
第四次作业
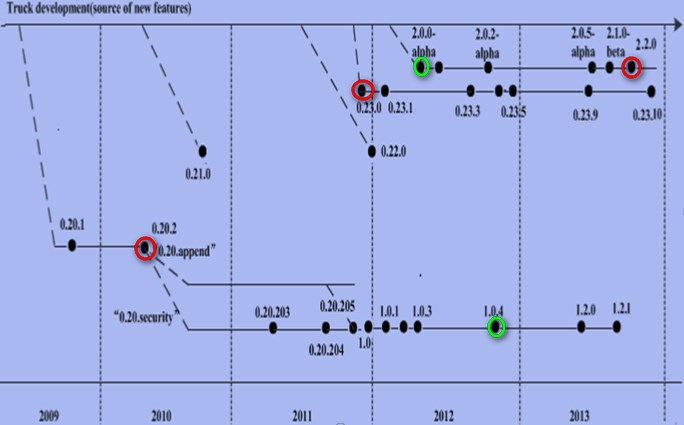
1.用图文与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop最早起源于Nutch。
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
2008年9月— Hive成为Hadoop的子项目
2008年— 淘宝开始投入研究基于Hadoop的系统–云梯
2009年3月— Cloudera推出CDH(Cloudera’s Dsitribution Including Apache Hadoop)
2009年7月— Hadoop Core项目更名为Hadoop Common;
2009年7月— MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
2009年7月— Avro 和 Chukwa 成为Hadoop新的子项目。
2011年1月— ZooKeeper 脱离Hadoop,成为Apache顶级项目。
2.简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系
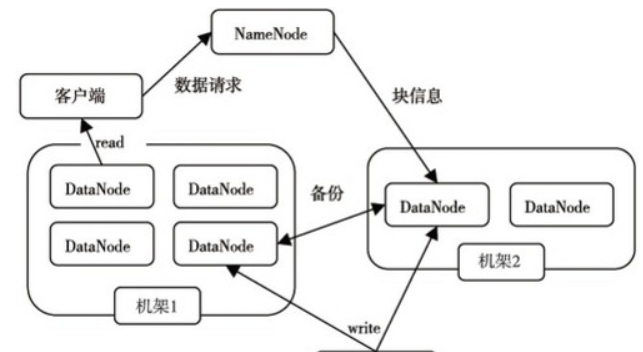
名称节点:
名称节点最主要功能:名称节点记录了每个文件中各个块所在的数据节点的位置信息。
第一名称节点类似于数据目录。其主要有两大构件构成,FsImage和Editlog,FsImage用于存储元数据(长时间不更新、Editlog用于更新数据,但是随着时间推移,Editlog内存储的数据越来越多,导致运行速度越来越慢。所以引入第二名称节点,当第一节点中Editlog到一个临界值时,HDFS会暂停服务,由第二节点将拷贝出Editlog,复制、添加到Fslmage后方并清空原Editlog的内容。
数据节点:
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 与HDFS的关联
5.完整描述Hbase表与Region的关系,三级寻址原理
6.理解并描述Hbase的三级寻址。
7.通过HBase的三级寻址方式,理论上Hbase的数据表最大有多少个Region?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号