Ubuntu下OpenCV显示文字信息
一、汉字点阵字库原理
1.1 什么是点阵?

 以上的两个文字的字模信息,应该让我们很清楚的明白了文字的显示原理。但是又是如何获取这些字模信息的呢?
以上的两个文字的字模信息,应该让我们很清楚的明白了文字的显示原理。但是又是如何获取这些字模信息的呢?1.2 什么是汉字字库?如何寻址?
1.3 什么是区位码
在国标GB2312—80中规定,所有的国标汉字及符号分配在一个 94 行、94 列的方阵中,方阵的每一行称为一个“区”,编号为 01 区到 94 区,每一列称为一个“位”,编号为01 位到 94 位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。区位码的前两位是它的区号,后两位是它的位号。用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。汉字“母”字的区位码是 3624,表明它在方阵的 36 区 24 位,问号“?”的区位码为0331,则它在 03 区 31 位。
1.4 什么是机内码
汉字的机内码是指在计算机中表示一个汉字的编码。机内码与区位码稍有区别。如上所述,汉字区位码的区码和位码的取值均在 1~94 之间,如直接用区位码作为机内码,就会与基本 ASCII 码混淆。为了避免机内码与基本 ASCII 码的冲突,需要避开基本 ASCII 码中的控制码(00H~1FH),还需与基本 ASCII 码中的字符相区别。为了实现这两点,可以先在区码和位码分别加上 20H,在此基础上再加 80H(此处“H”表示前两位数字为十六进制数)。经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低位字节,这两位字节的机内码按如下规则表示:高位字节 = 区 码 + 2 0 H + 8 0 H ( 或 区 码 + A 0 H ) 低 位 字 节 = 位 码 + 2 0 H + 8 0 H ( 或 位 码 + A 0 H ) 高位字节 = 区码 + 2 \ 0H + 8 \ 0H(或区码 + A \ 0H) \\ 低位字节 = 位码 + 2 \ 0H + 8 \ 0H(或位码 + A \ 0H)
由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的 01~94),所以汉字的高位字节与低位字节的取值范围则为 A1H~FEH(即十进制的 61~254)。 例如,汉字“啊”的区位码为 1601,区码和位码分别用十六进制表示即为 1001H,它的机内码的高位字节为 B0H,低位字节为 A1H,机内码就是 B0A1H。
正如我们在1.3中提到的
/* 区码 = HZ[0] - 128 位码 = HZ[1] - 128 */
二、点阵字库的显示原理
2.1显示的规律
所有的汉字或者英文都是下面的原理,
由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。编码排序A0A0→A0FE A1A0→A2FE依次排列。以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。其他的类推即可。英文点阵也是如此推理。

2.2字库的结构
1、点阵字库存储
在汉字的点阵字库中,每个字节的每个位都代表一个汉字的一个点,每个汉字都是由一个矩形的点阵组成,0代表没有,1代表有点,将0和1分别用不同颜色画出,就形成了一个汉字,常用的点阵矩阵有12*12, 14*14, 16*16三种字库。
字库根据字节所表示点的不同有分为横向矩阵和纵向矩阵,目前多数的字库都是横向矩阵的存储方式(用得最多的应该是早期UCDOS字库),纵向矩阵一般是因为有某些液晶是采用纵向扫描显示法,为了提高显示速度,于是便把字库矩阵做成纵向,省得在显示时还要做矩阵转换。我们接下去所描述的都是指横向矩阵字库。
2、16*16点阵字库
对于16*16的矩阵来说,它所需要的位数共是16*16=256个位,每个字节为8位,因此,每个汉字都需要用256/8=32个字节来表示。
即每两个字节代表一行的16个点,共需要16行,显示汉字时,只需一次性读取32个字节,并将每两个字节为一行打印出来,即可形成一个汉字。
3、14*14与12*12点阵字库
对于14*14和12*12的字库,理论上计算,它们所需要的点阵分别为(14*14/8)=25, (12*12/8)=18个字节,但是,如果按这种方式来存储,那么取点阵和显示时,由于它们每一行都不是8的整位数,因此,就会涉到点阵的计算处理问题,会增加程序的复杂度,降低程序的效率。
为了解决这个问题,有些点阵字库会将14*14和12*12的字库按16*14和16*12来存储,即,每行还是按两个字节来存储,但是14*14的字库,每两个字节的最后两位是没有使用,12*12的字节,每两字节的最后4位是没有使用,这个根据不同的字库会有不同的处理方式,所以在使用字库时要注意这个问题,特别是14*14的字库。
三、汉字点阵的获取
1、利用区位码获取汉字
- 汉字点阵字库是根据区位码的顺序进行存储的,因此,我们可以根据区位来获取一个字库的点阵,它的计算公式如下:
- 点阵起始位置 = ((区码- 1)*94 + (位码 – 1)) * 汉字点阵字节数
- 获取点阵起始位置后,我们就可以从这个位置开始,读取出一个汉字的点阵。
2、利用汉字机内码获取汉字
- 前面我们己经讲过,汉字的区位码和机内码的关系如下:
- 机内码高位字节 = 区码 + 20H + 80H(或区码 + A0H)
- 机内码低位字节 = 位码 + 20H + 80H(或位码 + AOH)
- 反过来说,我们也可以根据机内码来获得区位码:
- 区码 = 机内码高位字节 - A0H
- 位码 = 机内码低位字节 - AOH
- 将这个公式与获取汉字点阵的公式进行合并计就可以得到汉字的点阵位置。
四、点阵字库和矢量字库的差别
我们都只知道,各种字符在电脑屏幕上都是以一些点来表示的,因此也叫点阵。最早的字库就是直接把这些点存储起来,就是点阵字库。常见的汉字点阵字库有 16x16, 24x24 等。点阵字库也有很多种,主要区别在于其中存储编码的方式不同。点阵字库的最大缺点就是它是固定分辨率的,也就是每种字库都有固定的大小尺寸,在原始尺寸下使用,效果很好,但如果将其放大或缩小使用,效果就很糟糕了,就会出现我们通常说的锯齿现象。因为需要的字体大小组合有无数种,我们也不可能为每种大小都定义一个点阵字库。于是就出现了矢量字库。
矢量字库
矢量字库是把每个字符的笔划分解成各种直线和曲线,然后记下这些直线和曲线的参数,在显示的时候,再根据具体的尺寸大小,画出这些线条,就还原了原来的字符。它的好处就是可以随意放大缩小而不失真。而且所需存储量和字符大小无关。矢量字库有很多种,区别在于他们采用的不同数学模型来描述组成字符的线条。常见的矢量字库有 Type1字库和Truetype字库。
点阵字库
在点阵字库中,每个字符由一个位图表示,并把它用一个称为字符掩膜的矩阵来表示,其中的每个元素都是一位二进制数,如果该位为1表示字符的笔画经过此位,该像素置为字符颜色;如果该位为0,表示字符的笔画不经过此位,该像素置为背景颜色。点阵字符的显示分为两步:首先从字库中将它的位图检索出来,然后将检索到的位图写到帧缓冲器中。
实际应用
在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大。为了减少存储空间,一般采用压缩技术。
矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点。例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述。 对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等。
矢量字符的显示也分为两步。首先从字库中将它的字符信息。然后取出端点坐标,对其进行适当的几何变换,再根据各端点的标志显示出字符。
轮廓字形法是当今国际上最流行的一种字符表示方法,其压缩比大,且能保证字符质量。轮廓字形法采用直线、B样条/Bezier曲线的集合来描述一个字符的轮廓线。轮廓线构成一个或若干个封闭的平面区域。轮廓线定义加上一些指示横宽、竖宽、基点、基线等等控制信息就构成了字符的压缩数据。
五、实际的调用操作

已经提前创建好了一个名为cv9.cpp的文件 其中代码如下:
#include<iostream> #include<opencv/cv.h> #include"opencv2/opencv.hpp" #include<opencv/cxcore.h> #include<opencv/highgui.h> #include<math.h> using namespace cv; using namespace std; void paint_chinese(Mat& image,int x_offset,int y_offset,unsigned long offset); void paint_ascii(Mat& image,int x_offset,int y_offset,unsigned long offset); void put_text_to_image(int x_offset,int y_offset,String image_path,char* logo_path); int main(){ String image_path="tearsgirl.png"; char* logo_path="logo1.txt"; put_text_to_image(20,300,image_path,logo_path); return 0; } void paint_ascii(Mat& image,int x_offset,int y_offset,unsigned long offset){ //绘制的起点坐标 Point p; p.x = x_offset; p.y = y_offset; //存放ascii字膜 char buff[16]; //打开ascii字库文件 FILE *ASCII; if ((ASCII = fopen("Asci0816.zf", "rb")) == NULL){ printf("Can't open ascii.zf,Please check the path!"); //getch(); exit(0); } fseek(ASCII, offset, SEEK_SET); fread(buff, 16, 1, ASCII); int i, j; Point p1 = p; for (i = 0; i<16; i++) //十六个char { p.x = x_offset; for (j = 0; j < 8; j++) //一个char八个bit { p1 = p; if (buff[i] & (0x80 >> j)) /*测试当前位是否为1*/ { /* 由于原本ascii字膜是8*16的,不够大, 所以原本的一个像素点用4个像素点替换, 替换后就有16*32个像素点 ps:感觉这样写代码多余了,但目前暂时只想到了这种方法 */ circle(image, p1, 0, Scalar(0, 0, 255), -1); p1.x++; circle(image, p1, 0, Scalar(0, 0, 255), -1); p1.y++; circle(image, p1, 0, Scalar(0, 0, 255), -1); p1.x--; circle(image, p1, 0, Scalar(0, 0, 255), -1); } p.x+=2; //原来的一个像素点变为四个像素点,所以x和y都应该+2 } p.y+=2; } } void paint_chinese(Mat& image,int x_offset,int y_offset,unsigned long offset){//在图片上画汉字 Point p; p.x=x_offset; p.y=y_offset; FILE *HZK; char buff[72];//72个字节,用来存放汉字的 if((HZK=fopen("HZKf2424.hz","rb"))==NULL){ printf("Can't open HZKf2424.hz,Please check the path!"); exit(0);//退出 } fseek(HZK, offset, SEEK_SET);/*将文件指针移动到偏移量的位置*/ fread(buff, 72, 1, HZK);/*从偏移量的位置读取72个字节,每个汉字占72个字节*/ bool mat[24][24];//定义一个新的矩阵存放转置后的文字字膜 int i,j,k; for (i = 0; i<24; i++) /*24x24点阵汉字,一共有24行*/ { for (j = 0; j<3; j++) /*横向有3个字节,循环判断每个字节的*/ for (k = 0; k<8; k++) /*每个字节有8位,循环判断每位是否为1*/ if (buff[i * 3 + j] & (0x80 >> k)) /*测试当前位是否为1*/ { mat[j * 8 + k][i] = true; /*为1的存入新的字膜中*/ } else { mat[j * 8 + k][i] = false; } } for (i = 0; i < 24; i++) { p.x = x_offset; for (j = 0; j < 24; j++) { if (mat[i][j]) circle(image, p, 1, Scalar(255, 0, 0), -1); //写(替换)像素点 p.x++; //右移一个像素点 } p.y++; //下移一个像素点 } } void put_text_to_image(int x_offset,int y_offset,String image_path,char* logo_path){//将汉字弄上图片 //x和y就是第一个字在图片上的起始坐标 //通过图片路径获取图片 Mat image=imread(image_path); int length=18;//要打印的字符长度 unsigned char qh,wh;//定义区号,位号 unsigned long offset;//偏移量 unsigned char hexcode[30];//用于存放记事本读取的十六进制,记得要用无符号 FILE* file_logo; if ((file_logo = fopen(logo_path, "rb")) == NULL){ printf("Can't open txtfile,Please check the path!"); //getch(); exit(0); } fseek(file_logo, 0, SEEK_SET); fread(hexcode, length, 1, file_logo); int x =x_offset,y = y_offset;//x,y:在图片上绘制文字的起始坐标 for(int m=0;m<length;){ if(hexcode[m]==0x23){ break;//读到#号时结束 } else if(hexcode[m]>0xaf){ qh=hexcode[m]-0xaf;//使用的字库里是以汉字啊开头,而不是以汉字符号开头 wh=hexcode[m+1] - 0xa0;//计算位码 offset=(94*(qh-1)+(wh-1))*72L; paint_chinese(image,x,y,offset); /* 计算在汉字库中的偏移量 对于每个汉字,使用24*24的点阵来表示的 一行有三个字节,一共24行,所以需要72个字节来表示 */ m=m+2;//一个汉字的机内码占两个字节, x+=24;//一个汉字为24*24个像素点,由于是水平放置,所以是向右移动24个像素点 } else{ //当读取的字符为ASCII码时 wh=hexcode[m]; offset=wh*16l;//计算英文字符的偏移量 paint_ascii(image,x,y,offset); m++;//英文字符在文件里表示只占一个字节,所以往后移一位就行了 x+=16; } } cv::imshow("image", image); cv::waitKey(); }
完成代码后,我们需要完成一些额外的工作!!

在编译文件同子目录下,放入一些支持的汉字显示库,用于让我们的C++调用,可以显示中文名等信息。这点很重要,不然代码会一直报错!
结果展示如下: 我们在lena图上加入了自己的姓名等信息
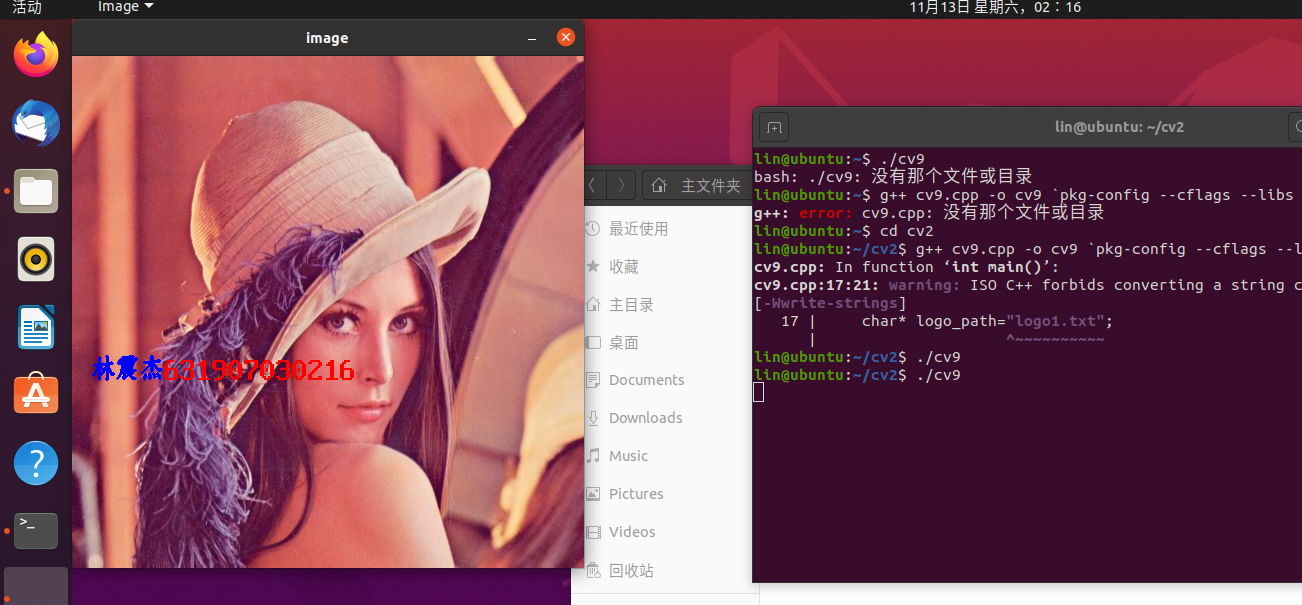
关于代码的一些解析:
int main(){ String image_path="Picture_Name.Format "; char* logo_path="filename.txt"; put_text_to_image(20,300,image_path,logo_path);//图片内容信息 return 0; }
可以将上述代码和前面的代码对照看 可以对应着进行修改
六、心得体会
Opencv的调用和修改的代码过程还是十分的复杂,尤其是汉字这样信息熵十分大而且显示起来并不简单的语言,使用的时候更加的困难。在改代码以及调用的过程中遇到了许多问题,但是都得以解决,且写在了文章里,希望通过接下来的学习能够更加的了解和理解Ubuntu和Opencv,一段时间没有使用让我对Ubuntu和CV都有了些许的陌生,这次是一次很好的复习。
七、参考链接
https://blog.csdn.net/weixin_47554309/article/details/121165507
https://blog.csdn.net/junseven164/article/details/121130735?spm=1001.2014.3001.5501

 浙公网安备 33010602011771号
浙公网安备 33010602011771号