Hive 的安装与配置
安装前提
本教程基于《Apache Hadoop 完全分布式集群搭建》下进行搭建
https://www.cnblogs.com/LzsCxb/p/15389375.html
软件版本
- Hadoop 2.10.1
- Mysql 8.0.26
- Hive 2.3.9
- 安装 Mysql(8.0.26) 到 slave2
https://www.cnblogs.com/LzsCxb/p/15366225.html - 下载 Mysql JDBC JAR 包
https://dev.mysql.com/downloads/connector/j
解压后将 JAR 包上传至服务器/opt/software
| 软件 | master | slave1 | slave2 |
|---|---|---|---|
| Hadoop | ✓ | ✓ | ✓ |
| Mysql | ✓ | ||
| Hive | ✓ |
Mysql 创建并授权 Hive 账户
slave2
不满足策略则需要按上面方法修改密码策略
create user 'hive'@'%' identified by '0000';
# 将所有权限授权给 Hive 账户
grant all on *.* to 'hive'@'%';
# 刷新权限
flush privileges;
测试是否能成功登录 mysql -uhive -p0000
配置 Hive
slave2
下载 Hive(2.3.9) 并解压缩
cd /opt/software
wget https://dlcdn.apache.org/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
tar -zxvf apache-hive-2.3.9-bin.tar.gz -C ../servers/
cd ../servers
mv apache-hive-2.3.9-bin hive-2.3.9
配置环境变量
vim /etc/profile
# HIVE
export HIVE_HOME=/opt/servers/hive-2.3.9
export PATH=$PATH:$HIVE_HOME/bin
# 使其生效
source /etc/profile
配置 Hive
创建 hive-site.xml 文件
cd $HIVE_HOME/conf
# 新建 hive-site.xml 文件增加以下内容:
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Hive 元数据的存放位置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave2:3306/hivemetadata?createDatabaseIfNotExist=true&allowPublicKeyRetrieval=true&useSSL=false</value>
<description>JDBC connect String for a JDBC metastore</description>
</property>
<!-- 指定驱动程序 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 连接数据库的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<!-- 连接数据库的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>0000</value>
<description>password to use against metastore database</description>
</property>
</configuration>
移动 JDBC 文件至 lib 目录
cp mysql-connector-java-8.0.26.jar /opt/servers/hive-2.3.9/lib
初始化元数据库
schematool -dbType mysql -initSchema

查看数据库是否创建成功
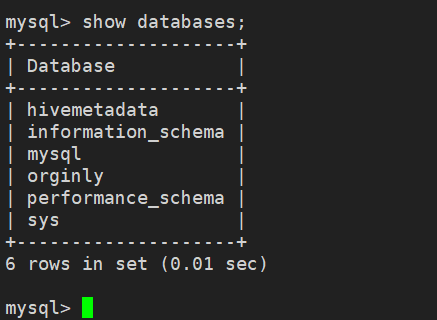
启动 Hive
hive
- 启动成功后如果出现 Log4j 版本冲突警告(可忽略)
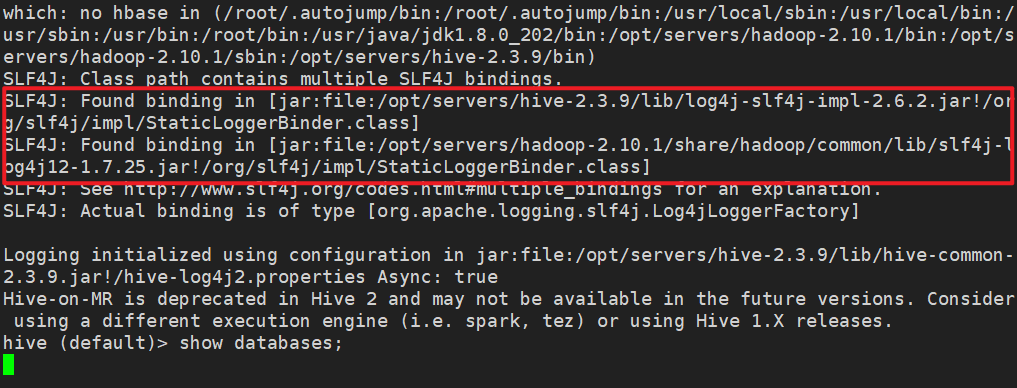
我们保留 Hadoop 的 Log4j,删除 Hive 中的 Log4j
rm /opt/servers/hive-2.3.9/lib/log4j-slf4j-impl-2.6.2.jar
-
如果出现下面异常是因为HDFS、服务未启动

-
如出现以下异常则是进入了安全模式,需要等待

到这里一个基本可用的 Hive 环境已经搭建好了!
Hive 常用属性配置
可以在 hive-site.xml 中增加以下常用配置,方便使用
数据存储位置
<property>
<!-- 数据默认存储位置(HDFS) -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
显示当前操作的 Database 库
<!-- 在命令行中显示当前操作的数据库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
显示表头属性
<property>
<!-- 在命令行中显示数据的表头 -->
<name>hive.cli.print.header</name>
<value>true</value>
</property>
本地模式
<property>
<!-- 操作小规模数据时,使用本地模式,提高效率 -->
<name>hive.exec.mode.local.auto</name>
<value>true</value>
</property>
备注:当 Hive 的输入数据量非常小时,Hive 通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间会明显被缩短。当一个 job 满足如下条件才能真正使用本地模式:
- job 的输入数据量必须小于参数:hive.exec.mode.local.auto.inputbytes.max (默认128MB)
- job 的 map 数必须小于参数:hive.exec.mode.local.auto.tasks.ma x(默认4)
- job 的 reduce 数必须为 0 或者 1
Hive Log4j 配置
cd /opt/servers/hive-2.3.9/conf
cp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties
可以使用默认配置


 浙公网安备 33010602011771号
浙公网安备 33010602011771号