第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | 数据采集,反爬虫,数据处理,可视化,Ajax,搭建服务器 |
| 作业源代码 | first-personal-work |
| 学号 | 211806229 |
前言
词云图挂服务器上面,数据加载有点慢,词云图很慢才会显示出来。
分析了一下作业,做了一张思维导图。
作业一需要通过爬虫进行数据的获取,查看网上的相关资料,基本都是通过 requests 获取数据,然后利用正则表达式处理数据。但是仔细观察了程序,发现他们爬虫的页数较少,但是由于是爬虫腾讯的网址,我觉得获取到所有的评论,肯定要反爬虫,目前的思路是利用用户代理和IP代理进行。IP代理这里还有涉及到IP池的问题,因为不充钱的肯定要自己处理IP。数据处理这步就是看第三步可视化需要什么样的数据了。echarts 官网没有找到词云图的模板,通过百度发现,好像是 echarts3.0 取消了词云图,但是还是可以通过 GitHub 获取到词云图模板的源码。观察源码发现,词云图所需要的数据格式也是{"name":xxx,"value":xxx}所有处理成这个格式就行了。因为获取到的评论都是长文字,所有这里就涉及到NLP自然语言的处理,作业提供了三个分词工具,仔细阅读了官方文档,发现 jieba 学起来比较简单,所以就选择了 jieba 进行分词。官网有实例代码,想过去应该是不会很难。
作业二,观察了一下用友,发现提供了 api 和示例代码以及 Json 返回示例,猜测应该是,通过提供的程序,可以获取到 Json 文本,然后利用得到的 Json 进行处理。通过搜索了解到,地图的展示也是通过模板 + 数据,然后数据还是{"name":xxx,"value":xxx},应该是和作业一一样的处理方法。后面简单写了一下处理方式。和作业一套路一样。
目前看起来作业二难度应该和作业一差不多,作业一难度主要在于反爬部分,作业二省略了数据获取的步骤,但是可视化可以有多种多样的样式。
一、计划安排
| 步骤 | 计划时间 | 完成状态 |
|---|---|---|
| 仓库搭建 | 5min | 完成 |
| 分析网址 | 30min | 完成 |
| 正则表达式 | 30min | 完成 |
| 完整代码 | 1h | 完成 |
| 反爬虫 | 1h | 完成 |
| 保存为JSON | 30min | 完成 |
| jieba分词处理 | 45min | 完成 |
| 数据处理 | 1h | 完成 |
| 词云 | 2h | 完成 |
| ajax | 3h | 完成 |
| 项目推送 | 10min | 完成 |
| 推送服务器 | 30min | 完成 |
2. 创新说明
利用宝塔,搭建了一个服务器,把网址挂载在上面。
二、仓库搭建
作业要求,是创建 crawl和chart两个分支一个是处理数据采集和代码编程的,一个是数据可视化的。
仓库分支是完成项目很重要的一个部分。个人认为,B站上面黑马程序员的Git教程的分支管理那个图很好理解,而小甲鱼的视频操作性更强。
三、数据采集
1)遇到的问题
1. 获取评论的时候也将子评论爬虫进去了。
仔细查看了源码,发现评论主要在 data 下面的 oriCommList 列表里,其他范围的评论为子评论。个人认为子评论也算有效评论,目前不打算处理。

2. 获取全部评论数,直接通过 requests 获取不到
尝试了 xpath 和 requests 发现不能获取全部评论数,所以目前只能通过 selenium 获取,但是 selenium 效率太低了,就获取一个评论总数,还不如打开源码直接修改评论总数,所以暂时没有修改
3. 评论总数数据太大
因为之前爬虫过很多网站,同一个 user-agent 很容易被 ban ,所以目前构建了用户代理,然后进行随机。其实还想加一个 ip 代理的,但是使用了 ip 代理的网址,上面写的正常的 ip ,在使用的时候,拒绝连接。也尝试过构建代理池。但是代理池一般都是使用docker 和 Redis 进行获取。暂时没有选用,之选用了用户代理,然后在获取 headers 的时候加个 time.sleep(1)。目前还是正常的。
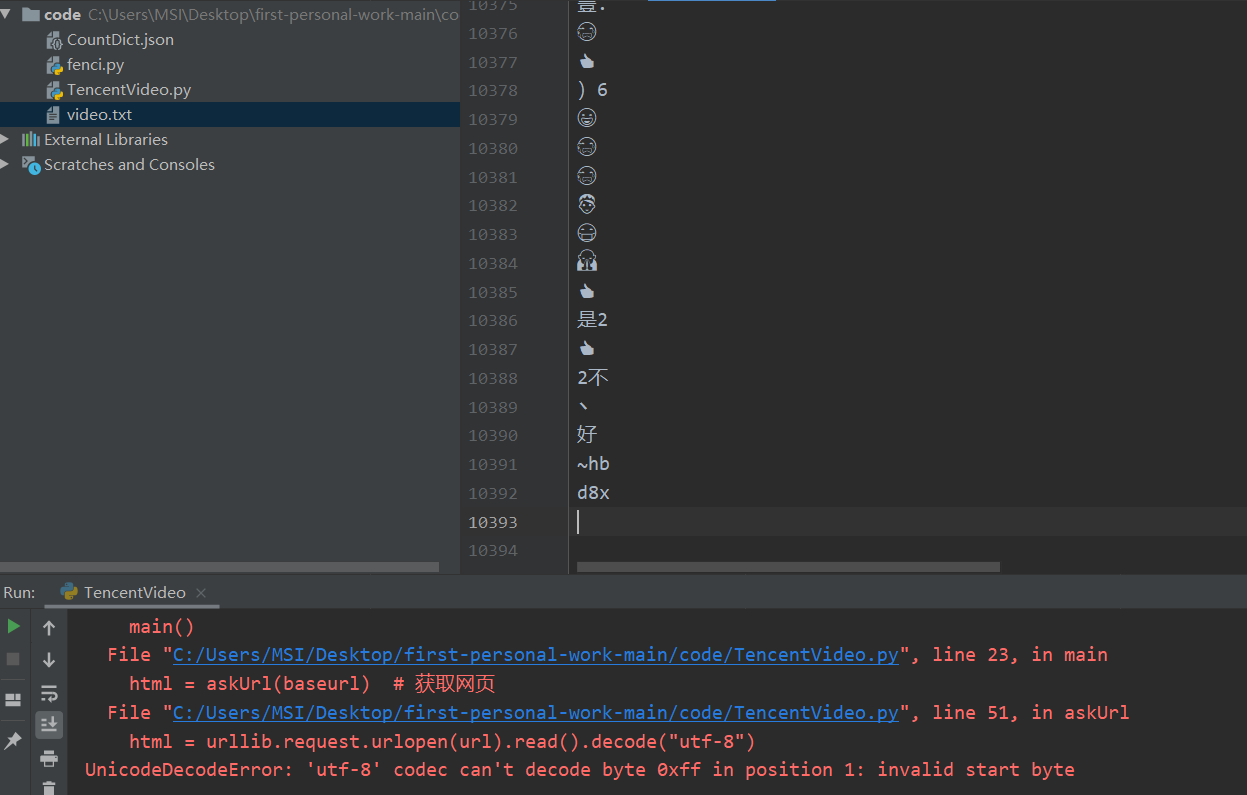
4. 报错'utf-8' codec can't decode byte 0xff in position 1: invalid start byte
遇到这个问题,实在无语,我怀疑后面的评论是新出的 emjoy,然后utf-8不能识别,程序挂掉了。但是选取其他格式,在解释的过程估计还会挂掉,就暂时爬到1万条吧。
四、数据处理
数据已经全部爬完了。需要开始进行数据处理,数据需要整理为{"name":xxx,"value":xxx}格式。
Python入门:jieba库的使用参考了这位大佬的程序。在之前在阅读制作词云的文章时,遇到文本问题的时候,他们会删去语气助词等词。查阅资料发现已经有人整理好了,中文常用停用词表,直接进行使用就行了。这时候就直接把分好的词中删除,停词即可。
参考了『NLP自然语言处理』中文文本的分词、去标点符号、去停用词、词性标注这位大佬的程序。再此基础上进行修改,并将处理好的词组,保存为echarts需要的格式。
def moveStopwords(words, stopwords): # 去停用词
out_list = []
for word in words:
if word in stopwords:
continue
else:
out_list.append(word)
return out_list
主要就是判断分出来的词是否在停用词内,不存在则存储到列表中用于后续的使用。
def main():
CountList = []
stopwords = getStopwords() # 创建停用词
words = dealFile() # 处理文本
depart = moveStopwords(words, stopwords) # 去停用词
items = totol(depart)
for i in range(len(items)):
CountDict = {}
word, count = items[i]
if count >= 10:
CountDict["name"] = word
CountDict["value"] = count
CountList.append(CountDict)
saveFile(CountList)
增加了一个判断语句,因为爬出来的数据很大,有很多仅出现了少次的词组,没有较大的意义,所以就进行了删除。
多次尝试发现,范围大于十的生成的图形会比较好看。
五、数据可视化
echarts 还是挺简单的。主要就五个步骤,然后直接在官方文档里面找配置项,进行更改。
由于目前版本的 echarts 是没用词云的模板的在 echarts.js 中。所以通过 GitHub 找到了 echarts-wordcloud,该文档提供了两份词云图的模板,直接使用就可以了。但是这个文档里面的数据是直接贴进去的,因为数据处理之后获得的数据较多,通过直接粘贴的方式,其实并不方便,所以就去学了一下 Ajax 调用 JSON 来渲染网页。因为网上有现成的,就直接改改就用了。但是有个问题,网页渲染的效率非常的低,不知道是因为数据量太大的原因,还是程序效率太低的原因。最后加了一个保存图片的工具栏,大概就这样完成了。效果图如下:

遇到的问题
1)界面渲染很慢
目前还没有解决。尝试过优化,但是失败了。加了一个加载动画,让进入网页不是那么的尴尬,但是在渲染数据的时候,还是有一段时间的空白。我在想是不是数据太大的原因,然后加载数据是直接通过循环列表的长度,时间复杂度较高的原因。
六、推送服务器
词云图网址挂服务器上面了。用宝塔,挺无脑的,可玩性还挺高。
index.html 不在主目录下面,在宝塔里设置运行路径,更改之后,网址不能渲染。直接带路径,却可以渲染很奇怪。
七、git commit 规范
你可能已经忽略的git commit规范,完整的写法可以参考以上连接。
简单的可以写成(冒号后面有一个空格需要注意。)
<type>: <subject> //这样的格式
type 主要有一下七种,根据需要进行选择。
feat: 新增feature
fix: 修复bug
docs: 仅仅修改了文档,如readme.md
style: 仅仅是对格式进行修改,如逗号、缩进、空格等。不改变代码逻辑。
refactor: 代码重构,没有新增功能或修复bug
perf: 优化相关,如提升性能、用户体验等。
test: 测试用例,包括单元测试、集成测试。
chore: 改变构建流程、或者增加依赖库、工具等。
revert: 版本回滚
subject 就是简短的描述一下提交内容。
需要注意的是
- 以动词开头,使用第一人称现在时;
- 第一个字母小写;
- 结尾不加句号(.);
- 内容不超过五十个字符
八、作业二:疫情统计分布信息图
1. 数据采集
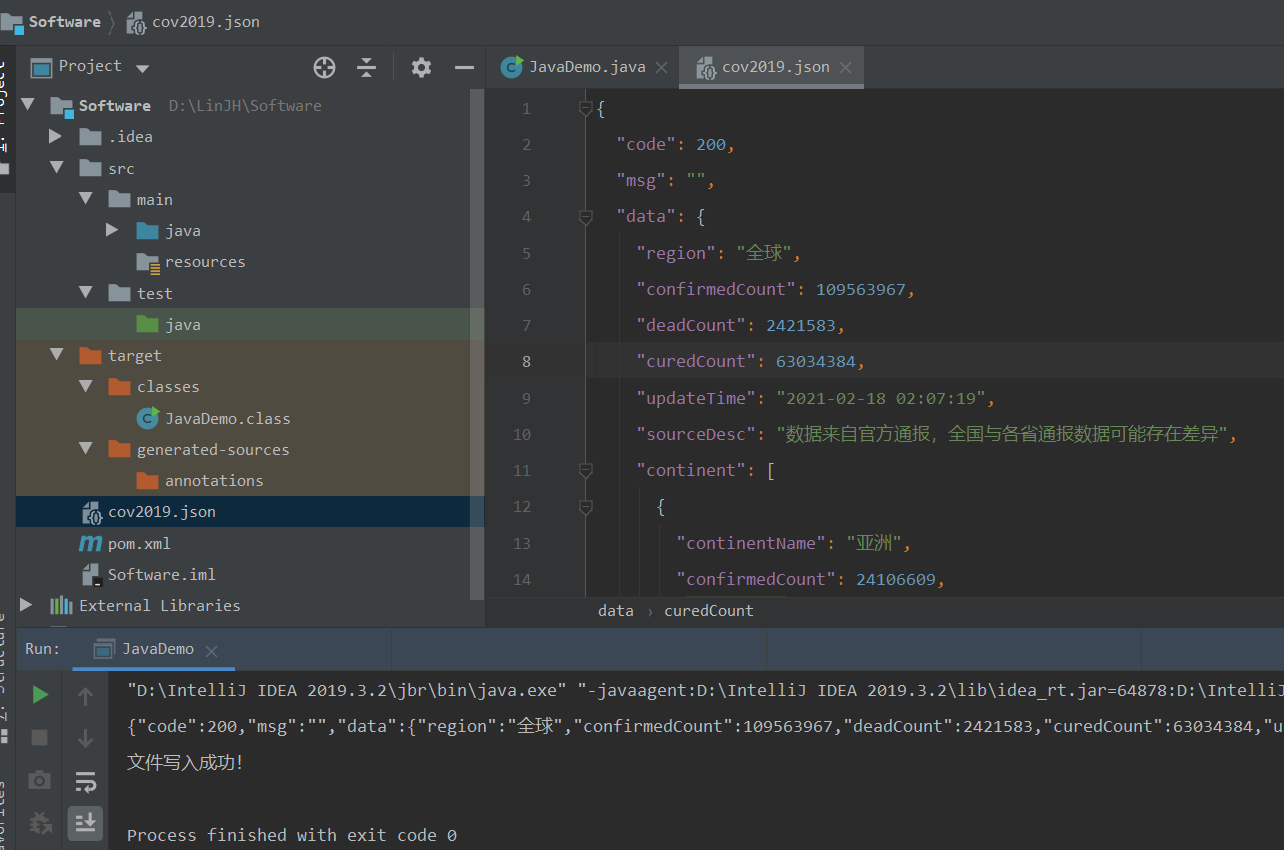
搭建了一个 Maven 环境,导入jar包,复制实例代码,更改key。编写一个文件保存函数,对获取到的JSON文本进行保存,数据获取完成。
2. 数据处理
这题难点应该在于数据处理。观察生成的 JSON 文件,发现国家的数据主要在country列表中间。它是一种层级递进的关系。直接调用import json库利用递进关系直接提取出所需要的信息。目前还注意到,他的国家是按照洲分的,所以每个洲都要单独的提取出来,然后进行整合处理。观察了 echarts 的地图模板发现,国家是英文的,所以要对中英文进行转化。通过用友接口提取出来的 JSON 文件,发现数据包含,确诊人数,治愈人数和死亡人数。这些信息都可以体现在网页上。格式大概就是{name:“福建”,value:[{name:“时间”,value:“20180318”},{name:“数值”,value:“521990”},{name:“类型”,value:“管理”},{name:“程度”,value:“一般”}]},具体可以参考echarts 中国地图,tooltip,legend同时显示多组数据
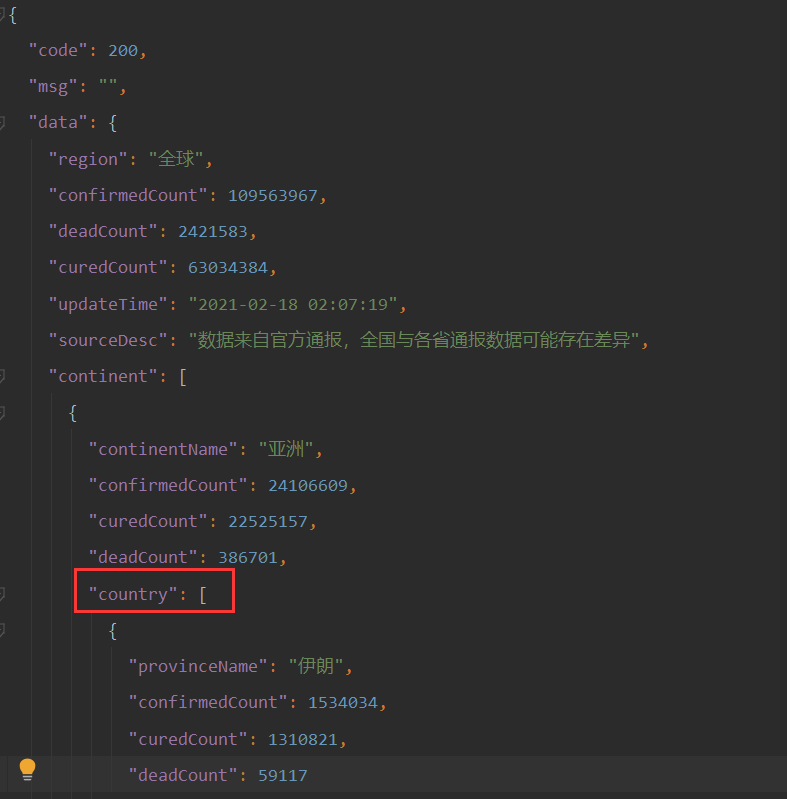
利用层级关系可以直接获取到想要的数据。
def DealDate(data):
data=data["data"]["continent"]
Asia=data[0]["country"]
Europe=data[1]["country"]
NorthAmerica=data[2]["country"]
SouthAmerica=data[3]["country"]
Africa=data[4]["country"]
Oceania=data[5]["country"]
country=Asia+Europe+NorthAmerica+SouthAmerica+Africa+Oceania
3. 数据可视化
首先找到一个世界地图的模板,DataVis-2019nCov,World Population。阅读项目,查看项目所需要的数据格式。然后直接引用处理过的 JSON 文件即可。
参考资料
Python入门:jieba库的使用
中文常用停用词表
『NLP自然语言处理』中文文本的分词、去标点符号、去停用词、词性标注
基于Echarts的自定义图案动态词云
5 分钟上手 ECharts

 浙公网安备 33010602011771号
浙公网安备 33010602011771号