[笔记]动态规划优化(斜率优化,决策单调性优化)
本文主要记录某些动态规划思路及动态规划优化。
首先先把以前写过的斜率优化祭出来。
斜率优化
经典例题。
设 表示最后班车在 时刻发车,所有人等待时间和的最小值。(这里的所有人是指到达时刻小于等于 的所有人)。
容易列出转移方程:
其中 到达时间在 范围内的所有人等待的时间和。也就是 ,其中 。
然后考虑如何 计算 。首先拆式子,变成 。设在范围内的 共有 个,在范围内的 的和为 ,那么就可以 计算。而 可以通过桶上前缀和得到。
具体的,假设 为到达时间小于等于 的人到达时间的和, 表示到达时间小于等于 的人的个数,那么 。
那么这样整个算法复杂度就是 的。只能通过 的数据。
接下来引入斜率优化。假设有 两个决策点,且 , 优于 。那么有
接下来把 展开,得:
展开,得:
两边同时消掉 ,得:
接下来,将含有 的项移到左边,其余的移到右边:
假设 ,那么可以将 除到右边:
设 ,那么 。
假设横坐标为 ,那么不等式右边可以斜率形式。设两个决策点 之间的斜率为 ,而待转移点为 ,那么有:
接下来考虑如下情景:
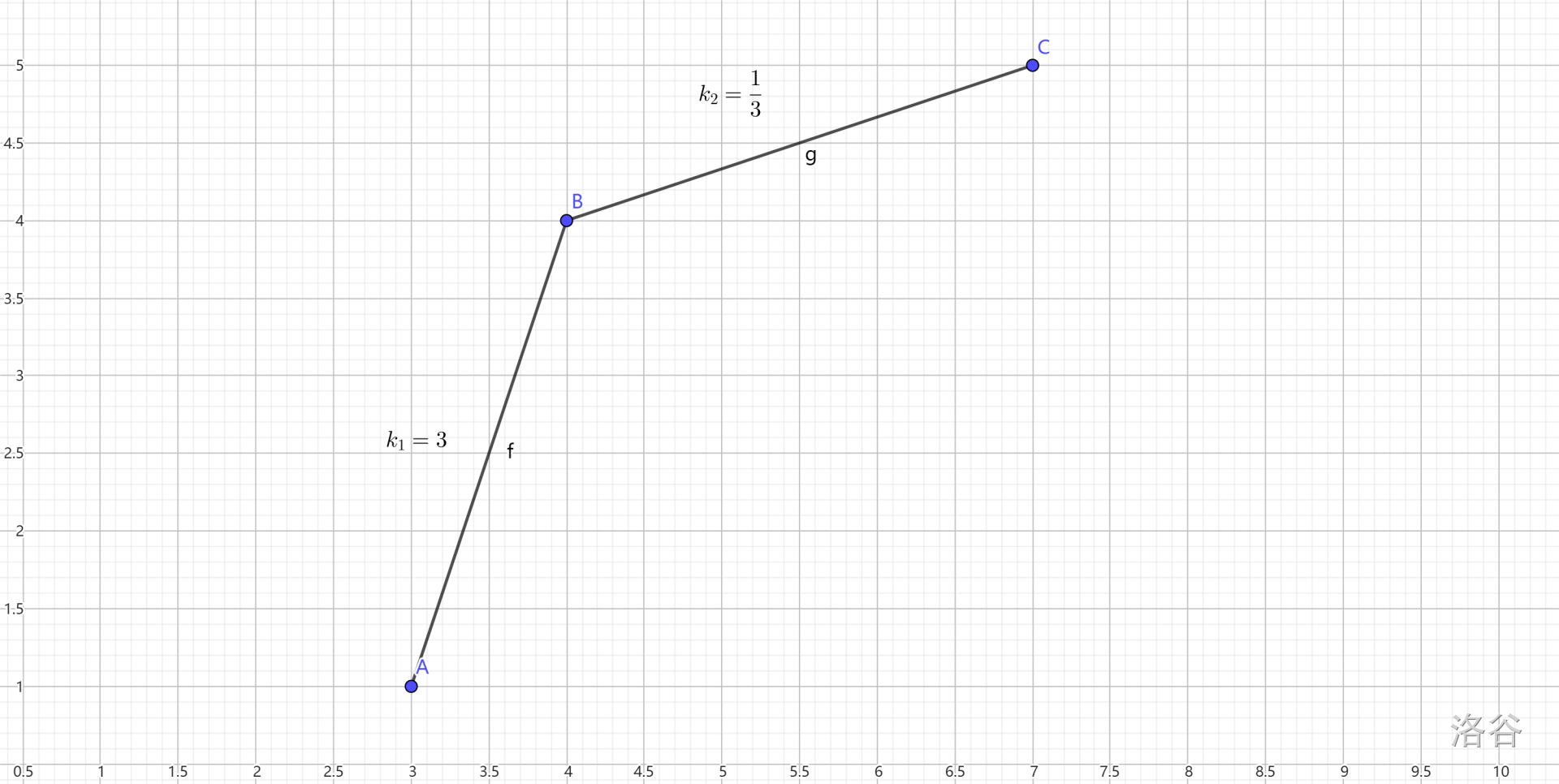
其中 。那么可以证明,无论 为多少, 点都是无用状态。
所以最优转移点之间的斜率一定严格单调递增。也就是我们要维护一个下凸壳。可以搞一个单调队列来做,然后每次转移的时候二分找到最佳转移点即可。这里的最佳转移点 就是指 之间的斜率为大于等于 的最小值。
所以搞完了。代码如下:
int cost(int x, int y) {
return y * (s[y].first - s[x - 1].first) -
(s[y].second - s[x - 1].second);
}
int f(int x) {
return dp[x] + s[x].second;
}
double delta(int x1, int x2) {
if (s[x2].first - s[x1].first == 0) return 1e-9;
return (s[x2].first - s[x1].first);
}
double slope(int x1, int x2) {
return (double)(f(x2) - f(x1)) / delta(x1, x2);
}
int get(int S) {
int l = 1, r = top;
while (l < r) {
int mid = l + r >> 1;
if (slope(stk[mid], stk[mid + 1]) >= S) r = mid;
else l = mid + 1;
}
return stk[l];
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) {
scanf("%d", &t[i]);
Map[t[i]].first ++ ;
Map[t[i]].second += t[i];
maxt = max(maxt, t[i]);
}
s[0].first = Map[0].first;
s[0].second = Map[0].second;
for (int i = 1; i < maxt + m; i ++ ) {
s[i].first = s[i - 1].first + Map[i].first;
s[i].second = s[i - 1].second + Map[i].second;
}
for (int i = 0; i < maxt + m; i ++ ) {
if (i >= m) {
while (top and slope(stk[top - 1], stk[top]) > slope(stk[top], i - m)) top -- ;
stk[ ++ top] = i - m;
}
dp[i] = s[i].first * i - s[i].second;
if (i >= m) {
int j = get(i);
dp[i] = dp[j] + cost(j + 1, i);
}
}
int ans = 2e9;
for (int i = maxt; i < maxt + m; i ++ )
ans = min(ans, dp[i]);
printf("%d\n", ans);
return 0;
}
接下来考虑线性做法。由于标准斜率 也是严格单调递增的,那么就可以把单调栈换成单调队列然后线性转移了。代码如下:
int t[N], dp[N];
int n, m, maxt;
PII Map[N], s[N];
int q[N];
int cost(int x, int y) {
return y * (s[y].first - s[x - 1].first) -
(s[y].second - s[x - 1].second);
}
int f(int x) {
return dp[x] + s[x].second;
}
double delta(int x1, int x2) {
if (s[x2].first - s[x1].first == 0) return 1e-9;
return (s[x2].first - s[x1].first);
}
double slope(int x1, int x2) {
return (double)(f(x2) - f(x1)) / delta(x1, x2);
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) {
scanf("%d", &t[i]);
Map[t[i]].first ++ ;
Map[t[i]].second += t[i];
maxt = max(maxt, t[i]);
}
s[0].first = Map[0].first;
s[0].second = Map[0].second;
for (int i = 1; i < maxt + m; i ++ ) {
s[i].first = s[i - 1].first + Map[i].first;
s[i].second = s[i - 1].second + Map[i].second;
}
int hh = 1, tt = 0;
for (int i = 0; i < maxt + m; i ++ ) {
if (i >= m) {
while (hh < tt and slope(q[tt - 1], q[tt]) > slope(q[tt], i - m)) tt -- ;
q[ ++ tt] = i - m;
}
while (hh < tt and slope(q[hh], q[hh + 1]) <= i) hh ++ ;
dp[i] = s[i].first * i - s[i].second;
if (i >= m) dp[i] = dp[q[hh]] + cost(q[hh] + 1, i);
}
int ans = 2e9;
for (int i = maxt; i < maxt + m; i ++ )
ans = min(ans, dp[i]);
printf("%d\n", ans);
return 0;
}
所以总结出斜率优化的规律:
-
可以表示成 的形式。
-
变形后的标准斜率非单调递增,可以在单调栈 / 单调队列里二分。
-
变形后的标准斜率单调递增,可以直接写单调队列暴力转移。
以上的递增也可以换成递减。
如果存在 非单调递增的情况,辣么就需要搞平衡树了。
决策单调性优化
原本证明很复杂的样子。实际上证明基本靠打表观察决策点。
决策单调性是指某一类 方程,当自变量 单调移动时,其决策点也单调移动。
目前已知的决策单调性满足这样的规律(仅考虑 ):
-
方程一般是 的形式。
-
的关于 的二阶偏导恒大于 / 小于零。
我知道首先要证什么 满足四边形不等式,还要证明什么 满足四边形不等式且局部单调啥的,但是这是规律。学 OI 谁还证明啊/kk
关于 的二阶偏导为正的意义就是指 函数随 增大增长率越来越快。否则就是增长率越来越慢。这显然和决策单调性挂钩。
举个例子,如果 ,这个显然是满足决策单调性的。它关于 的偏导大概是 的样子。然后可以发现这个决策点是单调左移的。
接下来引入二分队列。对于某些情况,比如下面的例子:
黑色的是初始值,红色的是增长率。求最大值。可以发现,决策点事单调右移的。
然后第一秒的时候,可以发现是第一个数是最优决策点。此时三个数分别为 。
第二秒的时候,计算机本来以为决策点要向右移动了,但实际上这时候三个数分别为 。最优决策点位置不动。
第三秒的时候,计算机觉得第二个数改该为最优决策点了吧?结果还不是。这时候的状态是 ,最优决策点变成了 。
所以这时候 反超了 决策点。所以我们需要告诉计算机什么时候 反超一。对于这个题,显然可以 计算。然后根据反超时间建一个单调栈 / 单调队列即可。但是有时候这个反超时间要二分。这也就是这个东西叫做二分栈 / 二分队列的原因。
接下来是例题。
设 代表在第 个短句后面打一个回车,前 个短句的最小不协调度。然后状态转移方程就是:
然后发现这符合决策单调性的规律。我们把 拆开看看。
。
其中 表示短句长度的前缀和。
首先我们看函数 的二阶导,显然就是 。当 的时候,这个东西显然是正的,也就是说函数增长率越来越快。接下来分析 函数。可以固定 不变,然后看看它关于 的变化情况。可以发现,当 不变的时候, 越大,其增长率越慢(因为 变小, 也变小,所以相当于 变小了)。由于要求最小值,所以决策点应该是单调右移的。
然后套上二分栈二分队列即可。
auto calc = [&](int l, int r) -> long double {
return dp[l] + qpow((long double)abs(s[r] - s[l] + r - l - 1 - L), P);
};
auto find = [&](int j, int i) -> int { // To cauculate when j becomes better than i
int l = j, r = n + 1, sum = 0;
while (l <= r) {
int mid = l + r >> 1;
if (calc(j, mid) >= calc(i, mid)) r = mid - 1;
else l = mid + 1;
}
return l;
};
scanf("%d", &T);
while (T -- ) {
scanf("%d%d%d", &n, &L, &P);
for (int i = 1; i <= n; i ++ ) {
scanf("%s", str[i]);
s[i] = s[i - 1] + strlen(str[i]);
}
hh = tt = 1; q[hh] = 0;
for (int i = 1; i <= n; i ++ ) {
while (hh < tt and t[hh] <= i) hh ++ ;
pre[i] = q[hh], dp[i] = calc(q[hh], i);
while (hh < tt and t[tt - 1] >= find(q[tt], i)) tt -- ;
t[tt] = find(q[tt], i);
q[ ++ tt] = i;
}
}
决策单调性优化
这种题目通常可以进行分层。比如 。这样可以关于 进行分层,看做从 层转移到第 层。然后观察层之间的转移是否有决策单调性。
通常来说,二维的决策单调性优化使用分治法来解决。具体是这样的:假设 表示当前层处理到了 这个区间,决策点在上一层的 这个区间。然后假设 。找到转移到 的最优决策点 。然后根据决策单调性可知,能够转移到 的最优决策点一定在区间 ,而 的最优决策点一定在区间 中(这里假设决策点的递增不是严格的)。递归处理 即可。
可以发现复杂度的瓶颈在于寻找 的最优决策点。如果每次寻找 决策点的复杂度为 ,那么时间复杂度就为 了。这里的 表示层数。
所以分治法适用于求解 最优转移点时间复杂度为 或均摊 的情况。
设 表示将前 个数分成 段的最大价值。那么那么转移方程就是 。显然可以根据分的段数分层。然后考虑如何求出 。考虑使用莫队的思想,开一个桶,然后搞两个指针移动一下。考虑这个复杂度为什么正确。首先在求 的时候如果采取下面的写法:
for (int i = min(R, mid); i >= L; i -- ) {
int ans = f[i - 1][level - 1] + cost(i, mid);
if (ans > f[mid][level]) f[mid][level] = ans, MID = i;
}
那么显然指针是单调左移的。
然后接下来 的时候,指针仍然会单调左移。接下来 的时候,指针又单调右移。所以指针的移动次数是 级别的。也就是做到了均摊 求最优决策点。
void solve(int l, int r, int L, int R, int level) {
if (l > r) return;
int mid = l + r >> 1, MID = L;
for (int i = min(R, mid); i >= L; i -- ) {
int ans = f[i - 1][level - 1] + cost(i, mid);
if (ans > f[mid][level]) f[mid][level] = ans, MID = i;
}
solve(l, mid - 1, L, MID, level);
solve(mid + 1, r, MID, R, level);
}
int main() {
scanf("%d%d", &n, &k);
for (int i = 1; i <= n; i ++ )
scanf("%d", &w[i]);
memset(f, -0x3f, sizeof f);
f[0][0] = 0;
for (int i = 1; i <= k; i ++ )
solve(1, n, 1, n, i);
printf("%d\n", f[n][k]);
return 0;
}



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库