数学相关
质数理论及筛法相关
质数判断(Miller-Rabbin 算法)
首先根据费马小定理,对于一个质数 pp,有 ∀a∈[1,p−1]∀a∈[1,p−1],ap−1≡1(mod p)ap−1≡1(mod p)。但是假设需要判断的数为 nn,随机挑选一个数 aa,并且判断 an−1≡1(mod n)an−1≡1(mod n) 成功,却不一定成立。这种数叫做卡迈克尔数。
于是有两种提高准确度的方法:
-
选择更多的 aa 进行多次尝试,每次都检验 an−1≡1(mod n)an−1≡1(mod n) 是否成立。
-
使用二次探测定理。
二次探测定理:若有 x2≡1(mod p)x2≡1(mod p),则有 x≡1(mod p)x≡1(mod p) 或 x≡p−1(mod p)x≡p−1(mod p)。
因此,如果当前的探测因子 aa 满足了 an−1≡1(mod n)an−1≡1(mod n)(此时无法证明 nn 是质数),那么可以继续探测是否满足 an−12≡1(mod n)an−12≡1(mod n) 或者 an−12≡n−1(mod n)an−12≡n−1(mod n),一直如此进行下去。
因此可以写出一个 O(slog2n)O(slog2n) 的代码:
bool MillerRabbin(int n) {
for (int p : tst) {
if (n == p) return 1;
else if (p > n) return 0;
int cnt = qpow(p, n - 1, n);
if (cnt != 1) return 0;
int now = n - 1;
while (!(now & 1) and cnt == 1) {
now >>= 1; cnt = qpow(p, now, n);
if (cnt != 1 and cnt != n - 1) return 0;
}
} return 1;
}
其中 tst 表示探测因子数组。
接下来继续对算法进行优化。发现复杂度瓶颈在快速幂。可以用 double 处理的 O(1)O(1) 快速幂来代替。另外一种方法则更加简便:首先将 n−1n−1 写成 t×2kt×2k 的形式。然后先判断 tt 是否成立,然后把 tt 自乘 kk 次,每次都判断一下。这样只需要用到乘法,因此复杂度降掉一个 loglog。
bool MillerRabbin(int n) {
if (n == 1) return 0;
int t = n - 1, k = 0;
while (!(t & 1)) t >>= 1, k ++ ;
for (int p : tst) {
if (n == p) return 1;
int a = qpow(p, t, n), ne = a;
rep(i, 1, k) {
ne = 1ll * a * a % n;
if (ne == 1 and a != 1 and a != n - 1) return 0;
a = ne;
} if (a != 1) return 0;
} return 1;
}
质数筛法
欧拉筛法:对于每个合数只筛其最小的因数。复杂度 O(n)O(n)。
void get_prime(int n) {
for (int i = 2; i <= n; i ++ ) {
if (!st[i]) q[ ++ cnt] = i;
for (int j = 1; j <= cnt && i * p[j] <= n; j ++ ) {
st[i * p[j]] == 1; if (i % p[j] == 0) break;
}
}
}
通常可以筛某些神奇的函数,其满足积性函数性质,或者与其最小质因子强相关。
约数个数和约数和
-
唯一分解定理:每个数 n∈N∗n∈N∗ 都可以被唯一分解成 ∏pcii∏pcii。
-
约数个数和:∏(ci+1)∏(ci+1)。每个质因子可以选 0∼ci0∼ci 个。
-
约数和:∏pci+1i−1pi−1∏pci+1i−1pi−1。道理与约数个数和相同,只不过换上了等比数列求和。
min-25 筛
解决函数 ff 的前缀和问题。
下文中的一些记号:
-
F(n)=∑ni=1f(i)F(n)=∑ni=1f(i):f(i)f(i) 的前缀和。
-
lp(n)lp(n):nn 的最小质因子。
-
pkpk:全体质数中第 kk 小的质数。
-
xyxy:默认下取整。
首先尝试解决这个问题:求出
其中 m∈{n1,n2,n3⋯,nn}m∈{n1,n2,n3⋯,nn},一共有 √n√n 中取值。
考虑 dp。设 g(j,m)g(j,m) 表示:
也就是对于所有的质数或者最小质因数大于 pjpj 的 f′f′ 求和。
这里的 f′f′ 需要满足下面的三个性质:
-
∀p∈P,f′(p)=f(p)∀p∈P,f′(p)=f(p)。
-
f′f′ 是完全积性函数。
-
∑f′∑f′ 可以快速求值。
初始时,g(0,m)=∑2≤i≤mf′(i)g(0,m)=∑2≤i≤mf′(i)。
转移时分两种情况:
-
若 p2j>mp2j>m:g(j,m)=g(j−1,m)g(j,m)=g(j−1,m)。因为不存在 i∈[1,m]i∈[1,m],使得 lp(i)>pjlp(i)>pj。
-
若 p2j≤mp2j≤m:
这个式子怎么理解呢?首先,这里可以理解成从 g(j−1,m)g(j−1,m) 里面筛掉所有 lp=pjlp=pj 的 f′f′ 值。而筛掉的值一定可以表示成 pj×qpj×q,其中 qq 是一个 ≤mpj≤mpj 而且最小质因子 ≤pj≤pj 的数。最后减掉的那块,是 g(j−1,mpj)g(j−1,mpj) 里面的那部分质数。由于 f′f′ 是完全积性函数,这两部分可以直接相乘。
以上部分时间复杂度被证明是 O(n0.75logn)O(n0.75logn)。
上面求出了 G(m)=∑i∈P,i≤mf(i)=g(π(m),m)G(m)=∑i∈P,i≤mf(i)=g(π(m),m)。
同余相关
最大公约数和最小公倍数
-
最大公约数(gcd(a,b)gcd(a,b)),也写作 (a,b)(a,b),是最大的 dd 满足 d|ad|a 且 d|bd|b。
-
设 a=∏pcii,b=∏qdiia=∏pcii,b=∏qdii,则 d=∏P∈{p}or{q}min(ci,di)d=∏P∈{p}or{q}min(ci,di)。
-
神奇 trick:nn 不同的数按一定顺序求 gcdgcd,O(logV)O(logV) 次之后变为 11。
-
最小公倍数,记作 [a,b][a,b],满足 [a,b](a,b)=ab[a,b](a,b)=ab。
bonus:最大公约数的二进制优化:
最大公约数求解过程中,如果两个数都有很多 22 的因子,那么就会浪费很多时间。二进制优化最大公约数基于下面的原理:
-
aa 为偶数,bb 为偶数:gcd(a,b)=gcd(a2,b2)×2gcd(a,b)=gcd(a2,b2)×2。
-
aa 为偶数,bb 为奇数:gcd(a,b)=gcd(a2,b)gcd(a,b)=gcd(a2,b)。
-
aa 为奇数,bb 为偶数:与上面同理。
-
a,ba,b 都为奇数:只能朴素求了。
int gcd(int a, int b) {
int i = 0, j = 0;
if (!a || !b) return a + b;
for (; !(a & 1); i ++ , a >>= 1);
for (; !(b & 1); j ++ , b >>= 1);
if (i > j) i = j;
while (true) {
if (a < b) swap(a, b);
if ((a -= b) == 0) return b << i;
while ((a & 1) == 0) a >>= 1;
}
}
该算法可以用于除法及其慢的情况,如高精 gcdgcd。
扩展欧几里得算法 exgcd
考虑不定方程
令 x′←y,y′←x−⌊ab⌋yx′←y,y′←x−⌊ab⌋y 之后迭代即可。
有两种不同写法,一种写法是按照上述规则模拟:
int exgcd(int &x, int &y, int a, int b) {
if (!b) { x = 1, y = 0; return a; }
int d = exgcd(x, y, b, a % b);
int tx = x, ty = y;
x = ty, y = tx - (a / b) * ty;
return d;
}
另一种方式在每次迭代的时候将 x,yx,y 翻转,这样可能更加简洁。
int exgcd(int &x, int &y, int a, int b) {
if (!b) { x = 1, y = 0; return a; }
int d = exgcd(y, x, b, a % b);
y -= (a / b) * x; return d;
}
tips:tips:
- 求 ax+by=cax+by=c 的方程的一组解:
假设 ax+by=(a,b)=dax+by=(a,b)=d 的一组解为 x0,y0x0,y0,则 ax0×cd+by0×cd=(a,b)×cd=cax0×cd+by0×cd=(a,b)×cd=c。
因此得到一组解 x=x0×cd,y=y0×cdx=x0×cd,y=y0×cd。
- 求 ax+by=cax+by=c 的所有解。
通过构造可以得到,若 x0,y0x0,y0 为方程的一组解,则 x=x0+b(a,b),y=y0−a(a,b)x=x0+b(a,b),y=y0−a(a,b) 也是方程的一组解。可以证明,所有解都可以表示成
的形式。
- 求 ax+by=cax+by=c 的所有正整数解。
利用通解的公式容易求得(x,yx,y 增减性相反)。
乘法逆元
用于进行模意义下的乘法。aa 的乘法逆元记作 a−1a−1。根据定义 a×a−1≡1(mod p)a×a−1≡1(mod p)
-
求单个值 aa 的乘法逆元:
-
通过 exgcdexgcd。发现就是解 ax≡1(mod p)ax≡1(mod p) 的解。可以直接用 exgcdexgcd 解同余方程。
-
通过费马小定理。
费马小定理:对于质数 pp 和一个与其互质的数 aa,一定满足 ap−1≡1(mod p)ap−1≡1(mod p)。
证明:∀a∈(0,p),a∈N∗,ka modp∀a∈(0,p),a∈N∗,ka modp 互不相同(k=0,1⋯p−1k=0,1⋯p−1)。因此 (p−1)!a=1a×2a⋯(p−1)a≡(p−1)!(mod p)(p−1)!a=1a×2a⋯(p−1)a≡(p−1)!(mod p)。因此 ap−1≡1(mod p)ap−1≡1(mod p)
所以得到 ap−1×a−1≡ap−2≡a−1(mod p)ap−1×a−1≡ap−2≡a−1(mod p)。快速幂求出 ap−2ap−2 即可。
int qpow(int a, int b = mod - 2) {
int s = 1; for (; b; b >>= 1, a = 1ll * a * a % mod)
if (b & 1) s = 1ll * s * a % mod; return s;
}
- 求 1∼n1∼n 中所有正整数阶乘的逆元。
首先线性预处理出所有正整数的阶乘。然后用扩欧或者快速幂求出所有阶乘的逆元。这样做的复杂度是 O(nlogn)O(nlogn)。
然后发现可以这样搞:首先求出 n!n! 的逆元。然后倒推,对于所有 (i!)−1(i!)−1,其都等于 [(i+1)!]−1×(i+1)[(i+1)!]−1×(i+1)。因此可以线性求出。
线性求阶乘逆元常应用于组合数学。
- 求 1∼n1∼n 中所有正整数的逆元:
首先线性求所有阶乘逆元。然后发现,对于数字 aa,其逆元 a−1=(a!)−1×(a−1)!a−1=(a!)−1×(a−1)!。可以做到线性。
- 求一堆数的逆元:
首先需要把整除 pp 的所有数拎出来单独处理。显然他们的逆元都是 00。
接下来处理所有数的前缀积,记为 preiprei。对 prenpren,用快速幂求逆元。
可以倒推出所有前缀积的逆元:pre_invi=pre_invi+1×aipre_invi=pre_invi+1×ai。
最后可以用前缀积和前缀积的逆元推出每个数的逆元。时间复杂度也是 O(n)O(n)。
中国剩余定理
本来应该先学中国剩余定理的。但是有了扩展中国剩余定理,朴素的 CRT 就没用了。
扩展中国剩余定理用来求解如下形式的同余方程组:
扩展中国剩余定理的基本思想是合并,通过 n−1n−1 次合并,将一个大的同余方程组合并成一个同余方程。
假设现在有两个同余方程:
现在要将他们合并。首先转化成不定方程:
成功转化成了系数为 (A,−B,b−a)(A,−B,b−a) 的不定方程,使用 exgcd 求出他的一个根。因此转化成了一个同余方程:x≡Ak1+a(mod lcm(A,B))x≡Ak1+a(mod lcm(A,B))。合并完成。
// 合并 x = a(mod A), x = b(mod B) 两个方程
// 返回的是新的 a', b',满足 x = a'(mod b')
PII merge(int a, int A, int b, int B) {
int k1, k2; int d = exgcd(k1, k2, A, B);
k1 = k1 * (b - a) / d;
int p = A / d * B; return {(A * k1 + a) % p, p};
}
bonus:
- 如果 xx 的系数不为 11。
也就是 P4774 [NOI2018] 屠龙勇士。
求解形如:
Excrt 因为 xx 的系数是一,因此可以直接联立两个不定方程。也尝试将这个东西转化成不定方程的形式。假设现在需要合并的两个同余方程是:
然后发现两个 xx 的系数不同,不能直接合并了。而这两个柿子两边又不能同时除以 pp 或者 PP,因为不保证逆元存在。这就非常难搞。
一个神奇的思路是直接解出两个方程。以第一个方程为例,方程中只有两个未知数 xx 和 −k1−k1,可以解出一个特解 x0x0。那么所有 xx 就可以表示成:
同理解第二个方程,可以得到
我们惊奇的发现这两个 xx 的系数相同了。所以可以合并一下:
里面只有 α,βα,β 两个未知数,解出他们两个就可以得到 xx。
- 扩展中国定理进行模数非质数的合并
即 古代猪文。
求 (nm)mod 999911658(nm)mod 999911658 的值。
将 999911658999911658 质因数分解得到:999911658=2×3×4679×35617999911658=2×3×4679×35617。
因此可以对 2,3,4679,356172,3,4679,35617 分别做一遍 LucasLucas,得到下面的同余方程:
可以直接用 excrt 合并一下。
另外一个应用是扩展卢卡斯。其基本思路也是将模数拆成若干质因数的次方,计算后 excrt 合并。
积性函数及系理论
如果一个数论函数 ff 对于任意的 n⊥mn⊥m 都满足 f(nm)=f(n)f(m)f(nm)=f(n)f(m),则称 ff 是一个积性函数。
积性函数可以使用筛法来求。后面会写。
欧拉函数
欧拉函数定义为:φ(n)φ(n) 表示 1∼n1∼n 中所有与 nn 互质的数的个数。
关于欧拉函数有下面的性质和用途:
-
欧拉函数是积性函数。可以通过这个性质求出他的公式。
-
f(p)=p−1f(p)=p−1。很显然,比质数 pp 小的所有数都与他互质。
-
f(p2)=p×(p−1)f(p2)=p×(p−1)。显然,对于这 p2p2 个数,只有 p,2p,3p⋯p2p,2p,3p⋯p2 不与 p2p2 互质。
-
f(pk)=pk−1(p−1)f(pk)=pk−1(p−1)。
-
假设 n=∏kpciin=∏kpcii,则 f(n)=∏kf(pcii)=∏kpck−1k(pk−1)=n∏kpk−1pkf(n)=∏kf(pcii)=∏kpck−1k(pk−1)=n∏kpk−1pk。
-
-
欧拉函数可以用线性筛筛出来。
假设当前的数是 nn,遍历到的质数为 pp,那么 m=p×nm=p×n 肯定要被筛掉。根据欧拉筛:
-
若 p|np|n,那么 pp 是 nn 的最小质因子,且 nn 中包含 mm 的所有质因子。根据单个欧拉函数的求法可以得到:φ(m)=φ(n)×pφ(m)=φ(n)×p。
-
否则,pp 和 nn 互质,根据积性函数的性质,φ(m)=φ(n)φ(p)φ(m)=φ(n)φ(p)。
-
int get_phi(int n) {
phi[1] = 1;
for (int i = 2; i <= n; i ++ ) {
if (!st[i]) p[ ++ cnt] = i, phi[i] = i - 1;
for (int j = 1; j <= cnt and 1ll * i * p[j] <= n; j ++ ) {
st[i * p[j]] = true; if (i % p[j] == 0) {
phi[i * p[j]] = phi[i] * p[j]; break;
} phi[i * p[j]] = phi[i] * phi[p[j]];
}
}
}
- 欧拉函数可以用来降幂。下面就来介绍。
完全剩余系
对于整数集 S={r1,r2⋯rn}S={r1,r2⋯rn} 满足:
-
任意不同元素 ri,rjri,rj,都有 ri≢rj(mod m)ri≢rj(mod m)。
-
∀a∈Z∀a∈Z,∃r∈S,r≡a(mod m)∃r∈S,r≡a(mod m)。
例如,对于 m=5m=5,S={0,1,2,3,4}S={0,1,2,3,4} 就是 55 的一个完全剩余系。通常地,将模 mm 的完全剩余系记做 ZmZm。
实际应用中,通常用 Zm={0,1,2⋯m−1}Zm={0,1,2⋯m−1} 来表示,也就是模 mm 的最小非负完全剩余系。
推论 11:任意 mm 个连续整数构成模 mm 的完全剩余系。
推论 22:若 a⊥ma⊥m 且 ZmZm 是一个完全剩余系,则 S={a,2a⋯ma}S={a,2a⋯ma} 构成一个完全剩余系。
下面证明推论 22。
设集合 S={ra|r∈Zm}S={ra|r∈Zm}。对于 ri,rj∈Zm,ri≠rjri,rj∈Zm,ri≠rj。假设存在同余 ria≡rja(mod m)ria≡rja(mod m)。由于 a⊥ma⊥m,因此 ri≡rj(mod m)ri≡rj(mod m)。根据完全剩余系的互异性,假设不成立。SS 的互异性证明完成。
因为 S⊂ZS⊂Z,由定义 (2)(2) 可得,∀a∈S∀a∈S,ZmZm 中有唯一的 rr 满足 r≡a(mod m)r≡a(mod m)。因此构成 SS 对 ZmZm 的单射。又因为 |S|=|Zm||S|=|Zm|,故构成 SS 到 ZmZm 的双射。
则对于任意整数,都存在 ZmZm 中的某个数 rr 与之同余,亦存在 SS 中某个数与之同余。定义 (1)(1) 证明完成。因此 SS 是一个完全剩余系。
简化剩余系
在完全剩余系基础上加上了更强的限制。
定义 Φm={r1,r2⋯rs}Φm={r1,r2⋯rs} 为模 mm 的简化剩余系,当且仅当:
-
任意不同元素 ri,rj∈Φmri,rj∈Φm,都有 ri≢rj(mod m)ri≢rj(mod m)。
-
∀a∈Z∀a∈Z,∃r∈Φm,r≡a(mod m)∃r∈Φm,r≡a(mod m)。
-
∀r∈Φm,r⊥m∀r∈Φm,r⊥m。
其中定义 (2),(3)(2),(3) 可以合并为 ∀a⊥m∀a⊥m,都存在唯一的 r∈Φmr∈Φm 满足 a≡r(mod m)a≡r(mod m)。
下面证明简化剩余系的一些推论。
推论 11:该剩余系对于 mod mmod m 的乘法具有封闭性。
证明:∀ri,rj∈Φm∀ri,rj∈Φm,都有 ri⊥m,rj⊥mri⊥m,rj⊥m。因此有 rirj⊥mrirj⊥m。根据性质 (2),(3)(2),(3),rirjrirj 也在 ΦmΦm 中。
根据 ai⊥m→ai⊥a−1iai⊥m→ai⊥a−1i 可知,aiai 的乘法逆元也在 ΦmΦm 中。因此证明了关于乘法和除法的封闭性,还证明了逆元的存在。
事实上,该简化剩余系 ΦmΦm 构成关于模 mm 乘法运算的交换群(阿贝尔群)。
推论 22:φ(m)=|Φm|φ(m)=|Φm|。
推论 33:对于 m>2m>2,有:
∑r∈Φmr=0∑r∈Φmr=0
证明:可能算是感性证明。根据欧几里得算法的流程,(r,m)=1(r,m)=1,则 (m,m−r)=1(m,m−r)=1,也即 (m,−r)=1(m,−r)=1。因此,如果 rr 在 ΦmΦm 中,则 −r−r 也在 ΦmΦm 中。由于 rr 与 −r−r 模 mm 不相等,因此简化剩余系中的数总是成对出现。相加可以证明。
这也说明,简化剩余系 ΦmΦm 的大小 |Φm||Φm| 一定是偶数(m>2m>2)。
推论 44:若 a⊥ma⊥m 且 ΦmΦm 是一个完全剩余系,则 S={ra|r∈Φm}S={ra|r∈Φm} 构成一个完全剩余系。
证明方法可以参考完全剩余系性质 22 的证明。
欧拉定理
定义:若 n,an,a 均为正整数,且 nn 与 aa 互质,则有 aφ(n)≡1(mod n)aφ(n)≡1(mod n)。
证明:对于 nn 的简化剩余系 ΦnΦn,根据简化剩余系的推论 44 可知,S={ar|r∈Φn}S={ar|r∈Φn} 也构成模 nn 的简化剩余系。
根据 ∏r∈Φnr≡∏r∈Sr(mod n)∏r∈Φnr≡∏r∈Sr(mod n),有 a|Φn|=aφ(n)≡1(mod n)a|Φn|=aφ(n)≡1(mod n)。证毕。
由此可以得到更弱的定理 Farmet 小定理:∀p∈P∀p∈P,ap−1≡1(mod p)ap−1≡1(mod p)。
扩展欧拉定理
扩展欧拉定理的证明就不在我能力所及的范围内了。在这就放个结论吧。
这个柿子就比较有用了,可以用来搞降幂之类的事情。
例题
求 222⋯2modp222⋯2modp 的值。
设 f(p)f(p) 表示 22 的幂塔对 pp 取模的值。那么他就等于 2f(φ(p))+φ(p)2f(φ(p))+φ(p)。由于 φφ 函数下降速度极快(loglog 速度),很快 φ(p)φ(p) 降为 11。这个东西可以递归求解。
int solve(int p) {
if (p == 1) return 0;
int phi = get_phi(p);
int s = solve(phi);
return qpow(2, s + phi, p);
}
给定一个数列 w1,w2⋯wnw1,w2⋯wn 和模数 pp, 每次询问一个区间 [l,r][l,r],求 www⋯wrl+2l+1lmod pwww⋯wrl+2l+1lmod p 的值
考虑欧拉降幂。欧拉函数下降速度很快,O(logp)O(logp) 次就能降为 11。因此可能只需要计算到 wl+kwl+k,后面的就全模 11 了(当然模 11 就是 00)。这个 kk 是 O(logp)O(logp) 级别的。
上面讨论的都是幂次大于 φ(p)φ(p) 的情况。如果幂次小于 φ(p)φ(p) 呢?怎么提前判断掉呢?
如果数列的每一项都 ≥2≥2,那么可以直接暴力判断,因为 O(logp)O(logp) 个数乘起来就会达到 pp。但是如果存在 11 呢?这个也好办,直接把 rr 调到 ll 后边的第一个 11 前面就行,这样保证了 [l,r][l,r] 中没有 11。同时,这个 11 对答案也没有影响,因为 x1=x,1x=1x1=x,1x=1。
下面是一份可供参考的代码实现:
#include <iostream>
#include <cstring>
#include <cstdio>
#include <map>
#define int long long
using namespace std;
const int N = 100010;
int n, m, p, a[N], suf[N];
map<int, int> bin;
int qpow(int a, int b, int p) {
int s = 1; for (; b; b >>= 1, a = a * a % p)
if (b & 1) s = s * a % p; return s;
}
bool check(int a, int b, int p) {
int s = 1;
for (; b; b >>= 1, a = a * a) {
if (a >= p) return 0;
if (b & 1) {
s = s * a; if (s >= p) return 0;
}
} return 1;
}
int get_phi(int n) {
int s = n;
for (int i = 2; i <= n / i; i ++ ) if (!(n % i)) {
s = s / i * (i - 1); while (!(n % i)) n /= i;
} if (n != 1) s = s / n * (n - 1); return s;
}
int solve(int u, int r, int p) {
if (u == r) return a[u] % p;
if (p == 1) return 0;
int phi = bin[p], s = a[r]; bool flg = 0;
for (int i = r; i > u + 1; i -- ) {
if (!check(a[i - 1], s, phi)) { flg = 1; break; }
s = qpow(a[i - 1], s, phi);
} if (s >= phi) flg = 1; int pw;
if (flg) pw = solve(u + 1, r, phi) + phi;
else pw = s;
return qpow(a[u], pw, p);
}
signed main() {
scanf("%lld%lld", &n, &p);
for (int i = 1; i <= n; i ++ )
scanf("%lld", &a[i]);
scanf("%lld", &m); int t = p; bin[1] = 1;
while (t != 1) bin[t] = get_phi(t), t = bin[t];
suf[n + 1] = n + 1;
for (int i = n; i >= 1; i -- )
if (a[i] == 1) suf[i] = i;
else suf[i] = suf[i + 1];
while (m -- ) {
int l, r; scanf("%lld%lld", &l, &r);
r = min(r, suf[l]); printf("%lld\n", solve(l, r, p));
} return 0;
}
数值算法
高斯消元
高斯消元原理
高斯消元用来解如下形式的方程组:
首先将所有系数写成系数矩阵:
接下来可以进行初等行列变换,将矩阵消成下三角矩阵。类似这样:
然后最后一行就表示 an,nxn=an,n+1an,nxn=an,n+1,可以解出 xnxn。
然后往回带,解出 xn−1xn−1,以此类推即可。时间复杂度 O(n3)O(n3)。
void gauss() {
rep(i, 1, n) {
rep(j, i, n) if (fabs(a[j][i]) > eps) {
swap(a[j], a[i]); break;
} if (fabs(a[i][i]) <= eps) continue;
rep(j, i + 1, n) {
if (fabs(a[j][i]) <= eps) continue;
db inv = (db)a[j][i] / a[i][i];
rep(k, i, n + 1)
a[j][k] -= inv * a[i][k];
}
}
for (int i = n; i; i -- ) {
f[i] = a[i][n + 1] / a[i][i];
for (int j = i - 1; j; j -- )
a[j][n + 1] -= a[j][i] * f[i];
}
}
高斯消元应用
- 解线性方程组
这个不用我说了吧。。。
- 在 dpdp 中用于消元
这个用处非常大。举个栗子:P3232 [HNOI2013] 游走
题意:给定 nn 点 mm 边无向简单图。要求给每条边重新编号 1∼m1∼m,使得每条边编号不同且从 11 到 nn 经过路径的权值和期望尽可能小。
n≤500,m≤125000n≤500,m≤125000。
发现边数很多,所以从点数入手。设 fifi 表示第 ii 个点被经过的期望次数,那么有:
当然,nn 号点被我们排除在外,因为到了 nn 就停止了。
然后发现,上面的柿子形成了一个 n−1n−1 元方程。用高斯消元解方程就可以得到 fufu。
然后可以得到每条边被经过的期望次数:g(u,v)=fudegu+fvdegvg(u,v)=fudegu+fvdegv。根据边被经过的期望次数贪心赋权即可。
其他用高斯消元求解 dpdp 的例题:P4321 随机漫游
- 矩阵求逆
矩阵 AA 的逆矩阵定义为 A−1A−1,满足 A−1×A=IA−1×A=I 且 A−1×A=IA−1×A=I。其中 II 表示单位矩阵。
求法:将原矩阵 AA 右面拼上一个单位矩阵 II。然后对左边一半也就是 AA 做初等行列变换消成单位矩阵,同时对右边做左边同样的操作(左边行加右边也加,左边同乘右边也同乘)。最后得到的右半边就是 A−1A−1。
证明真的不会/kk
int gauss() {
rep(i, 1, n) {
rep(j, i, n)
if (a[j][i] != 0) {
swap(a[i], a[j]); break;
}
if (a[i][i] == 0) return 0;
rep(j, i + 1, n) {
if (a[j][i] == 0) continue;
int inv = a[j][i] * qpow(a[i][i]) % mod;
rep(k, i, 2 * n) a[j][k] -= inv * a[i][k] % mod,
a[j][k] = (a[j][k] % mod + mod) % mod;
}
}
rep(i, 1, n) {
int inv = qpow(a[i][i]);
rep(j, 1, 2 * n) a[i][j] = a[i][j] * inv % mod;
}
dep(i, n, 1) {
rep(j, 1, i - 1) {
int inv = a[j][i];
rep(k, 1, 2 * n) a[j][k] -= a[i][k] * inv % mod,
a[j][k] = (a[j][k] % mod + mod) % mod;
}
} return 1;
}
signed main() {
read(n); int B = (10 * n + 5) * sizeof(LL);
rep(i, 0, n + 1) a[i] = (LL*)malloc(B);
rep(i, 1, n) rep(j, 1, n) read(a[i][j]);
rep(i, 1, n) a[i][i + n] = 1; int s = gauss();
if (!s) return puts("No Solution"), 0;
for (int i = 1; i <= n; i ++ , pc('\n'))
rep(j, 1, n) write(' ', a[i][j + n]);
return 0;
}
卷积及反演
某些定义
一些常见的积性函数。
-
莫比乌斯函数 μ(n)μ(n)。
-
欧拉函数 φ(n)φ(n):1∼n1∼n 中与 nn 互质的数的个数。
-
约数个数 d(n)d(n):nn 的约数个数。
-
约数和 σσ:∑d|nd∑d|nd。
-
元函数 ϵ(n)ϵ(n)。即 [n=1][n=1]。
-
单位函数 id(n)id(n)。即为 nn。
-
恒等函数 I(n)I(n)。该函数恒为 11。有时也写作 11。
狄利克雷卷积
定义两个数论函数的狄利克雷卷积为 (f∗g)(n)=∑d|nf(d)g(nd)(f∗g)(n)=∑d|nf(d)g(nd),读作 ff 卷 gg。
其中后面括号里的 nn 代表卷积范围。
卷积有下面这些良好的性质:
-
交换律:f∗g=g∗ff∗g=g∗f。
-
结合律:(f∗g)∗h=f∗(g∗h)(f∗g)∗h=f∗(g∗h)。
上面的性质可以根据卷积定义证明。这里略过。
常见数论函数的狄利克雷卷积
- d=1∗1d=1∗1
证明:1∗1=∑d|n1×1=d(n)1∗1=∑d|n1×1=d(n)。
- ϵ=μ∗1ϵ=μ∗1
上文提到过,∑d|nμ=[n=1]=ϵ(n)∑d|nμ=[n=1]=ϵ(n)。
- id=φ∗1id=φ∗1
利用欧拉函数性质证明。
(1)(1) φ(1)=1φ(1)=1
(2)(2) φ(p)=p−1φ(p)=p−1
(3)(3) φ(p2)=p×φ(p)=p2−pφ(p2)=p×φ(p)=p2−p
(4)(4) 根据性质 (3)(3), 推出 φ(pk)=φ(p)×pk−1=pk−pk−1φ(pk)=φ(p)×pk−1=pk−pk−1
(5)(5) c∑i=0φ(pi)=1+c∑i=1φ(pi)=1+c∑i=1pi−pi−1=pcc∑i=0φ(pi)=1+c∑i=1φ(pi)=1+c∑i=1pi−pi−1=pc
(6)(6) 若 n=k∑i=1pciin=k∑i=1pcii,则利用 (5)(5) 和积性函数的性质即可推出。
- φ=μ∗idφ=μ∗id
证明:由于 id=φ∗1id=φ∗1,根据卷积的性质,可以在等式两边同时卷上 μμ,得到 id∗μ=φ∗1∗μid∗μ=φ∗1∗μ。根据 μ∗1=ϵμ∗1=ϵ 得 id∗μ=φ∗ϵ=φid∗μ=φ∗ϵ=φ。证毕。
- σ=id∗1σ=id∗1
证明:σ(n)=∑d|nd=∑d|nid(d)×I(nd)=id∗1(n)σ(n)=∑d|nd=∑d|nid(d)×I(nd)=id∗1(n)。
莫比乌斯反演
莫比乌斯反演的形式如下:
如果存在 F(n)=∑d|nf(d)F(n)=∑d|nf(d),那么有 f(n)=∑d|nF(d)μ(nd)f(n)=∑d|nF(d)μ(nd)。
该结论可以利用狄利克雷卷积来证明。
证明:
F(n)=∑d|nf(d)F(n)=∑d|nf(d) 写成卷积的形式就是 F=f∗1(n)F=f∗1(n)。那么对两边同时卷上 μμ,可得 F∗μ(n)=f∗1∗μ(n)F∗μ(n)=f∗1∗μ(n)。由于 1∗μ(n)=ϵ1∗μ(n)=ϵ,所以原式可化为 F∗μ(n)=f∗ϵ(n)=fF∗μ(n)=f∗ϵ(n)=f,即 f(n)=∑d|nF(d)μ(nd)f(n)=∑d|nF(d)μ(nd)。证毕。
某些例题:
下面求和的上界省略了下取整符号。
P3455 [POI2007]ZAP-QueriesP3455 [POI2007]ZAP-Queries
求 n∑i=1m∑j=1[(i,j)=k]n∑i=1m∑j=1[(i,j)=k]。
大力莫反。
前面的 μμ 可以线筛,后面的可以整除分块套上 μμ 前缀和。
P2522 [HAOI2011]Problem bP2522 [HAOI2011]Problem b
求 b∑i=ad∑j=c[(i,j)=k]b∑i=ad∑j=c[(i,j)=k]。
上一道题的强化版。将上一道题写成函数 calc(n,m,k)calc(n,m,k),表示求 求 n∑i=1m∑j=1[(i,j)=k]n∑i=1m∑j=1[(i,j)=k] 的值。然后利用类似二维前缀和的方式,计算出答案即为 calc(b,d,k)−calc(a-1,d,k)−calc(c-1,b,k)+calc(a-1,c-1,k)calc(b,d,k)−calc(a-1,d,k)−calc(c-1,b,k)+calc(a-1,c-1,k)
首先考虑计算 n∑i=1n∑j=1(i,j)n∑i=1n∑j=1(i,j)。
首先枚举 (i,j)(i,j),得到 n∑d=1dn∑i=1n∑j=1[(i,j)=d]n∑d=1dn∑i=1n∑j=1[(i,j)=d]
继续化简:
φφ 可以前缀和,然后整除分块就好了。复杂度 O(n+√n)O(n+√n),瓶颈在前缀和。
原题要求的就是刚才求的减去 ∑i∑i 之后在除以 22 。这里根据最大公约数的交换律或者对称性易得。
另外,这个题也可以不必卷到 φφ。只要卷到 =n∑d=1dnd∑p=1μ(p)⌊npd⌋⌊npd⌋=n∑d=1dnd∑p=1μ(p)⌊npd⌋⌊npd⌋ 就可以套两层整除分块了。这样的复杂度是 O(n+n)=O(n)O(n+n)=O(n),也很优秀。
一天后返回来在看一眼原来推得式子,会发现确实推复杂了。正难则反,直接用 φ∗1=idφ∗1=id 来推。
可以发现结果是一样的。
设质数集为 PP,求:
又到了愉快的推式子时间:这里设 n≤mn≤m,
然后发现两个下取整可以直接整除分块,瓶颈就在计算 ∑d|k,d∈Pμ(kd) 上。这个玩意可以筛出质数后预处理。
预处理复杂度 O(n+nloglogn),计算复杂度 O(T√n)。总复杂度 O(n+nloglogn+T√n)。
看了一下题解,预处理也可以线性筛。不过不想看了,反正能过就行。
void init() {
mu[1] = 1;
for (int i = 2; i <= N - 5; i ++ ) {
if (!is_prime[i]) p[ ++ cnt] = i, mu[i] = -1;
for (int j = 1; j <= cnt and i * p[j] <= N - 5; j ++ ) {
is_prime[i * p[j]] = true;
if (i % p[j] == 0) break;
mu[i * p[j]] = - mu[i];
}
}
for (int i = 1; i <= cnt; i ++ )
for (int j = 1; p[i] * j <= N - 5; j ++ )
f[p[i] * j] += mu[j];
for (int i = 1; i <= N - 5; i ++ )
s[i] = s[i - 1] + f[i];
}
void substack() {
scanf("%lld%lld", &n, &m);
if (n > m) swap(n, m);
int ans = 0;
for (int l = 1, r; l <= n; l = r + 1) {
r = min(n / (n / l), m / (m / l));
ans += (n / l) * (m / l) * (s[r] - s[l - 1]);
}
printf("%lld\n", ans);
}
设 d(x) 为 x 的约数个数,给定 n,m,求
有结论:d(ij)=∑x|i∑y|j[(x,y)=1]
于是可以愉快地推柿子了。
不妨设 f(n)=n∑i=1⌊ni⌋,可以发现这个玩意就等于 n∑i=1d(i)。而这个东西可以筛 μ 的时候预处理出来。
于是柿子变成 min(n,m)∑d=1μ(d)f(nd)f(md)。整出分块即可。总复杂度 O(T√n)。预处理可以用线性筛,但是懒得写了,直接莽了个 O(nlogn) 暴力上去。
void init(int n) {
mu[1] = 1;
for (int i = 2; i <= n; i ++ ) {
if (!is_prime[i]) p[ ++ cnt] = i, mu[i] = -1;
for (int j = 1; j <= cnt and i * p[j] <= n; j ++ ) {
is_prime[i * p[j]] = true;
if (i % p[j] == 0) break;
mu[i * p[j]] = -mu[i];
}
}
for (int i = 1; i <= n; i ++ )
mu_s[i] = mu_s[i - 1] + mu[i];
for (int i = 1; i <= n; i ++ )
for (int j = i; j <= n; j += i)
s[j] ++ ;
for (int i = 1; i <= n; i ++ )
s[i] += s[i - 1];
}
void substack() {
scanf("%lld%lld", &n, &m);
int ans = 0;
for (int l = 1, r; l <= min(n, m); l = r + 1) {
r = min(n / (n / l), m / (m / l));
ans += s[n / l] * s[m / l] * (mu_s[r] - mu_s[l - 1]);
}
printf("%lld\n", ans);
}
组合数学
定义
Cmn,也记做 (nm),表示从 n 个元素中选择 m 个且不考虑顺序的方案数。有公式:
这个公式是怎么得到的呢?首先,先假设考虑顺序。那么选择第一个数的方案就有 n 种。然后再选一个,就要从剩下的 n−1 个里面选,以此类推。总方案数就是 n!(n−m)!。
那么如果不考虑顺序,那么需要再除以排列数 m!。
对于组合数的讨论,一般规定 0!=1,n≥m。
求法
三种方法求组合数:
- n,m≤5000
可以用杨辉三角来求解。有组合恒等式:
再根据 (n0)=1,O(n2) 递推求解即可。
- n,m≤10000000,答案对 p 取模(p 为质数)
根据上面的公式:(nm)=n!m!×(n−m)!,可以预处理出阶乘和阶乘逆元,然后 O(1) 计算。时间复杂度 O(n)∼O(1)
- n,m≤1018,答案对 p 取模(p 为质数且 p≤105)
引理:Lucas 定理
对于质数 p,有 (nm)≡(⌊np⌋⌊mp⌋)×(nmod pmmod p)(mod p) 恒成立。
组合恒等式及证明
- (nk)=(nn−k)
这个组合意义理解一下好了。从 n 个里面选出 k 个的方案数,也就等于从 n 个里面不选 n−k 个数的方案数。
多项式与生成函数
多项式
开头先扔板子:多项式板子们
定义
多项式(polynomial)是形如 P(x)=n∑i=0aixi 的代数表达式。其中 x 是一个不定元。
∂(P(x)) 称为这个多项式的次数。
多项式的基本运算
- 多项式的加减法
- 多项式的乘法
- 多项式除法
这里讨论多项式的带余除法。
可以证明,一定存在唯一的 q(x),r(x) 满足 A(x)=q(x)B(x)+r(x),且 ∂(r(x))<∂(B(x))。
q(x) 称为 B(x) 除 A(x) 的商式,r(x) 称为 B(x) 除 A(x) 的余式。记作:
特别的,若 r(x)=0,则称 B(x) 整除 A(x),A(x) 是 B(x) 的一个倍式,B(x) 是 A(x) 的一个因式。记作 B(x)|A(x)。
有关多项式的引理
-
对于 n+1 个点可以唯一确定一个 n 次多项式。
-
如果 f(x),g(x) 都是不超过 n 次的多项式,且它对于 n+1 个不同的数 α1,α2⋯αn 有相同的值,即 ∀i∈[1,n+1],i∈Z,f(αi)=g(αi)。则 f(x)=g(x)。
多项式的点值表示
如果选取 n+1 个不同的数 x0,x1,⋯xn 对多项式进行求值,得到 A(x0),A(x1)⋯A(xn),那么就称 {(xi,A(xi)) | 0≤i≤n,i∈Z} 为 A(x) 的点值表示。
快速傅里叶变换(FFT)
快速傅里叶变换是借助单位根进行求值和插值,从而快速进行多项式乘法的算法。
单位根
将复平面上的单位圆均分成 n 份,从 x 轴数,第 i 条线与单位圆的交点称为 i 次单位根,记作 ωin。
根据定义,可以得到:ω1n=isinα+cosα,α=2πn。
引理:欧拉公式
∀θ∈R,eiθ=isinθ+cosθ。
根据欧拉公式,可以得到:ω1n=e2πin。
由此那么可以得到下面的性质:
-
ωin×ωjn=ωi+jn
-
ωi+n2n=−ωin
-
ωi+nn=ωin
另外一种理解方式是通过棣莫弗公式。
引理:棣莫弗公式
∀θ∈R,(cosθ+isinθ)n=cos(nθ)+isin(nθ)
考虑两个复平面上的向量
计算两个向量相乘的结果,可得:
当 θ1=θ2,ρ1=ρ2 时便是大名鼎鼎的棣莫弗公式。
因此可以得到,单位圆上的两个复数相乘,模长不变(也就是还在单位圆上),幅角相加。然后可以由此理解上面的三个单位根性质。
离散傅里叶变换(DFT)
离散傅里叶变换,是将 ωkn,0≤k<n 代入 f(x) 和 g(x) 中求值的过程。
对于朴素的方法,每次代入一个单位根,然后用 O(n) 的复杂度计算函数值。时间复杂度 O(n2)。
离散傅里叶变换利用了单位根的性质巧妙优化了这个过程。离散傅里叶变换过程如下:
首先将 f(x) 根据次数的奇偶性拆成两部分,分别分为:
设
则 f(x)=e′(x2)+xo′(x2)。
将 ωkn 代入得到:
然后你发现,f(ωkn) 和 f(ωk+n2n) 仅仅差了一个符号!!!
所以只需要求出 e′(x) 和 o′(x) 对 ωkn(0≤k≤n2)上的取值,就可以推出 f(x) 在两倍点数上的取值。
每次问题规模缩小一半,因此时间复杂度 O(nlogn)。
离散傅里叶逆变换(IDFT)
假设对于两个多项式都得到了 t=n+m−1 个点值,设为 {(xi,A(xi)) | 0≤i<t,i∈Z},{(xi,B(xi)) | 0≤i<t,i∈Z}。
那么可以知道,多项式 C(x)=A(x)×B(x) 的点值表示一定为:
现在,只需要将这 t 个点插值回去,就可以得到 A(x)B(x) 了。
先设这 t 个点值分别是:{(xi,vi) | 0≤i<t,i∈Z},设最后的多项式为 C(x)=n+m−2∑i=0cixi,这里直接给出结论:
由此可见,IDFT 和 DFT 仅仅有一个负号的区别。只要将所有的单位根从 ωkn 变成 ω−kn 即可。
void FFT(cp a[], int n, int op) {
if (n == 1) return;
cp a1[n], a2[n];
rop(i, 0, n >> 1) a1[i] = a[i << 1], a2[i] = a[(i << 1) + 1];
FFT(a1, n >> 1, op), FFT(a2, n >> 1, op);
cp Wn = {cos(2 * pi / n), op * sin(2 * pi / n)};
cp Wk = {1, 0};
rop(i, 0, n >> 1) {
a[i] = a1[i] + Wk * a2[i];
a[i + (n >> 1)] = a1[i] - Wk * a2[i];
Wk = Wk * Wn;
}
}
void FFT(cp a[], cp b[], int n, int m) {
m = n + m; n = 1;
while (n <= m) n <<= 1;
FFT(a, n, 1); FFT(b, n, 1);
rop(i, 0, n) a[i] = a[i] * b[i];
FFT(a, n, -1);
rep(i, 0, m) a[i].x = a[i].x / n;
}
FFT 优化
- 三次变两次优化
原本的朴素 FFT,将 {a},{b} 两个序列分别求值,乘起来再 IDFT 插值一下,一共跑了三次 FFT。这是不好的。
三次变两次优化是这样的:将原序列合并成一个复数:{ai+bi×i}。做一遍 DFT 把求出的每个函数值平方。因为 (a+bi)2=(a2−b2)+(2abi)。因此把虚部取出来以后除以 2 就是答案。
void FFT(cp a[], int n, int op) {
if (n == 1) return;
cp a1[n], a2[n];
rop(i, 0, n >> 1) a1[i] = a[i << 1], a2[i] = a[(i << 1) + 1];
FFT(a1, n >> 1, op), FFT(a2, n >> 1, op);
cp Wn = {cos(2 * pi / n), op * sin(2 * pi / n)};
cp Wk = {1, 0};
rop(i, 0, n >> 1) {
a[i] = a1[i] + a2[i] * Wk;
a[i + (n >> 1)] = a1[i] - a2[i] * Wk;
Wk = Wk * Wn;
}
}
int main() {
read(n, m);
rep(i, 0, n) scanf("%lf", &a[i].x);
rep(i, 0, m) scanf("%lf", &a[i].y);
m = n + m; n = 1;
while (n <= m) n <<= 1;
FFT(a, n, 1);
rop(i, 0, n) a[i] = a[i] * a[i];
FFT(a, n, -1);
rep(i, 0, m) printf("%d ", (int)(a[i].y / 2 / n + 0.5));
}
- 蝴蝶变换优化
后面再补吧。其实本人感觉这个优化不是那么必要,因为三次变两次实在太快了。
FFT 例题
可以设 x=10,把 a 写成 A(x)=n∑i=0aixi 的形式(n=log10a)。同理可以把 b 转化为多项式 B(x)。
这样求两个数相乘就是求 A(x)×B(x) 啊。
所以直接 O(nlogn) 做完了。
给出 n 个数 q1,q2,…qn,定义
对 1≤i≤n,求 Ei 的值。
首先发现这个除以 qi 就是没用。所以可以化简成:
先看前面这个式子。答案就是:
设 f(x)=∑qixi,g(x)=1i2xi。可以发现,E′j=(f×g)[j]
再看后面这一块的式子。我们把 f(x) 的系数翻转,变成 f′(x)=∑qn−j+1xj。那么可以发现 E″j=(f′×g)[n−j+1]。
跑两次 FFT 就完事了。
首先发现加减相对于两个手环是对称的。因此可以把对一个手环的减法转化成对另一个手环的加法。这样可以假设全是在第一个手环上执行的加减操作。
第一个手环执行了加 c 的操作,且旋转过之后的序列为 [x1,x2⋯xn],第二个手环为 [y1,y2⋯yn]。计算差异值并化简,可以得到差异值是:
可以发现,这个序列只有最后一项是不定的。
因此将 y 序列翻转后再复制一倍,与 x 卷积,答案就是卷积后序列的 n+1∼2n 项系数的 max。
直接暴力枚举 c,加上前面依托就行了。
快速数论变换(NTT)
快速数论变换就是基于原根的快速傅里叶变换。
首先考虑快速傅里叶变换用到了单位根的什么性质。
-
ωkn,0≤k<n 互不相同。
-
ωkn=ωk+n2n。
-
ωkn=ω2k2n。
数论中,原根恰好满足这些性质。
对于一个素数的原根 g,设 gn=gp−1n。那么:
我们发现它满足 ωkn 的全部性质!
因此,只需要用 gkn=gp−1nk 带替全部的 ωkn 就可以了。
tips:对于一个质数,只有当它可以表示成 p=2α+1,且需要满足多项式的项数 <α 时才能使用 NTT。p 后面有个加一,是因为 gn 指数的分子上出现了 −1;p−1 需要时二的整数次幂,是因为每次都要除以 2。
bonus:常用质数及原根
p=998244353=119×223+1,g=3
p=1004535809=479×221+1,g=3
void NTT(int *a, int n, int op) {
if (n == 1) return;
int a1[n], a2[n];
rop(i, 0, n >> 1) a1[i] = a[i << 1], a2[i] = a[(i << 1) + 1];
NTT(a1, n >> 1, op), NTT(a2, n >> 1, op);
int gn = qpow((op == 1 ? g : invg), (mod - 1) / n), gk = 1;
rop(i, 0, n >> 1) {
a[i] = (a1[i] + 1ll * gk * a2[i]) % mod;
a[i + (n >> 1)] = (a1[i] - 1ll * gk * a2[i] % mod + mod) % mod;
gk = 1ll * gk * gn % mod;
}
}
NTT 优化:蝴蝶变换
盗大佬一张图

这是进行 NTT 的过程中数组下标的变化。
这样看似乎毫无规律。但是把他们写成二进制:
变换前:000 001 010 011 100 101 110 111
变换后:000 100 010 110 001 101 011 111
可以发现,就是对每个下标进行了二进制翻转。
因此可以先预处理出每个下标在递归底层对应的新下标。然后从底层往顶层迭代合并。
预处理每个下标的二进制翻转:
rop(i, 0, n) rev[i] = rev[i >> 1] >> 1 | (i & 1) << bit;
优化后的 NTT:
void NTT(int *a, int n, int op) {
rop(i, 0, n) if (i < rev[i]) swap(a[i], a[rev[i]]);
for (int mid = 1; (mid << 1) <= n; mid <<= 1) {
int gn = qpow((op == 1 ? g : invg), (mod - 1) / (mid << 1));
for (int i = 0, gk = 1; i < n; i += (mid << 1), gk = 1)
for (int j = 0; j < mid; j ++ , gk = 1ll * gk * gn % mod) {
int x = a[i + j], y = 1ll * a[i + j + mid] * gk % mod;
a[i + j] = Mod(x + y), a[i + j + mid] = Mod(x - y);
}
}
}
当然了,FFT 也可以用蝴蝶变换来优化。实践证明,速度变快了至少二分之一。
FFT 的迭代实现
void FFT(cp *a, int n, int op) {
rop(i, 0, n) if (i < rev[i]) swap(a[i], a[rev[i]]);
for (int mid = 1; (mid << 1) <= n; mid <<= 1) {
cp Wn = {cos(pi / mid), op * sin(pi / mid)};
for (int i = 0; i < n; i += (mid << 1)) {
cp Wk = {1, 0};
for (int j = 0; j < mid; j ++ , Wk = Wk * Wn) {
cp x = a[i + j], y = Wk * a[i + j + mid];
a[i + j] = x + y, a[i + j + mid] = x - y;
}
}
}
}
任意模数多项式乘法(MTT)
计算 f×g(mod p) 的结果(p 不一定能够表示成 2α+1 的形式)。
这个东西有两种做法,但是我只学会了三模 NTT。
首先,卷积之后每个系数最多达到 max{V}2×n 的大小。拿模板题举例,这个东西就是 1023。因此只需要找三个模数 p1,p2,p3,满足 p1p2p3>max{V}2×n,然后用他们分别 NTT,最后再 CRT / exCRT 合并即可。
int CRT(int a, int b, int c, int p) {
int k = 1ll * Mod(b - a, p2) * inv1 % p2;
LL x = 1ll * k * p1 + a;
k = 1ll * Mod((c - x) % p3, p3) * inv2 % p3;
x = (x + 1ll * k * p1 % p * p2 % p) % p;
return x;
}
void MTT(int *a, int n, int *b, int m, int p) {
int B = ((n + m) << 2) + 1;
rev = new int [B]();
int *a1 = new int [B](), *b1 = new int [B]();
int *a2 = new int [B](), *b2 = new int [B]();
int *a3 = new int [B](), *b3 = new int [B]();
rop(i, 0, B)
a1[i] = a2[i] = a3[i] = a[i], b1[i] = b2[i] = b3[i] = b[i];
NTT(a1, n, b1, m, p1); NTT(a2, n, b2, m, p2); NTT(a3, n, b3, m, p3);
inv1 = inv(p1, p2); inv2 = inv(1ll * p1 * p2 % p3, p3);
rep(i, 0, n + m) a[i] = CRT(a1[i], a2[i], a3[i], p);
}
这里选择的模数为:p1=998244353,p2=469762049,p3=1004535809。他们的原根都为 g=3。
多项式求逆
求多项式 f(x) 的逆元 f−1(x)。f(x) 的逆元定义为满足 f(x)g(x)=1(mod xn) 的多项式 g(x)。
使用倍增法即可求出多项式的逆元。
首先假设已经求出了 f(x)g′(x)≡1(mod x⌈n2⌉)。再假设 f(x)mod xn 意义下逆元为 g(x)。那么有:
两边同时乘以 f(x),可以得到:
倍增求即可。
void Inv(int *f, int *g, int n) {
if (n == 1) {
g[0] = inv(f[0]); return;
} Inv(f, g, (n + 1) >> 1);
int m = 1, bit = 0;
while (m < (n << 1)) m <<= 1, bit ++ ; bit -- ;
rop(i, 0, n) tmp[i] = f[i];
rop(i, n, m) tmp[i] = 0;
rev = new int [m + 5]();
rop(i, 1, m) rev[i] = (rev[i >> 1] >> 1) | (i & 1) << bit;
NTT(tmp, m, 1); NTT(g, m, 1);
rop(i, 0, m) g[i] = (2ll - 1ll * g[i] * tmp[i] % p + p) % p * g[i] % p;
NTT(g, m, -1); int invn = inv(m);
rop(i, 0, m) g[i] = 1ll * g[i] * invn % p;
rop(i, n, m) g[i] = 0;
free(rev); rev = NULL;
}
分治 FFT
给定序列 g1…n−1,求序列 f0…n−1。
其中 fi=∑ij=1fi−jgj,边界为 f0=1。
答案对 998244353 取模。
其实这是个多项式求逆板子
首先考虑生成函数 F(x)=∑+∞i=0fixi,G(x)=∑+∞i=0gixi。然后可以发现:
因此 F(x)(G(x)−1)=−f0,也就是:
所以直接设 g0=0,然后把 1−g 求逆就行了。
read(n);
rop(i, 1, n) read(g[i]);
rop(i, 1, n) g[i] = Poly::p - g[i];
(g[0] += 1) %= Poly::p; Poly::Inv(g, n);
rop(i, 0, n) write(' ', g[i]); return 0;
多项式对数函数(Polyln)
给定 f(x),求多项式 g(x) 使得 g(x)≡ln(f(x))(mod xn)
前置知识:简单的求导和积分,以及基本的多项式模板。
首先设 h(x)=ln(x),那么
然后对同余方程两边同时求导,得到
根据复合函数求导公式 f′(g(x))=f′(g(x))g′(x) 可得,
然后又有 ln′(x)=1x,因此
计算 f′(x) 和 f−1(x) 作为 a,b。计算 a×b(mod 998244353) 得到 g′(x) ,然后求 g′(x) 的积分就好了。
积分公式:∫xadx=1a+1xa+1。
void der(int *f, int n) { rep(i, 1, n) f[i - 1] = 1ll * i * f[i] % p; f[n] = 0; }
void Int(int *f, int n) {dep(i, n, 1) f[i] = 1ll * inv(i) * f[i - 1] % p; f[0] = 0; }
void Ln(int *f, int n) {
int B = (n << 2) + 5; int *_f = new int[B]();
rep(i, 0, n) _f[i] = f[i];
der(_f, n), Inv(f, n);
NTT(f, n, _f, n); Int(f, n);
free(_f); _f = NULL;
}
多项式指数函数(PolyExp)
给定多项式 f(x),求 g(x) 满足 g(x)≡ef(x)(mod xn)。
前置知识:牛顿迭代。
牛顿迭代是用来求函数零点的有力工具。
例如,下面这个图是使用牛顿迭代法求 f(x)=x4+3x2+7x+3 零点的过程。
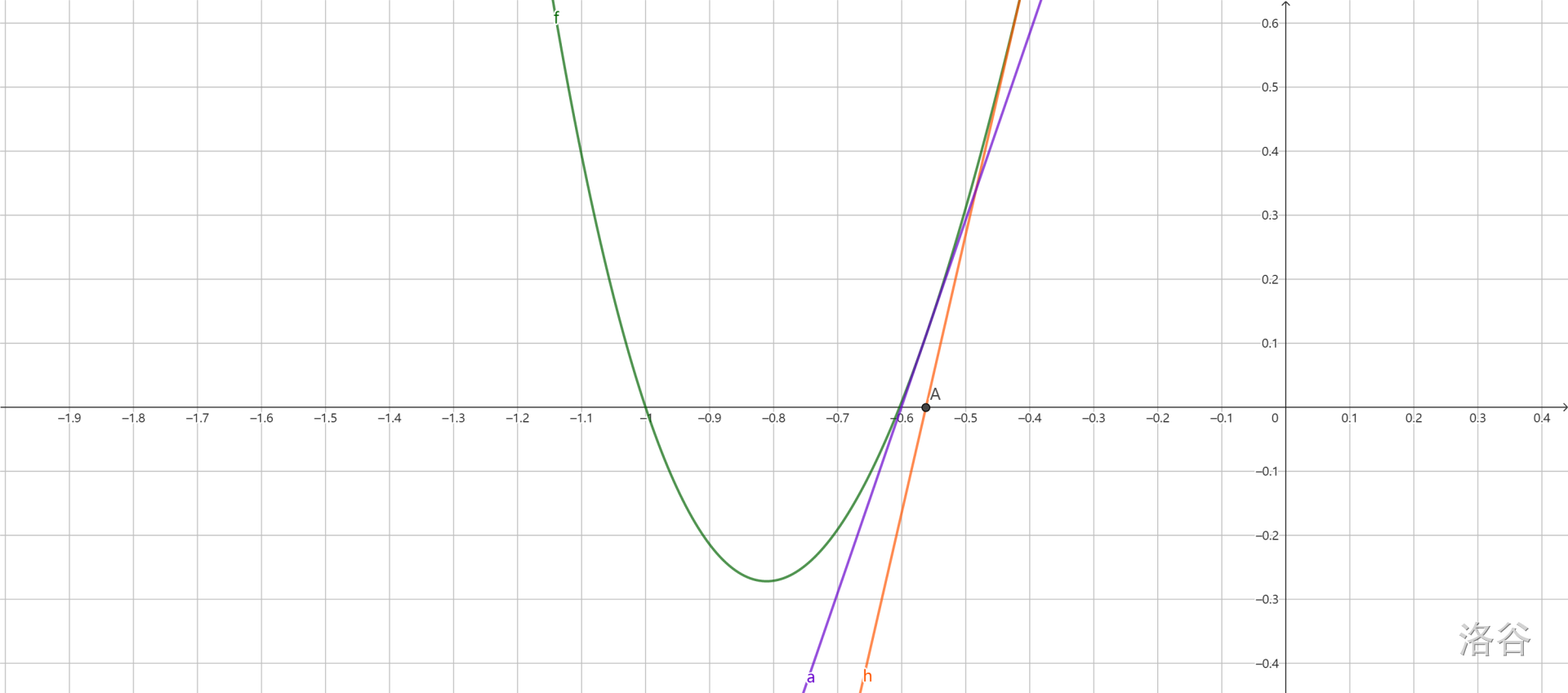
首先,随便选择一个点 (x0,f(x0)),过这个点做 f(x) 的切线。切线方程是 y=f′(x0)(x−x0)+f(x0)。它与 x 轴交于一点 A(−0.56243,0)。
接下来,再令 x1=−0.56243,过点 (x1,f(x1)) 再做 f(x) 的切线,与 x 轴交于点 B(−0.60088,0)。
再令 x2=−0.60088,如此迭代下去。可以发现,xn 会逐渐逼近零点。
刚才说切线方程为 y=f′(x0)(x−x0)+f(x0)。如果令 y=0,得到的 x 便是切线方程与 x 轴的交点,为
运用于多项式,假设要求使 f(g(x))≡0(mod xn) 的多项式 g(x),并且已经知道 f(g0(x))≡0(mod xn2)。
那么可以说,
接下来解决多项式 Exp。所求为 g(x) 使得 g(x)≡ef(x)(mod xn)。两边都取 ln 得到:
移项得:
设 F(g(x))=lng(x)−f(x),那么所求就是 F(x) 的零点。
假设已经有 g0(x) 使得 F(g0(x))≡0(mod xn2),根据上面的牛顿迭代,有:
根据这个柿子倍增求即可。每次需要计算一个 ln,一个乘法,时间 O(nlogn)。
写的有点丑,超级大肠数。
void Exp(int *f, int *g, int n) {
if (n == 1) return void(g[0] = 1);
Exp(f, g, (n + 1) >> 1);
int B = (n << 2) + 5; int *lnb = new int[B]();
rop(i, 0, n) lnb[i] = g[i]; Ln(lnb, n);
tmp = new int[B](); rop(i, 0, n) tmp[i] = f[i];
rop(i, 0, n) tmp[i] = (1ll * tmp[i] - lnb[i] + p) % p;
tmp[0] ++ ; NTT(g, n, tmp, n);
free(tmp); tmp = NULL; free(lnb); lnb = NULL;
}
多项式快速幂(PolyPower)
在模 xn 意义下计算 fk(x)。
有了前面的知识铺垫,这部分就非常的简单。
根据对数恒等式,有 f(x)=elnf(x)。
因此 fk(x)=eklnf(x)。
把 f(x) 乘以 k,求多项式 ln,然后再 exp 回来就行了。
void Power(int *f, int n, int k) {
Ln(f, n); rop(i, 0, n) f[i] = 1ll * f[i] * k % p; Exp(f, n);
}
多项式开根
在模 xn 意义下计算 f1k(x)。
这个最简单。直接把 1kmodp,然后多项式快速幂。
生成函数
定义
定义形如 f(x)=∞∑i=0aixi 的式子为生成函数,其中 x 是一个不定元,取值需要保证 f(x) 收敛。需要注意的是,x 在生成函数中并不以未知数的形式单独出现,其意义也脱离了代数上的未知数本身。
生成函数大致分为两种:OGF 和 EGF。前者主要用于无标号问题的计数,后者主要应用于有标号问题的计数。
为了书写方便,在下文中,将 a0+a1x+a2x2⋯ 简写成 {a0,a1,a2⋯}。
约定
-
为了书写方便,在下文中,将 a0+a1x+a2x2⋯ 简写成 {a0,a1,a2⋯}。
-
将 f(x) 中 xi 的系数记为 [xi]f(x),简记为 f(x)[i]。
数学基础
- D 算子(求导算子)
Df(x)=limδ→0f(x+δ)−f(x)δ。
对于 f(x)[i],对其施加以求导算子之后,(Df(x))[i]=(i+1)f(x)[i+1]。
- 上升幂和下降幂
定义 xm_ 为 x 的 m 次下降幂,xm_=x(x−1)(x−2)⋯(x−m+1)。
定义 x¯m 为 x 的 m 次上升幂,x¯m=x(x+1)(x+2)⋯(x+m−1)。
下面是关于上升 / 下降幂的有用的性质:
-
xm+n_=xm_(x−m)n_
-
x¯m+n=x¯m(x+m)¯n
-
xm_=(−1)m(−x)¯m
-
x¯m=(−1)m(−x)m_
-
Δ 算子(差分算子)
类似求导算子,我们定义差分算子 Δ,Δf(x)=f(x+1)−f(x)。
它不具有求导算子那样优美的性质,但是其对于下降幂来说,与求导的运算法则相同。具体的,Δ(xm_)=mxm−1_。
可以发现,差分算子和求导算子十分相似,他们也有一些比较相似的性质,例如:D(ex)=ex,Δ(2x)=2x。
后面的两个公式常用于上升幂和下降幂的转化。
生成函数的封闭形式
对于 OGF,其常常有自己的封闭形式。下面举几个例子。
- Example 4.1: {1,1,1,1⋯} 的生成函数。
这是 OIer 最喜闻乐见的式子。不妨设 f(x)=∞∑0xi,则有 xf(x)=∞∑1xi。可以发现,这相当于对 f 施加了 平移算子 E。将两个错项相减可以得到:
我们称 11−x 为 f(x) 的封闭形式。上面计算生成函数封闭形式的做法称为错位相减,是小学数学常用的一种方法。
利用上面的算法,可以求出下面几个生成函数的封闭形式:
-
{1,1,1,1⋯}OGF⟶11−x
-
{1,a,a2,a3⋯}OGF⟶11−ax
-
{1,xk,x2k,x3k⋯}OGF⟶11−xk
-
{1,c1xk,c2x2k⋯}OGF⟶11−cxk
-
{0,1,12,13⋯}OGF⟶−ln(1−x)
-
{1,1,12!,13!⋯}OGF⟶ex
-
{1,1,1⋯}OGF⟶11−x
封闭形式的展开技巧
- 泰勒展开 / 麦克劳林展开
上面的式子称为麦克劳林展开。注意,上面的式子没有考虑到 f 的敛散性。
通过麦克劳林展开,我们可以得到几乎所有函数的展开式。
- 换元法
利用上面得到的重要结论
将其中的 x 换成 qx,可以得到:
可以使用还原得到一些其他结论。
Example 5.1 求 f(x)=31−4x 的展开形式。
Example 5.2 求 f(x)=11+x 的展开式。
Example 5.3 求 f(x)=53−4x 的展开式。
可以发现,这个方法非常好用。它可以展开几乎一切分母为一次的分式。
- 裂项法
上面的换元法非常好用,但是只适用于 −1 次的式子。对于高次的式子,我们尝试将他变成 −1 次的进行解决。
Example 5.4 求 f(x)=1x2−4x+3 的展开式。
考虑到分母可以表示成 (1−x)(3−x) 的形式,我们尝试裂项。
不妨设 f(x)=1(1−x)(3−x)=A1−x+B3−x 的形式。
可以发现,A1−x+B3−x=A(3−x)+B(1−x)(1−x)(3−x)
于是有 A(3−x)+B(1−x)=1。解这个方程,得到:
对于分母更高次的情况,只要有实根,就可以裂项降次。
- 递推法
这个方法用于补裂项法的坑。
有的时候,分母是高次方程且没有实根,这非常不好,因为没法裂项。这时候可以使用这个方法。
Example 5.5 求 f(x)=11−2x+7x2 的展开形式。
我们发现对于分母,Δ=4−28<0,因此没有实根,无法裂项。
考虑设 f(x)=11−2x+7x2=a0+a1x+a2x2⋯
则有
做一下这个卷积,可以得到
因此,a0=1,a1=2,对于 n>1,an=2an−1−7an−2。这样我们得到一个递推形式。
利用特征根方程即可求出该递推式的通项。
学了上面这么多展开技巧,我们来举几个实际例子。
Example 5.6 斐波那契数列通项
定义 f0=0,f1=1,∀n≥2,fn=fn−1+fn−2。求 f 的通项。
不妨设 F(x)=∑fixi={0,1,1,2,3,5,8⋯}
我们对 F 施加一个平移算子,也就是乘上 x,得到
再施加一次平移算子,得到
可以发现,(F(x)−xF(x)−x2F(x))[n]=0(As for x≥2)。对于 x<2,我们强行补上即可。所以得到:
这样我们得到了 F(x) 的封闭形式。
接下来我们要对这个封闭形式进行展开。发现分母有实根,这非常好。我们求出它的两个实根,分别为
采用展开技巧中的裂项法对他进行裂项,得到
可以解得 A=√55,B=−√55。
将 A,B 代入并进行一顿化简(化简过程使用换元法)后,可以得到斐波那契数列的通项公式:
普通型生成函数的应用
Example 6.1 ACW 3132
一共八种物品,你要买这些物品。每个物品可以买无限件。
不妨将这八种物品设为 A,B,C,D,E,F,G,H,每种物品的购买有限制:
-
A:只能购买偶数个。
-
B:只能购买 0 个或 1 个。
-
C:只能购买 0 个,1 个或 2 个。
-
D:只能购买奇数个。
-
E:只能购买 4 的倍数个。
-
F:只能购买 0,1,2 或 3 个。
-
G:只能购买 ≤1 个。
-
H:只能购买 3 的倍数个。
求购买 n 个物品的方案数。n≤10500,答案对 10007 取模。
做法一:背包。设 fi 表示选择了 i 个物品的方案数。转移即可。
做法二:流氓算法。使用背包打表,用 BM 弄出通项。
做法三:使用生成函数。
我们考虑每种物品的生成函数对应的是什么。对于 A 物品,不妨将其生成函数设为 A(x),后面同理。
-
A(x)=1+x2+x4+⋯=11−x2
-
B(x)=1+x=1−x21−x
-
C(x)=1+x+x2=1−x31−x
-
D(x)=x+x3+x5+⋯=x1−x2
-
E(x)=1+x4+x8+⋯=11−x4
-
F(x)=1+x+x2+x3=1−x41−x
-
G(x)=1+x=1−x21−x
-
H(x)=1+x3+x6+⋯=11−x3
把这些东西乘起来消消乐,剩下的答案就是:
这样我们得到了封闭形式。展开就可以得到答案。我们尝试对这个东西进行展开。利用广义二项式定理,我们可以得到:
乘上 x 相当于对其施以平移算子,答案即为
Bonus:最后对于 1(1−x)4 的化简,其实有更简单的方法。
对于 11−x 求三阶导,发现就等于 1(1−x)4。
Example 6.2 P2000 拯救世界
和上一题差不多,列出来十个生成函数,乘起来消消乐就可以了。
Example 6.3 Super Poker II
写出四种扑克的 OGF,乘起来就可以了。由于没有绑账号所以没有写。
Some Important Tricks
- 对 F(x) 乘以 A(x)=1+x+x2+x3⋯,可以求出 F(x) 的前缀和。例子:差分与前缀和
指数型生成函数
指数型生成函数(EGF),通常用于有标号方案计数,如图计数等。
对于数列 P,其 EGF 定义为:
下面是一些常见数列的 EGF。
-
{1,1,1,1⋯}EGF⟶ex
-
{1,−1,1,−1⋯}EGF⟶e−x
-
{1,c,c2,c3⋯}EGF⟶ecx
-
{1,0,1,0⋯}EGF⟶ex+e−x2
-
{1,a,a2,a3,a4⋯}EGF⟶(1+x)a
上述推导可以直接在 0 处泰勒展开。
指数型生成函数应用
- 图计数
Example 8.1
n 个点的无向连通图计数。
设 B=∑2(i2)xi,表示无向图的方案数。
设 A=∑fixi,表示无向连通图方案数。
则有 B=eA,将 B 取 ln 可以得到 A。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 记一次.NET内存居高不下排查解决与启示