

数据挖掘模型学习--分类
目录
1 数据处理
1.1 读取数据集
data = pd.read_excel('./data/bankloan.xls')
print(data.head())
print(data.shape)
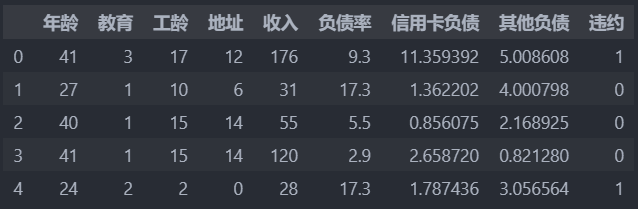
共700条数据,前8列为特征,最后1列为标签,'0'代表未违约,'1'代表违约
1.2 数据集划分
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
将特征与标签分别提取出来后,再进行训练集与测试集的划分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=4)
2 使用K近邻(KNN)进行分类
2.1 模型初始化与训练
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train, y_train)
2.2 模型预测与评估
from sklearn.metrics import classification_report
pred = knn.predict(X_test)
print(classification_report(y_test, pred))
得到结果如下:
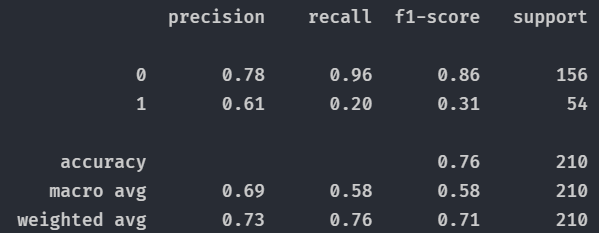
可以看出分类的准确率为76%
2.3 画出混淆矩阵
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[y, x], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
cm_plot(y_test, pred)
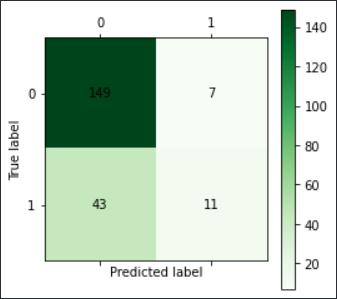
3 使用神经网络进行分类
3.1 创建神经网络与训练
from keras.models import Sequential
from keras.layers import Dense,Dropout
model = Sequential()
# input_dim表示数据集的特征维度
model.add(Dense(64,input_dim=8,activation='relu'))
# Drop防止过拟合的数据处理方式
model.add(Dropout(0.5))
model.add(Dense(64,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
# 编译模型,定义损失函数,优化函数,绩效评估函数
# binary_crossentropy 是二元分类问题会优先选择使用的损失函数
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 导入数据进行训练
model.fit(X_train,y_train,epochs=100,batch_size=128)
3.2 模型预测与评估
yp = model.predict(X_test)
yp[yp>0.5] = 1
yp[yp<0.5] = 0
# 模型评估
score = model.evaluate(X_test,y_test,batch_size=128)
print(score)

最终得到,损失值:0.4662424623966217 准确率:0.8142856955528259
3.3 画出混淆矩阵
cm_plot(y_test, yp)
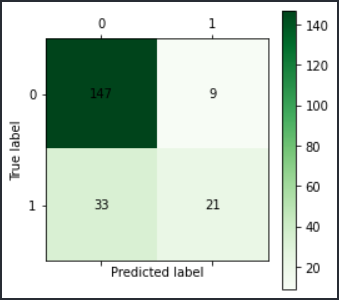
对比:两种分类模型最终得到的准确率相差不大,神经网络模型稍微要比K邻近模型好一点,并且还可以提高迭代次数。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)