反向传播(Back Propagation):
视频教程
1.代码说明:
- forward 计算loss
- backward 反向计算梯度
- 由sgd再更新W权重
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0])#选择权重,w=【1.0】
w.requires_grad = True#提醒w需要计算梯度
def forward(x):
return x * w
#w是tensor,二者相乘,x自动类型转换成tensor, x*w输出构建计算图(w需要计算梯度,所以输出结果也需要计算梯度)
# 损失函数:动态构建计算图
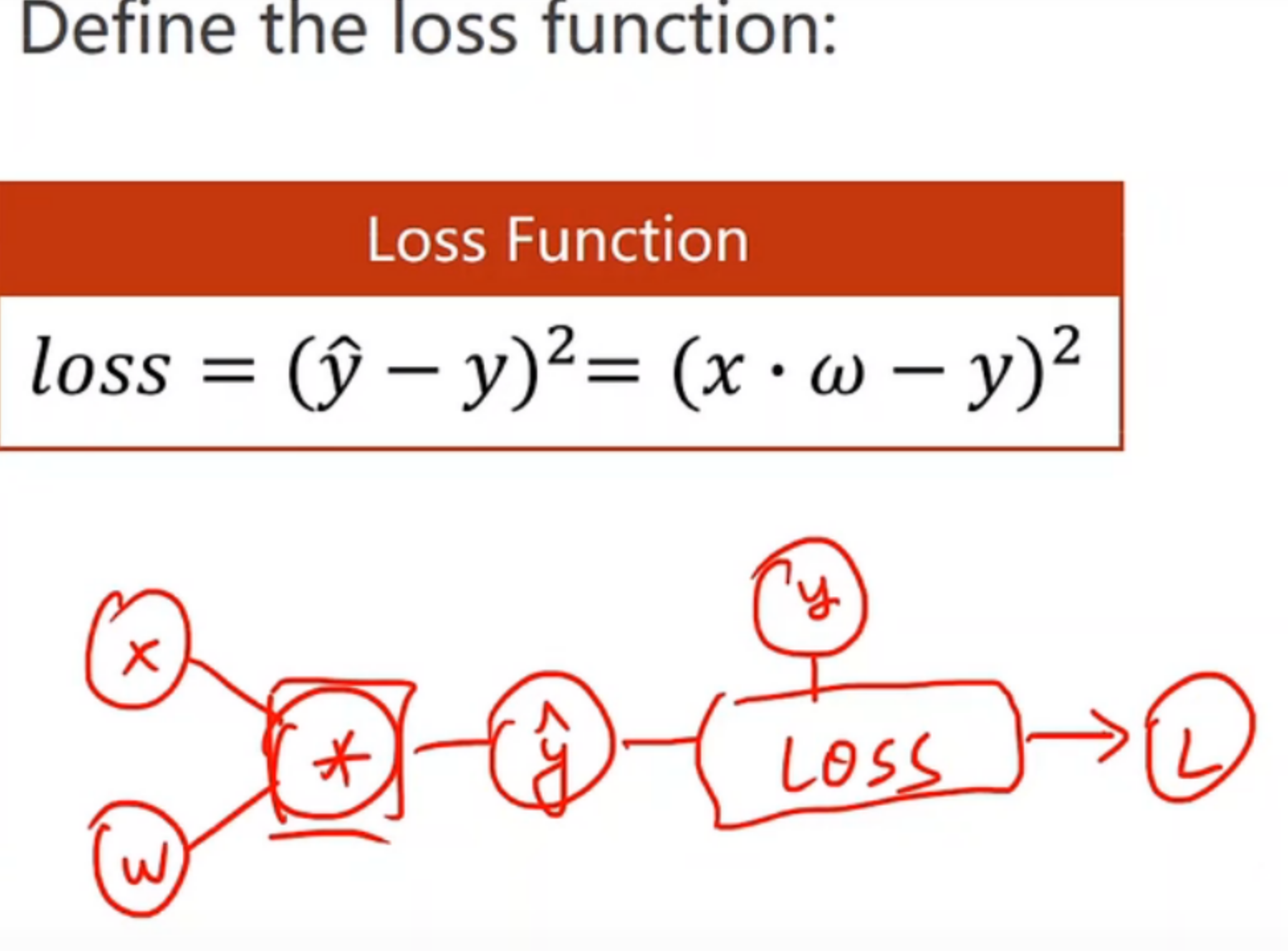
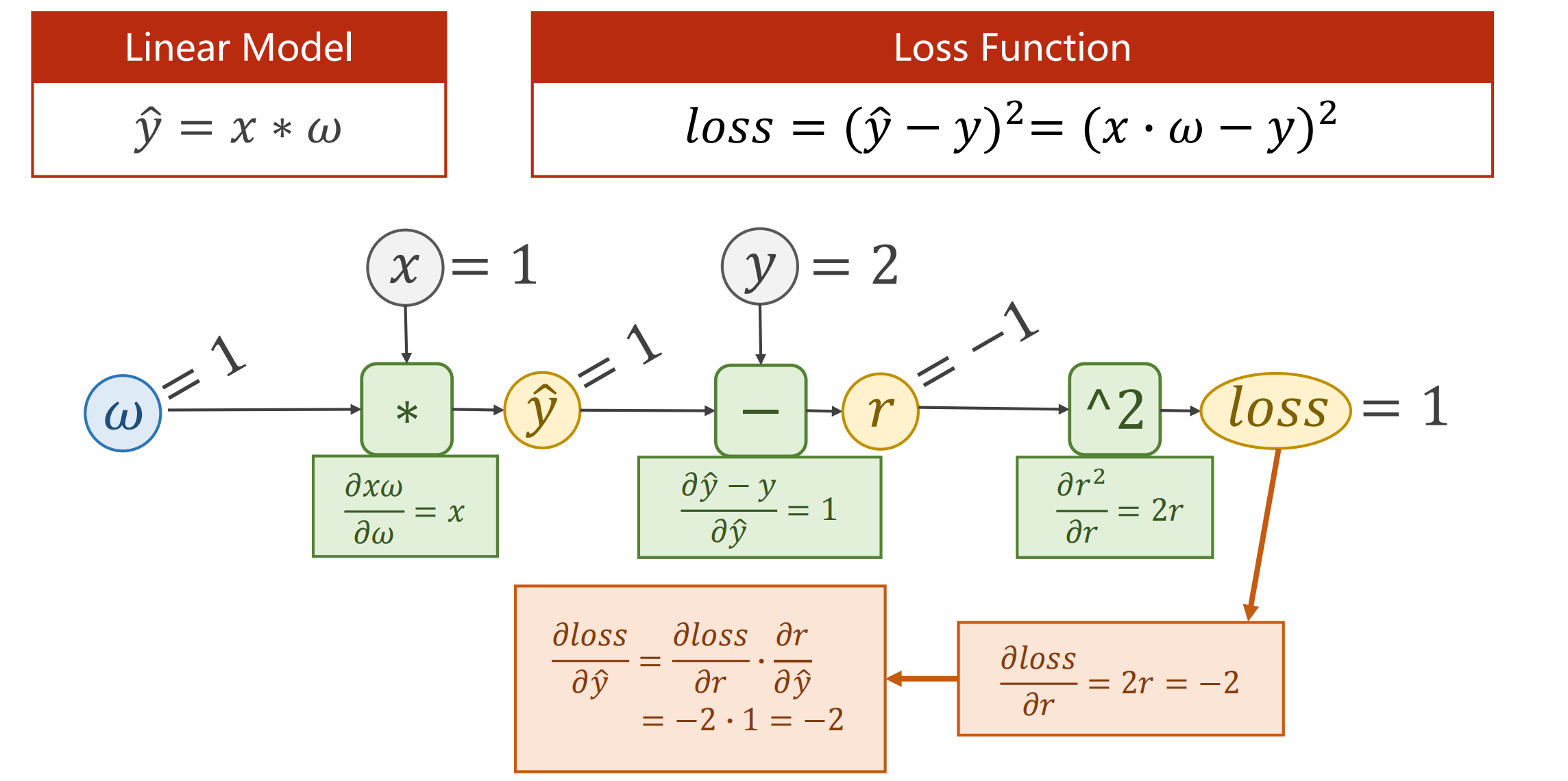
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
构建的计算图:
![image]()
print("predict (before training)",4, forward(4).item())
for epoch in range(100):#进行100轮
for x, y in zip(x_data,y_data):#每次从x_data,y_data 中组一个样本(x,y)
l = loss(x,y) #forward:计算样本损失
l.backward()#backward:从loss 开始,将链路上所有需要计算梯度的值自动计算出
print('\tgrad:',x,y,w.grad.item())#将计算的梯度存到grad中,item将梯度中数值取出来变成标量,防止产生计算图
w.data = w.data - 0.01 * w.grad.data
#将权重的数值进行修改,注意,此处就是纯计算,用.data,不是张量求梯度
w.grad.data.zero_()# 权重梯度的数据全部清0,保证w改变,得到相应梯度
print('progress:',epoch,l.item())#输出轮数与 损失值
print("predict(after training)",4, forward(4).item())
注意:
- w是Tensor(张量类型),Tensor包含data,grad,他们都是Tensor,grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用w.grad.data。(此处理解:张量用来构建计算图,更改W的值得用.data
- 在构建计算图中,与W相关的Tensor都需要求梯度
- l.backward()会把计算图中所有需要梯度(grad)的地方都会求出来,然后把梯度都存在对应的待求的参数中,最终计算图被释放。
- 更新权重,记得要设置grad为0,
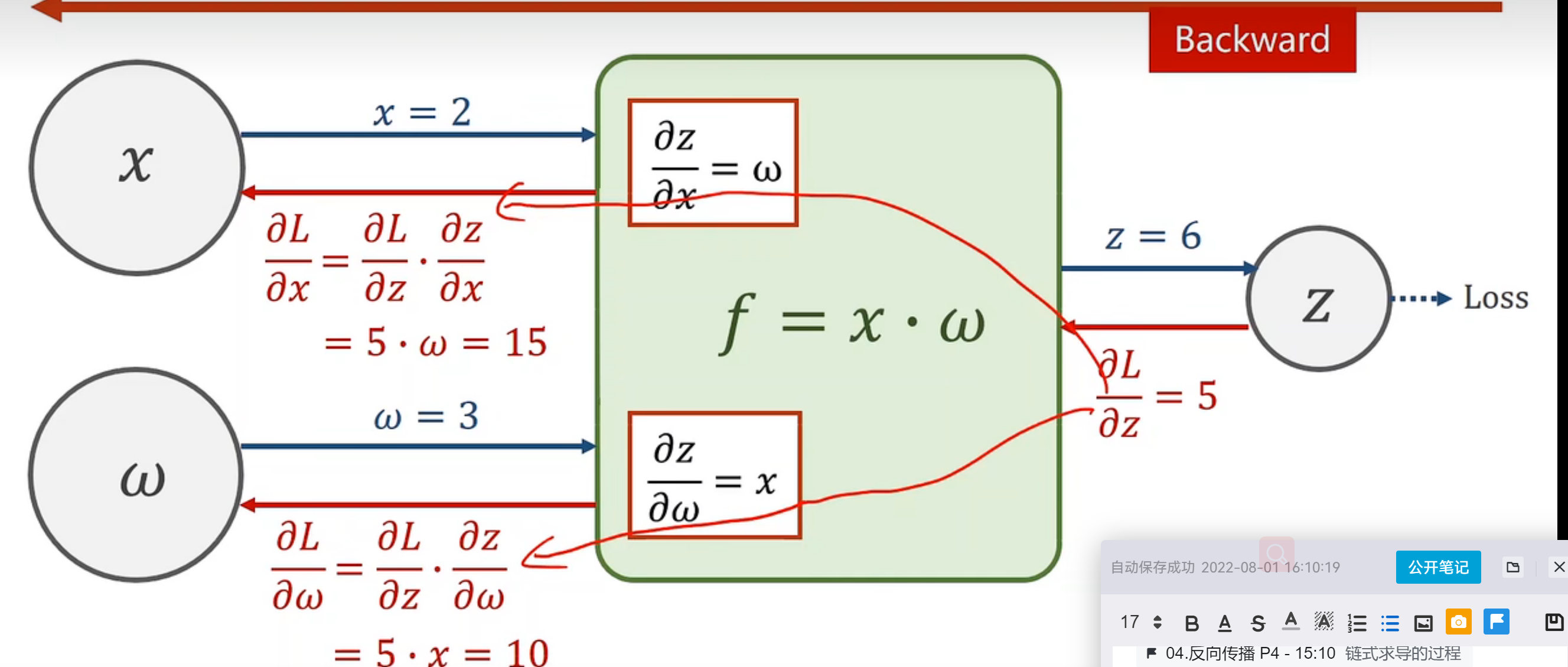
2.计算说明:
- forward:给了x与权重的量,在f模块中计算局部梯度,向前层层得出z的值,计算loss值。
- backward:计算loss与输出量z的偏导,一步步向前计算l与x,w的导数,一步步传播梯度。
![image]()
![image]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号