Flume 数据采集工具安装与使用
Flume 的定义
- Flume由Cloudera公司开发,是一个分布式、高可靠、高可用的海量日志采集、聚合、传输的系统。
- Flume支持在日志系统中定制各类数据发送方,用于采集数据;
- Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
简单的说,Flume是实时采集日志的数据库引擎。
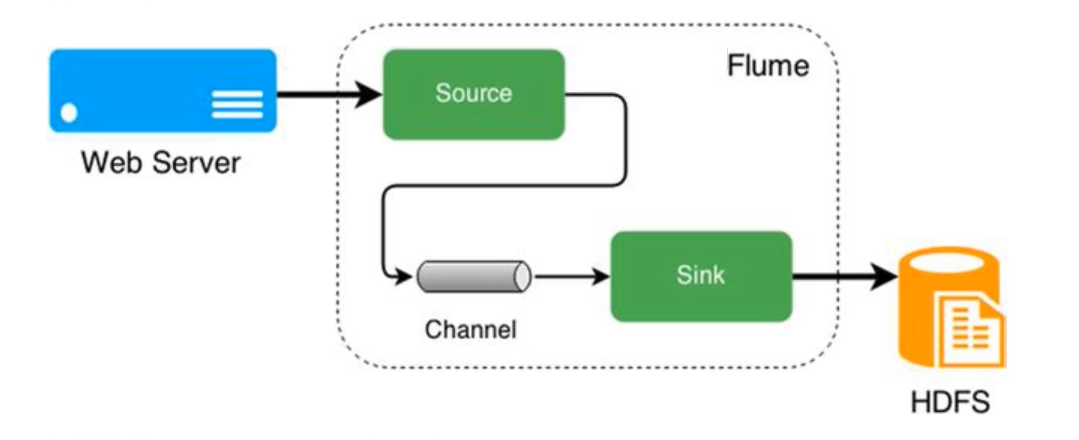
Flume 组建
Flume有三个重要组件:Source、Channel、Sink
- Source:数据接收的组件。处理各种类型、各个格式的日子数据。如:avro、exce、netcat。
- Channel:位与Source与Sink之间的缓冲区。允许Source、Sink运行在不同的速率上。(线程安全,可以同时处理多个Source、Sink)
- 常见的Channel:Memory Channel、File Channel
- Memory Channel:内存 速度快、容量有限、容易丢数据
- File Chenmel:文件 速度慢、容量大、不丢数据
- Sink:不断的从Channel中取数据,发送到目的地。
Flume 的特点
特点:
- 分布式:flume分布式集群部署,扩展性好
- 可靠性好:当节点出现故障时,日志能够被传送到其他节点上而不会丢失
- 易用性:flume配置使用较繁琐,对使用人员专业技术要求高
- 实时采集:flume采集流模式进行数据实时采集
适用场景 :适用于日志文件实时采集。
Flume 安装
https://flume.apache.org/download.html
本文章使用的是 Flume1.9.0
安装节点是slave2
- 下载安装
# 下载Flume1.9.0
wget https://dlcdn.apache.org/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz -P /opt/software --no-check-certificate
# 解压至 /opt/servers
tar -zxvf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/servers
# 重命名
cd /opt/servers
mv apache-flume-1.9.0-bin flume-1.9.0
- 配置环境变量
vim /etc/profile
# Flume
export FLUME_HOME=/opt/servers/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
使其生效
source /etc/profile
- 拷贝配置模版
cd $FLUME_HOME/conf
cp flume-env.sh.template flume-env.sh
- 修改配置
vim flume-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_202
简单案例
中文flume帮助文档
https://flume.liyifeng.org/
业务需求
监听本机 8888 端口,Flume将监听的数据实时显示在控制台
需求分析:
使用 telnet 工具可以向 8888 端口发送数据
- 监听端口数据,选择 netcat source
- channel 选择 memory
- 数据实时显示,选择 logger sink
实现步骤
- 安装telnet工具
yum install telnet
- 检查8888端口是否被占用。如果该端口被占用,可以选择使用其他端口完成任务
lsof -i:8888
# 如果有进程占用
kill [PID]
- 创建Flume Agent配置文件。flume-netcat-logger.conf
https://flume.liyifeng.org/#netcat-tcp-source
https://flume.liyifeng.org/#memory-channel
https://flume.liyifeng.org/#logger-sink
mkdir ~/conf
vim ~/conf/flume-netcat-logger.conf
添加以下内容
# Agent a1是Agent的名称,r1、c1、k1分别是source、channels、sink的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = slave2
a1.sources.r1.port = 8888
# Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
# Sink
a1.sinks.k1.type = logger
# Source、Channel、Sink之间的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Memory Channel是使用内存缓冲Event的Channel实现。速度比较快速,容量会受到jvm内存大小的限制,可靠性不够高。适用于允许丢失数据,但对性能要求较高的日志采集业务。
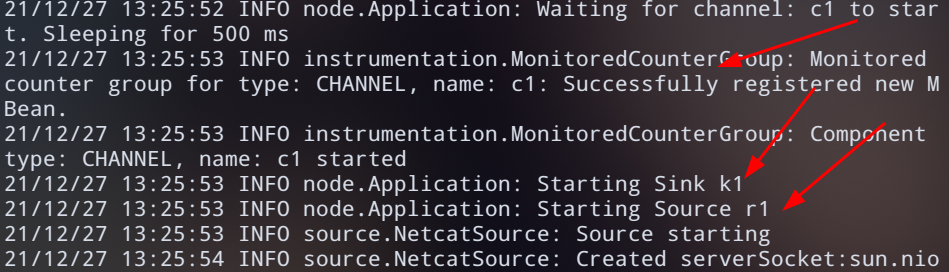
- 启动Flume
flume-ng agent --name a1 \
--conf-file ~/conf/flume-netcat-logger.conf \
-Dflume.root.logger=INFO,console
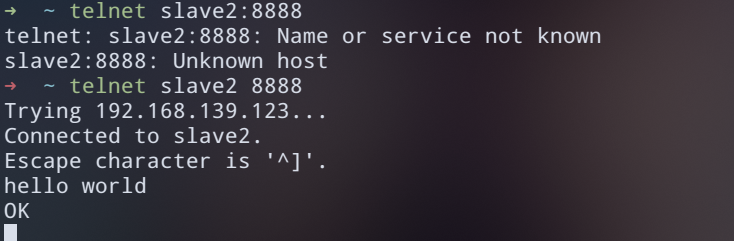
- 发送数据
telnet slave 8888
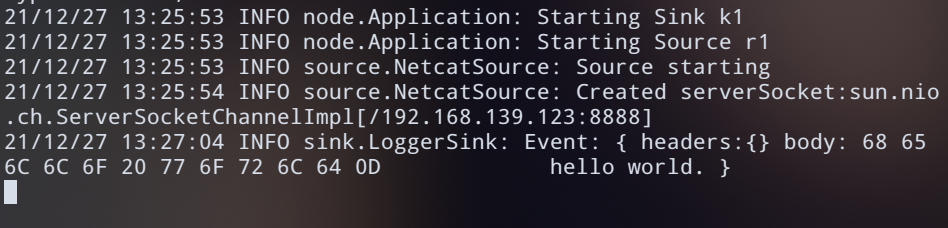
收到数据并打印在终端上
监控日志文件信息到HDFS
业务需求:监控本地日志文件,收集内容实时上传到HDFS
需求分析:
使用tail-F命令即可找到本地日志文件产生的信息
- source选择exec。exec监听一个指定的命令,获取命令的结果作为数据源。source组件从这个命令的结果中取数据。当agent进程挂掉重启后,可能存在数据丢失;
- channel选择memory
- sink选择HDFS
tail -f
等同于--follow=descripror,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F
等同于--follow=name--retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪选择语言
操作步骤
1、环境准备。Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包。将
commons-configuration-1.6.jar
hadoop-auth-2.10.1.jar
hadoop-common-2.10.1.jar
hadoop-hdfs-2.10.1.jar
commons-io-2.4.jar
htrace-core4-4.1.0-incubating.jar
拷贝到 $FLUME_HOME/lib文件夹下
cd $HADOOP_HOME/share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib
cp commons-configuration-1.6.jar $FLUME_HOME/lib
cp hadoop-auth-2.10.1.jar $FLUME_HOME/lib
cp hadoop-common-2.10.1.jar $FLUME_HOME/lib
cp hadoop-hdfs-2.10.1.jar $FLUME_HOME/lib
cp commons-io-2.4.jar $FLUME_HOME/lib
cp htrace-core4-4.1.0-incubating.jar $FLUME_HOME/lib
- 创建配置文件
vim ~/conf/flume-exec-hdfs.conf
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /tmp/root/hive.log
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://master:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
# 是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
# 积攒10000个Event才f1ush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 10000
# 设置文件类型,支持压缩。Datastream没启用压缩
a2.sinks.k2.hdfs.fileType = DataStream
# 1分钟滚动一次
a2.sinks.k2.hdfs.rollInterval = 60
# 128M滚动一次
a2.sinks.k2.hdfs.rollsize = 134217700
# 文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# 最小见余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
- 启动Flume
flume-ng agent --name a2 \
--conf-file ~/conf/flume-exec-hdfs.conf \
Dflume.root.logger=INFO,console
- 测试
使用命令监控,为什么做比对
cd /tmp/root
tail -F hive.log
输入错的命令使其产生日志
hive -e "show databasessss"
- 查看HDFS中的文件
hadoop fs -ls /flume


 浙公网安备 33010602011771号
浙公网安备 33010602011771号