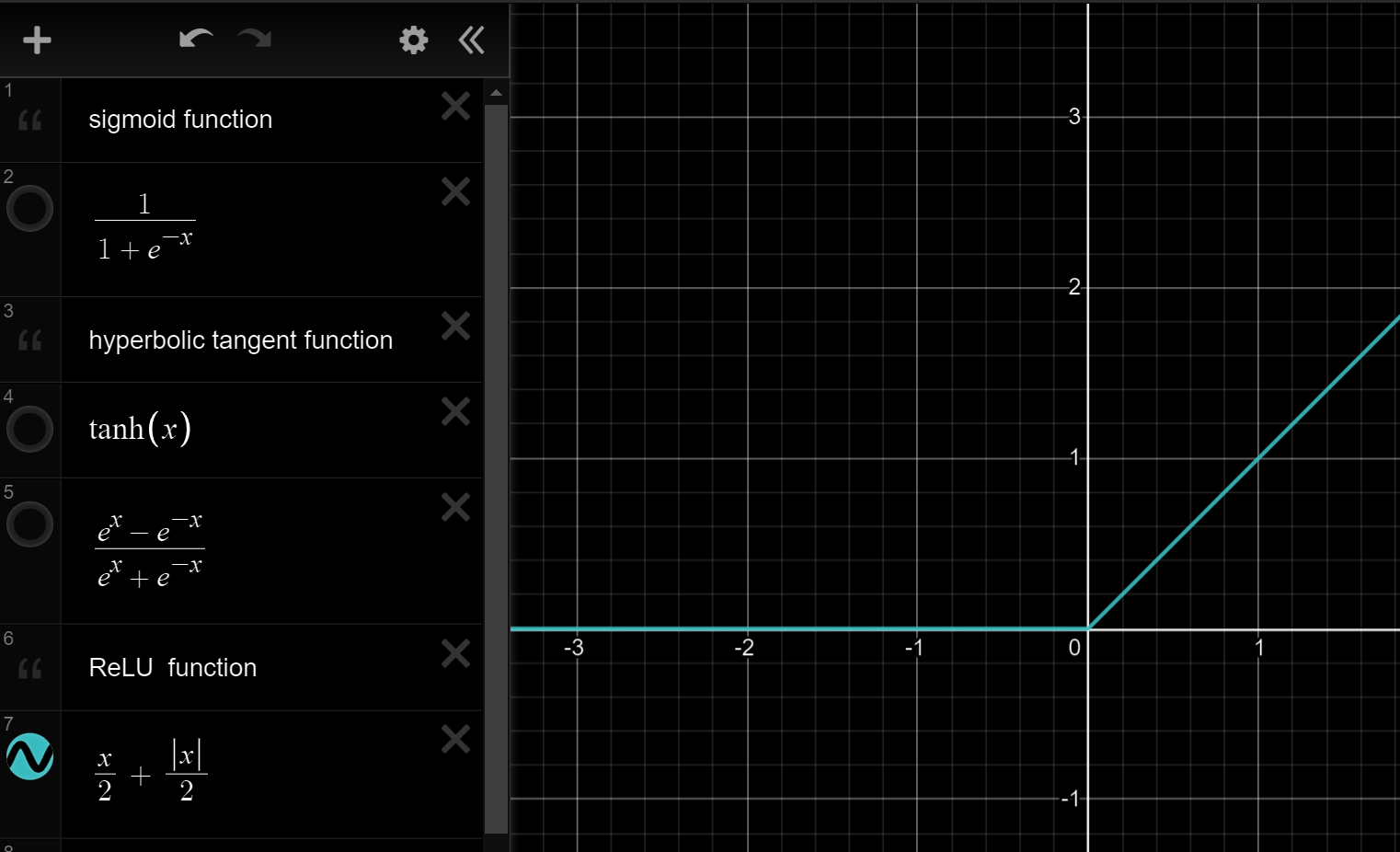
\[我们可以知道当z特别大或者特别小时,grad\;g变得趋向于0,\\这样往往会\text{“slow down gradient descent”}\\
所以在机器学习中我们有这样的方法叫\text{“rectified linear unit”}\\翻译过来叫线性修正单元(ReLU),公式为a=max(0,z)
\]
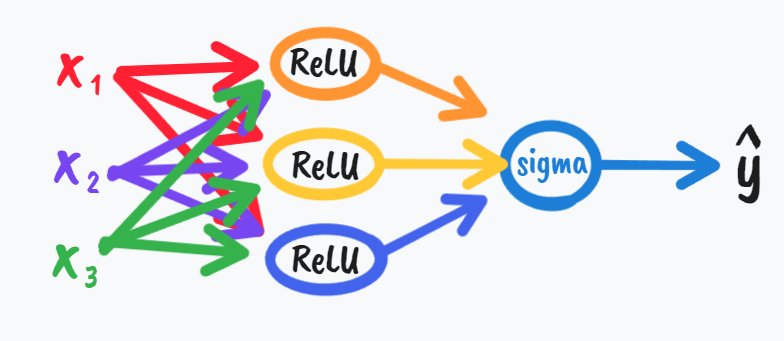
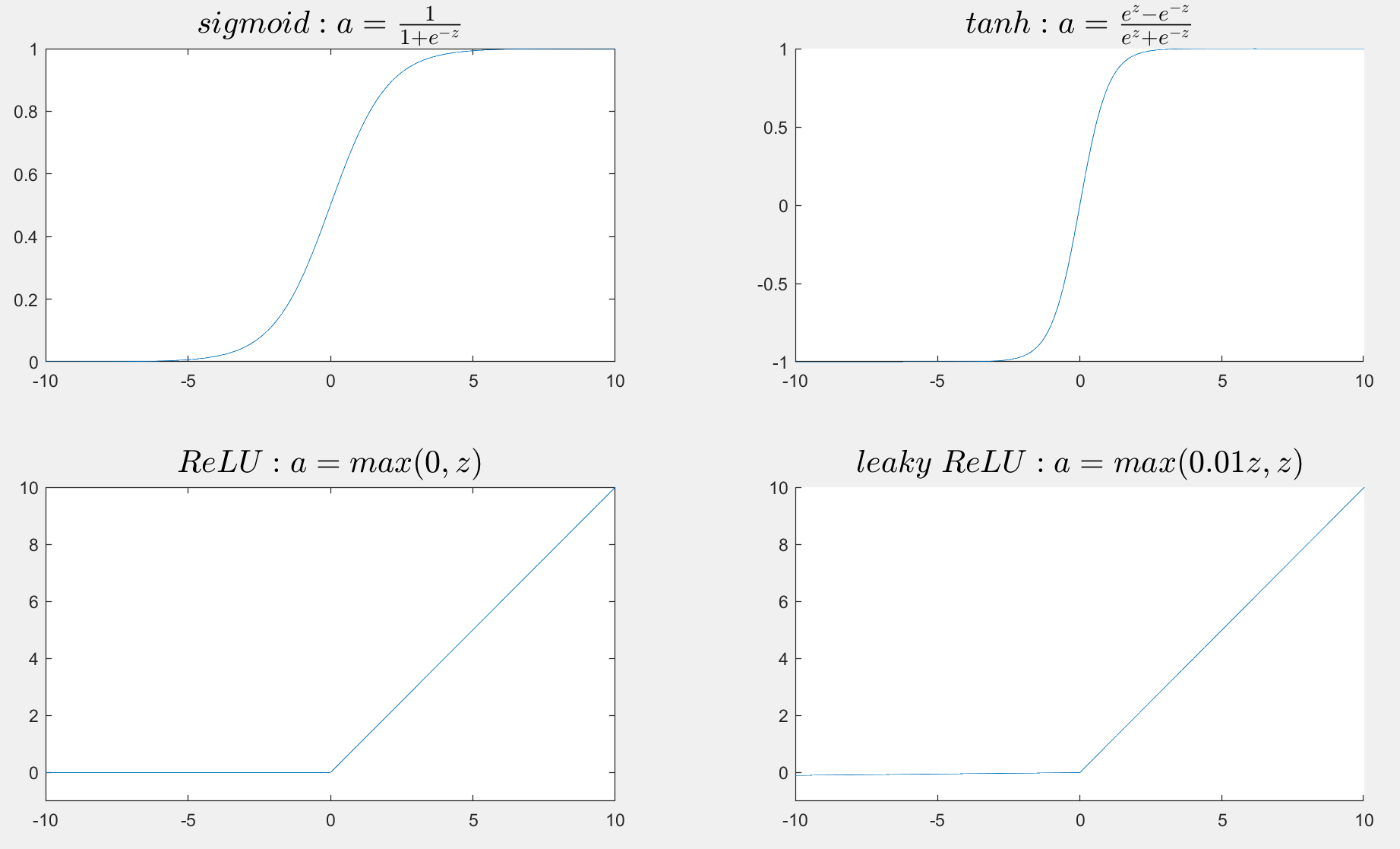
其中leaky是渗漏的意思,就是让小于零那一部分z还可以起到小小的作用🌹。而其中ReLU是不知道用啥时所用到的激活函数,事实上对于激活函数,或者对于函数中的细节改进,或者对于hidden layer中的单元数我们有很多种不同的选择,这也增大了我们的难度或者说是尝试的机会,或者像Andrew说的一样,you know try them all and then evaluate on like a holdout validation set.
接下来我们学习为什么需要非线性函数的原因:
\[\\z^{[1]}=W^{[1]}x+b^{[1]}
\\a^{[1]}=g^{[1]}(z^{[1]})
\\z^{[2]}=W^{[2]}a^{[1]}+b^{[2]}
\\a^{[2]}=g^{[2]}(z^{[2]})
\\通常在上面这个式中,如果我们有g^{[1]}(z^{[1]})=z^{[1]}
\\我们有时称它为linear\;activation\;function;
\\更好的名字应该是identity\;activation\;function(恒等激活函数)
\\如果我们在每一层都只用这种线性激活函数的话,我们容易想到
\\
\begin{align}
a^{[2]}&=W^{[2]}a^{[1]}+b^{[2]}
\\&=W^{[2]}(W^{[1]}x+b^{[1]})+b^{[2]}
\\&=(W^{[2]}W^{[1]})x+(W^{[2]}b^{[1]}+b^{[2]})
\\&=W'x+b'
\end{align}
\\最后得出的\hat{y}也不过是x的线性组合的结果,
\\\hat{y}=W'x+b'
\\就相当于是直接建立x与\hat{y}的关系,这样我们还不如去掉隐藏层(它在这里没有如何意义)
\]
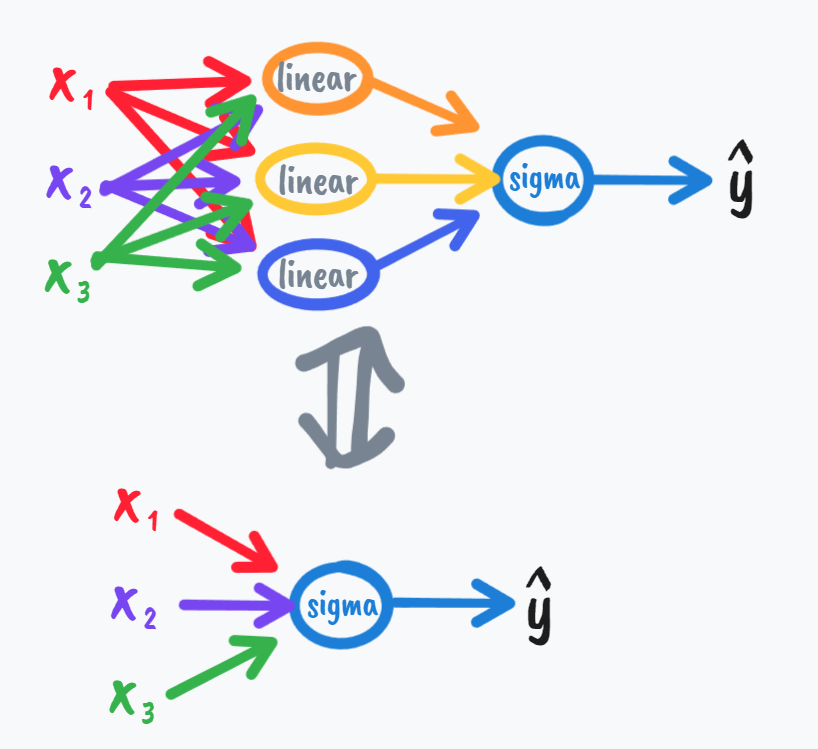
- 最后,笔者谈一下自己看法:其实我们更应该从物理层面去思考内在的激活函数关系,就好比六个对应自由度的值可以输出一个刚体的位姿,其内在肯定存在一个激活函数的模型,而不是建立很多隐层建立很多单元去逼近它,因为这样总是存在不能完全拟合的缺点,而且试错的快慢也需要由物质条件决定,但在现阶段难以得到更好结果的情况下用这种试错方法算是局部最优化了,我们好像也找不出理由不学习它。
激活函数的slope(斜率)和derivative(导数)
\[Sigmoid\;activation\;function:
\\g\left(x\right)=\sigma(x)=\frac{1}{1+e^{-x}}
\\\frac{d}{dx}g\left(x\right)=\frac{-e^{-x}}{(1+e^{-x})^2}=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}})=g(x)(1-g(x))
\\若a=g(z),g'(z)=a(1-a)
\]
\[Tanh\;activation\;function:
\\g\left(x\right)=tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}
\\\\\frac{d}{dx}g\left(x\right)=
\frac{(e^{x}+e^{-x})^2-(e^{x}-e^{-x})^2}{(e^{x}+e^{-x})^2}
=\frac{4}{(e^{x}+e^{-x})^2}=1-(tanh(x))^2
\\若a=g(z),g'(z)=1-a^2
\]
\[ReLU\;and\;Leaky\;ReLU:
\\g(z)=max(0,z)
\\g'(z)=
\begin{cases}
1 & \text{ if } z>0 \\
0 & \text{ if } z<0 \\
undefined & \text{ if } z=0\\
\end{cases}
\\(但事实上z=0处的导数为0或1都是没有影响的,这在我们后面训练数据的时候可以看到)
\\在实践中人们喜欢这样定义(影响不大):
\\g'(z)=
\begin{cases}
0 & \text{ if } z<0 \\
1 & \text{ if } z\ge 0 \\
\end{cases}
\\g(z)=max(0.01z,z)
\\g'(z)=
\begin{cases}
0.01 & \text{ if } z<0 \\
1 & \text{ if } z\ge 0 \\
\end{cases}
\]
画图matlab源代码
>> clear
>>
>> syms x;
>> clear
>> syms z;
>> a=sigma(z);
索引超出数组元素的数目(1)。
出错 sigma (line 96)
a=varargin{1}; b=varargin{2}; c=varargin{3}; d=varargin{4};
>> a=1/(1+e^(-z));
函数或变量 'e' 无法识别。
>> a=1/(1+exp^(-z));
错误使用 exp
输入参数的数目不足。
>> a=1/(1+exp(1)^(-z));
>> fplot(z)
>> plot(a,z)
错误使用 plot
数据必须为可转换为双精度值的数值、日期时间、持续时间或数组。% 老错误,plot不支持syms
>> clear
>> z=-2:0.01:2;
>> a=1/(1+exp(1)^(-z));
错误使用 ^ (line 51)
用于对矩阵求幂的维度不正确。请检查并确保矩阵为方阵并且幂为标量。要执行按元素矩阵求幂,请使用 '.^'。
>>
>> a=1/(1+exp(1).^(-z));
错误使用 /
矩阵维度必须一致。
>> a=1./(1+exp(1).^(-z));
>> plot(z)
>>
>> plot(a)
>> z=-10:0.1:10;
>> a=1./(1+exp(1).^(-z));
>> plot(a)
>> plot(a)
>> subplot(2,2,1)
>> plot(a)
>>
title('$\frac{sin(x)}{x}$','interpreter','latex', 'FontSize', 18); % 插入latex公式的方法
>> title('$sigmoid:a=\frac{1}{1+e^{-z}}$','interpreter','latex', 'FontSize', 18);
>> axis auto
>> plot(z,a)
>> subplot(2,2,2)
>> title('$tanh:a=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}$','interpreter','latex', 'FontSize', 18);
>> hold on;
>> subplot(2,2,1)
>> title('$sigmoid:a=\frac{1}{1+e^{-z}}$','interpreter','latex', 'FontSize', 18);
>> subplot(2,2,2)
>> a1=(exp(1).^(z)-exp(1).^(-z))/(exp(1).^(z)+exp(1).^(-z));
>> a1=(exp(1).^(z)-exp(1).^(-z))./(exp(1).^(z)+exp(1).^(-z));
>> plot(z,a1)
>> subplot(2,2,3)
>> title('$ReLU:a=max(0,z)$','interpreter','latex', 'FontSize', 18);
>> subplot(2,2,2)
>> title('$tanh:a=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}$','interpreter','latex', 'FontSize', 18);
>> a2=z./2+abs(z).2;
a2=z./2+abs(z).2;
↑
错误: 表达式无效。请检查缺失的乘法运算符、缺失或不对称的分隔符或者其他语法错误。要构造矩阵,请使用方括号而不是圆括号。
是不是想输入:
>> a2=z./2+abs(z)./2;
>> subplot(2,2,3)
>> plot(z,a2)
>> axis([-10,10,-10,10])
>> axis([-1,10,-10,10])
>> axis([-10,10,-1,10])
>> subplot(2,2,4)
>> title('$leaky\;ReLU:a=max(0.01z,z)$','interpreter','latex', 'FontSize', 18);
>> hold on
>> subplot(2,2,3)
>> title('$ReLU:a=max(0,z)$','interpreter','latex', 'FontSize', 18);
>> hold on
>> subplot(2,2,4)
>> a3=1.01.*z./2+abs(0.99.*z)./2;
>> plot(z,a3)
>> axis([-10,10,-1,10])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号