模型评估
在机器学习中,模型评估指标是判断模型性能的关键。让我们一起探讨一下分类问题的混淆矩阵和各种评估指标的计算公式。
首先,我们来看一下常见的分类问题评估指标:
-
准确率 (Accuracy):预测正确的结果占总样本的百分比,计算公式为:
\[\text{准确率} = \frac{TP + TN}{TP + TN + FP + FN}\]其中TP表示真正例(模型将正类别预测为正类别的样本数)、TN表示真负例(模型将负类别预测为负类别的样本数)、FP表示假正例(模型将负类别预测为正类别的样本数)、FN表示假负例(模型将正类别预测为负类别的样本数),尽管准确率可以判断总体的正确率,但在样本不平衡的情况下,它并不能作为很好的指标来衡量结果。
-
精确率 (Precision):所有被预测为正的样本中实际为正的样本的概率,计算公式为:
\[ \text{精确率} = \frac{TP}{TP + FP} \]
精确率代表对正样本结果中的预测准确程度。
-
召回率 (Recall):实际为正的样本中被预测为正样本的概率,计算公式为:
\[ \text{召回率} = \frac{TP}{TP + FN} \]
召回率用于关注实际坏用户被预测出来的概率。
-
F1 分数:综合精确率和召回率的表现,计算公式为:
\[ F1 = \frac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} \]
-
ROC 曲线和AUC 曲线:ROC 曲线是接受者操作特征曲线,AUC 是 ROC 曲线下的面积。这两个指标用于评估分类模型的性能。
二.KNN算法对鸢尾花分类的模型评估
使用交叉验证来获得KNN算法的评估结果。
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split, cross_val_score from sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
创建一个字典来存储不同K值的交叉验证分数
k_scores = {}
尝试不同的K值,并计算交叉验证分数
for k in range(1, 21):
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X_train, y_train, cv=5, scoring='accuracy')
k_scores[k] = np.mean(scores)绘制K值与交叉验证分数的关系图
plt.figure(figsize=(10, 6))
plt.plot(list(k_scores.keys()), list(k_scores.values()), marker='o', linestyle='--')
plt.title('K值与交叉验证分数的关系')
plt.xlabel('K值')
plt.ylabel('交叉验证分数')
plt.xticks(np.arange(1, 21, step=1))
plt.grid(True)
plt.show()
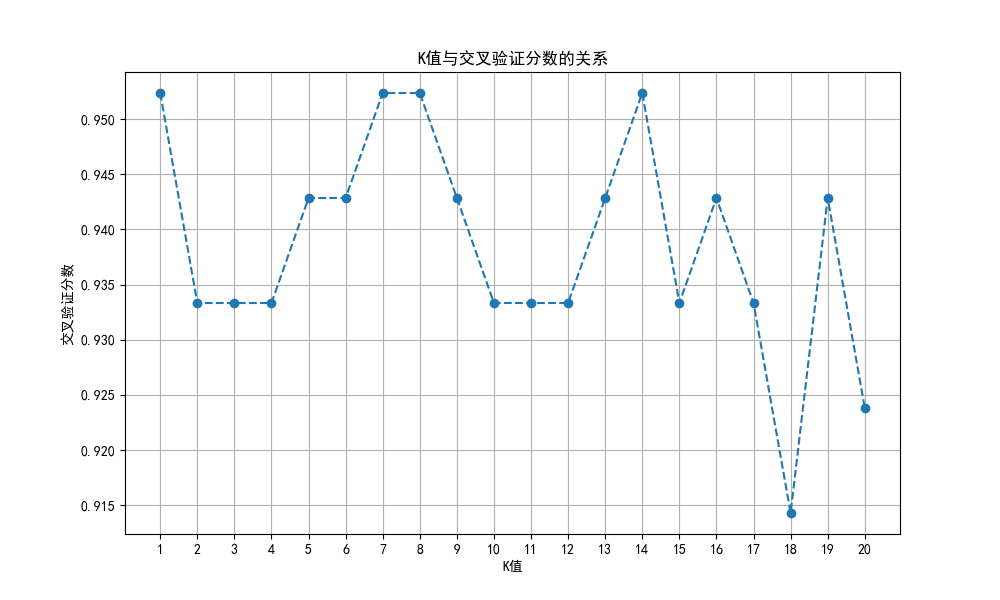
在这个图中,X轴代表K值,Y轴代表交叉验证分数。
-
选择最优的K值:观察曲线,找到使交叉验证分数最高的K值。通常来说,K值在一定范围内增大时,模型的准确性会先增加后减小,因此你需要找到准确性最高的K值。
-
高偏差与高方差的权衡:K值的选择涉及到偏差-方差权衡。较小的K值会导致模型具有较低的偏差但较高的方差,反之,较大的K值会导致模型具有较高的偏差但较低的方差。你需要根据具体情况选择合适的K值,以平衡偏差和方差,从而获得最佳的模型性能。
-
模型的稳定性:观察曲线的变化情况,如果曲线波动较大,说明模型对K值的选择比较敏感,可能存在较大的不稳定性。在这种情况下,你可能需要采取进一步的措施来提高模型的稳定性,例如增加数据量或采用其他算法。
-
验证结果的可信度:交叉验证分数越高,表示模型在未见过的数据上的泛化能力越强。因此,你可以根据交叉验证分数的高低来评估模型的表现,并决定是否需要进一步优化模型或增加数据特征。
综上所述,分析K值与交叉验证分数的关系图可以帮助你选择最佳的K值,并评估模型的性能和稳定性,从而做出更加准确的预测和决策。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号