
F1值
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下: F1值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
简介
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
F_1={(\frac{recall^{-1}+precision^{-1}}{2})}^{-1}=2\cdot \frac{precision \cdot recall}{precision+recall}
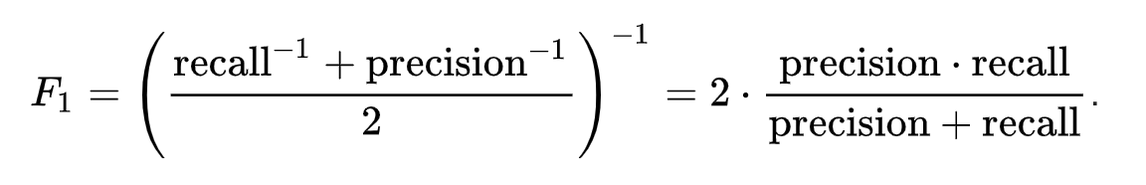
正实β的通式为:
F_\beta=(1+\beta^2)\cdot \frac{precision \cdot recall}{(\beta^2 \cdot precision)+recall}
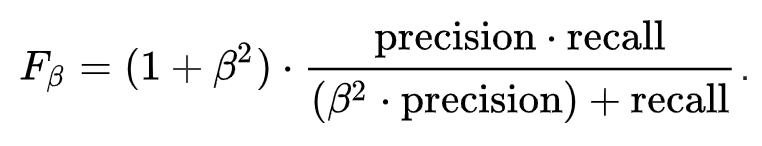
类型I和类型II错误的公式:
F_\beta=\frac{(1+\beta^2) \cdot true positive}{(1+\beta^2) \cdot true positive +\beta^2 \cdot false negative +false positive}
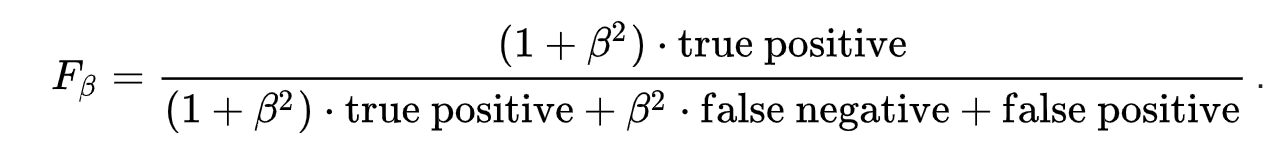
另外两个常用的F度量是 F_ {2}度量,其重量高于精度(通过强调假阴性)和 F_ {0.5}测量,其重量低于精确度(通过减弱假阴性的影响)。
推导出F-度量,以便 F _ {\ beta}“衡量检索的有效性,相对于那些将β倍重要性重新调整为精确度的用户而言”。 它基于Van Rijsbergen的有效性衡量标准
E = 1- (\frac{\alpha}{p}+\frac{1-\alpha}{r})
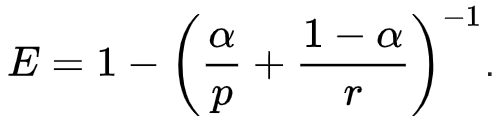
他们的关系是 F _ {\ beta} = 1-E,这里\alpha = \frac{1}{(1+\beta^2)}。
F1得分也称为Sørensen-Dice系数或Dice相似系数Dice similarity coefficient (DSC)。
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
TP:正确肯定的数目;
FN:漏报,没有正确找到的匹配的数目;
FP:误报,给出的匹配是不正确的;
TN:正确拒绝的非匹配对数;
列联表如下表所示,1代表正类,0代表负类:
| 算法|事实 | 预测1 | 预测0 |
| 实际1 | True Positive(TP) | False Negative(FN) |
| 实际0 | False Positive(FP) | True Negative(TN) |
Precision和Recall指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
传统的F-measure或平衡F-score(F1得分)是准确率和召回率的调和平均值:
【来源:WIKI; https://en.wikipedia.org/wiki/F1_score 】
不妨举这样一个例子:
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F1值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
【来源:机器之心; 【干货】机器学习算法常用指标总结 】
发展历史
描述
二分问题有很多指标可以进行评价:ROC ; F1 socorede;Matthews相关系数等。
ROC曲线在第二次世界大战期间首次用于雷达信号分析,然后才用于信号检测理论。1941年袭击珍珠港后,美国军队开始进行新的研究,以增加对正确探测到的日本飞机雷达信号的预测。为了这些目的,他们测量了雷达接收机操作员进行这些重要区分的能力,这被称为接收机操作特性。
在20世纪50年代,ROC曲线被用于心理物理学,以评估人体(有时是非人类动物)对弱信号的检测。在医学中,ROC分析已广泛用于诊断测试的评估。 ROC曲线也广泛用于流行病学和医学研究,并经常与循证医学一起提及。usted于1971年首次描述了它在医学中用于评估诊断性能的性能。在放射学中,ROC分析是评估新放射学技术的常用技术。在社会科学中,ROC分析通常被称为ROC准确率,这是一种判断默认概率模型准确性的常用技术。 ROC曲线广泛用于实验室医学,以评估测试的诊断准确性,选择测试的最佳截止值并比较多个测试的诊断准确性。
ROC曲线也证明可用于评估机器学习技术。 ROC在机器学习中的首次应用是1989年Spackman的工作中《Signal detection theory: Valuable tools for evaluating inductive learning》,他在比较和评估不同的分类算法时证明了ROC曲线的价值
ROC(receiver operating characteristic )曲线最初是由电气工程师和雷达工程师在第二次世界大战期间开发的,用于探测战场中的敌方物体,并很快被引入心理学以解释刺激的感知检测。 自那时起,ROC分析已用于医学,放射学,生物测定学,自然灾害预测,气象学,模型性能评估,和其他领域数十年,并越来越多地用于机器学习和数据挖掘研究。
ROC也被称为相对运行特性曲线,因为它是两个运行特性(TPR和FPR)的比较,随着标准的变化。
Matthews相关系数用于机器学习,生物化学家Brian W. Matthews在1975年引入的二元(两类)分类质量的量度。
F-measure这个名字被认为是在Van Rijsbergen的书中以不同的F函数命名的,当时它被引入MUC-4(Fourth Message Understanding Conference )。
在《The truth of the F-measure》中,Yutaka Sasaki提到:”有一件事仍然没有解决,那就是为什么F度量被称为F。几年前他与David D. Lewis的一次个人交流表明,当F度量被引入MUC-4时,这个名字是偶然选择的,van Rijsbergen的书中定义为“F测度”,考虑不同的F函数的结果。”
F分数通常用于信息检索领域,用于测量搜索,文档分类和查询分类性能。 早期的作品主要集中在F1得分上,但随着大型搜索引擎的激增,性能目标发生了变化,更加强调精确度或召回率,这从广泛的应用中可以看到。
F-score也用于机器学习。然而,请注意,F-度量不考虑真实的负面因素,并且诸如Matthews correlation coefficient,Informedness或Cohen's kappa之类的度量可能更适合评估二元分类器的性能。F-score已经广泛应用于自然语言处理文献中,例如命名实体识别和分词的评估。
虽然F-measure是Recall和Precision的调和平均值,但G-measure是几何平均值。
主要事件
| 年份 | 事件 | 相关论文/Reference |
| 1975 | Brian W. Matthews在1975年引入的二元(两类)分类质量的量度 | Matthews, B. W. (1975). Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure, 405(2), 442-451. |
| 1979 | van Rijsbergen的图书定义为“F测度” | Van Rijsbergen, C. J. (1979). Information retrieval. dept. of computer science, university of glasgow. URL: citeseer. ist. psu. edu/vanrijsbergen79information. html, 14. |
| 1989 | Spackman, K. A.将F度量用于信号测量 | Spackman, K. A. (1989). Signal detection theory: Valuable tools for evaluating inductive learning. In Proceedings of the sixth international workshop on Machine learning (pp. 160-163). |
| 1992 | F度量被引入MUC-4 | Chinchor, N. (1992, June). MUC-4 evaluation metrics. In Proceedings of the 4th conference on Message understanding(pp. 22-29). Association for Computational Linguistics. |
| 2008 | Li, X., Wang, Y. Y., & Acero, A.将度量使用到文本搜索中 | Li, X., Wang, Y. Y., & Acero, A. (2008, July). Learning query intent from regularized click graphs. In Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval (pp. 339-346). ACM. |
发展分析
瓶颈
Chen 和 Lin (2006) : "Combining SVMs with Various Feature Selection Strategies" 的论文中提出了一个问题:
“这些数据的两个特征都具有较低的F分数,因为分母(正负集的方差之和)远大于分子。”
换句话说,F-score 独立于其他特征揭示了每个特征的辨别力。 针对第一特征计算一个分数,针对第二特征计算另一个分数。 但它并没有展现两种功能(互信息)组合的信息。 这是 F-score 的主要弱点。
Contributor: Ruiying Cai

 浙公网安备 33010602011771号
浙公网安备 33010602011771号